Основные элементы аппарата структурных методов распознавания
Говоря о средстве описания объектов в терминах непроизводных элементов и их отношений, употребляют понятие язык. Правила этого языка, определяющие способы построения объекта из непроизводных элементов, называют грамматикой. В соответствии с грамматикой объект представляется предложением в этом языке.
Распознавание в основном состоит из следующих этапов: 1) определение непроизводных элементов и их отношений для конкретных типов объектов; 2) проведение синтаксического анализа предложения, представляющего объект, с тем чтобы установить, может ли некоторая фиксированная грамматика породить имеющееся описание объекта (грамматический разбор).
Грамматику можно определить, используя априорные сведения об объектах или проанализировав выборочное множество объектов. Процедура распознавания на основе использования структурных методов состоит из предварительной обработки, описания или представления объекта и синтаксического анализа (рис. 8.2). На этапе предварительной обработки предъявленный для распознавания объект подвергается кодированию и фильтрации, восстановлению и улучшению качества. Объект кодируется или аппроксимируется таким образом, чтобы дальше с ним было удобно работать. Например, черно-белое изображение можно закодировать с помощью сетки (или матрицы) нулей и единиц. Чтобы повысить эффективность обработки на последующих этапах работы, на этом этапе часто также прибегают к какой-нибудь
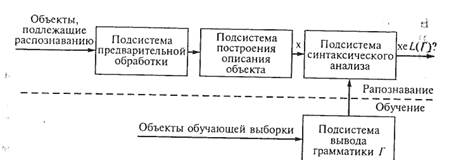
Рис. 8.2
разновидности «сжатия данных». Затем с помощью методов фильтрации и восстановления устраняются искажения в целях повышения качества изображения. Предполагается, что по окончании этапа предварительной обработки воспроизводятся образы достаточно хорошего качества.
Объект после предварительной обработки представляется некоторой структурой языкового типа (например, цепочкой или графом). Процесс получения представления объекта включает в себя процедуры: а) разбиения («сегментация») объекта; б) выделения признаков — непроизводных элементов. Чтобы найти представление объекта через его подобразы, необходимо его сегментировать и в результате этой операции идентифицировать (выделить) его непроизводные элементы и действующие в объекте отношения между ними. Другими словами, объекты, прошедшие предварительную обработку, разбиваются на подобразы в соответствии с предварительно определенными синтаксическими операциями. Каждый подобраз, в свою очередь, отождествляется с некоторым заданным набором непроизводных элементов. В результате каждый объект получает свое представление с помощью некоторого набора непроизводных элементов и ряда фиксированных синтаксических операций. Например, при использовании операции соединения объект получает представление в виде некоторой цепочки соединенных непроизводных элементов.
Система должна обладать способностью обнаруживать синтаксические связи, существующие в объекте. Решение о синтаксической правильности представления объекта, т. е. о принадлежности его к определенному классу, задаваемому определенной синтаксической системой или грамматикой, вырабатывается синтаксическим анализатором (блоком грамматического разбора). При выполнении синтаксического анализа (грамматического разбора) анализатор обычно воспроизводит полное синтаксическое описание объекта в виде дерева грамматического разбора, если соответствующий объект является синтаксически правильным.
В противном случае объект либо отклоняется, либо подвергается анализу с помощью других заданных грамматик, которыми могут описываться другие классы изучаемых объектов.
