Сравнительная оценка признаков
Выше были рассмотрены достаточно общие методы выбора совокупности признаков, которые целесообразно и доступно использовать при построении системы распознавания. Однако на практике достаточно часто возникает более простая задача, состоящая в проведении сравнительной оценки качества признаков. Остановимся на некоторых методах решения этой задачи. При этом будем полагать, что качество признака хl выше, чем качество признака хs, l, s=l, ..., N, если в соответствии с выбранным критерием сравнительной оценки показатель качества признака xi больше или меньше (в зависимости от метода сравнения) показателя качества признака хs.
Сравнение апостериорных вероятностей. Пусть задан алфавит классов Ωi, i=l, ..., m, выбран априорный словарь признаков xj, j=1, ..., Na, известны условные плотности распределений fi(хj) и априорные вероятности Р(Ωi). Требуется произвести сравнительную оценку признаков хl и хs, l, s= 1, ..., Na, иначе — определить, какой из этих признаков обладает лучшими разделительными свойствами. Разделим диапазон изменения признака х, на интервалы D1i(xl); D2i(xl); ...; Dmi(xl), на которых отличны от нуля соответственно одна функция fi(хl); две функции fi(хl), ..., m функций fi(хl).
То же проделаем и с признаком xs, т. е. определим интервалы D1i(xs); D2i(xs)...; Dmi(xs). Вероятность получить однозначное решение равна

(5.37)
Вероятность получить двузначное решение вида «класс g, или класс q», g, q=1, ..., m, равна

(5.38)
где D2i — совокупность интервалов, на которых отличны от нуля какие-либо две функции из набора fi(хl).
Вероятность получить m-значное решение вида «класс 1, или класс 2, ..., или класс m» равна

(5.39)
где Dmi(xl) — совокупность интервалов, на которых отличны от нуля все т функций fi(хl)., i=l, 2, ..., m.
Обозначив 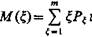 математическое ожидание случайной величины x, которая может принимать значения x=1, 2, ..., m с вероятностями Рx, определим указанное математическое ожидание для первого и второго признаков, т. е. Mxl(x) и Mxs(x). Если Mxl(x)>Mxs (x)(x), то признак хs обладает лучшими разделительными свойствами, если Mxs(x)>Mlx(x), то признак xl обладает лучшими разделительными свойствами. Будем полагать, что в первом случае выше качество признака хs, а во втором случае — признака хl.
математическое ожидание случайной величины x, которая может принимать значения x=1, 2, ..., m с вероятностями Рx, определим указанное математическое ожидание для первого и второго признаков, т. е. Mxl(x) и Mxs(x). Если Mxl(x)>Mxs (x)(x), то признак хs обладает лучшими разделительными свойствами, если Mxs(x)>Mlx(x), то признак xl обладает лучшими разделительными свойствами. Будем полагать, что в первом случае выше качество признака хs, а во втором случае — признака хl.
Сравнение вероятностных характеристик признаков. Сравнительная оценка качества признаков может быть произведена и в случае, когда условные плотности распределений fi(хj) неизвестны, однако известны первые и вторые моменты этих распределений, т. е. mji и Dji. Оценка, основанная на использовании этих данных, возможна в связи с тем, что признаки Xj могут быть условно подразделены на две группы.
К первой группе относятся признаки, значения которых незначительно изменяются при переходе от одного объекта данного класса к другому объекту и весьма заметно изменяются при переходе от объекта одного класса к объектам других классов.
Ко второй группе относятся признаки, значения которых чувствительны к переходам от одного объекта данного класса к другому объекту и лишь незначительно изменяются при переходах от объектов одного класса к объектам других классов.
Признаки, относящиеся к первой группе, полезней признаков, относящихся ко второй группе. Количественная оценка качества признаков xj, j=1, 2, ..., N, может быть произведена следующим образом.
Пусть некоторый механизм вырабатывает значения j-го признака с вероятностями, равными априорным вероятностям Р(Ωi), i=1, ..., m. Определим математическое ожидание некоторой фиктивной случайной величины, принимающей значения mji с вероятностями Р(Ωi), т. е.
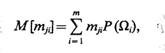
(5.40)
а также математическое ожидание дисперсии j-го признака по классам:
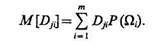
(5.41)
Если M[Dli]<M[Dsi], l, s=1, ..., Na то при прочих равных условиях качество признака xt выше, чем качество признака хl так как вдоль оси признака xs объекты располагаются компактней, чем вдоль оси признака хs.
Дисперсия математического ожидания распределений признаков при переходе от класса к классу  Если `Dli>`Dsi то при прочих равных условиях качество признака xl выше, чем качество признака хs так как вдоль оси признака хl объекты, относящиеся к разным классам, располагаются на удалениях больших, чем вдоль оси признака xs. Геометрическая интерпретация сказанного прослеживается при рассмотрении рис. 5.2, а, б.
Если `Dli>`Dsi то при прочих равных условиях качество признака xl выше, чем качество признака хs так как вдоль оси признака хl объекты, относящиеся к разным классам, располагаются на удалениях больших, чем вдоль оси признака xs. Геометрическая интерпретация сказанного прослеживается при рассмотрении рис. 5.2, а, б.
В качестве критерия сравнительной оценки признаков целесообразно использовать величину 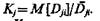
Будем полагать, что если Кl<Кs, то качество признака хl выше, чем качество признака хs при этом наилучший признак тот, который реализует 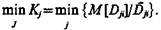
Информационный подход. Сравнительная оценка качества признаков xl и xs, l, s=1, ..., Na может быть произведена также на основе определения количества информации, которое получает система в процессе распознавания объектов в результате определения каждого из этих признаков.
Пусть распознаваемый объект может принадлежать лишь одному из т классов, априорные вероятности отнесения этого объекта к определенному классу обозначим Р(Ωi) i,j=1, 2, ..., m, а условные плотности распределения значений признаков —fj(xl), fj(xs).
До проведения экспериментов исходная априорная неопределенность состояния системы, или ее энтропия,

