рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Философия
- /
- Моделі створення і функціонування потоків
Реферат Курсовая Конспект
Моделі створення і функціонування потоків
Моделі створення і функціонування потоків - раздел Философия, Лекція 6 Розбиття програм на множину потоків Мета Потоку – Виконати Певну Роботу Від Імені Процесу. Якщо Процес Містить Де...
Мета потоку – виконати певну роботу від імені процесу. Якщо процес містить декілька потоків, кожен потік виконує деякі підзадачі як частини загальної задачі, що виконується процесом. Потокам делегується робота у відповідності до конкретної стратегії, що визначає, яким чином реалізується делегування роботи. Якщо додаток моделює деяку процедуру або об’єкт, то вибрана стратегія повинна відображати цю модель. Використовуються наступні розповсюджені моделі:
· делегування (²керуючий-робочий²);
· мережа з рівноправними вузлами;
· конвеєр;
· ²виробник-споживач².
Кожна модель характеризується власною декомпозицією робіт (Work Breakdown Structure – WBS), яка визначає, хто відповідає за створення потоків і при яких умовах вони створюються. Наприклад, існує централізований підхід, при якому один потік створює інші потоки і кожному з них делегує деяку роботу. Існує також конвеєрний (assembly-line) підхід, при якому на різних етапах потоки виконують різну роботу. Створені потоки можуть виконувати одну і ту ж задачу на різних колекціях даних, різні задачі на одній і тій же колекції даних або різні задачі на різних колекціях даних. Потоки поділяються на категорії за виконанням задач тільки певного типу. Наприклад, можна створити групу потоків, які будуть виконувати тільки обчислення, тільки ввід або тільки вивід.
Можливі задачі, для успішного рішення яких необхідно комбінувати подані вище моделі. В попередніх лекціях розглянули процес візуалізації. Задачі 1, 2 та 3 виконувалися послідовно, а задачі 4, 5 та 6 могли виконуватися паралельно. Всі задачі можливо виконувати різними потоками. Якщо необхідно відобразити декілька зображень, потоки 1, 2 і 3 можуть реалізувати конвеєр. По завершенню потоку 1 зображення передається потоку 2, в той час потік 1 може виконувати свою роботу над наступним зображенням. Після буферизації зображень потоки 4, 5 і 6 можуть реалізувати паралельну обробку. Модель функціонування потоків являє собою частину структурування паралелізму в додатку, в якому кожен потік може виконуватися на окремому процесорі. Модель функціонування потоків (та їх короткий опис) подано в табл. 4.
| Таблиця 4. Моделі функціонування потоків | |
| Модель | Опис |
| Модель делегування | Центральний потік (²керуючий²) створює потоки (²робочі²), призначає кожному з них задачу. Керуючий потік може очікувати до тих пір, доки всі потоки не завершіть виконання своїх задач |
| Модель рівноправних вузлів | Всі потоки мають однаковий робочий статус. Такі потоки називаються рівноправними. Потік створює всі потоки, необхідні для виконання задач, але не реалізує ніякого делегування відповідальності. Рівноправні потоки можуть опрацьовувати запити від одного вхідного потоку даних, що поділяється всіма потоками, або кожен потік може мати власний вхідний потік даних |
| Конвеєр | Конвеєрний потік застосовується для поетапної обробки потоку вхідних даних. Кожний етап – це потік, який виконує роботу на деякій сукупності вхідних даних. Коли дана сукупність пройде всі етапи, обробка всього потоку даних буде завершена |
| Модель ²виробник-споживач² | Потік ²виробник² готує дані , що споживаються потоком ²споживачем². Дані зберігаються в блоці пам’яті, що поділяється потоком – ²виробником² і ²споживачем² |
3.1. Модель делегування
В моделі делегування один потік (²керуючий²) створює потоки (²робочі²) і призначає кожному з них задачу. Керуючому потоку необхідно очікувати до тих пір, доки всі потоки не завершать виконання своїх задач. Керуючий потік делегує задачу, яку кожен робочий потік повинен виконати, шляхом задання деякої функції. Разом із задачею на робочий потік лягає і відповідальність за її виконання та отримання результатів. Крім того, на етапі отримання результатів 
можлива синхронізація з керуючим (або іншим) потоком.
