Генетические алгоритмы.
Генетический алгоритм (англ. genetic algorithm) — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию. Является разновидностью эволюционных вычислений, с помощью которых решаются оптимизационные задачи с использованием методов естественной эволюции, таких как наследование, мутации, отбор и кроссинговер. Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе.
Описание алгоритма
Задача формализуется таким образом, чтобы её решение могло быть закодировано в виде вектора («генотипа») генов, где каждый ген может быть битом, числом или неким другим объектом. В классических реализациях ГА предполагается, что генотип имеет фиксированную длину. Однако существуют вариации ГА, свободные от этого ограничения.
Некоторым, обычно случайным, образом создаётся множество генотипов начальной популяции. Они оцениваются с использованием «функции приспособленности», в результате чего с каждым генотипом ассоциируется определённое значение («приспособленность»), которое определяет насколько хорошо фенотип, им описываемый, решает поставленную задачу.
При выборе «функции приспособленности» (или fitness function в англоязычной литературе) важно следить, чтобы её «рельеф» был «гладким».
Из полученного множества решений («поколения») с учётом значения «приспособленности» выбираются решения (обычно лучшие особи имеют большую вероятность быть выбранными), к которым применяются «генетические операторы» (в большинстве случаев «скрещивание» — crossover и «мутация» — mutation), результатом чего является получение новых решений. Для них также вычисляется значение приспособленности, и затем производится отбор («селекция») лучших решений в следующее поколение.
Этот набор действий повторяется итеративно, так моделируется «эволюционный процесс», продолжающийся несколько жизненных циклов (поколений), пока не будет выполнен критерий остановки алгоритма. Таким критерием может быть:
* нахождение глобального, либо субоптимального решения;
* исчерпание числа поколений, отпущенных на эволюцию;
* исчерпание времени, отпущенного на эволюцию.
Генетические алгоритмы служат, главным образом, для поиска решений в многомерных пространствах поиска.
Таким образом, можно выделить следующие этапы генетического алгоритма:
1. Задать целевую функцию (приспособленности) для особей популяции
2. Создать начальную популяцию
* (Начало цикла)
1. Размножение (скрещивание)
2. Мутирование
3. Вычислить значение целевой функции для всех особей
4. Формирование нового поколения (селекция)
5. Если выполняются условия остановки, то (конец цикла), иначе (начало цикла).
Создание начальной популяции
Перед первым шагом нужно случайным образом создать начальную популяцию; даже если она окажется совершенно неконкурентоспособной, вероятно, что генетический алгоритм все равно достаточно быстро переведет ее в жизнеспособную популяцию. Таким образом, на первом шаге можно особенно не стараться сделать слишком уж приспособленных особей, достаточно, чтобы они соответствовали формату особей популяции, и на них можно было подсчитать функцию приспособленности (Fitness). Итогом первого шага является популяция H, состоящая из N особей.
Размножение (Скрещивание)
Размножение в генетических алгоритмах обычно половое — чтобы произвести потомка, нужны несколько родителей, обычно два.
Размножение в разных алгоритмах определяется по-разному — оно, конечно, зависит от представления данных. Главное требование к размножению — чтобы потомок или потомки имели возможность унаследовать черты обоих родителей, «смешав» их каким-либо способом.
Почему особи для размножения обычно выбираются из всей популяции H, а не из выживших на первом шаге элементов H0 (хотя последний вариант тоже имеет право на существование)? Дело в том, что главный бич многих генетических алгоритмов — недостаток разнообразия (diversity) в особях. Достаточно быстро выделяется один-единственный генотип, который представляет собой локальный максимум, а затем все элементы популяции проигрывают ему отбор, и вся популяция «забивается» копиями этой особи. Есть разные способы борьбы с таким нежелательным эффектом; один из них — выбор для размножения не самых приспособленных, но вообще всех особей.
Мутации
К мутациям относится все то же самое, что и к размножению: есть некоторая доля мутантов m, являющаяся параметром генетического алгоритма, и на шаге мутаций нужно выбрать mN особей, а затем изменить их в соответствии с заранее определёнными операциями мутации.
Отбор
На этапе отбора нужно из всей популяции выбрать определённую её долю, которая останется «в живых» на этом этапе эволюции. Есть разные способы проводить отбор. Вероятность выживания особи h должна зависеть от значения функции приспособленности Fitness(h). Сама доля выживших s обычно является параметром генетического алгоритма, и её просто задают заранее. По итогам отбора из N особей популяции H должны остаться sN особей, которые войдут в итоговую популяцию H'. Остальные особи погибают.