(5.42)

Рис. 5.2
Здесь логарифм может быть взят при любом основании а> 1. На практике удобнее пользоваться логарифмами при основании 2 и выражать энтропию в битах.
Определим, какое количество информации получает система распознавания при измерении признака xl.
Если признак xl принимает дискретные значения с вероятностями 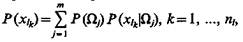 то полная условная энтропия системы распознавания при измерении всех возможных значений признака xl
то полная условная энтропия системы распознавания при измерении всех возможных значений признака xl
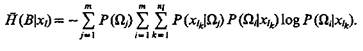
(5.43)
Если признак хl — непрерывный и его совместная плотность распределения— условная плотность распределения  признака xl в Ωi-м классе), то значение полной условной энтропии системы после измерения признака xl
признака xl в Ωi-м классе), то значение полной условной энтропии системы после измерения признака xl
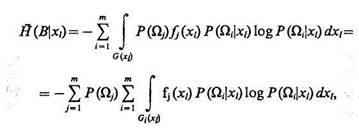
(5.44)
где G — полная область изменения признака xl по всем классам; Gi — область изменения признака xl в Ωi-м классе.
Таким образом, если проведены эксперименты, связанные с определением признака xh и рассчитаны апостериорные вероятности отнесения объекта к соответствующим классам, то количество информации, которое получает система распознавания в результате проведения этих экспериментов, составит: ; если признак дискретный, то
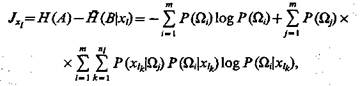
(5.45)
если признак непрерывный, то
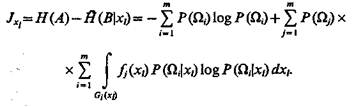
(5.46)
Аналогичные выражения могут быть получены и для признака хs. При этом будем полагать, что качество признака хl выше, чем качество признака хs в случае, если количество информации, связанное с определением признака xl больше, чем количество информации, связанное с определением признака хs т. е. Jxl> Jxs. При этом имеем в виду следующее. Информативность признаков не является постоянной величиной и не представляет собой безусловной величины, а наоборот, в общем случае количество информации, получаемое системой распознавания в результате измерения каждого данного признака, зависит от того, какие признаки были определены ранее и какие значения они приняли. Это в равной мере относится как к статистически зависимым, так и к статистически независимым признакам.
Пусть задан словарь признаков  В общем случае
В общем случае

