Биномиальное распределение и измерение вероятностей - раздел Философия, МАТЕМАТИЧЕСКАЯ СТАТИСТИКА В Этой Теме Рассмотрим Основные Типы Распределения Дискретных Случайных Перем...
В этой теме рассмотрим основные типы распределения дискретных случайных переменных. Предположим, что вероятность наступления некоторого случайного события А при единичном испытании равно р. Производится серия испытаний в каждом из которых случайное событие А может наступить с этой вероятностью р, причем следует отметить, что испытания независимы друг от друга.
Примеры исчисления вероятностей можно обобщить на основе следующей ниже иллюстрации.
Если подбрасываются одновременно 2 монеты (а, b), то существуют 4 возможных случая выпадения герба Т и цифры Н:
аb аb аb аb
ТТ ТН НТ НН
В первом исходе имеем 2 герба. Принимая это за 2 благоприятных исхода, получим вероятность каждого из них р, а сложного события (ТТ) 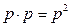 . В данном случае, при р = 1/2;
. В данном случае, при р = 1/2;
p2 = 1/4.
Четвертый из возможных исходов НН представляет 2 неблагоприятных исхода с вероятностью q × q = q2 = 1/4.
Каждый из двух других исходов является комбинацией одного благоприятного и одного неблагоприятного случаев.
Вероятность каждого из этих исходов равна p × q = 1/2 × 1/2 =1/4, а обоих вместе ТН и НТ равна их сумме, т. е. 2 р × q = 1/2.
Обобщенным выражением процесса получения вероятностей различных сочетаний независимых событий, когда вероятности их известны, являются последовательные члены разложения бинома.
Для рассматриваемого примера из двух событий имеем:
(р +q)2 = p2 + 2pq + q2. , При p = 1/2 получим (1/2 + 1/2)2 = 1/4+1/2+1/4.
Если 3 монеты а, b, с подбрасываются одновременно, получим 8 возможных комбинаций:
abс abc abc abc abc abc abc abc
ТТТ ТТН ТНН ТНТ НТТ НТН ННТ ННН
Вероятность выпадения 3 гербов составит 1/8, 2 гербов (в сочетании с одним случаем цифры) равна 3/8, одного герба и 2 цифр – 3/8, ни одного герба – 1/8. При 3 независимых событиях степень бинома равна 3.
Вероятности отдельных возможных исходов даются последовательными членами разложения:
(р + q)3 = p3 + 3p2q + 3pq2 + q3.
При p = q = 1/2 имеем (1/2 + 1/2)3 = 1/8 + 3/8 + 3/8 + 1/8, т. e. то же, что и непосредственным подсчетом.
Если число независимых случайных событий n, то вероятность n, n–1, n–2 и т. д. благоприятных исходов равна последовательным членам разложения:
(р + q)n
Если желаем получить вероятные численности разных исходов при данном числе испытаний n, применяем выражение:
N × (p+q)n
Например, при числе испытаний N = 200 и двух независимых событиях n в каждом испытании вероятные численности будут равны 200×(p+q)2 = 200×(р2+2р×q+q2). Если p = q = 1/2, имеем последовательные вероятные численности: 50 + 100 + 50.
При подбрасывании монеты 200 раз (N = 200) выпадения герба следует ожидать в 50 случаях, герба или цифры – в 100 случаях и цифры – 50 случаях.
При тех же р и N, но n = 3 получим последовательные вероятные численности: 25 + 75 + 75 + 25, которые означают 3, 2, 1 наступление события и ненаступление его, причем сумма всех численностей равна N.
При 200 бросаниях трех монет ожидаем в 25 случаях выпадения 3 гербов (ТТТ), в 75 случаях выпадения 2 гербов и одной цифры (ТТН), в 75 случаях выпадения 2 цифр и одного герба (ННТ) и в 25 случаях – 3 цифр.
Итак, когда вероятности независимых событий известны априори, то можно определить вероятные численности любого данного числа n, n–1, n–2.... наступления события и ненаступления его. При этом неважно, равны или не равны р и q, лишь бы они оставались при испытаниях постоянными. Этот факт имеет большое значение в теории статистики.
При изучении природных явлений выделение элементарных событий и вообще расчленения причинного процесса, в результате которого происходят случайные события, обычно невозможно. Классический подход к определению вероятности здесь бессилен. Проблему определения вероятностей таких событий решают на основе статистического подхода.
Однако классический подход к определению вероятностей событий лежит в основе теории анализа случайных событий и теоретических (модельных) распределений исходов испытаний. В свою очередь теория математического анализа случайных событий и модели распределений исходов испытаний являются базой статистических методов, в частности, базой статистических заключений.
