рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Философия
- /
- СОРТУВАННЯ
Реферат Курсовая Конспект
СОРТУВАННЯ
СОРТУВАННЯ - раздел Философия, ПРОГРАМУВАННЯ 1.1 Методи Сортування Сортувати Можн...
1.1 Методи сортування
Сортувати можна дані будь-якого базового типу, представлені в довільному вигляді, однак найчастіше сортувати потрібно масиви та зв’язані списки. Постановкою задачі може бути визначений будь-який порядок розташування елементів у посортованому наборі, найчастіше за зростанням або спаданням. Це не змінює суті методів сортування, але для спрощення викладу тут матеріалу будемо вважати, що – за зростанням.
За способом зберігання даних у пам’яті комп’ютера розрізняють два види сортування: внутрішнє і зовнішнє. Алгоритм внутрішнього сортування використовує тільки оперативну пам’ять, коли зчитування/запис даних відбувається за один прохід. При зовнішньому сортуванні використовується зовнішня пам’ять, наприклад жорсткі диски, і виконується декілька зчитувань та записів. Зовнішнє сортування застосовується для обробки даних, які не поміщаються в оперативній пам’яті. Тип сортування (внутрішнє чи зовнішнє) визначається не фізичними параметрами обчислювальної системи, а алгоритмом. Алгоритм зовнішнього сортування може використовувати віртуальну пам’ять і велику частину часу працювати з диском.
Оцінювати ефективность алгоритму сортування можна за різними параметрами, з них найважливішим є його швидкодія або час виконання програми. Оскільки всі алгоритми сортування, як правило, містять цикли й розгалуження, то при цьому береться до уваги кількість порівнянь та число перестановок елементів у наборі даних. Як одиницю виміру ефективності методу застосовують 0-нотацію, вона враховує загальну кількість циклічного перебору елементів масиву даних у відношенні до n – числа всіх елементів. Якщо, наприклад, під час сортування масиву довжиною n число перебору елементів дорівнює n або близьке до нього, то говорять, що 0-нотація має порядок n.
Час виконання програми для абсолютної більшості методів сортування залежить від вигляду даних, але 0-нотація кожного з них незмінна, вона характеризує ефективність методу при, так би мовити, найгірших даних.
Розглянемо окремі методи сортування.
Метод виборучи не найпростіший. Під час сортування багаторазово вибирається найменший елемент. За першим разом його міняють місцями з першим елементом, за другим – з другим і т. д. до кінця масиву. Ідея методу полягає в тому, що при кожній перестановці елемент перемещуєтся прямо в необхідне місце. Спочатку ми знаходимо найменший елемент і замінюємо ним перший елемент набору. Потім знаходимо наступний мінімальний елемент у ще не посортованій частині набору і ставимо його на друге місце. Закінчивши цей процес, отримаємо повністю посортований набір. Цей метод тому й називається сортуванням методом вибору, що він оснований на виборі елемента.
Алгоритм реалізований у вигляді програми мовою С, яка показана в прикладі 1.1.
Приклад 1.1 – Демонстрація методу вибору
# include<stdio.h> /* Метод вибору */
unsigned long int cykl = 0, kil = 0;
void s(int *a, int n)
{
int i, j, min, num;
for(i = 0; i<n-1; i++)
{
min = a[i]; num = i;
for(j = i; j<n; j++)
{
if(a[j] < min){min = a[j]; num = j;}
cykl++;
}
a[num] = a[i]; a[i] = min; kil++;
}
return;
}
int main(void)
{
int i, count = 999;
int m[999], dop[9] = {9, 3, 5, 1, 6, 7, 4, 2, 3};
clrscr();
for(i = 0; i<count; i++)m[i] = 0;
for(i = 0; i<9; i++)m[i] = dop[i]; /* cykl = 499499 kil = 998 */
/*for(i = 0; i<9;i ++)m[i+990] = dop[i]; */ /* cykl = 499499 kil = 998 */
for(i = 0; i<count; i++)printf("%2d", m[i]);
s(m, count);
for(i = 0; i<count; i++)printf("%2d", m[i]);
printf("ncykl = %9ld kil = %dn", cykl, kil);
getch( );
return 0;
}
На її початку оголошено дві глобальні змінні типу long int (для цього виду сортування просто тип int може виявитися закоротким): cykl та kil, ініціалізовані нулями. Вони служать для підрахунку відповідно кількості виконань циклів та числа перестановок елементів під час сортування масиву.
Програма складається з двох частин: головної програми main( ) та підпорядкованої функції s(). У головній програми оголошено дві локальні змінні: i – параметр циклу та count – кількість елементів масиву m. У нашому прикладі m = 999. Також оголошено допоміжний масив dop, ініціалізований 9 елементами. Тип даних не впливає на будову алгоритму, тут вибрано тип int.
Головна програма складається з чотирьох послідовних циклів та звернення до функції s(). У першому циклі відбувається ініціалізація масиву m нулями. У другому – допоміжний масив dop вставляється на початок масиву m. Таким чином, передбачається сортування масиву m, перші 9 елементів якого дорівнюють елементам масиву dop, а решта – нулю. Назвемо цей варіант масиву масив 1. Під час виконання програми дослідимо вплив вигляду даних на ефективність алгоритму, тому випробуємо її 2 рази: на вищеописаному масиві m та на цьому ж масиві, але вже останні 9 його елементів будуть містити масив dop, а решта – нулі, назвемо його масив 2. Цикл формування другого варіанту даних тимчасово закоментарений. Решта два цикли служать для дворазового виводу масиву m – до і після сортування.
