Реализация процесса распознавания на основе структурных методов
Для распознавания неизвестного объекта на основе структурных методов необходимо прежде всего найти его непроизводные элементы и отношения между ними, а затем с помощью синтаксического анализа (грамматического разбора) установить, согласуется ли описание образа с грамматикой, которая, по предположению, могла его породить.
Для формирования соответствующей грамматики можно воспользоваться либо априорными сведениями о распознаваемых объектах, либо результатами изучения конечного выборочного множества «типичных» в некотором смысле объектов. В первом случае говорят о задании грамматики на основе эвристических соображений, во втором — о выводе грамматики.
Допустим, что имеем дело с двумя классами объектов (Ω1 и Ω2) и объекты, входящие в эти классы, можно описать с помощью признаков, принадлежащих некоторому конечному множеству. Эти признаки можно считать основными символами (элементы основного словаря) и обозначать через V (их называют также непроизводными символами, непроизводными элементами). Каждый объект может рассматриваться как цепочка или предложение, поскольку он составлен из элементов основного словаря.
Пусть также существует грамматика Г такая, что порождаемый ею язык состоит из предложений (объектов), принадлежащих исключительно одному из классов, например классу Ω1. Эта грамматика может быть использована для классификации объектов, так как предъявленный неизвестный объект можно отнести к классу Ω1 если он является предложением языка L(Г). В противном случае объект приписывается классу Ω2. В данном случае объект попадает в класс Ω2 исключительно потому, что не входит в класс Ω1 :если оказывается, что объект не является грамматически правильным предложением в смысле грамматики Г, то предполагается, что он должен принадлежать классу Ω2. На самом же деле объект может не относиться и к классу Ω2. Он может также представлять собой зашумленную или искаженную цепочку, которую в ряде случаев предпочтительно просто изъять из рассмотрения. Для этого необходимо располагать грамматиками Г1 и Г2, порождающими языки L(Г1) и L(Г2), соответственно. Объект зачисляется в тот класс, в языке которого он оказывается грамматически правильным предложением. Если последнее не выполняется, то очевидно, что данный объект не принадлежит ни одному из двух заданных классов и, следовательно, требуется еще одна грамматика Г3 и т. д. В случае т классов рассматривается т грамматик и связанных с ними языков L(Гi), i= 1, 2, ..., m. Распознаваемый объект относится к классу Ω1, в том и только в том случае, если он является грамматически правильным предложением языка L(Гi). Если объект оказывается грамматически правильным предложением более чем одного языка, решение относительно его принадлежности принимается точно таким же образом, как это делается при использовании иных методов распознавания, когда оказывается, что результаты реализации процедуры распознавания не позволяют определенно отнести объект к одному из заданных классов.
Практическое использование структурного метода требует обычно разрешения следующих основных проблем : 1) построения адекватного описания распознаваемых объектов; 2) выбора грамматики; 3) реализации процесса распознавания посредством процедур синтаксического анализа; 4) использования процедур обучения для вывода грамматик; 5) применения в рамках структурного подхода процедур из других методов распознавания (например, статистических для учета помех и искажений случайного характера, кластер-анализа и т. д.).
Рассмотрим основные приемы, используемые при практическом применении структурных методов распознавания.
Выбор непроизводных элементов. Первым шагом в построении структурного описания объекта распознавания является определение набора непроизводных элементов, с помощью которых можно было бы описывать рассматриваемый объект. Этот выбор зависит от самого характера объекта, вида исходных данных, области приложений и способа практической реализации системы распознавания. В настоящее время не существует некоего универсального решения задачи выбора непроизводных элементов. Обычно при выборе непроизводных элементов пользуются следующими основными критериями:
Критерий 1. Непроизводные элементы должны служить основными элементами образа, с тем чтобы с их помощью обеспечивалось получение компактного и адекватного описания исходных данных с помощью вполне определенных структурных отношений (например, отношения соединения).
Критерий 2. Непроизводные элементы должны легко поддаваться выделению или распознаванию с помощью известных методов неструктурного характера, так как предполагается, что они представляют собой простые и компактные образы, «внутренняя» структурная информация которых не принимается во внимание.
