рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Обобщённая модель обработки экспериментальных данных
Реферат Курсовая Конспект
Обобщённая модель обработки экспериментальных данных
Обобщённая модель обработки экспериментальных данных - раздел Образование, Проблема статистической обработки экспериментальных данных Цель Обработки Данных Эксперимента Заключается В Получении Из Них Сведений О ...
Цель обработки данных эксперимента заключается в получении из них сведений о свойствах изучаемого объекта или процесса. На заключительном этапе экспериментатор принимает решение относительно этих свойств. Данное решение может быть связано, например, с оцениванием конкретных значений величин, характеризующих свойства объекта, а также с проверкой предположений о нахождении этих величин в определённых пределах, предположений о возможных законах распределения и т.д. Следует отметить, что процедура оценивания связана с получением оценок характеристик объекта. Под оценкой будем понимать приближённое значение оцениваемой величины, которое целесообразно принимать за её истинное значение. На рис.1.1 приведена обобщённая модель обработки экспериментальных данных.
Состояние (свойства) исследуемого объекта или процесса абстрагируется пространством ситуаций {E}. При этом под E Î {E} в общем случае понимается абстрактный параметр, характеризующий ситуацию, т.е. состояние объекта (фазовые координаты, структуру и т.д.). Абстрактный параметр может выражаться числом, функцией, функционалом, оператором, отношением, событием и т.п. Пространство ситуаций при оценивании вектора A<m> представляет множество всех возможных его значений. Экспериментатора интересует истинное значение вектора A<m>.
В процессе наблюдений регистрируется случайный вектор 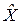 , который связан с вектором A выражениями (1.1.4) – (1.1.7). В общем виде истинную связь обозначим соотношением X = N(E). Случайные воздействия (помехи)
, который связан с вектором A выражениями (1.1.4) – (1.1.7). В общем виде истинную связь обозначим соотношением X = N(E). Случайные воздействия (помехи)  , образующие пространство воздействий {}, искажают эту связь и она принимает вид
, образующие пространство воздействий {}, искажают эту связь и она принимает вид  .
.
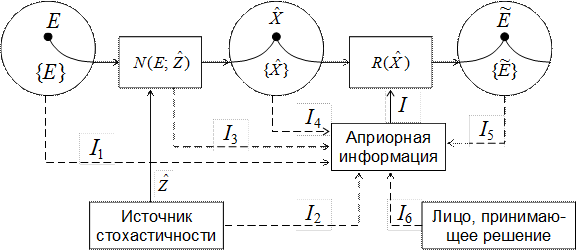
Рис.1.1. Обобщённая модель обработки экспериментальных данных
Помехи генерируются источником стохастичности. Операция над параметром E и случайной величиной (процессом) , в результате которой формируется вектор , обозначена на схеме 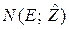 .
.
Множество {} всех значений , которые могут быть реализованы при всех возможных значениях E и , составляет пространство наблюдений. Информация о параметре E из вектора получается при обработке последнего. Статистическую процедуру преобразования над вектором обозначим через R(). Величина I характеризует всю совокупность априорной информации, которая используется в статистической процедуре совместно с результатами наблюдений . Следует подчеркнуть, что эта информация известна до начала эксперимента. Результатом преобразования величин и I является принятие решения о параметре E. Поэтому функцию R можно назвать решающей функцией.
Как видно из рис.1.1 (пунктирные линии), априорная информация I1, I2, I3, I4, I5, I6 может отражать определённые свойства пространства ситуаций, источника стохастичности, оператора N, пространства наблюдений, пространства решений и требований лица, принимающего решение.
Множество всех решений  образует пространство решений
образует пространство решений 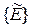 . Идеальный исход обработки экспериментальных данных сводится к тождеству
. Идеальный исход обработки экспериментальных данных сводится к тождеству 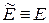 . Однако на практике это тождество оказывается нереализуемым. Решение
. Однако на практике это тождество оказывается нереализуемым. Решение  является случайной величиной (вектором, функцией), с помощью которой экспериментатор оценивает интересующую его величину E. При этом степень близости данной оценки к истинному значению E определяется как характером априорной информации об условиях эксперимента и о задаче обработки данных, так и особенностями процедуры принятия решений.
является случайной величиной (вектором, функцией), с помощью которой экспериментатор оценивает интересующую его величину E. При этом степень близости данной оценки к истинному значению E определяется как характером априорной информации об условиях эксперимента и о задаче обработки данных, так и особенностями процедуры принятия решений.
Выше указывалось, что помехи и регистрируемые в процессе наблюдения сигналы представляют собой случайные объекты (величины, векторы, функции). Из теории вероятностей известно, что самой полной характеристикой случайного объекта является закон распределения. Наиболее употребительны формы закона распределения в виде функции распределения 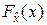 и плотности распределения
и плотности распределения 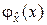 . В рассматриваемом случае принципиальное влияние на выбор способов обработки и качества обработки имеют законы распределения на пространствах {} и {}, а также оператор
. В рассматриваемом случае принципиальное влияние на выбор способов обработки и качества обработки имеют законы распределения на пространствах {} и {}, а также оператор  . Обычно предполагается известным. Наиболее распространён случай, когда по отношению к помехе оператор N является оператором суммирования (помеха аддитивная).