Процес сортування виконує функція s( ), яка від час виклику з головної програми приймає два параметри: вказівник на масив m та змінну count – кількість елементів, які підлягають сортуванню. На її початку оголошено такі 4 локальні змінні типу int:
‒ i, j – параметри циклів;
‒ min – мінімальне значення масиву a;
‒ num – порядковий номер мінімального елемента.
За своєю структурою цей алгоритм сортування являє собою два вкладені цикли з розгалуженням всередині другого циклу. Перший цикл служить для перебору місць масиву, на які буде покладений черговий мінімальний елемент. Пошук мінімального елемента у ще не посортованій частині масиву відбувається всередині вкладеного циклу шляхом порівняння елементів між собою.
Параметр зовнішнього циклу цього методу змінюється від 0 до n-1 (n разів), а внутрішнього – від i до n (загалом у два рази менше), тому сумарна кількість порівнянь дорівнює n*n/2 = n2/2, отже 0-нотація методу вибору має порядок n2. Це дуже багато, тому метод вибору вважається малоефективним.
Бульбашковий метод передбачає багаторазове, в циклі порівняння двох сусідніх елементів між собою і, якщо наступний елемент є меншим за попередній, то вони переставляються, тобто міняються місцями. Таким чином, менший елемент піднімається (як бульбашка повітря у воді) вгору, а більший опускається вниз. Якщо пройдено весь набір і не зроблено жодної перестановки, то дані вважаються відсортованими і виконання алгоритму припиняється.
Програма, яка демонструє бульбашковий метод, наведена в прикладі 1.2.
Приклад 1.2 – Сортування масиву бульбашковим методом
# include<stdio.h> /* Бульбашковий метод */
long int cykl = 0, kil = 0;
void s(int *a, int n)
{
int i, j, tmp, ind;
for(i = 0; i<n-1; i++)
{ind = 0;
for(j = 1; j<n; j++)
{
if(a[j]<a[j-1]){tmp = a[j]; a[j] = a[j-1]; a[j-1] = tmp; ind++; kil++;}
cykl++;
}
if(ind == 0)break;
}
return;
}
main( )
{int i, count = 999;
int m[999], dop[9] = {9, 3, 5, 1, 6, 7, 4, 2, 3};
clrscr();
for(i = 0; i<count; i++)m[i] = 0;
/* for(i = 0; i<9; i++)m[i] = dop[i]; cykl = 9980 kil = 8932 */
for(i = 0; i<9; i++)m[i+990] = dop[i]; /*cykl = 6986 kil =22 */
for(i = 0; i<count; i++)printf("%3d", m[i]);
s(m, count); getch();
for(i = 0; i<count; i++)printf("%3d", m[i]);
printf("ncykl = %9ld kil = %dn", cykl, kil);
getch( );
}
У процедурі s() цього методу застосовується змінна tmp для тимчасового запам’ятовування значення елемента під час його перестановки та ind – індикатор припинення сортування.
Як і стосовно кількості порівнянь, так і щодо кількості перестановок 0-нотація алгоритму бульбашкового сортування має порядок n2. Найкращий ефект (найменші затрати часу) досягається в тому разі, коли список майже відсортований і малі елементи наприкінці списку відсутні.
Цей метод можна покращити, застосувавши двостороннє бульбашкове сортування, яке іноді називають сортування перемішуванням. Для цього у внутрішній цикл прикладу 1.2 можна додати такий оператор:
if(a[n-j-1]>a[n-j]){tmp = a[n-j]; a[n-j] = a[n-j-1]; a[n-j-1] = tmp; ind++; kil++;}
Тоді перша ітерація проходить так же, як і при стандартному бульбашковому сортуванні, а друга – в протилежному напрямку. Висхідна ітерація дозволяє малим елементами “спливати” тільки на один рівень, а більшим – “потонути” швидше. Однак, це є перевагою лише в тому випадку, коли більша частина малих елементів розташована внизу (наприкінці) масиву.
Метод лінійних вставок до певної міри можна вважати комбінацією двох попередньо розглянених. У процесі виконання програми подібно до методу вибору масив ділиться на дві частини: вже посортовану і ще ні. Межею між ними є значення параметра зовнішнього циклу. Якщо черговий елемент, вибраний у зовнішньому циклі, виявиться меншим, ніж найбільший у вже посортованій частині масиву, то він у внутрішньому циклі пересувається все вище на своє місце бульбашковим методом. Цей метод демонструє програма, подана в прикладі 1.3.
Приклад 1.3 – Метод лінійних вставок
# include<stdio.h> /* Метод лінійних вставок */
int cykl = 0, kil = 0;
void s(int *a, int n)
{
int i, j, tmp;
for(i = 1;i<n; i++)
for(j = i; j>0; j--)
{
cykl++;
if(a[j-1] > a[j]){kil++; tmp = a[j]; a[j] = a[j-1]; a[j-1] = tmp;}
else break;
}
return;
}
main( )
{int i, count = 999;
int m[999], dop[9] = {9, 3, 5, 1, 6, 7, 4, 2, 3};
clrscr( );
for(i = 0; i < count; i++)m[i] = 0;
for(i = 0;i < 9; i++)m[i] = dop[i]; /* cykl = 9927 kil = 8932 */
/* for(i = 0;i<9; i++)m[i+990] = dop[i]; cykl= 1020 kil = 22 */
for(i = 0; i<count; i++)printf("%2d", m[i]);
getch( );
s(m, count);
printf("ncykl = %d kil = %dn", cykl, kil);
for(i = 0; i<count; i++)printf("%2d", m[i]);
getch( );
}
Метод Шелла (Donald Lewis Shell) вважається оптимальним з погляду на складність, особливо для порівняно невеликих наборів даних (до 20 елементів).
