Часть 2. Индексирование
Как отмечалось выше, определение ключа для таблицы означает автоматическую сортировку записей, контроль отсутствия повторений значений в ключевых полях записей и повышение скорости выполнения операций поиска в таблице.
Для реализации этих функций в СУБД применяют индексирование.
Термин «индекс» тесно связан с понятием «ключ», хотя между ними есть и некоторое отличие.
Под индексом понимают средство ускорения операции поиска записей в таблице, а следовательно, и других операций, использующих поиск: извлечение, модификация, сортировка и т. д.
Таблицу, для которой используется индекс, называют индексированной.
Можно сказать, что индекс выполняет роль оглавления таблицы, просмотр которого предшествует обращению к записям таблицы.
В некоторых системах, например, Paradox, индексы хранятся в индексных файлах, хранимых отдельно от табличных файлов.
Варианты решения проблемы организации физического доступа к информации зависят в основном от следующих факторов:
• вида содержимого в поле ключа записей индексного файла;
• типа используемых ссылок (указателей) на запись основной таблицы;
• метода поиска нужных записей.
В поле ключа индексного файла можно хранить значения ключевых полей индексируемой таблицы либо свертку ключа (так называемый хеш-код).
Преимущество хранения хеш-кода вместо значения состоит в том, что длина свертки независимо от длины исходного значения ключевого поля всегда имеет некоторую постоянную и достаточно малую величину (например, 4 байта), что существенно снижает время поисковых операций.
Недостатком хеширования является необходимость выполнения операции свертки (требует определенного времени), а также борьба с возникновением коллизий (свертка различных значений может дать одинаковый хеш-код).
Для организации ссылки на запись таблицы могут использоваться три типа адресов: абсолютный (действительный), относительный и символический (идентификатор).
На практике чаще всего используются два метода поиска: последовательный и бинарный (основан на делении интервала поиска пополам).
Проиллюстрируем организацию индексирования таблиц двумя схемами: одноуровневой и двухуровневой. При этом примем ряд предположений, обычно выполняемых в современных вычислительных системах. Пусть ОС поддерживает прямую организацию данных на магнитных дисках, основные таблицы и индексные файлы хранятся в отдельных файлах. Информация файлов хранится в виде совокупности блоков фиксированного размера, например целого числа кластеров.
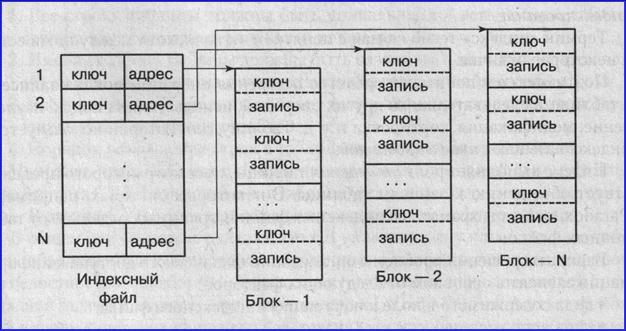 |
При одноуровневой схеме в индексном файле хранятся короткие записи, имеющие два поля: поле содержимого старшего ключа (хеш-кода ключа) адресуемого блока и поле адреса (физического адреса) начала этого блока (рис. 3).
Рис. 3. Одноуровневая схема индексации
В каждом блоке записи располагаются в порядке возрастания значения ключа или свертки. Старшим ключом каждого блока является ключ его последней записи.
Если в индексном файле хранятся хеш-коды ключевых полей индексированной таблицы, то алгоритм поиска нужной записи (с указанным ключом) в таблице включает в себя следующие три этапа:
1. Образование свертки значения ключевого поля искомой записи.
2. Поиск в индексном файле записи о блоке, значение первого поля которого больше полученной свертки (это гарантирует нахождение искомой свертки в этом блоке).
3. Последовательный просмотр записей блока до совпадения сверток искомой записи и записи блока файла. В случае коллизий сверток ищется запись, значение ключа которой совпадает со значением ключа искомой записи.
Основным недостатком одноуровневой схемы является то, что ключи (свертки) записей хранятся вместе с записями. Это приводит к увеличению времени поиска записей из-за большой длины просмотра (значения данных в записях приходится пропускать).
Двухуровневая схема в ряде случаев оказывается более рациональной, в ней ключи (свертки) записей отделены от содержимого записей (рис. 4).
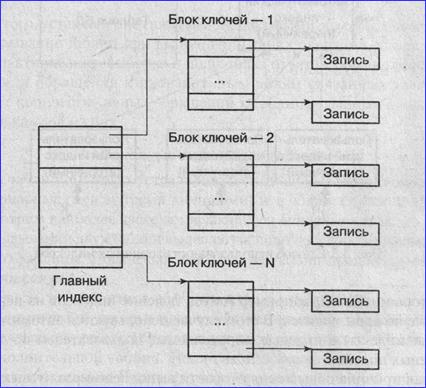 |
Рис. 4. Двухуровневая схема индексации
В этой схеме индекс основной таблицы распределен по совокупности файлов: одному файлу главного индекса и множеству файлов с блоками ключей.
Ключевые поля таблицы во многих СУБД, как правило, индексируются автоматически. На практике для создания индекса для некоторой таблицы БД пользователь указывает поле таблицы, которое требует индексации.
Индексные файлы, создаваемые по ключевым полям таблицы, часто называются файлами первичных индексов.
Индексы, создаваемые пользователем для не ключевых полей, иногда называют вторичными (пользовательскими) индексами.
Введение таких индексов не изменяет физического расположения записей таблицы, но влияет на последовательность просмотра записей. Индексные файлы, создаваемые для поддержания вторичных индексов таблицы, обычно называются файлами вторичных индексов.
Связь вторичного индекса с элементами данных базы может быть установлена различными способами. Один из них - использование вторичного индекса как входа для получения первичного ключа, по которому затем с использованием первичного индекса производится поиск необходимых записей (рис. 5).
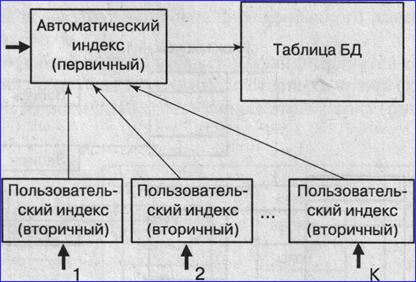 |
Рис. 5. Способ использования вторичных индексов
Некоторыми СУБД, например Access, деление индексов на первичные и вторичные не производится. В этом случае используются автоматически создаваемые индексы и индексы, определяемые пользователем по любому из не ключевых полей.
Главная причина повышения скорости выполнения различных операций в индексированных таблицах состоит в том, что основная часть работы про изводится с небольшими индексными файлами, а не с самими таблицами. Наибольший эффект повышения производительности работы с индексированными таблицами достигается для значительных по объему таблиц.
Индексирование требует небольшого дополнительного места на диске и незначительных затрат процессора на изменение индексов в процессе работы. Индексы в общем случае могут изменяться перед выполнением запросов к БД, после выполнения запросов к БД, по специальным командам пользователя или программным вызовам приложений.