Самообучающиеся системы распознавания
На практике иногда приходится сталкиваться с необходимостью построения распознающих устройств в условиях, когда провести классификацию объектов либо невозможно, либо по тем или другим соображениям нецелесообразно. В качестве примера можно сослаться на необходимость классификации некоторой совокупности объектов таким образом, чтобы в один класс были объединены объекты, значения отдельных параметров которых находятся в пределах определенных, заранее заданных диапазонов.
Пусть, например, сигналы изучаемой совокупности характеризуются параметрами х1, х2, х3, ... . Требуется так осуществить классификацию, чтобы в один класс были объединены объекты, значения параметров которых удовлетворяют, например, условиям x1³x1*; x2£x2*; x3** <х3£х3*; ..., в другой класс — объекты, значения параметров которых удовлетворяют условиям х1 <х1**, х2>х2**; x3*<x3£x3***; ..., где x1*, x1**, х2*, x2**, x3**, х3*** — некоторые фиксированные числа.
В рассматриваемой ситуации число классов заранее не известно, поэтому информации о принадлежности каких-либо объектов к тем или другим классам нет и единственный путь формирования системы распознавания —• применение методов самообучения, которые получили также наименование таксономии (от греч. taxis — расположение, строй, порядок и nomos — закон), кластер-анализа, автоматической классификации без учителя. К самообучению приходится прибегать и тогда, когда хотя заранее и известно число классов, однако обучающая выборка не дана — имеется лишь некоторая совокупность объектов и значения признаков, которыми они характеризуются, т. е. даны объекты w1 ..., wl и величины х11, ..., х1N; х21, ..., х2N, ..., хl1, ..., xlN, но не указано, к каким классам относятся эти объекты. При этом необходимо обратить внимание на то, что построение самообучающихся систем распознавания и в одном, и другом случаях базируется на известном, заранее выбранном априорном словаре признаков [13].
Задачи таксономии возникают в самых различных отраслях науки и техники. Например, в экономике, для проведения сравнительного анализа эффективности функционирования промышленных объектов, возникает задача такого подразделения анализируемой совокупности предприятий на группы (классы), при которой в каждую группу попадали бы предприятия, в некотором смысле подобные друг другу (скажем, с точки зрения фондовооруженности, объема валовой продукции, численности работающих и т. п.). В информатике при построении банков данных различного назначения (документов, текстов, деталей, нормативов, норм и т. п.), которые назовем объектами, для обеспечения эффективности информационно-поисковых систем, предназначенных для извлечения по запросам нужной информации из банков, также возникает задача подразделения исходного множества объектов на некоторое количество таксонов (кластеров), в пределах которых объекты в каком-то смысле близки друг другу.
Процедура самообучения при неизвестном числе классов. Рассмотрим, как может быть организована процедура самообучения, когда число классов неизвестно [8]. Пусть выбрано признаковое пространство, описываемое вектором  Даны некоторая совокупность объектов w1 ..., wl, и значения векторов
Даны некоторая совокупность объектов w1 ..., wl, и значения векторов 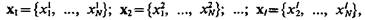 которыми описываются эти объекты.
которыми описываются эти объекты.
Обозначим P(Ωi) вероятность появления объекта класса Ωi, a fi(x) — условную плотность распределения значений признаков внутри Ωi -го класса. Хотя функции P(Ωi) и fi(х) неизвестны, однако относительно совместной плотности распределения вероятностей

(3.51)
естественно предположить, что конструктор системы распознавания так определил условия, на основе которых в результате самообучения будет осуществлена классификация объектов, что «центрам» классов в признаковом пространстве соответствуют существенные максимумы функции f(x). Именно поэтому цель самообучения — на основе показов векторов х1 ..., xl и заданных условий объединения объектов в классы определить совместную плотность распределения, найти ее существенные максимумы, а следовательно, и «центры» классов и тем самым их число m.
Для решения задачи воспользуемся алгоритмами обучения, основанными на методе стохастической аппроксимации. Положим, что искомая совместная плотность распределения может быть аппроксимирована конечным набором ортонормированных функций jj(х):