Так, для речи естественно считать фонемы «хорошим» набором непроизводных элементов, на котором задается отношение соединения. Подобным же образом штрихи (черточки) выбираются в качестве непроизводных элементов для представления рукописных символов. Однако для изображения вообще не имеется какого-либо «универсального элемента изображения», подобного фонеме или штриху для конкретных объектов — речи или рукописных символов. Иногда для адекватного описания необходимо, чтобы непроизводные элементы содержали информацию, существенную при распознавании данных объектов или явлений. Если, в частности, при решении задачи распознавания объекта существен его размер (или форма, или местоположение), то непроизводные элементы должны нести информацию о размере (или форме, или местоположении), с тем чтобы объекты, принадлежащие различным классам, оказывались различными независимо от того, какой метод используется для анализа их соответствующих описаний. Это условие, однако, часто приводит к необходимости прибегать к семантической информации при описании непроизводных элементов.
Пример [28]. Допустим, что необходимо уметь отличать прямоугольники различных размеров от других фигур.
Выбирается следующий набор непроизводных элементов: a¢—0° — отрезок горизонтальной линии; b¢—90° — отрезок вертикальной линии; с¢—180° — отрезок горизонтальной линии; d¢—270 — отрезок вертикальной линии.
Множество всех возможных прямоугольников (различных размеров) задается с помощью одного предложения — цепочки a¢b¢c¢d¢ (рис. 8.3). Если же требуется различение прямоугольников различных размеров, то приведенное описание оказывается неадекватным. В этом случае в качестве непроизводных элементов необходимо использовать отрезки единичной длины. Множество прямоугольников различных размеров можно описывать с помощью языка

Критерий 2 выбора непроизводных элементов может в некоторых случаях вступать в противоречие с критерием 1 из-за того, что непроизводные элементы, выбранные в соответствии с последним, могут плохо поддаваться распознаванию с помощью известных в настоящее время методов. Однако критерий 2 допускает выбор достаточно сложных непроизводных элементов, если только они могут быть распознаны. Усложнение непроизводных элементов позволяет упрощать структурные описания, т. е. дает возможность пользоваться менее сложными грамматиками. Отыскание компромиссного решения имеет существенное значение при построении реальных систем распознавания, основанных на использовании структурных методов.
Использование грамматик и языков для структурного описания объектов. Как уже отмечалось, грамматику можно использовать
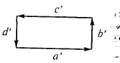
Рис. 8.3
для порождения предложений, представляющих собой некий объект, и для проведения грамматического разбора предложений, с тем чтобы установить, является ли их структура допустимой с точки зрения соответствующей грамматики. Обычно подобные грамматики строятся на основе имеющихся априорных сведений и эвристических соображений, порожденных опытом и профессиональной культурой разработчика системы распознавания.
При построении структурного описания объекта, т. е. при порождении соответствующего предложения в рамках выбранной или заданной грамматики, исходным элементом служит начальный символ 1, входящий в множество вспомогательных символов W. Правило, принадлежащее набору правил R данной грамматики, позволяет преобразовать начальный символ 1 в цепочку символов, например I®аА, что соответствует замене символа I символами аА. Некоторые символы такой цепочки могут входить в множество вспомогательных символов W, а другие — принадлежать множеству непроизводных элементов V*.
* Далее будем обозначать непроизводные элементы строчными буквами, а вспомогательные символы — прописными.
Вспомогательные символы, входящие в преобразованную цепочку, могут снова подвергнуться преобразованиям в соответствии с правилами грамматики, а вспомогательные символы, появляющиеся в цепочках, полученных в результате очередного преобразования,— подвергаться преобразованиям и т. д. Предложение считается сформированным, если представляющая его цепочка содержит только непроизводные элементы.