Процедура распознавания — это сопоставление с эталоном. Цепочка непроизводных элементов, представляющая поданный на вход системы объект, сопоставляется с цепочками непроизводных элементов, описывающими классы. Распознаваемый объект с помощью выбранного критерия согласия (подобия) относится к тому классу, с которым обнаруживается наилучшая близость. Иерархическая структурная информация при этом практически игнорируется. В то же время полный разбор цепочки, представляющей распознаваемый объект, позволяет полностью изучить его иерархическое структурное описание. Между этими двумя крайностями заключено множество промежуточных подходов. В частности, можно сформировать набор тестов для проверки наличия или отсутствия определенных подобразов или непроизводных элементов, так же как комбинации и тех, и других. Результаты такой проверки, которую можно проводить с помощью процедур просмотра таблиц, построения дерева решений или логического анализа, используются для выработки классификационного решения. Каждый из этих тестов может одновременно являться и процедурой сопоставления с эталоном, и процедурой грамматического разбора, определенными для поддерева, представляющего подобраз. Обычно выбор конкретной процедуры распознавания зависит от специфических особенностей задачи: если распознавание требует работы с полным описанием объекта, то необходим грамматический разбор; в других случаях полного разбора можно избежать, ограничившись более простыми методами.
Чтобы получить грамматику, характеризующую структурную информацию об изучаемом классе объектов, необходим ее вывод по заданному набору обучающих объектов, представленных описаниями структурного типа (в настоящее время этот этап, как правило, выполняется вручную). Данная процедура аналогична процедуре обучения в других методах распознавания. Структурное описание соответствующего класса формируется в процессе обучения на примерах реальных объектов, относящихся к этому классу. Это описание в форме грамматики используется затем для представления объектов и синтаксического анализа. В более общем случае обучение может предусматривать определение наилучшего набора непроизводных элементов и получение соответствующего структурного описания классов объектов или явлений.
Некоторые понятая теории формальных грамматик. Поскольку практическая реализация структурных методов распознавания образов основана на использовании некоторых идей и методов математической лингвистики, рассмотрим некоторые ее основные понятия, необходимые для усвоения сущности структурного подхода.
Термин формальная грамматика представляет собой общее название нескольких типов исчислений, используемых в математической лингвистике для описания строения естественных языков, а также некоторых искусственных языков, в частности языков программирования. Под грамматиками в математической лингвистике понимают некоторые специальные системы правил, задающие (или характеризующие) множества цепочек (конечных последовательностей) символов. Эти объекты могут интерпретироваться как языковые объекты различных уровней, например как словоформы, словосочетания и предложения (цепочки словоформ) и т. п.
Следовательно, формальные грамматики имеют дело с абстракциями, возникающими в результате обобщения таких стандартных лингвистических понятий, как словоформа, словосочетание и предложение. Из определенного набора символов (обозначающих, например, все словоформы русского языка) можно строить произвольные цепочки; одни из них естественно считать правильными, или допустимыми, а другие — неправильными, или недопустимыми.
Формальная грамматика задает правильные цепочки, если либо для любой предъявленной цепочки грамматика позволяет установить, является или нет эта цепочка правильной, и в случае положительного ответа дает указания о строении этой цепочки, либо грамматика позволяет построить любую правильную цепочку, давая при этом указания о ее строении, и не строит ни одной неправильной цепочки. В первом случае формальная грамматика называется распознающей, во втором — порождающей.
Формальные грамматики обладают двумя следующими существенными особенностями. Во-первых, существующие формальные грамматики описывают только совокупность возможных результатов, не давая прямых указаний, как именно можно получить результат, соответствующий определенной исходной задаче. Во-вторых, в формальных грамматиках все утверждения формулируются исключительно в терминах небольшого числа четко определенных и весьма элементарных символов и операций. Это делает формальные грамматики очень простыми с точки зрения их логического строения и облегчает изучение их свойств дедуктивными методами.
Структурные методы распознавания базируются на порождающей грамматике — системе, состоящей из четырех частей:
основной, или терминальный, словарь; вспомогательный словарь; начальный символ; набор правил подстановки.
Основной (терминальный) словарь. Это набор исходных элементов, из которых строят цепочки, порождаемые грамматикой. Элементы основного словаря называют основными (терминальными) символами.
Вспомогательный (нетерминальный) словарь. Это набор символов, которыми обозначаются классы исходных элементов или цепочек исходных элементов, а также в отдельных случаях некоторые специальные элементы (вспомогательные или нетерминальные).