Генетические алгоритмы применяются для решения следующих задач:
1. Оптимизация функций
2. Оптимизация запросов в базах данных
3. Разнообразные задачи на графах (задача коммивояжера, раскраска, нахождение паросочетаний)
4. Настройка и обучение искусственной нейронной сети
5. Задачи компоновки
6. Составление расписаний
7. Игровые стратегии
8. Теория приближений
9. Искусственная жизнь
10. Биоинформатика (фолдинг белков)
25. Иерархическое представление проектной информации (уровни абстрагирования, детализации), направления разработки системы: "сверху - вниз", "снизу-вверх", "изнутри - к границам", "от границ - внутрь".
Проектирование ПС на ранних стадиях характеризуется высокой неопределенностью исходных данных и представлений разработчиков о свойствах и функциях создаваемой системы.
Уровни абстрагирования определяют систему понятий (модель абстракции), привлекаемых для описания инженерных решений. Уровни представления определяются в рамках конкретной предметной области, методики моделирования, могут регламентироваться различными стандартами.
Уровень абстрагирования будем сопоставлять с видом моделей абстракций, а переход по уровням абстрагирования – с переходом на новый вид модели абстракций.
Уровни детализации определяют степень детализации элементов и связей компонент моделируемой системы при описании ее на одном уровне абстрагирования. Уровни детализации могут регламентироваться конкретными методиками моделирования.
Под уровнем детализации будем понимать соответствующий иерархический уровень в модели абстракций (модель абстракций – иерархическая структура).
Уровни определенности характеризуют форму описания моделей. Наиболее существенными уровнями определенности являются концептуальный уровень, логический уровень и физический уровень.
· Концептуальный уровень – содержательное описание модели исходя из содержательного процесса управления. Характеризуется неформальными (слабо формализованными) средствами описания инженерных решений.
· Логический уровень – представление моделей системы с использованием типового математического аппарата, на основе которого можно проводить анализ и синтез структур и адекватно отображать с заданной степенью соответствия реальные процессы. Характеризуется формально обоснованными инженерными решениями.
· Физический уровень – описание модели системы на уровне программно-аппаратных средств реализации. Характеризуется практической выполнимостью моделей абстракций на программном уровне.
· Направления, в котором ведется разработка системы: "сверху - вниз", "снизу-вверх" , "изнутри - к границам", "от границ - внутрь".
С точки зрения направления, в котором ведется разработка проекта системы, различают стратегии "сверху - вниз", "снизу-вверх" , "изнутри - к границам", "от границ - внутрь" .
Рис. 2.1. Функциональная декомпозиция по принципу "сверху-вниз".

Рис. 2.1. Функциональная декомпозиция по принципу "сверху-вниз".
одна сложная функция F; нисходящая функциональная декомпозиция продолжается далее путем разложения F на подфункции, которые в свою очередь, тоже разбиваются на подфункции и т.д.
Рис. 2.2. Функциональный синтез по принципу "снизу-вверх".
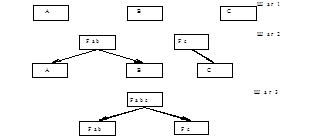
Рис. 2.2. Функциональный синтез по принципу "снизу-вверх".
исходные функции группируются в агрегированные функции все более высокого уровня, пока не будет достигнута вершина системы, которую можно рассматривать как одну сложную функцию.
Рис. 2.3. Функциональный синтез и декомпозиция по принципу "изнутри к границам".

Рис. 2.3. Функциональный синтез и декомпозиция по принципу "изнутри к границам".
проблемы
1 обе стратегии предполагают наличие у системы какой-либо определенной вершины, где управление через некоторый интерфейс передается от системы внешнему автономному объекту.
2 не принимается во внимание никакая информация: вопросы прохождения данных, совместного их использования и построения вложенных структур оставляются для выяснения после завершения процедур функциональной декомпозиции или синтеза. Потоки информации и структура данных становятся, таким образом, категориями, подчиненными по отношению к задачам управления.
3 они сильно затрудняют установление четких критериев оценки получающихся в результате структур. Поэтому разные разработчики будут завершать эту фазу проектирования с совершенно различными результатами функциональной декомпозиции.