(5.47)
Применительно к статистически зависимым признакам, т. е. когда  утверждение, содержащееся в (5.47), обсуждалось в публикациях по проблеме распознавания. В то же время применительно к статистически независимым признакам, т. е. когда
утверждение, содержащееся в (5.47), обсуждалось в публикациях по проблеме распознавания. В то же время применительно к статистически независимым признакам, т. е. когда 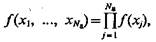 этот вопрос либо вообще не обсуждался, либо трактовался ошибочно.
этот вопрос либо вообще не обсуждался, либо трактовался ошибочно.
В [19] приведены результаты подробного исследования проблемы информативности признаков в системах распознавания. Показано, что статистическая независимость признаков распознаваемых объектов не является условием ни необходимым, ни достаточным для того, чтобы информативность признаков была величиной, не зависящей от того, какие признаки были определены на предыдущих шагах и какие при этом значения они приняли. Этот вопрос имеет не только теоретическое, но и практическое значение, так как если бы информативность признаков была величиной постоянной, то тогда не представляло бы затруднений решить задачи: 1) минимизации описаний классов объектов на основе априорного определения группы наиболее информативных признаков, определяемых с помощью соотношений (5.45) и (5.46); 2) построения оптимального маршрута распознавания на основе априорного ранжирования признаков в соответствии с их информативностью. *
*Даже оставляя в стороне принципиальный вопрос о ресурсах, затрачиваемых на разработку аппаратуры, необходимой для определения тех или других признаков (задача 1), а также связанных с проведением экспериментов по определению признаков распознаваемых объектов (задача 2), легко заметить, что с учетом сказанного эти задачи подобным образом не могут быть решены.
При построении систем распознавания целесообразно априорно оценивать информативность каждого признака (в предположении, что он определен первым). Такая процедура позволяет, по крайней мере предварительно, определять, какие из признаков априорного словаря целесообразно исключить из дальнейшего рассмотрения. Окончательное решение, связанное с построением рабочего словаря признаков, может быть принято на основе общего подхода к проблеме (см. § 5.1 — 5.4).
Далее (см. гл. 9) будет подробно рассмотрен вопрос о глобальном оптимальном планировании процесса распознавания. Здесь же обсудим возможность использования для локальной оптимизации процесса распознавания информационного подхода.
Пусть оценена информативность всех признаков рабочего словаря, а также известна стоимость C(xj), j=l, ..., Np, определения признаков. На первой стадии экспериментов определяется такой признак из рабочего словаря (например, хk), который доставляет экстремальное значение функции L(xj)=J(xj)/C(xj), т. е.

(5.48)
где J(xj) — количество информации, вносимое в систему распознавания измерением признака xj, усредненное по всему множеству его возможных значений.
Признак хk и надлежит измерить на первой стадии экспериментов. Далее в зависимости от того, какое конкретное значение принял признак хk=х*k, определяется такой признак, например xh который в среднем по всему множеству его значений доставляет экстремум функции  т. е.
т. е.
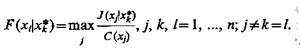
(5.49)
Аналогично определяются третья и последующие стадии экспериментов. При этом на каждом шаге целесообразно проверять, не превзойден ли заданный уровень вероятности отнесения неизвестного объекта к какому-либо классу. Если это произошло, то целесообразно дальнейшее проведение экспериментов прекратить.
§ 5.6. Построение рабочего словаря признаков при отсутствии априорного словаря признаков
Выше были рассмотрены методы определения признакового пространства при ограничениях на стоимость его реализации и методы сравнительной оценки признаков, возможность применения которых связана с наличием априорного словаря признаков. Однако в практике построения систем распознавания приходится сталкиваться с ситуациями, когда априорный словарь признаков неизвестен, а дана лишь некоторая совокупность реализаций сигналов, характеризующих явления или процессы, для распознавания которых предназначена разрабатываемая система. К таким сигналам могут быть отнесены, например, сигналы звуковые, возникающие в процессе работы некоторых технических устройств, радиолокационные или световые, отраженные от каких-либо объектов, электрические, возникающие при электрокардиографических или энцефалографических исследованиях, и т. д. В подобных ситуациях возникает следующая задача: на основе совокупности сигналов, характеризующих каждый класс объектов или явлений, определить и упорядочить признаки, приписывая больший вес признаку, несущему больше информации при различении объектов или явлений.
Решение этой задачи на основе разложения Карунена — Лоэва состоит в следующем [17]. Пусть множество объектов или явлений подразделено на классы Ωi, получена совокупность реализаций сигналов xi(t) на интервале 0£t^0£T, характеризующая классы, известна априорная вероятность появления объектов Р(Ωi), i=1, ..., m, и сигналы хi(t) представляют собой случайные функции. Положим, что функции обладают разложением
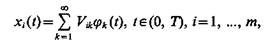
(5.50)
где Vik — случайные коэффициенты, математическое ожидание которых M(Vik) = 0; {jk(t)}—множество детерминированных ортонормированных координатных функций на интервале (0, Т). Корреляционная функция случайных процессов, описывающих классы Ωi, i=l, ..., m,