Пример [29]. Рассмотрим грамматику Г={V, W, I, R}, где V={a, b, с, d}; W={I, A, В, С, D};
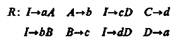
В данном случае можно вывести четыре предложения (=> — символ вывода):

Если считать непроизводными элементами ориентированные отрезки, изображенные на рис. 8.4, а, то с помощью этой грамматики можно получить четыре описания отрезков, образующих прямой угол (рис. 8.4, б). Здесь использован прием, позволяющий описывать двумерные объекты с помощью цепочечных грамматик. Этот прием заключается в соединении структур только в особых точках. Один из способов реализации этого требования заключается в том, что в каждой структуре выделяются только две точки. В нашем случае выделенные точки интерпретируются как «головной» и «хвостовой» концы стрелки.
Деревья. На рис. 8.5 изображен процесс вывода для последнего примера [29] в виде дерева. Начальный символ I выполняет роль корня дерева, концевые узлы, прочитываемые слева направо, образуют выведенное предложение.
Использование деревьев для описания многомерных структур — процедура несложная. В сущности, любая иерархически упорядоченная схема позволяет представить соответствующий объект в виде дерева. Так, на рис. 8.6, а [14] упорядочение состоит в группировке областей, причем область b находится в области а, в свою очередь находящейся в области r. На рис. 8.6, б изображена древовидная структура, естественно вытекающая из этой схемы упорядочения. Каждое дерево вывода задает одно предложение. Большинство грамматик позволяет получать значительное, а при введении вероятностных правил вывода — и бесконечное число предложений.
Процесс решения также можно представить в виде дерева. В простейшем случае в таких деревьях от каждого узла отходят две ветви: одна соответствует наличию у объекта определенного признака, другая — его отсутствию. Подобные деревья не несут какой-либо информации о процессе вывода в указанном выше смысле — они дают иерархическое представление о том, какие признаки (в случае структурного распознавания — какие непроизводные элементы и отношения) характеризуют изучаемый объект. Однако можно сформировать грамматику, описывающую процесс вывода в соответствии со структурой дерева решений (обычно в рамках этого метода строится и используется только дерево).
Процедуры распознавания, связанные с использованием деревьев решений, относят к группе структурных методов, хотя в строгом смысле слова деревья решений являются инструментом иерархического метода разделения. Последний используется в случаях, когда дерево решений «содержит» много признаков. В каждом узле дерева изучается один признак и в зависимости от результатов этого изучения определяется очередная ветвь дерева. Результат классификации определяется на нижнем ярусе дерева. Подобная схема распознавания очень удобна для учета априорных сведений об объектах, однако для нее отсутствуют оптимальные процедуры обучения.
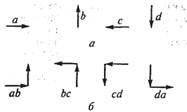
Рис. 8.4
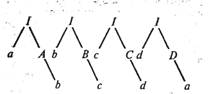
Рис. 8.5
С помощью деревьев решений удобно описывать фигуры, построенные из отрезков линий, например символы. Приведем в качестве примера дерево решений, изображенное на рис. 8.7 [29]. В узле 1 проверяется наличие непроизводного элемента «вертикальный отрезок прямой»; в узле 2а — наличие примыкания снизу справа к непроизводному элементу «вертикальный отрезок прямой» непроизводного элемента «горизонтальный отрезок прямой»; в узле 2б — наличие криволинейного непроизводного элемента; в узле 3 — наличие примыкания сверху справа к непроизводному элементу «вертикальный отрезок прямой» непроизводного элемента «горизонтальный отрезок прямой» [на самом деле проверяется примыкание к комбинации (подобразу) вертикального и горизонтального непроизводных элементов]; в узле 4 — наличие примыкания в середине непроизводного элемента «вертикальный отрезок прямой» справа непроизводного элемента «горизонтальный отрезок прямой» (с той же оговоркой, что и в угле 3).
Очевидно, что в более сложных случаях из одного узла могут выходить не две ветви, а несколько; например, проверка наличия примыкания к нижней части непроизводного элемента «вертикальный отрезок прямой» непроизводного элемента «горизонтальный отрезок прямой» справа, справа и слева одновременно либо отсутствия примыкания горизонтального непроизводного элемента.
Реализация процесса распознавания с помощью грамматического разбора. Значение формальных грамматик для распознавания заключается, в частности, в том, что они позволяют говорить о синтаксической правильности или неправильности применительно к определенной грамматике представления изучаемого образа с помощью заданных непроизводных элементов и отношений. Ответ на этот вопрос позволяет получить процедура, называемая грамматическим разбором.