Керуючий потік може створювати робочі потоки в результаті запитів, поданих до системи. При цьому обробка запиту кожного типу може бути делегована робочому потоку. В цьому випадку керуючий потік виконує деякий цикл подій. При виникненні подій робочі потоки створюються і на них накладаються певні обов’язки. Для кожного нового запиту, що надійшов до системи, створюється новий потік. При використанні такого підходу процес може перевищити граничний об’єм виділених йому ресурсів або граничну кількість потоків. В якості альтернативного варіанту керуючий потік може реалізувати пул потоків, яким будуть пере призначатися нові запити. Керуючий потік створює під час ініціалізації деяку кількість потоків, а потім кожний потік призупиняється до тих пір, доки не буде додано запит в їх чергу. При розміщенні запитів в чергу керуючий потік сигналізує робочому про необхідність обробки запиту. Як тільки потік вирішує свою задачу, він дістає з черги наступний запит. Якщо в черзі більше немає доступних запитів, потік призупиняється до тих пір, доки керуючий потік не подасть повідомлення йому про надходження чергового завдання в чергу. Якщо всі робочі потоки повинні поділяти одну чергу, то їх можна запрограмувати на обробку запитів тільки одного типу. Якщо тип запиту в черзі не співпадає з типом запитів, на обробку яких орієнтований потік, то він може знову призупинитися. Головна мета керуючого потоку – створити всі потоки, розмістити завдання в чергу і ²розбудити² робочі потоки, коли ці завдання стануть доступними. Робочі потоки виясняють про наявність запиту в черзі, виконують призначену роботу та призупиняються самі, якщо для них немає більше роботи. Всі робочі та керуючий потік виконуються паралельно. Описані два підходи до реалізації моделі делегування подано для порівняння на рис. 6.
3.2. Модель з рівноправними вузлами
Якщо в моделі делегування є керуючий потік, якій делегує задачі робочим потокам, то в моделі з рівноправними вузлами всі потоки мають однаковий робочий статус. Не дивлячись на існування одного потоку, який первісно створює всі потоки, необхідні для виконання всіх задач, цей потік вважається робочим, але він не виконує ніяких функцій по делегуванню задач. В даній моделі немає ніякого централізованого потоку, але на робочі потоки покладена велика відповідальність. Всі рівноправні потоки можуть опрацьовувати запити з одного вхідного потоку даних, або кожен робочий потік може мати власний вхідний потік даних, за який він відповідає. Вхідний потік даних може також зберігатися у файлі даних або базі даних. Робочі потоки можуть потребувати взаємо
дії і розподілу ресурсів. Модель рівноправних потоків подано на рис. 7.
3.3. Модель конвеєра
Модель конвеєра подібна стрічці складального конвеєра в тому, що вона передбачає наявність потоку елементів, які опрацьовуються поетапно. На кожному етапі окремий потік виконує деякі операції над певною сукупністю вхідних даних. Коли ця сукупність даних пройде всі етапи, обробка всього вхідного потоку даних буде завершено. Такий підхід дозволяє опрацьовувати декілька вхідних потоків одночасно. Кожен потік відповідає за отримання проміжних результатів, роблячи їх доступними для наступного етапу (або наступного потоку) конвеєра. Останній етап (або потік) генерує результати роботи конвеєра в цілому.

Поступово, як вхідні дані проходять по конвеєру, не виключено, що на деякому етапі їх порції будуть буферизовані на певних етапах, доки потоки ще займаються обробкою попередніх порцій. Це може викликати сповільнення конвеєра, якщо виявиться, що обробка даних на якомусь етапі відбувається повільніше, ніж на інших. При цьому виникає відставання в роботі. Щоб запобігти відставання, можна для ²сповільненої² ланки створити додаткові потоки. Всі етапи конвеєра повинні бути зрівноважені за часом, щоб ні один етап не займав більше часу, ніж інші. Для цього необхідно всю роботу розподілити по конвеєру рівномірно. Чим більше етапів в конвеєра, тим більше створюється потоків обробки. Збільшення кількості потоків також може сприяти запобіганню відставання в роботі. Модель конвеєра подано на рис. 8.
