Алгоритм универсального кодирования методом Лемпела-Зива.
Этот метод относится к классу универсальных потому, что он не требует априорных знаний о статистике символов. Такой метод носит менее математически обоснованный, но более практический характер.
Алгоритм LZ77 разработан израильскими математиками Авраамом Лемпелом и Якобом Зивом.
Одной из причин популярности алгоритма LZ, является их исключительная простота при высокой эффективности сжатия.
LZ77 использует уже просмотренную часть сообщения как словарь. Чтобы добиться сжатия он пытается заменить очередной фрагмент сообщения на указатель в содержимое словаря.
LZ77 использует «скользящее окно по сообщению», разделенное на две неравные части. Большая часть окна - словарь, включающий уже просмотренную часть сообщения. Вторая, меньшая часть окна является буфером, содержащим еще не закодированные символы входного потока.
Алгоритм пытается найти в словаре фрагмент, совпадающий с содержимым буфера.
На практике размер словаря составляет несколько килобайт, а размер буфера не более 100 байт. В результате кодирования формируется совокупность групп по три элемента в каждой [a,l,z],
где a – относительный адрес в словаре, т.е. смещение в словаре относительно его начала фрагмента, совпадающего с содержимым буфера;
l – число совпадающих символов (длина фрагмента):
z – следующий символ из буфера, который отличается от продолжения фразы в словаре.
Пример: Закодировать строку «КРАСНАЯ КРАСКА» (8 символов – словарь, 5 символов – буфер).
| Шаг кодирования | Словарь (8) | Буфер (5) | Код |
| …….. | КРАСН | < 0,0,К> | |
| …….К | РАСНА | < 0,0,Р> | |
| ……КР | АСНАЯ | < 0,0,А> | |
| …..КРА | СНАЯ_ | < 0,0,С> | |
| ….КРАС | НАЯ _К | < 0,0,Н> | |
| …КРАСН | АЯ_КР | < 5,1,Я> | |
| .КРАСНАЯ | _КРАС | < 0,0,_> | |
| КРАСНАЯ_ | КРАСК | < 0,4,К> | |
| АЯ_КРАСК | А | < 0,0,А> |
В последней строке буква А берется не из словаря, т.к. она последняя.
Длина двоичного кода будет складываться из
 ,
,
где
 - длина словаря
- длина словаря
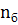 - длина буфера
- длина буфера
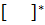 - операция округления в большую сторону.
- операция округления в большую сторону.
Здесь считается, что символы кодируются 8-битным двоичным кодом (например, ASCII+)
Тогда в примере: 
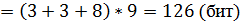 , хотя исходная длина сообщения 14x8=112 бит.
, хотя исходная длина сообщения 14x8=112 бит.
Исходя из алгоритма, такое кодирование часто называют словарным кодированием.
Очевидно, что сжатие будет иметь место, если длина кода сообщения будет меньше кода того же сообщения при непосредственном кодировании символов.
Для словарного кодирования установлено, что:
1. Часто повторяющиеся цепочки символов кодируются очень эффективно.
2. Редко появляющиеся символы и последовательности символов с течением времени удаляются из словаря фраз.
3. Повторяющиеся символы кодируются эффективно.
4. Можно доказать, что словарное кодирование асимптотически оптимально. Это означает, что для очень длинного текста избыточность исчезает, т.е. среднее число бит, необходимое для кодирования одного символа, стремится к энтропии этого текста.
5. Практически достижимая степень сжатия для длинных текстов составляет 50-60 %.
В семейство алгоритмов LZ входит несколько алгоритмов, которые модифицировались разными авторами в аспекте формирования кодовой группы, но во всех модификациях используется словарь.
Наибольшее практическое распространение получил алгоритм LZW (Лемпела-Зива-Уэлга) созданный в 1984 г. В этом алгоритме длина кода уменьшается, так как не используется буфер, а кодирование проводится только по словарю, и, следовательно, код определяется только размером словаря.
Декодирование словарного кода происходит в обратном порядке и упрощается тем, что не требуется поиск совпадений в словаре.