Цей метод є узагальненням методу вставок. Він заснований на тому, що сортування методом вставок виконується дуже швидко на майже відсортованому масиві даних. Він також відомий як сортування з убуваючим кроком. На відміну від сортування методом вставок, при сортуванні методом Шелла весь масив не сортується одночасно, але розбивається на декілька сегментів, які сортуються нарізно за допомогою методу вставок.
Для деякої довжини кроку h будемо вважати, що масив складається з h окремих сегментів. Кожний сегмент містить приблизно n, поділене на h, елементів. Після того, як усі сегменти відсортовані, масив поділяється на меншу кількість сегментів (тобто довжина кроку зменшується). Процес повторюється до остаточного сортування всього масиву, коли h стане дорівнювати 1. Цікаво, що, оскільки довжина останнього кроку досягає 1, то можна використовувати будь-яку послідовність довжин кроків. Тим не менше, деякі значення довжини кроків мають переваги над іншими. Найкращу послідовність довжин кроків ще належить знайти. Хоча принцип сортування методом Шелла досить простий, його формальний аналіз утруднений, однак відомо, що при розумному виборі послідовності довжин кроків h його 0-нотація менша за n.
Використання цього методу сортування оправдане наявністю декількох великих елементів у масиві даних. Іноді найбільший елемент може стояти на першому місці. У такому випадку сортування методом вставок на кожному кроці буде перемещувати цей елемент на одну позицію правіше (нижче). Максимальний елемент буде переміщуватися n-1 разів. Іноді поруч з ним знаходяться інші великі елементи. Вони так само, як і максимальний елемент, будуть переміщуватися в кінець масиву. У деяких дуже рідкісних випадках всі елементи масиву розташовуються в зворотному порядку, тоді метод вставок стає найнеефективнішим. Саме в цьому випадку переважає сортування методом Шелла. Вважається, що час сортування за методом Шелла пропорціональний √n.
Припустимо, що в деякий момент часу крок h дорівнює 10, тобто фактично на даному кроці ми виконуємо сортування методом вставок кожного десятого елемента масиву. Елементи в нашому h-підмасиві будуть переміщуватися на одну позицію за один крок у цьому підмасиві, але в самому масиві це – десять позицій, тобто ми знайшли спосіб, за допомогою якого можна переміщувати великі елементи в 10 разів швидше, ніж при сортуванні методом вставок. Ще краще сортування методом Шелла підходить для майже впорядкованого масиву, тому над методом вставок він володіє значними перевагами. Реалізація методу Шелла мовою С приведена в прикладі 1.4.
У цій програмі inc = h – крок, який після кожного сортування сегментів зменшується в 5/11 разів, поки не досягне значення 1.
Приклад 1.4 – Сортування методом Шелла
# include<stdio.h> /* Метод Шелла */
int cykl = 0, kil = 0;
void s(int *a, int n)
{
int i, inc, j, tmp;
for(inc = n; inc >0;)
{
for(i = inc; i<n; i++)
{
j = i; tmp = a[i];
while(j >= inc && (tmp < a[j-inc]))
{
a[j] = a[j-inc]; j -= inc;
cykl++;
}
a[j] = tmp; kil++;
}
inc = ((inc>1) && (inc<5)) ? 1 : 5*inc/11;
}
}
main( )
{
int i, count = 999;
int m[999], dop[9] = {9,3,5,1,6,7,4,2,3};
clrscr();
for(i = 0; i<count; i++)m[i] = 0;
for(i = 0; i<9; i++)m[i] = dop[i]; /* cykl = 47 kil = 7166 */
/* for(i = 0; i<9; i++)m[i+990] = dop[i]; cykl = 9 kil = 7166 */
for(i = 0; i<count; i++)printf("%2d", m[i]);
s(m, count); getch( );
printf("ncykl=%d kil=%dn", cykl, kil); getch( );
for(i = 0; i<count; i++)printf("%2d", m[i]);
getch();
}
Вважається, що час сортування за методом Шелла пропорційний кореню квадратному з n.
Метод Хоара (Charles Antoni Richard Hoare), реалізований за допомогою рекурсії функцій, показано в прикладі 1.5. В даному випадку функція s() має три параметри: a – заданий масив, left – ліва та right – права межа діапазону сортування, який з кожним зверненням до цієї функції зменшується.
Сортування починається з елемента, який знаходиться посередині діапазону (між left і right), його ще називають компарандом. Найкращим варіантом початкового елемента буде середньоарифметичне значення, тобто середнє між максимальним і мінімальним, які будуть крайніми в посортованому масиві і які, як правило, заздалегідь невідомі.
Суть методу полягає в розділенні масиву на дві частини, після чого всі елементи, менші за компаранд, переміщуються бульбашковим методом вліво, а більші – вправо. Далі кожна з цих частин ділиться окремо, а елементи переміщуються тим же способом, поки весь масив не стане посортованим.
Приклад 1.5 – Сортування методом Хоара
# include<stdio.h> /* Метод Хоара */
int cykl1 = 0, cykl2 = 0, kil = 0;
void s(int *a, int left, int right)
{
int i, j, x, y;
i = left; j = right;
x = a[(left + right)/2];
cykl1++;
do{
while((a[i]<x) && (i<right))i++;
while((x < a[j]) && (j > left))j--;
if(i <= j){y = a[i];a[i] = a[j];a[j] = y; i++; j--; kil++;}
cykl2++;
}while(i <= j);
if(left < j)s(a, left, j);
if(i < right)s(a, i, right);
return;
}
main( )
{
int m[999], dop[9] = {9,3,5,1,6,7,4,2,3};
int i, k, count=999;
clrscr( );
for(i=0; i<count; i++)m[i] = 0;
/* for(i = 0; i<9; i++)m[i] = dop[i]; cykl1 = 518 cykl2 = 4522 kil = 4520*/
for(i = 0; i<9; i++)m[i+990] = dop[i]; /*cykl1 = 519 cykl2 = 4508 kil = 4506*/
for(i = 0; i<count; i++)printf("%2d", m[i]);
s(m, 0, count-1); getch( );
for(i = 0;i<count; i++)printf("%2d", m[i]);
getch( );
printf("ncykl1=%d cykl2=%d kil=%dn", cykl1, cykl2, kil);
getch( );
}
Відомо, що рекурсія функцій – циклічний процес, тому під час випробування програми варто підрахувати не лише число, так сказати, чистих циклів, але й кількість звернень до процедури. Для цього тут застосовуються змінні: cykl2 – загальна кількість виконань циклів та cykl1 – кількість звернень до процедури.
