рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Философия
- /
- Обычно понятия данные и информация считают синонимичными. Необходимо, однако, помнить, что эти понятия имеют разный смысл
Реферат Курсовая Конспект
Обычно понятия данные и информация считают синонимичными. Необходимо, однако, помнить, что эти понятия имеют разный смысл
Обычно понятия данные и информация считают синонимичными. Необходимо, однако, помнить, что эти понятия имеют разный смысл - раздел Философия, Введение. Содержание Курса ...
Введение. Содержание курса
В любой АИС информация хранится в ЭВМ и обрабатывается с помощью ЭВМ. ЭВМ обрабатывает информацию таким образом, как это необходимо пользователю или приложению.
Пользователями АИС являются люди, пользующиеся услугами системы. Приложение – это программа или, иначе, прикладная программа, обрабатывающая данные, хранящиеся в ЭВМ. Разница – в интерфейсе. Для пользователей нужны средства общения с АИС или, так называемый интерфейс пользователя. Если же АИС работает только с приложением, то интерфейс не нужен.
Обычно понятия данные и информация считают синонимичными. Необходимо, однако, помнить, что эти понятия имеют разный смысл.
Понятие информация обычно используют тогда, когда хотят подчеркнуть содержательный смысл, т.е. семантику сообщения. Но ЭВМ не способна воспринимать смысловое содержание. В памяти ЭВМ хранятся лишь 1 и 0, которыми она и оперирует. Поэтому, применительно к ЭВМ, обычно используют понятие данные. Приписывая данным определенный смысл (с помощью алгоритмов, программ, структуризации данных), их обработку воспринимают как обработку информации.
Мы, в дальнейшем, будем использовать эти понятия как синонимы. Разницу между ними будем подчеркивать лишь при необходимости.
Решение любой задачи, связанной с обработкой информации на ЭВМ, выполняется в несколько этапов. Вначале задача четко формулируется и формализуется с тем, чтобы можно было разработать алгоритм ее решения. Затем:
-определяется структура данных, позволяющая представить информацию в памяти ЭВМ;
-выбирается способ и метод обработки данных;
-разрабатывается алгоритм решения задачи;
-и, наконец, пишутся программы обработки на алгоритмическом языке.
В настоящей дисциплине изучаются способы организации и хранения данных в памяти ЭВМ, а также методы обработки данных.
Курс по нашей дисциплине состоит из трех разделов.
В разделе 1 рассматриваются структуры данных, т.е. способы организации и хранения данных в основной памяти ЭВМ, позволяющие наполнять данные определенным смысловым содержанием.
В разделе 2 рассматриваются методы и способы обработки данных, позволяющие составлять эффективные алгоритмы и программы обработки данных.
В разделе 3 рассматриваются способы организации данных во внешней памяти ЭВМ и методы доступа к данным, хранящимся на ВЗУ ЭВМ.
Организация памяти ЭВМ
Архитектура машинной памяти Память ЭВМ – это совокупность различных ЗУ. Основными техническими… Емкость ЗУ определяет предельный объем данных, которые можно разместить в ЗУ. Емкость измеряется в битах, байтах, а,…Адресация основной памяти
Каждая ячейка имеет уникальный адрес, по которому происходит обращение к ней при записи и считывании. ОП является ЗУ с непосредственным доступом,…Структуры данных
Три уровня представления данных При разработке АИС различают три уровня представления данных: логический… На логическом уровне работают с логическими структурами данных. Логическая структура данных отображает информацию об…Логическая структура данных определена, если определены типы логических записей и установлены связи между ними.
