рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Философия
- /
- Тамбов 2010
Реферат Курсовая Конспект
Тамбов 2010
Тамбов 2010 - раздел Философия, Дисциплина Теория информации Тема №4: Оптимальное эффективное кодирование источников Тема №4: Оптимальное (Эффективное) Кодирование Источников....
Тема №4: Оптимальное (эффективное) кодирование источников.
4.1. Понятие кодирования. Кодовое дерево.
В процессе кодирования каждая буква исходного алфавита представляется различными последовательностями, состоящими из кодовых букв (цифр). Если исходный алфавит содержит m букв, то для построения равномерного кода с использованием D кодовых букв необходимо обеспечить выполнение следующего условия:
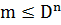 ,
,
где n- количество элементов кодовой последовательности.
Для построения равномерного кода достаточно пронумеровать буквы исходного алфавита и записать их коды как n-разрядное число в D-ичной системе счисления.
Заметим: понятие равномерного кода означает, что каждая буква исходного алфавита m кодируется кодовой последовательностью одинаковой длины n.
Пример: код длины n=S в двоичной системе счисления D=2 позволяет представить 32 буквы русского алфавита пятиразрядными двоичными числами.
Очевидно, что при различной вероятности появления букв исходного алфавита равномерный код является избыточным, так как энтропия, характеризующая информационную емкость сообщения максимальна при равновероятных буквах исходного алфавита:
 .
.
Т.е. информационные возможности кода используются не полностью.
Пример: Для двоичного пятиразрядного кода букв русского алфавита информационная емкость составляет  5 бит,
5 бит, 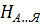 =4,35 бит.
=4,35 бит.
Устранение избыточности достигается применением неравномерных кодов, в которых буквы, имеющие наибольшую вероятность, кодируются более короткими кодовыми последовательностями, а более длинные комбинации присваиваются редким, имеющим меньшую вероятность буквам.
Если i-ая буква, вероятность которой pi, получает кодовую комбинацию длины ni, то средняя длинна кода (кодового слова) равна:

Введем понятие кодового дерева, которым часто пользуются при рассмотрении кодов.
Известно, что любую букву (событие), содержащиеся в алфавите (сообщении) источника, можно разложить на последовательности двоичных решений с исходами «да»=1 и «нет»=0 без потери информации.
Таким образом, каждой букве исходного алфавита может быть поставлена в соответствие (приписана) некоторая последовательность двоичных символов – «0» или «1», а такую последовательность называют кодовым словом. При этом потери информации не происходит, так как каждое событие может быть восстановлено по соответствующему кодовому слову.

C1,C2, C3,C4 – дерево кодов имеет разную длину кода (кодового слова).
– Конец работы –
Эта тема принадлежит разделу:
Дисциплина Теория информации Тема №4: Оптимальное эффективное кодирование источников
Тамбовский государственный технический университет... Кафедра Информационные системы... Дисциплина Теория информации...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Тамбов 2010
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.017 сек.
Новости и инфо для студентов