Метод Хоара на сьогодні вважається найефективнішим для даних з рівномірним законом розподілу, тому його ще називають методом швидкого сортування. Однак, у ньому застосовується рекурсія функцій, що суттєво його сповільнює, бо додається певний об’єм роботи, пов’язаний з їх обслуговуванням. Через це він матиме перевагу над іншими методами лише у випадку великих масивів даних, які нараховують сотні та більше елементів.
Вважається, що в методі Хоара число порівнянь приблизно дорівнює n*log(n), а кількість перестановок елементів – n*log(n)/6.
Таблиця 1.1 – Дані для порівняння алгоритмів сортування
| Назва методу сортування | Кількість виконань циклів (cykl) | Кількість перестановок (kil) | ||
| Масив 1 | Масив 2 | Масив 1 | Масив 2 | |
| Вибору | ||||
| Бульбашкове | ||||
| Перемішуванням | ||||
| Лінійних ставок | ||||
| Шелла | ||||
| Хоара |
Як уже було вище сказано, під час випробування вищеописаних алгоритмів застосовувалися два варіанти даних: масив 1, перші 9 елементів якого були більші за нуль, а решта дорівнювали нулю, та масив 2, де більші за нуль елементи були розташовані наприкінці масиву. Оскільки в обох варіантах заданого масиву значна кількість елементів дорівнювала нулю, то вона не потребувала сортування. Це дозволило оцінити якість алгоритмів ще й за цією ознакою. Результати випробувань зведені в таблицю 1.1. Зауважимо, що це далеко не всі варіанти даних, які можна використати для оцінки якості алгоритмів. Не врахована кількість часу, затраченого на виконання програм.
Неефективним буде й застосування рекурсивної функції для організації циклічного процесу. Відомо, що вона і транжирить пам’ять, і виконується повільніше, ніж оператор циклу.
Аналізуючи ці результати, можна зробити такі висновки:
‒ у методі вибору вигляд даних не впливає ні на кількість виконань циклів, ні на число перестановок елементів. Крім того, він найгірший за числом виконань циклів (cykl = 499499). Число перестановок kil = 998, тобто kil = count-1;
‒ бульбашкове сортування та метод лінійних вставок більш ефективні, якщо великі елементи масиву знаходяться в кінці масиву (тут kil = 22);
‒ порівняно з просто бульбашковим методом варіант двостороннього сортування дозволяє скоротити число cykl майже в два рази;
‒ метод Шелла має значну перевагу тоді, коли малі елементи знаходяться на початку масиву та коли масив майже посортований;
‒ метод Хоара можна вважати найкращим для даних з рівномірним законом розподілу.
Цей перелік методів сортування далеко не вичерпаний і його можна доповнити. Це, зокрема, такі методи, як Сінглтона, пірамідальне сортування, сортування підрахунком, метод множинних вставок, порозрядне сортування, сортування злиттям та інші. Сьогодні відомо більше десятка різних методів сортування, одні з них кращі в одних випадках, інші переважають у інших. Наприклад, сортування злиттям вигідно застосовувати при зовнішньому сортуванні, коли під час виконання програми в оперативній пам’яті знаходиться лише частина даних, а решта – на диску.
Пошуки ефективних алгоритмів сортування тривають.
1.2 Сортування масиву структур
Зрозуміло, що мова буде йти не про сортування елементів всередині структури, хоча й така задача може бути поставлена, а про масив структур.
Посортувати масив структур можна будь-яким відомим методом, проте це завдання має свою специфіку. Як правило, структури громізкі, великі, тому порівняно з масивами простих даних зростає кількість перестановок (чим більша структура, тим більшу кількість елементів приходиться переставляти) під час використання тих методів, де вони застосовуються. Тоді вирішальним фактором у визначенні 0-нотації методу може стати саме кількість перестановок структур. Ця обставина підказує, що пріоритетним буде метод сортування з якомога меншими кількостями перестановок. Як видно з таблиці 1.1, для даних з рівномірним законом розподілу таким може виявитися метод вибору.
Таблиця 1.2 – Приклад масиву структур
| Код підприємства | Назва підприємства | Місто |
| Харкiвтрансгаз | Харків | |
| Прикарпаттрансгаз | Івано-Франківськ | |
| Київтрансгаз | Київ | |
| Львiвтрансгаз | Львів | |
| Експорттрансгаз | Ужгород | |
| Гадячгазпром | Полтава |
Наведемо приклад, посортуємо дані таблиці 1.2 за назвами міст у порядку зростання. Візьмемо метод вибору. Програма показана в прикладі 1.6, де операцію сортування виконує функція s(). Для порівняння назв міст скористаємося функцією strncmp(). Вона має три параметри: два слова, які порівнюються між собою, та кількість символів, які повинні враховуватися під час порівняння. Ця функція видає довільне від’ємне ціле число, якщо друге слово менше за перше, додатнє, якщо – більше, і нуль – у випадку їх рівності. У прикладі для порівняння слів враховуються дві перші букви (3-й параметр функції strncmp() дорівнює 2), проаналізувавши назви міст, бачимо, що цього достатньо.
