Метод кодирования Шеннона - Фано.
Буквы исходного алфавита записываются в порядке убывающей вероятности. Упорядоченное таким образом множество букв разбивается так, чтобы суммарные вероятности двух подмножеств были примерно равными. Всем буквам верхней половины в качестве первого символа кода присваивают 1, а буквам нижней половины – 0. Затем каждое подмножество снова разбивается на два подмножества с соблюдением того же условия примерного равенства вероятностей и с тем же условием присвоения кодовых элементов в качестве второго символа. Такое разбиение продолжается до тех пор, пока в подмножестве не останется только по одной букве кодового алфавита.
Пример: Провести эффективное кодирование ансамбля из восьми букв (знаков).
| Буква xi | Вероятности pi | Кодовая последовательность | Длина кодового слова ni | pini | -pilog2pi | |||
| Номер разбиения | ||||||||
| x1 | 0,25 | 0,5 | 0,50 | |||||
| x2 | 0,25 | 0,5 | 0,50 | |||||
| x3 | 0,15 | 0,45 | 0,41 | |||||
| x4 | 0,15 | 0,41 | ||||||
| x5 | 0,05 | 0,2 | 0,22 | |||||
| x6 | 0,05 | 0,2 | 0,22 | |||||
| x7 | 0,05 | 0,2 | 0,22 | |||||
| x8 | 0,05 | 0,2 | 0,22 |
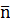 =
= = (0,25*2+0,25*2+0,15*3+0,15*3+0,05*4+0,05*4+0,05*4+0,15*4)=2,7 бит
= (0,25*2+0,25*2+0,15*3+0,15*3+0,05*4+0,05*4+0,05*4+0,15*4)=2,7 бит
 = - (2*0,25*log2 0,25 + 2*0,15*log2 0,15 + 4*0,05*log20,05) = 2,7 бит
= - (2*0,25*log2 0,25 + 2*0,15*log2 0,15 + 4*0,05*log20,05) = 2,7 бит
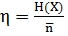 =
= 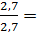 1
1
Метод Шеннона - Фано не всегда приводит к однозначному построению кода, так как при разбиении на подмножества можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппу. Следовательно, такое кодирование хотя и является эффективным, но не всегда будет оптимальным.