(3.52)
Если обозначить f(x) функцию истинной плотности распределения, то функционал
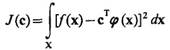
(3.53)
будет характеризовать квадратичную меру уклонения искомой плотности распределения от истинной. Задача состоит в том, чтобы найти такое оптимальное значение вектора с=с°, которое минимизирует функционал

(3.54)
В силу того, что компоненты вектор-функции j(х) ортонормированы, оптимальное значение вектора с
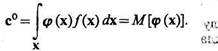
(3.55)
Таким образом, оптимальное значение вектора с0 равно математическому ожиданию вектор-функции j(х), значения реализаций которой могут быть получены на основании априорной информации — величин компонентов векторов х1 ..., хl.
Для определения с0 воспользуемся алгоритмом обучения. Тогда

(3.56)
Если положить g[n] = 1/n, обеспечивающим минимум дисперсии оценки с при любом фиксированном значении n, то
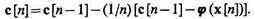
(3.57)
Найдя значение с0 и подставив его в (3.55), определим функцию (х, с0). Ее анализ и выявление существенных максимумов позволяют определить число классов, к которым могут быть отнесены объекты изучаемой совокупности. Это обеспечивает возможность решения задачи, состоящей в определении границ классов и рассматриваемой в гл. 4.
Изложенный способ построения самообучающейся системы распознавания, основанный на методе стохастической аппроксимации, носит достаточно общий, универсальный характер, однако его реализация в реальных условиях сопряжена с известными затруднениями. В то же время на практике для решения задач таксономии используются сравнительно несложные методы, основанные на измерении меры сходства, заданной расстоянием в признаковом пространстве х = {х1 ..., хN} между парами объектов wk, wl k, 1=1, ..., n.
Для определения расстояния между объектами wk и wl может быть использовано соотношение
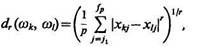
где хkj и хlj — значения l-го признака у k-го и l -го объекта, соответственно; {xj1 ..., xjp} Î {х1 ..., xN} — подмножество признаков, используемое для вычисления расстояния; r — целое положительное число.
Чаще используется метрика, основанная на понятии эвклидово расстояние. Для выделения кластеров необходимо задать пороги. Если d(wk, wl)<dпop, то объекты wk, wl заключаются в один кластер.
В общем случае, когда значимость признаков с точки зрения их вклада в классификацию различна и, кроме того, признаки статистически зависимы, то для формирования кластеров пользуются обобщенным (взвешенным) расстоянием Махаланобиса
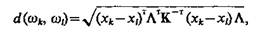
где хk и xl — значения признаков объектов wk и w, соответственно, используемые при кластеризации; К — ковариационная матрица; L — симметричная неотрицательно-определенная матрица весовых коэффициентов, которая чаще всего выбирается диагональной [14].
Для разбиения исходного множества объектов на кластеры может быть использована последовательность действий, имеющих такую геометрическую интерпретацию.

Рис. 3.1
1. Производится нумерация объектов, например, в порядке возрастания значения какого-либо признака (рис. 3.1). На рисунке в целях наглядности признаковое пространство ограничено признаками x1 и x2.
2. Проводятся линии, параллельные осям, из точки, соответствующей объекту w1 и на них откладываются значения порогов dd1пор и dd2пор. Из концов полученных отрезков проводятся линии, параллельные осям. Так формируется первый кластер — класс объектов Ω1.
3. Выполняется та же последовательность операций применительно к точке, соответствующей ближайшему к классу Ω1 объекту (в данном случае w9), при этом формируется новый кластер — класс объектов Ω2 и т. д. Естественно, что приведенному «геометрическому» описанию алгоритма таксономии соответствует и «алгебраическое» описание, позволяющее его программно реализовать на ЭВМ.
Глава 4 ВЕРОЯТНОСТНЫЕ СИСТЕМЫ РАСПОЗНАВАНИЯ ОБЪЕКТОВ И ЯВЛЕНИЙ
Анализ характера задачи распознавания объектов или явлений в случае, когда характер признаков вероятностный, т. е. когда между признаками объектов и классами, к которым они могут быть отнесены, существуют вероятностные связи, показал, что построение алгоритмов распознавания может быть основано на результатах теории статистических решений. При полной исходной априорной информации эти результаты могут быть использованы непосредственно. При неполной исходной информации эти результаты могут быть использованы лишь путем реализации процедуры обучения или самообучения.