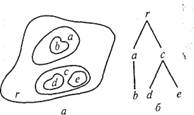
Рис. 8.6
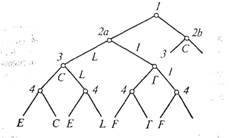
Рис. 8.7
Используют два основных вида грамматического разбора: разбор сверху вниз и разбор снизу вверх. Процедура разбора сверху вниз состоит в последовательных попытках путем использования правил соответствующей грамматики получить заданное терминальное предложение исходя из начального символа. При использовании процедуры разбора снизу вверх необходимо восстанавливать дерево вывода, начиная с элементов основного словаря и применяя инвертированные правила подстановки. Эта процедура начинается с конкретного предложения и заканчивается при получении начального символа. Так, непроизводный элемент а, входящий в предложение аb (см. последний пример), может быть получен как в результате перехода D®a, так и в результате перехода 1®аА; элемент D возникает в результате подстановки I®dD, так что этот вывод не приводит к получению предложения ab. Так как подстановки I®aA и А-+b действительно порождают предложение ab, то это предложение считается грамматически правильным; предложения же ас и ad отклоняются.
Описанные схемы грамматического разбора, в принципе, неэффективны, так как предусматривают проведение полного перебора при применении правил подстановки. Часто можно избежать воспроизведения всей последовательности применения правил подстановки, так как можно проверять допустимость промежуточных результатов, выясняя тем самым, обеспечивает ли данная последовательность правил успешный грамматический разбор.
Повышение эффективности грамматического разбора можно обеспечить с помощью учета синтаксических правил, устанавливающих допустимые или запрещающих какие-то специфические отношения между объектами.
Пример [14]. Рассмотрим грамматику Г = {V, W, I, R}, где V={a1, a2}, W= {I, О1, О2},

способную порождать квадраты [непроизвольные элементы представляют собой горизонтальный и вертикальный отрезки прямой фиксированной длины (рис. 8.8, в)]; отношения выше (х, у) и слева (х, у) читаются соответственно «х расположен над у» и «х расположен слева от у», при этом часть х обязательно находится непосредственно над отрезком у и часть отрезка х во втором случае находится непосредственно слева от отрезка у.

Рис. 8.8
Последовательное применение правил грамматики приводит к получению структур, приведенных на рис. 8.8, б. Их построение начинается с горизонтального отрезка, затем вводится еще один горизонтальный отрезок, расположенный над первым, после чего между ними помещаются два вертикальных отрезка. Разнообразие конструкций обеспечивается наложением ограничений на позиционные отношения выше и слева.
Проиллюстрируем на примере, приведенном выше, порядок выполнения синтаксически ориентированного грамматического разбора. Пусть требуется установить, принадлежит ли некоторая конструкция к классу объектов, порождаемых данной грамматикой. При разборе снизу вверх в первую очередь делается попытка обнаружить объект О1 с помощью вхождения в объект непроизводного элемента а2 слева от непроизодного элемента а2. В положительном случае разбор продолжается, в отрицательном — исследуемый объект отклоняется. Поскольку процедура разбора снизу вверх начинается с терминального предложения, на первом шаге рассматриваются только правила подстановки, приводящие исключительно к непроизводным элементам. На следующем шаге разбора необходимо получить объект О2, состоящий из объекта О1 расположенного над непроизводным элементом а1. При положительном результате предпринимается попытка вывести начальный символ 1, отыскивая непроизводный элемент а1 расположенный над объектом О2. При положительном результате образ считается допустимым, при отрицательном — отклоняется. На рис. 8.8, б представлены грамматически правильные объекты, на рис. 8.8, в — объекты, отклоненные на одном из шагов разбора.
Вывод грамматик. Рассмотрим на конкретном примере способ получения грамматики, пригодной для описания объектов в рамках структурного подхода к распознаванию, с помощью процедуры обучения. В сущности, искомая грамматика формируется на основании изучения конечной выборки предложений некоторого языка, причем иногда при этом учитывается и конечная выборка предложений, не относящихся к данному языку. Элементы первой выборки должны обладать структурной полнотой в том смысле, что каждое правило искомой грамматики используется при порождении, по крайней мере, одного предложения выборки.