Приклад 1.6 – Сортування масиву структур методом вибору
# include<stdio.h> /* Сортування масиву структур методом вибору */
# include<string.h>
struct pidpr{int kod;
char naz[25];
char mst[15];};
void s(struct pidpr *a, int n)
{
int i, j, num;
struct pidpr tmp, min;
for(i = 0; i<n-1; i++)
{
min = a[i]; num = i;
for(j = i; j<n; j++)if(strncmp(a[j].mst, min.mst, 2)){min = a[j]; num = j;}
a[num] = a[i]; a[i] = min ;kil++;
}
return;
}
int main(void)
{int i, count=6;
struct pidpr m[6]={{1, "Харківтрансгаз ", "Харків "},
{2, "Прикарпаттрансгаз", "Івано-Франківськ"},
{3, "Київтрансгаз ", "Київ "},
{4, "Львівтрансгаз ", "Львів "},
{5, "Експорттрансгаз ", " жгород "},
{6, "Гадячтрансгаз ", "Полтава "}};
for(i = 0; i<count; i++)printf("%3d %20s %15sn", m[i].kod, m[i].naz, m[i].mst);
s(m, count); getch(); puts(" ");
for(i = 0; i<count; i++)printf("%3d %20s %15sn", m[i].kod, m[i].naz, m[i].mst);
printf("ncykl = %d kil = %dn", cykl, kil); /* cykl = 20 kil = 5 */
getch( );
return 0;
}
Ця програма практично не відрізняється від вищенаведеної в прикладі 1.1, за виключенням того, що замість масиву чисел маємо масив структур типу pidpr. Відповідно, цей тип має заданий масив m у головній програмі, змінні tmp і min та масив a – у підпрограмі s(). Для перестановки елементів структури використано ту властивість компілятора, що вона дозволяє переприсвоювати всю структуру в цілому, наприклад, a[i] = min, а не кожний її елемент окремо. Це, однак, не зменшує кількість перестановок, а лише скорочує текст програми.
1.3 Сортування зв’язаного списку
Можна виділити два підходи до побудови алгоритму сортування зв’язаного списку. При першому переставляються адреси даних, тобто дані залишаються на місці, в тих же комірках пам’яті, а змінюються лише посилання на них у списку. За другим способом адреси залишаються на своєму місці, а переставляються дані. Перший спосіб можна реалізувати, застосувавши відомі операції вилучення та вставки структур. Він буде вигідним у тому випадку, коли програма має посилання за допомогою адрес на конкретні структури списку без його гортання, тобто містить прямий доступ до структур. Тоді в тих посиланнях не потрібно буде змінювати адреси структур, після сортування вони залишаться такими ж.
Звичайно, що при цьому першому способі адреси списку, або хоча б їх частина, не будуть розташованими в якомусь порядку, а будуть розкиданими по пам’яті в межах списку. Проте, це не викличе додаткових затрат часу на його гортання. В умовах виробництва адреси списку (визначені функцією malloc() під час його редагування), як правило, завжди розкидані, тобто значення кожної адреси можна вважати випадковим числом.
Другий спосіб передбачає переставляння структур, тобто переприсвоєння даних, тому він буде невигідним при наявності у списку великих, об’ємистих структур і матиме перевагу лише у випадку негромізких. Адже, набагато простіше переставити дві адреси, ніж дві структури.
Перестановка адрес має ще й ту перевагу, що їх взагалі можна не переставляти, достатньо лише вставити кожну адресу з мінімальним елементом перед поточною та усунути прогалину, яку вона залишила, шляхом з’єднання попередньої її адреси з наступною.
Це показано на рисунку 1.1, де зверху маємо вигляд списку до перестановки адреси, а внизу – після. Тут k, i – порядкові номери структур у списку.
Зв’язаний список вигідний ще й тим, що в реальних умовах виробництва його часто приходиться пересортовувати кожного разу після доточування черговою структурою. Тоді слід зразу поставити нову структуру в потрібне місце списку й не буде утворюватися прогалина та виникати потреба в її усуванні.
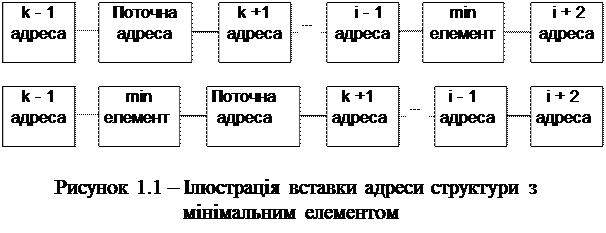
Подібний прийом можна застосувати й під час сортування масиву структур, але тоді прийдеться переставляти всі структури від поточної до місця, яке займала мінімальна, інакше порушиться індексація елементів масиву. Тобто індекси всіх елементів масиву від поточного до того, який передував мінімальному, прийдеться збільшувати на одиницю.
Перестановка адрес подана у прикладі 1.7. В ньому ставиться задача створити та посортувати зв’язаний список у порядку зростання назв міст, використавши дані таблиці 1.2. Для її реалізації застосовується метод вибору мінімального елемента.
Тут список формує головна програма. Сортує – функція s( ), під час її виконання застосовуються такі адреси:
- *head – початок звязаного списку;
- *curr – параметр зовнішнього циклу, гортання списку для вставки адреси з мінімальним елементом;
- *prev – адреса, яка передує curr;
- *curv – параметр внутрішнього циклу, гортання списку під час пошуку мінімального елемента;
- *sort – адреса, яка передує curv;
- *mini – адреса мінімального елемента;
- *prem – адреса, яка передує mini.