На логическом уровне представления данных не учитывается техническое и программное обеспечение АИС, т.е. не учитывается язык программирования, тип… На уровне хранения оперируют со структурами хранения.При разработке структур хранения устанавливаются
-способ представления логических записей в памяти машины, т.е. определяются хранимые записи, -способ установления связей. На уровне хранения учитываются особенности выбранного языка программирования.Внутренняя структура записи
Единицей первого, самого нижнего уровня, являются элементарное данное. Это – число, символ, логическое данное. Элементарные данные читаются… Элементарное данное имеет определенную форму представления в ОП и занимает… Для символьных данных – 1 символ занимает в памяти 1 байт. Каждый символ представлен определенным восьмиразрядным…Способы размещения данных в памяти ЭВМ
Последовательное представление данных в памяти ЭВМ
При последовательном представлении данные в памяти машины размещаются в соседних последовательно расположенных ячейках. При этом физический порядок… Пример: список студентов в журнале. Для хранения структуры данных в виде последовательного списка в памяти выделяется блок свободных ячеек под максимально…Связанное представление данных в памяти ЭВМ
При связанном представлении в каждой записи предусматривается дополнительное поле, в которое помещается указатель (ссылка). Физический порядок… Структуры хранения, основанные на связанном представлении, называются… Пусть, в соответствии с решаемой задачей, записи должны иметь следующий логический порядок: Зап. A, Зап. B, Зап. C,…Способ хранения, основанный на преобразовании
Ключа записи в ее адрес
Способ размещения по вычисляемому адресу используется для размещения данных как в основной памяти – таблицы с прямым доступом, так и при хранении… Для вычисления адресов используются различные процедуры, выполняющие линейные… Функция, выполняющая процедуру над ключом и генерирующая адрес записи, называется функцией преобразования. В…Страница 01
 |
К
Страница
Страница 02 переполнения
N Страница N ……..Линейные структуры данных
Массивы
Каждый элемент массива идентифицируется одним или несколькими индексами. Индекс – это целое число, значение которого определяет позицию… В однородных массивах все элементы являются данными одного и того же типа и… В зависимости от числа индексов, идентифицирующих каждый элемент, различают одномерные и многомерные массивы.Записать новый элемент можно только в вершину стека, в ту ячейку, на которую установлен указатель вершины. Прочитать из стека можно только тот элемент, который также находится в вершине стека и на который установлен указатель вершины.
Элемент, на который установлен указатель вершины, называется текущим. Указатель вершины всегда содержит информацию о позиции текущего элемента в стеке. Прочитанный элемент считается удаленным из стека.
Информация в стеке обрабатывается по принципу "последним пришел – первым ушел", так как первым будет прочитан тотэлементстека,который включался в стек последним. Структуру стека часто называют структурой типа LIFO (Last In – First Out).
Для хранения стека можно использовать как последовательное, так и связанное представление данных в памяти.
При последовательном представлении под стек резервируется блок памяти, внутри которого стек растет и сокращается. Указатель вершины стека можно размещать в одной из ячеек выделенного блока или в отдельной переменной памяти.
Можно организовать стек с изменяемым указателем вершины или с неизменным указателем вершины.
Рассмотрим стек с изменяемым указателем вершины.
Пусть указатель вершины хранится в переменной вне стека. Когда стек пуст, указатель вершины равен нулю. Перед включением каждого нового элемента указатель вершины увеличивается на 1 и устанавливается на свободную ячейку, в которую и будет записан вновь пришедший элемент. Этот элемент становится текущим. После выполнения нескольких операций включения стек может оказаться переполненным.
 При выполнении операции чтения читается содержимое той ячейки, на которую установлен указатель вершины. После чтения текущего элемента указатель вершины уменьшается на 1, прочитанный элемент становится недоступным и считается исключенным из стека. После выполнения подряд нескольких операций чтения стек может оказаться пустым. Обычно операции записи и чтения чередуются.
При выполнении операции чтения читается содержимое той ячейки, на которую установлен указатель вершины. После чтения текущего элемента указатель вершины уменьшается на 1, прочитанный элемент становится недоступным и считается исключенным из стека. После выполнения подряд нескольких операций чтения стек может оказаться пустым. Обычно операции записи и чтения чередуются.
Можно организовать стек так, что значение указателя вершины будет неизменным. Тогда указатель вершины всегда будет указывать на одну и ту же ячейку, находящуюся в вершине стека. Здесь будет размещаться текущий элемент. Именно из этой ячейки читается элемент стека. В эту же ячейку будет записываться новый элемент.
Перед включением элемента ячейка, на которую установлен указатель вершины, должна быть пустой. Поэтому все имеющиеся в стеке элементы должны передвинуться так, чтобы освободить эту текущую ячейку. Операцию включения в стек часто называют «проталкиванием».
Читается из стека текущий элемент. После чтения текущего элемента все остальные элементы стека передвигаются так, чтобы стереть прочитанный элемент, так как этот элемент должен быть исключен из стека. Операцию чтения часто называют «выталкиванием».
На рисунке изображены стек с изменяемым указателем вершины и стек с неизменным указателем вершины.
Недостаток последовательного представления стека состоит в том, что всегда остается опасность переполнения стека, когда весь зарезервированный под стек участок памяти окажется заполненным.
При связанном представлении стека нет необходимости резервировать память под стек, так как все элементы стека размещаются в любых свободных ячейках памяти и связываются между собой указателями. Указатель вершины указывает на ячейку с текущим элементом. Вновь включаемый элемент размещается в любой свободной ячейке, на которую устанавливается указатель вершины. Ячейка с новым элементом включается в связанный список элементов стека. При чтении элемента указатель вершины изменяется так, чтобы прочитанный элемент оказался исключенным из связанного списка.
