Арифметическое кодирование.
Алгоритм Хаффмана , рассмотренный ранее, не может передавать на каждый символ сообщения, если не использовать блоковое кодирование, менее одного бита информации. Хотя энтропия источника с алфавитом из таких символов может быть меньше 1, особенно при существенном отличии вероятностей символов алфавита.

Хотелось бы иметь такой алгоритм кодирования, который позволял бы кодировать символы менее чем 1 битом.
Одним из таких алгоритмов является арифметическое кодирование, представленное в 70-х годах XX века.
При арифметическом кодировании будем исходить из факта, что сумма вероятностей символов (и соответствующих им относительным частот), всегда равна 1. Относительные частоты появления символов могут определяться путем текущих статистических измерений исходного сообщения (это первый « проход» процедуры кодирования).
Особенностью арифметического кодирования является то, что для отображения последовательности символов на интервале [0,1] используются относительные частоты.
Если, например, символ А а сообщении BANANANBAB (10 символов) встречается 4 раза, то его относительная частота =0,4 и, таким образом, определяют всех символов в сообщении: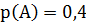 ,
, 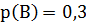 ,
, 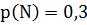
Результатом такого отображения является сжатие символов (посимвольное сжатие) в соответствии с их вероятностями.
Т.е. результатом арифметического сжатия будет некоторая дробь из интервала [0,1], которая представляется двоичной записью (это второй «проход» процедуры кодирования). «Двухпроходная» процедура кодирования реализуется и для алгоритмов Шеннона и Хаффмана.
Принципиальное отличие арифметического кодирования от методов Шеннона и Хаффмана в его непрерывности, т.е. арифметическому кодированию подвергается сообщение целиком (набор символов, файл), а не символы по отдельности или их блоки.
Эффективность арифметического кодирования растет с увеличением длины сжимаемого сообщения (для кодирования Шеннона и Хаффмана этого не происходит).
Алгоритм арифметического кодирования заключается в построении отрезков (интервалов), однозначно определяющих заданную последовательность символов в соответствии с их вероятностями (относительными частотами появления). Объединение всех отрезков, пересекающихся только в граничных точках, для вероятностей каждого символа должно образовывать формальный интервал [0,1]. Для последнего полученного интервала, соответствующего последнему символу в сообщении, находится число, принадлежащее его внутренней части. Это число и будет двоичным кодом для рассматриваемой последовательности.
Пример арифметического кодирования:
Пусть алфавит источника состоит из 2-х символов a и b с соответствующими вероятностями p(a) =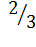 , p(b) =
, p(b) =  . Необходимо закодировать сообщение {aba}.
. Необходимо закодировать сообщение {aba}.
Рассмотрим интервал [0,1] и разобьем его на отрезки, соответствующие вероятностям [0,2/3] и [2/3,1]. Поступающий символ попадет только в один из этих отрезков, который снова разобьем на части, пропорциональные вероятностям обоих символов алфавита и т.д. до последнего символа в алфавите.
| Шаг кодирования | Поступающий символ | Интервал |
| нет | [ 0,1 ] | |
| a | [ 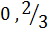 ] ]
| |
| b | [  ] ]
| |
| a | 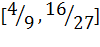
|
| |

| |
| |


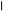
 1.
1.
|
| ||||




 2.
2.
 |
1. 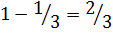 ,
,
2.  ,
,
3. 

|
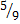
|

|

 3.
3.
 | ||||||
|
| |||||
1. 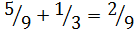 ,
,
2. 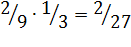 ,
,
3. 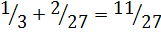
Внутри последнего интервала 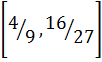 выберем число 16/32=1/2, которое в двоичном представлении и будет кодом сообщения aba -> 0.1 (0 и десятичную точку не учитывают) => получим длину кода на символ <1 бит.
выберем число 16/32=1/2, которое в двоичном представлении и будет кодом сообщения aba -> 0.1 (0 и десятичную точку не учитывают) => получим длину кода на символ <1 бит.
Декодирование арифметического кода производится по его значению и тем же интервалам до восстановления исходного сообщения.
Важной особенностью арифметического кодирования является тот факт, что в конце кодируемого сообщения обязательно ставится специальный символ (маркер) его окончания, который используется для декодирования сообщения.