На рис. 8.9 [14] представлена схема вывода цепочечных грамматик. Задача заключается в том, что множество выборочных цепочек {хi} подвергается обработке с помощью адаптивного обучающего алгоритма (на рисунке он назван алгоритмом вывода). На выходе блока в результате процесса обучения воспроизводится грамматика Г, согласованная с заданными цепочками. Процедура, позволяющая решить указанную задачу в общем случае, до сих пор неизвестна; существует, однако, множество частных алгоритмов. Типичным подходом в этой области можно считать следующий. Сначала строятся правила подстановки, порождающие именно те цепочки, которые были заданы; затем посредством сращивания элементов основного словаря — более простая рекурсивная грамматика, обеспечивающая порождение бесконечного числа цепочек. Процедура состоит из трех этапов: 1) формирования правил подстановки; 2) преобразования правил подстановки в грамматику; 3) упрощения грамматики.
На примере двумерной грамматики продемонстрируем ее вывод, поскольку, как указывалось выше, именно этот тип грамматик представляет в настоящее время наибольший интерес с прикладной точки зрения. Предполагается, что заданы конечный набор отношений, конечный список элементов основного словаря, т. е. непроизводных элементов, и некоторое множество описаний объектов {S1,..., Sn}. Каждое описание содержит список входящих в него непроизводных элементов, каждый из которых может быть снабжен какой-либо дополнительной информацией. Задача состоит в определении «хорошего» набора правил грамматики, записанных через заданные отношения и согласующихся с заданным набором объектов. Таким образом, следует сформировать грамматику такую, чтобы при введении в грамматический анализатор любого из заданных объектов и разборе его в соответствии с полученной грамматикой на выходе анализатора воспроизводилось одно или несколько структурных описаний объекта.
Первый шаг процесса вывода выполняется отдельно и независимо для каждого «входного» объекта. В результате этого шага должна выявиться структура, задаваемая выбранной системой отношений — в данном случае предикатов, характеризующих как свойства непроизводных элементов, так и отношения между ними. На этом же шаге для каждого элемента объектов проверяется справедливость на них предикатов. При положительном исходе такой проверки формируется новый элемент и информация о соответствующих импликантах и истинности предиката фиксируется в виде некоторого правила грамматики. Затем выполняется следующий цикл, в котором предикаты проверяются на элементах, построенных из новых элементов и элементов входных объектов; процедура повторяется до тех пор, пока построение новых элементов оказывается невозможным. В каждом очередном цикле, естественно, проверяются лишь те описания, которые содержат хотя бы один элемент, сформированный в предыдущем цикле.
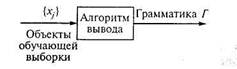
Рис. 8.9
По окончании первого шага проверяют, какие из элементов включают в качестве своих импликант все непроизводные элементы соответствующего входного объекта. Все не прошедшие проверку описания и описания, входящие в качестве импликант в описания, прошедшие проверку, из дальнейшего рассмотрения исключаются. Соответственно исключаются и все правила грамматики, не использовавшиеся при построении оставленных описаний. Полученные таким образом описания являются некоей разновидностью деревьев структурных описаний, которые сначала подвергаются «чистке» (в частности, отождествляются деревья, оказывающиеся эквивалентными в результате замены конкретных непроизводных элементов их типами).
Для каждого входного объекта таким образом строится одна или несколько грамматик, соответствующих различным структурным описаниям, получаемым для входного объекта. Лишь те элементы вспомогательного словаря соответствуют высшему уровню описания — описанию объекта в целом, которые встречаются более чем в одной из построенных грамматик.