Альтернативные, дискретно варьирующие признаки, как было показано выше, распределяются так, что вероятные численности их появления могут быть найдены по формуле бинома Ньютона:
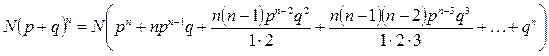 (3.1)
(3.1)
где n – число независимых исходов в одном испытании; р – вероятность благоприятного исхода одного случая; q – вероятность неблагоприятного исхода; N – общее число испытаний (исходов).
При n = 6 возможны 26 = 64 исходов. При равной вероятности альтернатив, т. е. при условии р = q = 0,5, получим следующий ряд вероятных численностей:
64(0,5 + 0,5)6 = 64 [1/64 + 6/64 + 15/64 + 20/64 + 15/64 + 6/64 + 1/64] = 1+6+15 + 20 + 15 + 6+1
Откладывая значения числа наступления благоприятных исходов m по оси абсцисс, а значения вероятных численностей – по оси ординат, получим многоугольник численностей распределения (рисунок 3.1). Ломаная линия, соединяющая точки на графике, называется кривой распределения.
Найденные по формуле бинома численности или биномиальные коэффициенты (при p = q = 0,5) можно получить также при помощи треугольника Паскаля (таблица 3.1). Числовые значения коэффициентов построены так, что любой из них получается суммированием двух стоящих над ним строкой выше значений, справа и слева.
Значения коэффициентов, начиная с единицы, закономерно возрастают до определенного уровня, а затем в той же последовательности уменьшаются. Кривые, изображающие биномиальные распределения с р = q = 0,5, симметричны. При любой степени бинома п число коэффициентов равно n+1, например при
n = 1 оно равно 2 и т. д. Сумма биномиальных коэффициентов равна 2n, как в нашем примере, n = 6; N = 26 = 64.
Если р и q не равны, распределение будет асимметрично, причем тем в большей степени, чем меньше n. При большом n, например 30 и более, оно симметрично и малоступенчато. Характер распределения остается тем же, независимо от того, выражено оно в значениях вероятности или в значениях частоты m ожидаемого события.
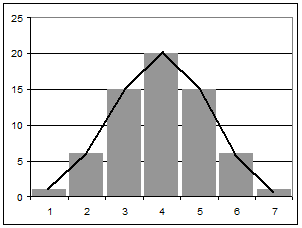
Рисунок 3. 1 – Кривая распределения
Таблица 3.1 – Треугольник Паскаля
| n
| Биномиальные коэффициенты
| N=2n
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Для вычисления вероятностей у события (появиться m раз в n независимых испытаний) наряду с формулой бинома применяют также формулу Якоба Бернулли:
 (3.2)
(3.2)
Здесь 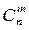 – число сочетаний из n элементов по m, или биномиальный коэффициент;
– число сочетаний из n элементов по m, или биномиальный коэффициент;
р – вероятность ожидаемого события (благоприятного исхода);
q = 1 – р – вероятность противоположного события; m – частота появления ожидаемого события; n –число испытаний; n! и m! –факториалы, т. е.: 1×2×3×...×n и 1×2×3×...×m.
Совокупность вероятностей при m = 1, 2, 3, ...n называется биномиальным распределением вероятностей.
Так, для предыдущего примера, при p = q = 0,5, n = 6 и
m = 0, 1, 2, ..., 6 вероятности будут:
m = 0 
m = 1 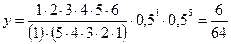
m = 2 
при m = 3, 4, 5, 6 вероятности соответственно будут равны:
20/64; 15/64; 6/64; 6/64 т. е. такие, какие получены по формуле бинома.
Биномиальное распределение определяется двумя параметрами: средней величиной μ = np и дисперсией 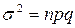 или квадратическим отклонением
или квадратическим отклонением 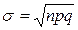 .
.
Для рассматриваемого примера имеем среднюю частоту ожидаемого случайного события m = nр = 6 – 0,5 = 3 и дисперсию
s2 = npq = 6 × 0,5 × 0,5 = 1,5.
Все темы данного раздела:
УЧЕБНОЕ ПОСОБИЕ
для студентов вузов, обучающихся по специальности 1-31 01 01 «Биология»
Гомель 2010
Предмет и метод математической статистики
Предмет математической статистики – изучение свойств массовых явлений в биологии, экономике, технике и других областях. Эти явления обычно представляются сложными, вследствие разнообразия (варьиров
Понятие случайного события
Статистическая индукция или статистические заключения, как главная составная часть метода исследования массовых явлений, имеют свои отличительные черты. Статистические заключения делают с численно
Вероятность случайного события
Числовая характеристика случайного события, обладающая тем свойством, что для любой достаточно большой серии испытаний частота события лишь незначительно отличается от этой характеристики, называет
Вычисление вероятностей
Часто возникает необходимость одновременно складывать и умножать вероятности. Например, требуется определить вероятность выпадения 5 очков при одновременном бросании 2 кубиков. Искомая сумма вероят
Понятие случайной переменной
Определив понятие вероятности и выяснив ее главные свойства, перейдем к рассмотрению одного из важнейших понятий теории вероятностей – понятия случайной переменной.