Алгоритм сортування являє собою два вкладені цикли типу for. Внутрішній цикл служить для пошуку адреси структури з мінімальним значенням змінної mst (назви міста) подібно до того, як це робилося в програмі прикладу 1.6, і присвоєння цієї адреси змінній mini. Гортання структур у цьому циклі відбувається адресою curv від наступної за адресою структури з мінімальним елементом, знайденим на попередньому кроці пошуку, тобто від curr->dali до останньої. Кількість його виконань зменшується на одиницю при кожному виконанні зовнішнього циклу. Цей цикл містить розгалуження, яке й шукає та запам’ятовує адресу мінімального елемента.
У зовнішньому циклі відбувається гортання списку адресою curr і присвоєння адресі чергової структури, починаючи від head, адреси структури з мінімальним mst. Він має два розгалуження, з яких перше запобігає перестановку адрес, якщо поточна структура з адресою curr і має мінімальний елемент. Така перестановка просто спричинить зайві затрати часу. Друге або вставляє структуру з мінімальним елементом на перше місце (її адреса стає head), або прив’язує до prev, яка передує curr.
Приклад 1.7 – Сортування зв’язаного списку шляхом
перестановки адрес
# include<stdio.h> /* Сортув. зв. списку, перестановка адрес */
# include<stdlib.h>
# include<string.h> /* strcpy( ) */
struct pidpr{int kod;
char naz[25];
char mst[15];
struct pidpr *dali;};
struct pidpr m[6]={{1,"Харківтрансгаз ", "Харків "},
{2,"Прикарпаттрансгаз ", "Івано-Франківськ"},
{3,"Київтрансгаз ", "Київ "},
{4,"Львівтрансгаз ", "Львів "},
{5,"Експорттрансгаз ", "Ужгород "},
{6,"Гадячтрансгаз ", "Полтава "}};
struct pidpr *head=NULL,*prev, *curr, *curv, *prem, *mini, *sort;
int i;
void write(void) /* Функція виводу результатів */
{
for(i = 0,curr = head; curr != NULL;curr = curr->dali)
printf("і = %d adr = %p kod = %d naz = %s mst = %s dali = %pn",
i++, curr, curr->kod, curr->naz, curr->mst, curr->dali);
return;
}
void s(void) /* Функція сортування */
{
for(prev = curr = head;curr->dali != NULL;prev = curr,curr = curr->dali)
{prem = prev; mini = curr;
for(sort = curr, curv = curr->dali; curv != NULL; sort = curv,curv = curv->dali)
if(strncmp(curv->mst, mini->mst, 2)<0){prem = sort;mini = curv;}
if(mini == curr)continue;
if(curr == head)head=mini; else prev->dali = mini;
prem->dali = mini->dali;
mini->dali = curr; curr = mini;
}
return;
}
int main(void) /* Головна програма main */
{
int count = 6;
clrscr();
for(i = 0; i<count; i++)
{
curr = malloc(sizeof(struct pidpr));
if(head == NULL)head = curr; else prev->dali = curr;
*curr = dano[i];
curr->dali = NULL;
prev = curr;
}
puts("Створений список:");
write();
s();
puts("Посортований список:");
write();
return 0;
}
Перестановка структур – порівняно рідкісна операція, як уже було сказано вище, вона невигідна. Функція s() для цього випадку прийме вигляд, показаний у прикладі 1.8. Тут для перестановки структур служить адреса sort як допоміжна.
Приклад 1.8 – Сортування шляхом перестановки структур
void s(void) /* Сортування шляхом перестановки структур */
{
sort = malloc(sizeof(struct pidpr));
for(curr = head;curr->dali != NULL;curr = curr->dali)
{
for(curv = curr->dali, mini = curr; curv != NULL; curv = curv->dali)
if(strncmp(curv->mst, mini->mst, 2) < 0)mini = curv;
*sort = *curr; *curr = *mini; *mini = *sort;
sort->dali = curr->dali; curr->dali = mini->dali; mini->dali = sort->dali;
}
return;
}
2 ПОШУК
2.1 Алгоритми пошуку
Пошук є чи не найпоширенішим завданням, адже перш, ніж використати дані, їх спочатку необхідно знайти. Для виконання пошукових операцій найбільш вдалими можна вважати масиви.
Будова алгоритму пошуку в значній мірі залежить від вигляду даних. Вони можуть бути посортованими або ні, може бути заздалегідь відомо де саме найвища ймовірність знаходження об’єкта пошуку: посередині масиву чи ближче до його початку або кінця, масив може містити одне унікальне відшукуване значення чи декілька. Може статися також, що відшукуване значення відсутнє, тоді виникає задача пошуку найближчого значення до відшукуваного.
Впливає на алгоритм і постановка задачі: відшукується перше ж значення чи всі, які відповідають заданій умові, чи є в наявності додаткові умови та ін. Розглянемо декілька прикладів програмування пошукових операцій.
Послідовний пошук заданого значення масиву виконується в циклі з розгалуженням. Подібне завдання вже розглядалося вище під час пошуку мінімального елемента, програма якого подана в прикладі 1.6 (внутрішній цикл з параметром j). Аналізуючи її, бачимо, що тут кількість порівнянь елементів дорівнює n. Це багато, однак, якщо подібний пошук відбудеться у вже посортованому масиві, то це число скоротиться до одиниці, бо тоді мінімальний елемент завжди буде першим.
Якщо в масиві з рівномірним законом розподілу значень елементів, а це чи не найчастіший випадок, відшукується один перший же заданий елемент, то кількість порівнянь буде мати порядок n/2, бо ймовірність знаходження елемента в першій чи другій половині масиву буде однакова.