Второй шаг процесса вывода состоит в следующем. Строится объединение грамматик, полученных на первом шаге для каждого из объектов. К каждой из этих грамматик применяется специальная процедура преобразования и из полученных модифицированных грамматик, согласно некоторому критерию, выбирается наилучшая. Предпочтение, естественно, отдается коротким грамматикам, поскольку такие, действительно, являются единой грамматикой для заданной обучающей выборки, а не просто набором частных случаев. Однако целесообразно, чтобы правила подстановки были как можно конкретнее в том, что касается возможных типов непроизводных элементов и отношений. Очевидно, что окончательный критерий выбора грамматики должен базироваться на какой-то комбинации двух этих эвристических приемов.
Преобразование грамматики.
1. Устраняются все избыточные вхождения правил, если какое-то правило входит в преобразуемую грамматику Г несколько раз.
2. Отыскивается такая пара элементов вспомогательного словаря, что отождествление этих элементов (замена одного другим во всей грамматике) приведет к появлению избыточных вхождений правил. При наличии различных вариантов выбора таких пар следует выбирать пару, приводящую к наибольшему числу избыточных вхождений. После отождествления правил следует вернуться к шагу 1.
3. Отыскивается такая пара N, n, включающая элемент вспомогательного словаря N и непроизводный элемент n, что включение в грамматику Г правила N®n (если оно в нее не входит) и выборочная замена N на и в грамматике Г приводят после устранения множественности вхождений правил к сокращению их числа. При наличии различных вариантов выбора таких пар следует выбирать пару, обеспечивающую наибольшее сокращение числа правил в грамматике. Затем следует вернуться к шагу 1.
4. Вводится порог по числу отождествляемых на шагах 1—3 правил: замена производится, если число вхождений или отождествляемых правил не меньше значения порога. Это делается для того, чтобы не снижать существенно разделяющую силу грамматики.
5. Вводится порог по числу правил, оказывающихся идентичными во всем (исключение составляет тип непроизводного элемента): если число таких правил больше значения порога или равно ему, то соответствующие правила заменяются одним, содержащим непроизводный элемент произвольного типа. Затем следует вернуться к шагу 1.
Если дальнейшие упрощения невозможны, процедура прекращается. В результате выводится одна грамматика. После того как указанная процедура выполняется для каждой из сформированных на первом этапе грамматик, необходимо выбрать «наилучшую» грамматику. В качестве критерия оптимальности грамматики может быть, например, использовано отношение разделяющей силы грамматики к квадрату числа ее правил, а разделяющая сила грамматики определяется как сумма разделяющих сил каждого из ее правил; последние же определяются как сумма количества входящих в него непроизводных элементов и термов, представляющих отношение или свойство.
Пример [30]. Рассмотрим ситуацию, когда предъявляется только один входной объект, представленный на рис. 8.10, а. Здесь непроизводные элементы принадлежат к следующим типам: окружность, точка, квадрат, отрезок прямой.
Пусть заданы следующие предикаты: слева (х, у) (выполняется, если элемент х находится слева от элемента у); выше (х, у) (выполняется, если элемент х находится выше элемента у); внутри (х, у) (выполняется, если элемент х находится внутри элемента у).
В данном случае входной объект представляется перечнем, включающим пять непроизводных элементов: точка (два), окружность, квадрат и отрезок прямой. Вначале выделяются все случаи, когда элементы входного списка удовлетворяют одному из заданных предикатов. Каждый выполненный предикат образует новый элемент. Проверяется, какие новые элементы можно построить из исходных вновь образованных, затем эта процедура повторяется с очередными построенными элементами и так до тех пор, пока возможности построения новых элементов не окажутся исчерпанными. После этого удаляются все элементы, не являющиеся компонентами некоторого элемента, содержащего все непроизводные элементы входного объекта. Практически это выглядит следующим образом. Непроизводные элементы снабжены номерами 1—5, нумерация новых элементов начинается с 6.