Допустим, что в результ
Дискретные случайные переменные
Случайная переменная дискретна, если совокупность возможных ее значений конечна, или, по крайней мере, поддается счислению. Предположим, что случайная переменная X может принимать значения x1
Непрерывные случайные переменные
В противоположность дискретным случайным переменным, рассмотренным в предыдущем подразделе, совокупность возможных значений непрерывной случайной переменной не только не конечна, но и не поддается
Математическое ожидание и дисперсия
Часто возникает необходимость охарактеризовать распределение случайной переменной с помощью одного–двух числовых показателей, выражающих наиболее существенные свойства этого распределения. К таким
Моменты
Большое значение в математической статистике имеют так называемые моменты распределения случайной переменной. В математическом ожидании большие значения случайной величины учитываются недостаточно.
Прямоугольное (равномерное) распределение
Прямоугольное (равномерное) распределение — простейший тип непрерывных распределений. Если случайная переменная X может принимать любое действительное значение в интервале (а, b), где а и b – дейст
Нормальное распределение
Нормальное распределение играет основную роль в математической статистике. Это ни в малейшей степени не является случайным: в объективной действительности весьма часто встречаются различные признак
Логарифмически нормальное распределение
Случайная переменная Y имеет логарифмически нормальное распределение с параметрами μ и σ, если случайная переменная X = lnY имеет нормальное распределение с теми же параметрами μ и &
Средние величины
Из всех групповых свойств наибольшее теоретическое и практическое значение имеет средний уровень, измеряемый средней величиной признака.
Средняя величина признака – понятие очень глубокое,
Общие свойства средних величин
Для правильного использования средних величин необходимо знать свойства этих показателей: срединное расположение, абстрактность и единство суммарного действия.
По своему численному значени
Средняя арифметическая
Средняя арифметическая, обладая общими свойствами средних величин, имеет свои особенности, которые можно выразить следующими формулами:
Средний ранг (непараметрическая средняя)
Средний ранг определяется для таких признаков, для которых еще не найдены способы количественного измерения. По степени проявления таких признаков объекты могут быть ранжированы, т. е. расположены
Взвешенная средняя арифметическая
Обычно, чтобы рассчитать среднюю арифметическую, складывают все значения признака и полученную сумму делят на число вариантов. В этом случае каждое значение, входя в сумму, увеличивает ее на полную
Средняя квадратическая
Средняя квадратическая вычисляется по формуле:
, (6.5)
Она равна корню квадратному из суммы
Медиана
Медианой называют такое значение признака, которое разделяет всю группу на две равные части: одна часть имеет значения признака меньшее, чем медиана, а другая – большее.
Например, если име
Средняя геометрическая
Чтобы получить среднюю геометрическую для группы с n данными, нужно все варианты перемножить и из полученного произведения извлечь корень n-й степени:
Средняя гармоническая
Средняя гармоническая рассчитывается по формуле
. (6.14)
Для пяти вариантов: 1, 4, 5, 5 сре
Число степеней свободы
Число степеней свободы равно числу элементов свободного разнообразия в группе. Оно равно числу всех имеющихся элементов изучения без числа ограничений разнообразия.
Например, для исследова
Коэффициент вариации
Стандартное отклонение – величина именованная, выраженная в тех же единицах измерения, как и средняя арифметическая.
Поэтому для сравнения разных признаков, выраженных в разных единицах из
Лимиты и размах
Для быстрой и примерной оценки степени разнообразия часто применяются простейшие показатели:
lim = {min ¸ max} – лимиты, т. е. наименьшее и наибольшее значения признака,
p =
Нормированное отклонение
Обычно степень развития признака определяется путем его измерения и выражается определенным именованным числом: 3 кг веса, 15 см длины, 20 зацепок на крыле у пчел, 4% жира в молоке, 15 кг настрига
Средняя и сигма суммарной группы
Иногда бывает необходимо определить среднюю и сигму для суммарного распределения, составленного из нескольких распределений. При этом известны не сами распределения, а только их средние и сигмы.
Скошенность (асимметрия) и крутизна (эксцесс) кривой распределения
Для больших выборок (n > 100) вычисляют еще два статистических показателя.