В прикладі 2.1 подана програма, яка виконує пошук відомостей про підприємство, розташоване в місті Ужгород, у масиві таблиці 1.2. Тут пошук виконує підпрограма p(). Вона містить усього один цикл типу for з параметром і, який змінюється від 0 до n-1, де n – кількість елементів масиву. Порівняння елементів у циклі виконує стандартна функція strcmp(), яка видає нуль у випадку входження другого свого параметра в перший (тобто, якщо рядок Ужгород входить до складу рядка a[i].mst).
Приклад 2.1 – Послідовний пошук елемента масиву
# include<stdio.h> /* Послідовний пошук 1-го елемента масиву */
# include<string.h>
struct pidpr{int kod;
char naz[25];
char mst[15];};
int p(struct pidpr *a, int n)
{
int i;
for(i = 0; i<n; i++)if( ! strcmp(a[i].mst, "Ужгород"))return i;
}
main( )
{int i, count = 6, k;
struct pidpr m[6] = {{1, "Харківтрансгаз ", "Харків "},
{2, "Прикарпаттрансгаз", "Івано-Франківськ "},
{3, "Київтрансгаз ", "Київ "},
{4, "Львівтрансгаз ", "Львів "},
{5, "Експорттрансгаз ", "Ужгород "},
{6, "Гадячтрансгаз ", "Полтава "}};
clrscr( );
k=p(m, count);
printf("nkod = %d naz = %s mst = %sn", m[k].kod, m[k].naz, m[k].mst);
getch( );
}
kod = 5 naz = Експорттрансгаз mst =Ужгород
Як видно з виданих програмою результатів, кількість порівнянь дорівнювала 5, бо в масиві відшукуваний елемент займав 5-е місце.
Метод половинного ділення ще називають методом дихотомії. Він призначений для пошуку в посортованому масиві.
Суть цього методу полягає в тому, що в циклі вибирається середній елемент масиву, який ділить масив на дві частини, половини: ліву й праву. Якщо він менший за відшукуваний, то для подальшого ділення вибирається права половина, інакше – ліва, тому на кожному кроці область пошуку скорочується вдвоє. Пошук припиняється, коли довжина лівої або правої половини не зменшиться до одного елемента, який і буде відшукуваним.
Як бачимо, цей метод дозволяє суттєво зменшити кількість порівнянь. Його ефективність зростає із збільшенням області пошуку, чим довший масив, тим метод ефективніший. У реальних умовах виробництва якраз найчастіше приходиться обробляти великі масиви даних, що й зумовило широке застосування цього методу. Однак, він працює лише в посортованому масиві.
Вважається, що кількість порівнянь цього методу не перевищує число log2(n).
Нижче в прикладі 2.2 подана програма, де поставлена та ж задача, що і в прикладі 2.1, лише береться вже посортований масив.
Приклад 2.2 – Метод половинного ділення
# include<stdio.h> /* Метод половинного ділення */
struct pidpr{int kod;
char naz[25];
char mst[15];};
int kil = 0;
int s(struct pidpr *a, int n)
{
int i = 0, k;
while(1)
{
k=(n+i)/2; kil++;
if(i == k || n == k)break;
if(a[k].mst[0] <= 'У')i = k; else n = k;
}
return k;
}
main( )
{int i, count = 6, k;
struct pidpr m[6] = {{2, "Прикарпаттрансгаз", "Івано-Франківськ"},
{3, "Київтрансгаз ", "Київ "},
{4, "Львівтрансгаз ", "Львів "},
{6, "Гадячтрансгаз ", "Полтава "},
{5, "Експорттрансгаз ", "Ужгород "},
{1, "Харківтрансгаз ", "Харків "}};
clrscr( );
k = s(m, count);
printf("kil=%d kod=%d naz=%s mst=%sn", kil, m[k].kod, m[k].naz, m[k].mst);
getch( );
}
kil = 4 kod = 5 naz = Експорттрансгаз mst = Ужгород
У програмі прикладу 2.2 використана та властивість масиву, що перша буква назв міст ніде не повторюється, тому пошук відбувається лише за цією буквою. Тут використовуються змінні: i – ліва, n – права межа та k – середина області пошуку. Змінна kil служить для підрахунку числа порівнянь, воно завжди буде меншим за кількість елементів масиву і в даному випадку дорівнює 4.
2.2 Індекси
Під час виконання пошукових операцій часто приходиться мати декілька по-різному посортованих структур – за різними умовами. Зокрема, у прикладі 2.1 можна сортувати структури в порядку зростання значень змінної kod або за розташуванням назв підприємств чи міст у алфавітному порядку. Отже, прийдеться або мати декілька копій масиву структур чи зв’язаного списку, або кожного разу його пересортовувати. В цьому випадку вигідніше мати один еталоннний масив, а паралельно зробити потрібну кількість (за числом умов пошуку) копій, які міститимуть лише два стовпчики: посортовані значення і відповідні їм значення індексів еталонного масиву. Ці копії називають індексами. Тоді під час пошуку заданого значення користуються цими копіями, а решту даних беруть із еталонного масиву за відповідним номером цього значення у індексі.
Ефективність застосування індексів очевидна, адже для їх зберігання та пересортовування потрібно затратити набагато менше машинного часу та пам’яті, ніж для масивів структур.
Виготовлення індекса має свою специфіку, зумовлену тим, що процес сортування практично всіма відомими методами супроводжується багаторазовими переставляннями елементів у різні місця масиву. Однак, індекс повинен зберігати найперше значення цього місця, тобто те, яке елемент має в еталонному непосортованому масиві. Це примушує під час кожної операції перестановки елемента переносити разом з ним і його початковий номер. Нижче в прикладі 2.3 подано програму, яка виготовляє індекс misto для взятого з таблиці 1.2 масиву структур. Цей масив не буде посортованим, він еталонний. Індекс будемо застосовувати для пошуку потрібної назви міста, тому він матиме посортований масив цих назв і порядкові номери кожної назви в еталонному масиві. Індекс – це допоміжний, супутний масив.