3.4. Модель ²виробник-споживач²
В моделі ²виробник-споживач² існує потік-²виробник², який готовить дані, що споживаються потоком-²споживачем². Дані зберігаються в блоці пам’яті, який поділяється потоками ²виробник² та ²споживач². Потік-²виробник² повинен спочатку приготувати дані, які в подальшому потік-²споживач² отримає. Такому процесу необхідна синхронізація. Якщо потік-²виробник² будо поставляти дані значно швидше, ніж потік-²споживач² встигає їх опрацьовувати, то потік-²виробник² декілька раз перезапише результати своєї роботи, перш ніж потік-²споживач² встигне їх опрацювати. Але, якщо потік-²споживач² буде приймати дані значно швидше, ніж потік-²виробник² зможе їх надавати, то потік-²споживач² буде або знову опрацьовувати вже оброблені дані, або спробує прийняти ще не підготовлені дані. Модель ²виробник-споживач² подано на 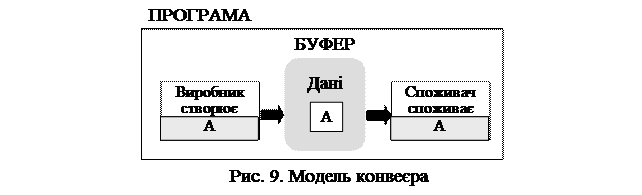
рис. 9.
3.5. Моделі SPMD і MPMD для потоків
В кожній з описаних вище моделей потоки знову і знову виконують одну і ту ж задачу на різних колекціях даних або їм призначаються різні задачі для виконання на різних колекціях даних. Ці потокові моделі використовують схеми SPMD (Single-Program, Multiple-Data – одна програма, декілька потоків даних) і MPMD (Multiple-Program, Multiple-Data – множина програм, множина потоків даних). Ці схеми подають моделі паралелізму, які ділять програми на потоки інструкцій і даних. Їх можна використовувати для опису типу роботи, яку реалізують потокові моделі з використанням паралелізму. В контексті нашого викладу матеріалу модель MPMD краще подати, як MТMD (Multiple-Thread, Multiple-Data – множина програм, множина потоків даних). Ці моделі описують систему з різними потоками виконання (thread), які обробляють різні колекції даних, або потоки даних (stream). Аналогічно модель SPMD краще розглядати як модель SТMD (Single-Thread, Multiple-Data – одна потік виконання, декілька потоків даних). Дана модель описує систему з одним потоком виконання, який опрацьовує різні колекції, або потоки, даних. Це означає, що різні колекції даних обробляються декількома ідентичними потоками виконання (викликаючи одну і ту ж підпрограму).
Як модель делегування, так і модель рівноправних потоків можуть використовувати моделі паралелізму SТMD і MТMD. Як було описано вище, пул потоків може використовувати різні підпрограми для обробки різних колекцій даних. Така поведінка відповідає моделі MТMD. Пул потоків може бути також налаштований на виконання однієї і тієї ж підпрограми. Запити (або завдання), що посилаються системі, можуть являти собою різні колекції даних, а не різні задачі. І в цьому випадку поведінка множини потоків, що реалізують одні і ті ж інструкції, але на різних колекціях даних, відповідає моделі SТMD. Модель рівноправних потоків може бути реалізована у вигляді потоків, що виконують однакові або різні задачі. Кожен потік виконання може мати свій власний потік даних або декілька файлів з даними, призначеними для обробки кожним потоком. В моделі конвеєра використовується MТMD-модель паралелізму. На різних етапах виконуються різні види обробки, тому в довільний момент часу різні сукупності вхідних даних будуть знаходитися на різних етапах виконання. Модельне подання конвеєра було б марним, якби на кожному етапі виконува
лась одна і таж обробка. Моделі паралелізму SТMD і MТMD подано на рис. 10.
– Конец работы –
Эта тема принадлежит разделу:
Лекція 6 Розбиття програм на множину потоків
На сайте allrefs.net читайте: Лекція_6.
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Моделі створення і функціонування потоків
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.031 сек.
Новости и инфо для студентов