Структура стека используется в тех случаях, когда требуется быстрое выполнение операций чтения и записи без оценки содержательного смысла данных. Такие задачи являются типичными для трансляторов (вычисление алгебраических выражений) и для операционных систем (обработка прерываний, обработка вызовов подпрограмм).
Очередь
Чтение элементов начинается с начала (с головы) очереди. Указатель начала (УН) указывает на элемент, который будет читаться первым. Прочитанный… Включение элементов возможно только в конец (в хвост) очереди. Указатель конца… Данные в такой структуре обрабатываются в порядке их поступления по принципу «первым пришел – первым ушел». Структуру…Таблица
В рассмотренных ранее структурах данных читаться и обрабатываться может лишь тот элемент, к которому структура обеспечивает доступ посредством индекса или указателе вершины. В процессе доступа никак не анализируется содержимое полей записей.
В большинстве задач обработки информации обращение должно осуществляться к записи об объекте, обладающем вполне определенными свойствами. В таких случаях в процессе доступа необходимо анализировать содержимое того или другого поля записи. Читаться должна лишь запись с определенным значением указанного поля. Такой доступ, называемый доступом по ключу, реализуется в табличных структурах данных.
Таблица – это линейная структура данных с произвольным доступом по ключу записи. В зависимости от способа хранения таблицу можно рассматривать как структуру фиксированного или переменного размера.
Таблица состоит из строк и одного или более столбцов. Строки таблицы – это записи об объектах предметной области. Столбцы таблицы – это поля записей, содержащие значения свойств объектов. Каждый столбец имеет имя соответствующего свойства.

Доступ к элементам (записям) таблицы осуществляется по ключу,т.е. по заданному значению одного или нескольких полей. На обработку подается (например, выводится на экран) запись, содержащая заданное значение ключевого поля.
В зависимости от задачи обработки в качестве ключа могут использоваться те или иные поля. Ключ, состоящий из одного поля, называется простым, ключ, состоящий из нескольких полей, называется составным.
Среди всех полей может существовать такое поле, значения которого уникальным образом идентифицируют каждую запись таблицы. Такое поле называется первичным (основным, главным) ключом таблицы.
Для хранения таблиц используется как последовательное, так и связанное представление данных в памяти.
При последовательном представлении таблица хранится в виде последовательного списка и обладает всеми недостатками последовательного списка (см. рис. из этой лекции). Записи таблицы располагаются одна за другой в заранее зарезервированном блоке памяти. Такие таблицы легко составлять и дополнять. Новые записи добавляются в конец таблицы, на это требуется минимальное время. Однако поиск в таких таблицах длителен. В процессе поиска последовательно просматриваются все записи таблицы, начиная с первой, и анализируется значения их ключевого поля. Просмотр происходит до тех пор, пока не будет найдена нужная запись, или пока, после просмотра всей таблицы, не будет выработан сигнал отсутствия нужной записи.
Обычно таблицы упорядочиваются в соответствии с каким-либо принципом, например, по возрастанию значений ключевого поля или по частоте обращения к записям. В том случае таблица хранятся в виде упорядоченного последовательного списка.
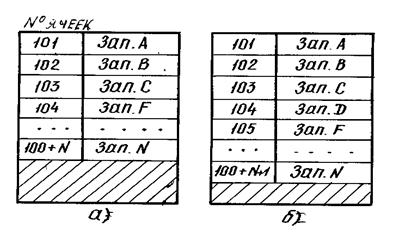
В таких таблицах поиск может быть существенно ускорен за счет использования специальных методов.
Однако ведение упорядоченной таблицы усложняется и сопровождается рядом дополнительных процедур. Так, например, для включения в упорядоченную таблицу новой записи надо определить место, которое должна занять эта запись в соответствии со значением своего ключа. Соответствующая ячейка памяти должна быть освобождена, для чего следующие записи передвигаются на одну ячейку, т.е. часть таблицы перезаписывается.
Пусть в таблицу, упорядоченную по алфавиту, содержащую записи Зап.А, Зап.В, Зап.С и Зап.F, …, Зап.N надо включить Зап. D. Эту запись необходимо физически разместить вслед за записью С в ячейке 104. Для этого все последующие записи необходимо передвинуть в сторону больших адресов. Таким образом, таблицу придется перезаписывать всякий раз с приходом новой записи. При удалении записи таблицу также придется перезаписывать.
Хранение таблиц в виде упорядоченного последовательного списка выгодно тогда, когда предельный размер таблицы заранее известен, а задачи обработки данных требуют частого обращения к данным (частых поисков), но редкого добавления и удаления данных.