Начальный символ. Это выделенный нетерминальный символ, обозначающий совокупность (класс) всех тех языковых объектов, для описания которых предназначается данная грамматика. Так, в грамматике, порождающей предложения, начальным будет символ, означающий предложение; в грамматике, порождающей допустимые слоги, начальный символ означает слог и т. п.
Правила подстановки. Это выражения вида «х®у», что означает «заменить x на у» или «подставить х вместо у», где х и у — цепочки, содержащие любые терминальные или нетерминальные символы.
Для описания собственно процесса порождения, т. е. того, как грамматика применяется, необходимо введение таких понятий, как непосредственная выводимость, выводимость, язык, порождаемый грамматикой.
Непосредственная выводимость. Если имеются цепочки хну, которые можно представить в виде x=z1az2 и y=z1bz2, где а®b — одно из правил грамматики Г, то говорят, что цепочка у непосредственно выводима из цепочки х в грамматике Г. Другими словами, цепочка х может быть переработана в цепочку у за один шаг применением одной подстановки: х получается из у подстановкой b на место некоторого вхождения цепочки а. Это обозначается как  или х½ =у.
или х½ =у.
Выводимость. Если имеется последовательность цепочек х0, х1б ..., хn, в которой каждая следующая цепочка непосредственно выводима из предыдущей, то цепочка хn выводима из цепочки х0. Последовательность цепочек х0, х1, ..., хn называется выводом хn из х0 в грамматике Г. Это означает, что цепочка х0 перерабатывается в цепочку хn не обязательно за один шаг, а последовательным применением нескольких подстановок. Очевидно, что непосредственная выводимость есть частный случай выводимости. Вывод, начинающийся начальным символом и заканчивающийся цепочкой, состоящей только из терминальных символов, называется полным выводом. Естественно, не всякий вывод, начинающийся начальным символом, является полным; возможны выводы, начинающиеся начальным символом, которые невозможно продолжить до полного вывода,— тупиковые выводы. Невозможность продолжать вывод, хотя он и не является полным, т. е. не кончается цепочкой терминальных символов, определяется тем, что в соответствующей грамматике отсутствует правило, левая часть которого содержалась бы в последней цепочке данного вывода. Считая, что от «хорошей» грамматики вовсе не требуется, чтобы любой вывод в ней заканчивался правильной терминальной цепочкой: достаточно, чтобы любой полный вывод давал правильную цепочку.
Существенно, что порождающая грамматика не есть алгоритм, поскольку правила подстановки представляют собой не последовательность предписаний, а совокупность решений. Это означает, что, во-первых, правило вида а®b понимается в грамматике как «а можно заменить на b» (но можно и не заменять); в алгоритме же а-+b означало бы «а не следует заменить на b» (нельзя не заменять); во-вторых, порядок применения правил в грамматике произволен: любое правило, в принципе, разрешается применять после любого.
Язык, порождаемый грамматикой. Совокупность всех терминальных цепочек, т. е. цепочек, состоящих только из терминальных символов, выводимых из начального символа в грамматике Г, называется языком, порождаемым грамматикой Г, и обозначается L(Г). Следовательно, применение грамматики — это построение полных выводов, последние цепочки которых и образуют язык, порождаемый грамматикой. Две различные грамматики могут порождать один и тот же язык, т. е. одно и то же множество терминальных цепочек. Такие грамматики называются эквивалентными грамматиками.
Итак, порождающая грамматика есть упорядоченная четверка Г =<V, W, I, R), где V и W—непересекающиеся конечные множества, называемые соответственно основным и вспомогательным алфавитами или словарями [их элементы называются соответственно основными (или терминальными) и вспомогательными (или нетерминальными) символами], I — элемент W, называемый начальным символом, и R — конечное множество правил, имеющих вид j®y, где j и y— цепочки (слова) в алфавите VÈW и «®» — символ, не принадлежащий VÈW (R — схема грамматики).