Пусть, например, обнаружен элемент выше (4, 5) — соответствующий предикат выполняется, а компонентами нового элемента служат непроизводные элементы 4 и 5. Полный список всех элементов, которые можно построить из непроизводных элементов, имеет следующий вид:
Цикл 1. 6. (4, 5): выше (4, 5). 7. (1, 2): внутри (2,1). 8. (1, 3): внутри (3,1). 9. (1, 4): внутри (4, 1). 10. (1, 5): внутри (5, 1). 11. (2, 3): слева (2, 3). 12. (1, 2, 3); слева (2, 3) внутри (2, 1) внутри (3, 1). 13. (1, 4, 5): выше (4, 5): внутри (4, 1) внутри (5, 1). Цикл 2.14 (1, 6): внутри (б, 1). 15. (1, 11): внутри (11,1). 16. (4, 11): выше (И, 4). 17. (5, 11): выше (11, 5). 18. (6, 11): выше (11, 6). Цикл 3. 19. (1, 16): внутри (1, 16). 20. (1, 17): внутри (1, 17). *21. (1, 18): внутри (1, 18). 22. (5, 17): выше (16, 5). *23. (1,22): внутри (22, 1).
Два отмеченных звездочками элемента соответствуют двум структурным описаниям входного объекта, которые удалось построить. Соответствующие деревья представлены на рис. 8.10, б, в.
Каждое из полученных таким образом структурных описаний непосредственно переводится в грамматику (при этом символы Г1, Г2, ГЗ, ... используются по мере необходимости для обозначения элементов вспомогательного словаря, а элементы основного словаря заменяются непроизводным элементом определенного типа).
Итак, две построенные грамматики имеют следующий вид: грамматика 1. 1®(х, у): Г1 (х), окружность (у): внутри (х, у): Г1® (х, у): Г2 (х), отрезок прямой (у): выше (х, у): Г2® (х, у): Г3 (х), квадрат (у): выше (х, у): Г3® (х, у): точка (х), точка (у): слева (х, у);
грамматика 2. 1® (х, у): Г4(х), окружность (х): внутри (х, у); Г4® (х, у); Г5(х), Г6(у): выше (х, у); Г5® (х, у): точка (х), точка (у): слева (х, у); Г6® (х, у): квадрат (х), отрезок прямой (у); выше (х, у).
Структурный подход к распознаванию не располагает еще стройной и строгой математической теорией — это направление распознавания переживает сейчас период развития и пока должно
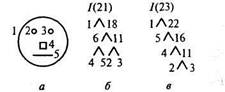
Рис. 8.10
рассматриваться как некий комплекс практически работающих эвристических приемов. Основные области приложения структурного распознавания в настоящее время — обработка и анализ сигналов различной природы, двумерных и трехмерных изображений. Практика построения систем распознавания свидетельствует о том, что структурные методы целесообразно использовать совместно с другими методами распознавания объектов и явлений. Степень применимости структурных методов будет определяться развитием их математической теории и наличием ориентированных на его использование диалоговых вычислительных систем.
Глава 9 УПРАВЛЕНИЕ ПРОЦЕССОМ РАСПОЗНАВАНИЯ ОБЪЕКТОВ И ЯВЛЕНИЙ
Один из наиболее существенных критериев эффективности системы распознавания — вероятность правильного решения ею задач распознавания неизвестных объектов. При прочих равных условиях, в частности в условиях оптимальной обработки апостериорной информации, значение этого критерия тем выше, чем больший объем измерительной информации используется при распознавании данного объекта. Более того, при определенных ограничениях, накладываемых на признаки, когда v — число признаков, используемых при распознавании возрастает, увеличивается вероятность однозначного решения задачи распознавания и при v®¥ стремится к единице.
Однако в физически реализуемых системах распознавания число используемых признаков ограничено. Более того, при распознавании конкретных объектов иногда нецелесообразно использовать весь набор признаков рабочего словаря. Связано это с тем, что определение каждого признака требует проведения соответствующего эксперимента и, следовательно, сопряжено с затратами материальных и временных ресурсов. В то же время объекты некоторых классов могут распознаваться с заданным уровнем вероятности правильного решения и при использовании лишь части признаков рабочего словаря. В подобной ситуации предельно возможное накопление измерительной информации неоправданно, а рационально процесс определения признаков распознаваемого объекта завершать в каждом конкретном случае на определенном шаге. Именно в связи с этим возникают рассматриваемые ниже задачи оптимизации процесса распознавания. Их постановка и методы решения базируются на последовательных алгоритмах оптимизации, разработанных акад. В. С. Михалевичем [31].