Скошенность кривой называется асимметрией:
Вариационный ряд
По мере увеличения численности изучаемых групп все более и более проявляется та закономерность в разнообразии, которая в малочисленных группах была скрыта случайной формой своего проявления.
Гистограмма и вариационная кривая
Гистограмма – это вариационный ряд, представленный в виде диаграммы, в которой различная величина частот изображается различной высотой столбиков. Гистограмма распределения данных представлена на р
Достоверность различия распределений
Статистическая гипотеза – это определённое предположение о распределении вероятностей, лежащем в основе наблюдаемой выборки данных.
Проверка статистической гипотезы – это процесс принятия
Критерий по асимметрии и эксцессу
Некоторые признаки растений, животных и микроорганизмов при объединении объектов в группы дают распределения, значительно отличающиеся от нормального.
В тех случаях, когда какие-нибудь при
Генеральная совокупность и выборка
Весь массив особей определенной категории называется генеральной совокупностью. Объем генеральной совокупности определяется задачами исследования.
Если изучается какой-нибудь вид диких жив
Репрезентативность
Непосредственное изучение группы отобранных объектов дает, прежде всего, первичный материал и характеристику самой выборки.
Все выборочные данные и сводные показатели имеют значение в каче
Ошибки репрезентативности и другие ошибки исследований
Оценка генеральных параметров по выборочным показателям имеет свои особенности.
Часть никогда не может полностью охарактеризовать все целое, поэтому характеристика генеральной совокупности
Доверительные границы
Определять величину ошибок репрезентативности необходимо для того, чтобы выборочные показатели использовать еще и для нахождения возможных значений генеральных параметров. Этот процесс называется о
Общий порядок оценки
Три величины, необходимые для оценки генерального параметра, – выборочный показатель (), критерий надежности
Оценка средней арифметической
Оценка средней величины имеет целью установить величину генеральной средней для изученной категории объектов. Требуемая для этой цели ошибка репрезентативности определяется по формуле:
Оценка средней разности
В некоторых исследованиях в качестве первичных данных берется разность двух измерений. Это может быть в случае, когда каждая особь выборки изучается в двух состояниях – или в разном возрасте, или п
Недостоверная и достоверная оценка средней разности
Такие результаты выборочных исследований, по которым нельзя получить никакой определенной оценки генерального параметра (или он больше нуля, или меньше, или равен нулю), называются недостоверными.
Оценка разности генеральных средних
В биологических исследованиях особое значение имеет разность двух величин. По разности ведется сравнение разных популяций, рас, пород, сортов, линий, семейств, опытных и контрольных групп (метод гр
Критерий достоверности разности
При том большом значении, которое имеет для исследователей получение достоверных разностей, появляется необходимость овладеть методами, позволяющими определить – достоверна ли полученная, реально с
Репрезентативность при изучении качественных признаков
Качественные признаки обычно не могут иметь градаций проявления: они или имеются, или не имеются у каждой из особей, например пол, комолость, наличие или отсутствие каких-нибудь особенностей, уродс
Достоверность разности долей
Достоверность разности выборочных долей определяется так же, как и для разности средних:
(10.34)
Коэффициент корреляции
Во многих исследованиях требуется изучить несколько признаков в их взаимной связи. Если вести такое исследование по отношению к двум признакам, то можно заметить, что изменчивость одного признака н
Ошибка коэффициента корреляции
Как и всякая выборочная величина, коэффициент корреляции имеет свою ошибку репрезентативности, вычисляемую для больших выборок по формуле:
Достоверность выборочного коэффициента корреляции
Критерий выборочного коэффициента корреляции определяется по формуле:
(11.9)
где:
Доверительные границы коэффициента корреляции
Доверительные границы генерального значения коэффициента корреляции находятся общим способом по формуле:
Достоверность разности двух коэффициентов корреляции
Достоверность разности коэффициентов корреляции определяется так же, как и достоверность разности средних, по обычной формуле
Уравнение прямолинейной регрессии
Прямолинейная корреляция отличается тем, что при этой форме связи каждому из одинаковых изменений первого признака соответствует вполне определенное и тоже одинаковое в среднем изменение другого пр
Ошибки элементов уравнения прямолинейной регрессии
В уравнении простой прямолинейной регрессии:
у = а + bх
возникают три ошибки репрезентативности.
1 Ошибка коэффициента регрессии:
Частный коэффициент корреляции
Частный коэффициент корреляции – это показатель, измеряющий степень сопряженности двух признаков при постоянном значении третьего.