. Обычно предполагается известным. Наиболее распространён случай, когда по отношению к помехе оператор N является оператором суммирования (помеха аддитивная).
В зависимости от того, известны законы распределений на пространствах {} и {} или нет, статистические методы обработки экспериментальных данных подразделяются на параметрические (классические) и непараметрические.
Параметрические методы используются тогда, когда законы распределений на указанных пространствах известны. Однако, на практике они не всегда априори известны. При постановке экспериментов для исследования новых явлений и процессов истинные законы распределений могут быть неизвестны вообще. В других случаях условия эксперимента и характер помех настолько сложны и нестабильны, что трудно говорить о конкретных законах непосредственно в период проведения экспериментальных работ. Так, например, в задачах приёма и обработки телеметрической информации о техническом состоянии бортовых устройств космических аппаратов характер помех меняется в зависимости от времени суток, взаимного расположения пункта приёма и аппарата на орбите, наличия целенаправленных возмущающих воздействий. В настоящее время проблема обработки экспериментальных данных при неизвестных законах распределений решается двумя путями.
Во-первых, используется минимаксный подход. При этом решаемая задача фактически сводится к параметрической, так как данный подход приводит к нахождению закона распределения на {}, в некотором смысле «наилучшего среди плохих» (максимин) или «наихудшего среди хороших» (минимакс).
Во-вторых, применяются методы непараметрической статистики.
Во многих научных дисциплинах (исследование операций, теория принятия решений, теория игр и т.д.) по информированности специалиста, решающего задачу, различают три уровня – детерминированный, статистический и неопределённый.
Наиболее простым является первый уровень – детерминированный, когда условия решения задачи известны полностью и случайные факторы отсутствуют. Применительно к обобщённой модели на рис.1.1 это означает, что операторы N и R точно известны, Z – неслучайная величина, все измерения проводятся абсолютно точно. Крайний случай этой ситуации – достоверно известно значение параметра E. Говорят, что решение задачи на детерминированном уровне производится в условиях определённости.
На втором, стохастическом уровне известны множество возможных ситуаций и априорное вероятностное распределение случайных факторов и этих ситуаций. В обобщённой модели обработки экспериментальных данных (см. рис.1.1) это касается законов распределений величин и . На стохастическом уровне информированности специалист находится в «условиях риска».
Наконец, на уровне неопределённости известно множество ситуаций, но отсутствует априорная информация о распределениях. Принято говорить, что задача решается в условиях неопределённости.
Последние два уровня обобщаются термином «условия неполной информации». Статистические методы обработки экспериментальных данных используются именно в условиях неполной информации.
При этом параметрические методы в основном используются на стохастическом уровне, а непараметрические – на уроне неопределённости. Утверждение «в основном» подчёркивает, что в принципе и параметрические и непараметрические методы при необходимости могут быть использованы на обоих рассматриваемых уровнях неполной информации.
Многие задачи обработки данных решаются в условиях, когда относительно исходной информации (характеристик исследуемого объекта, ошибок измерений и т.д.) выдвигаются определённые гипотезы. В действительности эти гипотезы могут отличаться от фактических, реально существующих характеристик. Иначе говоря, модель может оказаться неадекватной реальным процессам. В связи с этим необходимо отметить, что различные статистические процедуры обладают различной чувствительностью к такой неадекватности. Чувствительность означает степень влияния экспериментальных данных на результаты их обработки. Поскольку непараметрические методы требуют наименьшего объёма априорной информации, то очевидно, что они и менее чувствительны к искажениям исходных данных.
Выше отмечалось, что экспериментальная информация может моделироваться с помощью случайных величин, векторов или функций. Случайная функция представляет собой наиболее общую модель наблюдаемого сигнала. Если аргументом случайной функции является время, то для неё используется термин «случайный процесс». Значительная часть результатов экспериментов описывается случайными процессами.
При наиболее распространённой аддитивной ошибке модель непрерывного сигнала имеет вид
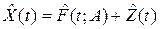 ,
,
где  – полезная составляющая наблюдаемого сигнала; A<m> - вектор оцениваемых параметров.
– полезная составляющая наблюдаемого сигнала; A<m> - вектор оцениваемых параметров.
Характер полезной составляющей может быть использован как один из признаков для классификации моделей наблюдения. При этом можно выделить следующие типы полезных сигналов: детерминированный сигнал с неизвестными параметрами, случайный сигнал с известной функцией распределения (с точностью до параметров) и случайный сигнал с неизвестной функцией распределения (функция распределения может быть задана только классом распределений).
– Конец работы –
Эта тема принадлежит разделу:
Проблема статистической обработки экспериментальных данных
На сайте allrefs.net читайте: "Проблема статистической обработки экспериментальных данных"
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Обобщённая модель обработки экспериментальных данных
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.035 сек.
Новости и инфо для студентов