Упорядоченную таблицу можно хранить в виде связанного списка. Ведение динамически изменяющейся таблицы при этом не требует выполнения процедур перезаписи. Однако поиск в такой таблице возможен лишь последовательным просмотром записей в порядке, определяемом указателем. Ускоренный поиск в таких таблицах невозможен. Под указатели расходуется дополнительная память.
Для хранения таблиц часто используют смешанный (последовательно-связанный) способ хранения.

При создании таблицы записи размещаются последовательно в зарезервированном блоке памяти (Табл. А и Табл. В). По мере роста Таблицы А, после того как выделенный под нее блок окажется заполненным, для табл. А выделяется новый блок памяти. Он связывается указателем с первым блоком. После заполнения Таблицы В под нее также выделяется новый блок памяти. Такие таблицы могут расти как угодно долго.
Для хранения таблиц часто используется способ, основанный на преобразовании ключа записи в адрес ее хранения. При этом обеспечивается самый быстрый – прямой - доступ к записям.
Если все N записей таблицы имеют разные значения ключа Ki и найдена функция f(Ki) , такая, что для любого 0 < I <= N f(Ki) принимает целое значение от 0 до m, то значение f(Ki) можно рассматривать как адрес ячейки памяти, в которой и размещается запись с ключом Ki . Функция f(Ki) - это функция преобразования (функция расстановки). Доступ к любой записи осуществляется путем непосредственного вычисления по значению ключа адреса хранения этой записи. Время поиска в таких таблицах минимально и определяется, в основном, временем вычисления функции f(Ki) .
В роли адреса табличного элемента может выступать его порядковый номер; индекс элемента массива, в котором хранится запись; номер записи файла, в которой размещается табличный элемент.
Табличная структура – это удобная, привычная и весьма распространенная форма представления данных. Таблицы широко используются в трансляторах операционных систем. В таких таблицах хранятся, например, символы входного языка и коды их внутреннего представления, идентификаторы переменных и адреса их хранения и т.п. На табличном представлении данных основаны реляционные базы данных.
5. Процессы обработки информации. Сортировка и поиск
Основные понятия сортировки
Многие задачи, связанные с обработкой и поиском информации, решаются быстрее и эффективнее, если данные хранятся в памяти в определенном порядке. Однако вопрос о необходимости упорядочивания данных должен решаться каждый раз применительно к конкретной задаче. При этом анализируются возможности ВЗУ, объем ОП, частота обращения к данным, частота их обновления, характер обработки и особенности данных.
В разных приложениях используются различные критерии упорядочивания. Данные могут упорядочиваться по значению вероятности обращения к ним, по частоте обращения, в хронологическом порядке. Процесс упорядочивания данных по возрастанию или убыванию значения критерия упорядочивания называется сортировкой.
Чаще всего бывает необходимо сортировать записи по возрастанию или убыванию значений ключа, причем ключ может быть простым или составным.
При решении многих задач необходимо обеспечить упорядочивание внутри упорядочивания. Например, все записи о студентах факультета могут быть упорядочены по номерам групп, а внутри каждой группы – в алфавитном порядке фамилий. В этом случае номер группы будет старшим ключом, а первая буква фамилии – младшим ключом.
В общем случае можно определить несколько уровней ключей, при этом старший ключ называют ключом первого ранга, а младшие ключи соответственно ключами второго, третьего и т.д. рангов. Сортировка в этом случае выполняется поэтапно. Вначале записи сортируются по ключу первого ранга. Затем записи, имеющие одинаковые значения этого ключа, сортируются по ключу второго ранга и т.д. Так, например, ключом первого ранга может являться первая буква фамилии, ключом второго ранга – вторая буква.
В процессе сортировки записи могут физически перемещаться в памяти так, что запись с меньшим ключом окажется расположенной перед записью с большим ключом. Это – физическое упорядочивание.
В ряде случаев бывает полезным так называемое логическоеупорядочивание. В этом случае создается дополнительная таблица, которая обеспечивает доступ к записям основного массива в соответствии с выбранным критерием упорядочивания. Так, например, можно создать вспомогательный вектор, значения элементов которого – это индексы элементов основного массива. При обработке данных сначала читается элемент вспомогательного вектора, затем следует обращение к соответствующему элементу основного массива. В этом случае нужный порядок обработки данных задается без физического перемещения записей основного массива в памяти.
Основные принципы сортировки
В ключевом поле могут храниться числовые или символьные данные. В зависимости от этого данные сортируются либо численным, либо алфавитно-цифровым способом. При численной сортировке сравниваются числовые значения ключа.