Математическая статистика позволяет установить корреляцию
Множественный коэффициент корреляции
Множественный коэффициент корреляции трех переменных – это показатель тесноты линейной связи между одним из признаков (буква индекса перед тире) и совокупностью двух других признаков (буквы индекса
Линейное уравнение множественной регрессии
Математическое уравнение для прямолинейной зависимости между тремя переменными называется множественным линейным уравнением плоскости регрессии. Оно имеет следующий общий вид:
Корреляционное отношение
Если связь между изучаемыми явлениями существенно отклоняется от линейной, что легко установить по графику, то коэффициент корреляции непригоден в качестве меры связи. Он может указать на отсутстви
Свойства корреляционного отношения
Корреляционное отношение измеряет степень корреляции при любой ее форме.
Кроме того, корреляционное отношение обладает рядом других свойств, представляющих большой интерес в статистическом
Ошибка репрезентативности корреляционного отношения
Еще не разработано точной формулы ошибки репрезентативности корреляционного отношения. Обычно приводимая в учебниках формула имеет недостатки, которыми не всегда можно пренебречь. Эта формула не уч
Критерий линейности корреляции
Для определения степени приближения криволинейной зависимости к прямолинейной используется критерий F, вычисляемый по формуле:
Дисперсионный комплекс
Дисперсионный комплекс – это совокупность градаций с привлеченными для исследования данными и средними из данных по каждой градации (частные средние) и по всему комплексу (общая средняя).
Статистические влияния
Статистическое влияние – это отражение в разнообразии результативного признака того разнообразия фактора (его градаций), которое организовано в исследовании.
Для оценки влияния фактора нео
Факториальное влияние
Факториальное влияние – это простое или комбинированное статистическое влияние изучаемых факторов.
В однофакторных комплексах изучается простое влияние одного фактора при определенных орга
Однофакторный дисперсионный комплекс
Дисперсионный анализ разработан и введен в практику сельскохозяйственных и биологических исследований английским ученым Р. А. Фишером, который открыл закон распределения отношения средних квадратов
Многофакторный дисперсионный комплекс
Ясное представление о математической модели дисперсионного анализа облегчает понимание необходимых вычислительных операций, особенно при обработке данных многофакторных опытов, в которых больше ист
Преобразования
Правильное использование дисперсионного анализа для обработки экспериментального материала предполагает однородность дисперсий по вариантам (выборкам), нормальное или близкое к нему распределение в
Показатели силы влияний
Определение силы влияний по их результатам требуется в биологии, сельском хозяйстве, медицине для выбора наиболее эффективных средств воздействия, для дозировки физических и химических агентов – ст
Ошибка репрезентативности основного показателя силы влияния
Точная формула ошибки основного показателя силы влияния еще не найдена.
В однофакторных комплексах, когда ошибка репрезентативности определяется только для одного показателя факториального
Предельные значения показателей силы влияния
Основной показатель силы влияния равен доле одного слагаемого от всей суммы слагаемых. Кроме того, этот показатель равен квадрату корреляционного отношения. По этим двум причинам показатель силы вл
Достоверность влияний
Основной показатель силы влияния, полученный в выборочном исследовании, характеризует, прежде всего, ту степень влияния, которая реально, в действительности, проявилась в группе исследованных объек
Дискриминантный анализ
Дискриминантный анализ является одним из методов многомерного статистического анализа. Цель дискриминантного анализа состоит в том, чтобы на основе измерения различных характеристик (признаков, пар
Постановка задачи, методы решения, ограничения
Предположим, имеется n объектов с m характеристиками. В результате измерений каждый объект характеризуется вектором x1 ... xm, m >1. Задача состоит в том, что
Предположения и ограничения
Дискриминантный анализ «работает» при выполнении ряда предположений.
Предположение о том, что наблюдаемые величины – измеряемые характеристики объекта – имеют нормальное распределение. Это
Алгоритм дискриминантного анализа
Решение задач дискриминации (дискриминантный анализ) состоит в разбиении всего выборочного пространства (множества реализации всех рассматриваемых многомерных случайных величин) на некоторое число
Кластерный анализ
Кластерный анализ объединяет различные процедуры, используемые для проведения классификации. В результате применения этих процедур исходная совокупность объектов разделяется на кластеры или группы
Методы кластерного анализа
В практике обычно реализуются агломеративные методы кластеризации.
Обычно перед началом классификации данные стандартизуются (вычитается среднее и производится деление на корень квадратный
Алгоритм кластерного анализа
Кластерный анализ – это совокупность методов классификации многомерных наблюдений или объектов, основанных на определении понятия расстояния между объектами с последующим выделением из них групп, &







Новости и инфо для студентов