Якби індекс містив не назви (масиви символів), а якісь числа, наприклад коди підприємств, то він виглядав би як двовимірний масив чисел і був простішим. У нашому випадку масив назв уже являє собою двовимірний масив, тому запропонуємо такий засіб: індекс двовимірним так і залишиться, лише в ньому додамо один стовпчик для зберігання порядкових номерів. Тому в програмі індекс має таке оголошення: char misto[6][16]. Перше число дорівнює 6 – за кількістю рядків, назв міст. З 16-ти стовпчиків (2-ге число) перші 15 будуть використані для букв, з яких складаються назви, включаючи ознаку кінця рядка '�', а 16-й – для номерів цих назв. На початку функції в індекс копіюються назви міст та в їхні порядкові номери, взяті з еталонного (заданого постановкою задачі) масиву структур a.
Зауважимо, що, на відміну від деяких інших мов програмування, мова С дозволяє в масиві літерного типу мати як букви, так і числа. В протилежному випадку індекс міг би складатися з двох масивів різних типів: назв міст і їхніх номерів у еталонному масиві структур.
Масив sort – допоміжний, він використовується під час перестановок назв міст. Сортування методом вибору забезпечує функція s( ).
Приклад 2.3 – Виготовлення індекса
# include<stdio.h> /* Виготовлення індекса */
# include<string.h>
struct pidpr{int kod;
char naz[25];
char mst[15];};
char misto[6][16], sort[16];
void s(struct pidpr *a, int n)
{
int i, j, num; char min;
for(i = 0; i<n; i++){strcpy(misto[i], a[i].mst); misto[i][15] = i;}
for(i = 0; i<n; i++)
{
min = misto[i][0]; num = i;
for(j = i+1; j<n; j++)if(misto[j][0] < min){min = misto[j][0]; num = j;}
if(num == i)continue;
strcpy(sort, misto[num]); j = misto[num][15];
strcpy(misto[num], misto[i]); misto[num][15] = misto[i][15];
strcpy(misto[i], sort); misto[i][15] = j;
}
return;
}
int main(void)
{int i, count = 6, kil;
struct pidpr m[6] = {{1,"Харківтрансгаз ", "Харків "},
{2,"Прикарпаттрансгаз ", "Івано-Франківськ "},
{3,"Київтрансгаз ", "Київ "},
{4,"Львівтрансгаз ", "Львів "},
{5,"Експорттрансгаз ", "Ужгород "},
{6,"Гадячтрансгаз ", "Полтава "}};
clrscr( );
puts("Заданий масив структур:");
for(i = 0;i < count;i ++)printf("%d %d %s %sn", i, m[i].kod, m[i].naz, m[i].mst);
s(m, count);
puts("nПосортований масив misto (індекс):");
for(i = 0; i<count; i++)printf("%s %dn", misto[i], misto[i][15]);
getch( );
return 0;
}
Посортований масив misto (індекс):
Івано-Франківськ 1
Київ 2
Львів 3
Полтава 5
Ужгород 4
Харків 0
Пошук за допомогою індекса можна виконати будь-яким відомим способом, але, зрозуміло, що пріоритетним буде метод половинного ділення. Нижче подано функцію p(), оператори, які слід додати в головну програму прикладу 2.3, та результати пошуку. Тут ставиться та ж задача, що і в прикладі 2.2.
int p(int n, char *poshuk)
{ int i = 0, k;
while(1)
{k = (i+n)/2;
if(i == k || n == k)break;
if(misto[k][0] <= poshuk[0])i = k; else n = k;
}
return misto[k][15];
}
char ss[15] = "Ужгород";
kil = p(count, ss);
printf("Відомості про %s: %d %s %sn", ss, m[kil].kod, m[kil].naz, m[kil].mst);
Відомості про Ужгород: 5 Експорттрансгаз Ужгород
У цьому фрагменті подібно до вищеподаних прикладів теж використана та обставина, що назви міст різняться між собою однією першою буквою. Якщо потрібно врахувати більше букв, то можна застосувати функцію strncmp( ). На відміну від функції strstr( ), ця функція не просто перевіряє входження одного рядка символів у інший, але й порівнює рядки між собою. Результатом її виконання є ціле число, яке менше за нуль, якщо букви другого рядка (ASCII-коди) менші за перший, і дорівнює нулю у випадку їх рівності. Нижче подано ще один варіант функції p(), де у назвах враховуються дві перші букви (а можна й більше).
int p(int n, char *poshuk)
{int i = 0, k;
while(1)
{
k = (i+n)/2;
if(i == k || n == k)break;
if(strncmp(misto[k], poshuk, 2)<=0 )i=k; else n=k;
}
return misto[k][15];
}
Для методу послідовного пошуку функція p() буде мати такий вигляд:
int p(int n, char *poshuk)
{int i;
for(i = 0; i<n; i++)if(strstr(misto[i], poshuk))return misto[i][15];
}
Зауважимо, що всі ці варіанти функції p() практично не відрізняються від поданих у попередніх прикладах 2.1 та 2.2, за винятком того, що вони повертають у головну програму не знайдений номер елемента, а число, яке знаходиться в 16-му (15-му, бо нумерація починається з 0) стовпчику індекса.
– Конец работы –
Эта тема принадлежит разделу:
ПРОГРАМУВАННЯ
Івано Франківський національний технічний університет нафти і газу... В М Юрчишин Б В Клим В Б Кропивницька...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: СОРТУВАННЯ
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.042 сек.
Новости и инфо для студентов