Если в поле ключа хранятся символьные данные, то в процессе сортировки сравниваются строки символов. В результате сортировки устанавливается лексикографический порядок следования записей. При сравнении символов сопоставляются двоичные коды их внутримашинного представления.
Сравнение строк символов производится в соответствии с определеннымиправилами. Пусть сравниваются две строки символов латинского алфавита: X1X2…Xm и Y1Y2…Yn , где X i и Y i - символы, каждому из которых соответствует определенный двоичный код. Первая строка будет считаться меньше второй строки в следующих случаях:
1. Если первая строка короче второй и все символы первой строки являются частью второй. Например, строка mask меньше строки masked.
2. Если очередной символ первой строки меньше соответствующего символа второй строки. Например, строка read меньше строки record, строка readied меньше строки recon, строка data меньше строки file.
Различные приложения могут использовать в качестве ключа различные поля записей. В этом случае потребуется сортировка по нескольким ключам.
Сортировка массива по нужному для данного приложения ключу может выполняться всякий раз перед началом обработки данных. По окончании обработки отсортированный массив уничтожается. В этом случае время сортировки входит в общее время обработки данных.
При другом подходе копии информационного массива, упорядоченные по различным ключам, постоянно хранятся в памяти. Такие массивы называются инвертированными. Большой расход памяти в этом случае окупается ускорением процесса обработки.
В зависимости от состава технических средств, используемых в процессе сортировки, различают внутреннюю и внешнюю сортировки. Сортировку называют внутренней, если весь упорядочиваемый массив целиком помещается в ОП и находится там в течение всего процесса сортировки. Внешняя сортировка производится в массивах данных, объем которых превышает свободный объем ОП. В этом случае исходный и отсортированный массивы размещаются на устройствах внешней памяти. В процессе сортировки отдельные части исходного массива по очереди передаются в ОП, где упорядочиваются одним из методов внутренней сортировки. Затем каждая из этих частей переписывается на ВЗУ. Этот процесс повторяется несколько раз. Полученные упорядоченные части затем объединяются. Операция объединения упорядоченных последовательностей данных, размещенных на ВЗУ, называется слиянием. Следовательно, внутренняя сортировка состоит из двух этапов: внутренней сортировки и слияния.
Существует много методов внутренней сортировки, каждый из которых имеет свои преимущества и недостатки. Оценка характеристик методов сортировки позволяет в каждом конкретном случае сделать наилучший выбор. Критериями оценки различных методов являются среднее число операций сравнения, выполняемых в процессе сортировки и число перестановок или обменов элементов. Эффективность сортировки определяется как частное от деления среднего числа сравнений на число элементов массива.
Процесс сортировки, производимый любым из методов, состоит из нескольких циклов. В каждом цикле просматривается вся последовательность, и выполняются определенные операции над ее элементами. Один цикл обработки называется проходом. В зависимости от выбранного метода для упорядочивания всего массива требуется то или иное количество проходов. Кроме того, различные методы сортировки требуют большего или меньшего объема ОП.
Литература
1. 002.05 (021) Т 761 И.П.Трофимова. Системы обработки и хранения информации. М. "Высшая школа", 1989
2. 1539 Линейные структуры данных. Метод. указания к лаб. работам.
Вопросы для самостоятельно проработки (указаныпараграфыучебника)
Сортировка методом выбора – п. 11.2.
Сортировка методом обмена – п. 11.2.
Сортировка методом вставок – п.11.2.
Сортировка методом подсчета (в отсутствии и при наличии одинаковых ключей) – п. 11.2, методичка.
Сортировка методом Шелла – п.11.2.
Внешняя сортировка – п.11.3.
Основные принципы информационного поиска
В запросе на поиск задается аргумент поиска. В том случае, когда надо найти запись об объекте, обладающем определенным свойством, т.е. запись с… Аргумент поиска может представлять собой перечень полей и их значений. В этом… В случае многоаспектного поиска аргумент поиска обычно представляет собой логическое выражение. Операндами формулы…Последовательный поиск - п.12.2.
Ускоренный последовательный поиск - п.12.3.
Двоичный поиск - п.12.3.
Блочный поиск – п.12.3.
Поиск по двоичному дереву - п.12.4.
– Конец работы –
Используемые теги: обычно, понятия, Данные, информация, считают, Син, мичными, необходимо, Однако, помнить, Что, эти, понятия, имеют, разный, смысл0.138
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Обычно понятия данные и информация считают синонимичными. Необходимо, однако, помнить, что эти понятия имеют разный смысл
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.186 сек.
Новости и инфо для студентов