(5.51)
Подставив (5.50) в (5.51), получим

(5.52)
Пусть случайные коэффициенты Vik удовлетворяют условиям
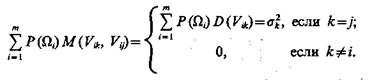
(5.53)
Тогда (5.53) приобретает вид

(5.54)
или

(5.55)
Если можно поменять местами суммирование и интегрирование, то (5.55) запишется так:
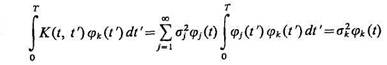
(5.56)
Разложение (5.50), в котором функции jk(t) определяются согласно (5.55) или (5.56) через корреляционную функцию K(t, t'), называется обобщенным разложением Карунена — Лоэва.
Искомое признаковое пространство (координатная система) образуется в результате решения интегрального уравнения Фред-гольма второго рода (5.56), ядро которого — корреляционная функция K(t, /') случайных процессов х,(0, описывающих классы Ωi, i = l, ..., m, на интервале наблюдения [0, T] относительно координатных функций jk(t), k=l, 2, ... .
При упорядочении координатных функций jk(t) в порядке убывания соответствующих им собственных значений s2k коэффициенты разложения случайных процессов Vik обладают также в порядке убывания наилучшими разделительными качествами, т. е. вносят в систему большее количество информации. Это означает следующее. Пусть координатным функциям jr(t) и jl(t) соответствуют значения дисперсий s2r и s2l и при этом s2r > s2l, k, r, 1=1,2, ... . Тогда признак хr обладает лучшими разделительными свойствами, чем признак хl. Использование признака хr вносит в систему распознавания больше информации, чем использование признака хl. Заметим, что s2k представляют собой дисперсию математического ожидания распределений найденных признаков (k= 1, 2, ...) при переходе от класса к классу (см. § 5.5).
Построение признакового пространства системы распознавания на основе коэффициентов разложения Карунена — Лоэва обеспечивает минимизацию начальной энтропии системы, определяемой величиной Р(Ωi) i = 1,..., m. При этом среднеквадратичная ошибка, возникающая за счет того, что реальное признаковое пространство системы реализуется на основе конечного числа признаков, минимальна.

Рис. 5.3

Рис. 5.4
Пример*. Пусть дана совокупность реализаций сигналов, принадлежащих классам Ω1 и Ω2. Будем полагать, что сигналы описывают эргодические случайные стационарные процессы. Выполнено усреднение по множеству реализаций, относящихся к каждому классу, и построены корреляционные функции КΩ1 (t) и КΩ2 (t). Последние будем рассматривать в качестве описаний классов (рис. 5.3).
*Пример разработан Л. И. Калиновым.
Корреляционные функции КΩ1 (t) и КΩ2 (t) представим в виде набора числовых значений, относящихся к дискретным моментам времени, а затем применительно к КΩ1 (t) и КΩ2 (t) выполним обобщенное разложение Карунена — Лоэва. В результате найдем, что суммарное значение дисперсии  при этом два члена разложения (20-й и 44-й) обеспечивают значение дисперсий s220 + s244 =0,83, что составляет 97,7% от суммарного значения дисперсии. Это дает основание признаковое пространство проектируемой системы распознавания строить с использованием только двух признаков, которые обозначим x1 и х2. При этом оценки математических ожиданий и дисперсий признаков по классам Ω1 и Ω2 соответственно равны:
при этом два члена разложения (20-й и 44-й) обеспечивают значение дисперсий s220 + s244 =0,83, что составляет 97,7% от суммарного значения дисперсии. Это дает основание признаковое пространство проектируемой системы распознавания строить с использованием только двух признаков, которые обозначим x1 и х2. При этом оценки математических ожиданий и дисперсий признаков по классам Ω1 и Ω2 соответственно равны:
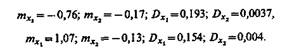
На рис. 5.4, а, б показаны гистограммы, представляющие собой описания классов на языке признаков x1 и х2. Из рисунков видно, что признак х1 обладает лучшими разделительными свойствами, чем признак х2 (действительно, s21»0,8, в то время как D22»0,03).