Архитектура клиент/сервер
Наиболее важным вопросом реализации архитектуры клиент/сервер является не столько вопрос о том, где будет проведена граница между этими двумя частями, сколько о том, как разумно произвести это разделение. Возвращаясь к первоосновам, ответ на этот вопрос нам известен: нужно сосредоточиться на поведении каждой абстракции, основывающемся на анализе вариантов использования каждой сущности, и только затем принять решение о размещении поведения. После того, как мы проделаем такую работу в отношении нескольких основных объектов, станут ясны общие механизмы, понимание которых поможет нам правильно разместить оставшиеся абстракции.
Для примера рассмотрим поведение классов Order и ProductRecord. Анализ первого из них дает нам следующий перечень необходимых операций:
- construct
- setCustomer
- setOrderAgent
- addItem
- removeItem
- orderID
- customer
- orderAgent
- numberOfItems
- itemAt
- quantityOf
- totalValue
Перечисленные сервисные операции можно сразу выразить на языке C++, предварительно дав два новых определения типов:
// типы идентификационных номеров
typedef unsigned int OrderID;
// тип, описывающий местную валюту
typedef float Money;
Теперь получаем следующее определение класса:
class Order {
public:
Order();
Order(OrderID);
Order(const Order&);
~Order();
Orders operator=(const Orders);
int operator==(const Orders) const;
int operator!=(const Orders) const;
void setCustomer(Customer&);
void setOrderAgent(OrderAgent&);
void addItem(Product&, unsigned int quantity = 1);
void removeItem(unsigned int index, unsigned int quantity = 1);
OrderID orderID() const;
Customer& customer() const;
OrderAgent& orderAgent() const;
unsigned int numberOfItem() const;
Product& itemAt (unsigned int) const;
unsigned int quantityOf(unsigned int) const;
Money totalValue() const;
protected:
...
};
Обратим внимание на наличие нескольких вариантов конструктора. Первый из них используется по умолчанию (Order()) для создания объекта с новым уникальным значением идентификатора OrderID. Копирующий конструктор также создает объект с уникальным идентификатором, но при этом копирует в него состояние объекта, использованного в качестве аргумента.
Последний конструктор принимает в качестве аргумента OrderID, то есть конструирует объект уже существующий в базе данных и извлекает из базы его параметры. Другими словами, в этом случае мы повторно материализуем объект, существующий в базе данных. Такая операция, безусловно, требует выполнения некоторых действий: при восстановлении объекта из базы данных соответствующий SQL-механизм должен либо сделать объект разделяемым, либо синхронизировать состояние двух объектов, созданных в разных приложениях. Детали, конечно, скрыты в реализации и недоступны клиенту, который использует объект, применяя обычный объектный интерфейс.
Реализация описанного подхода не вызывает особых затруднений. Если класс Order спроектирован так, что его состояние полностью определяется идентификатором OrderID, то реализация операций сводится к обычным операторам чтения и записи из базы данных. Копии объектов синхронизируются, поскольку соответствующая таблица в базе служит единым репозиторием состояния для всех представлений одного объекта.
Диаграмма объектов на рис. 10-6 иллюстрирует описанный SQL-механизм на примере сценария выставления счета. В сценарии реализованы следующие события:
- aClient активизирует операцию setCustomer применительно к объекту класса Order; объект класса Customer передается в качестве параметра.
- Объект класса Order вызывает селектор customerID c параметром заказчика, позволяющим получить из базы данных соответствующий первичный ключ.
- Объект, соответствующий заказу, использует SQL-оператор UPDATE, чтобы установить идентификатор заказчика в базе данных заказов.
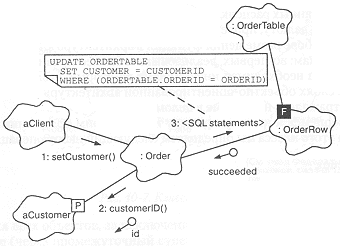
Рис. 10-6. Выставление счета.
Описанный механизм предполагает, что мы можем положиться на существующий в базе данных механизм блокировки записей и взаимного исключения при доступе (представьте себе, что могло бы случиться при одновременном обновлении одной записи из двух приложений). Если этот механизм блокировки должен быть видимым для клиента, то можно воспользоваться тем же подходом, который использовался нами при создании библиотеки классов в главе 9. Ниже мы покажем, что механизм выполнения транзакции позволяет модифицировать за один прием несколько записей в базе, обеспечивая тем самым целостность базы данных.
После реализации описанного механизма вопрос о размещении бизнес-логики имеет скорее тактическое значение. В этом смысле ситуация не отличается от той. которую мы имели бы в не объектно-ориентированной архитектуре. Но в объектно-ориентированной архитектуре можно изменить эти решения, скрыв сам факт изменения от клиента. Таким образом, клиента не затрагивают изменения, которые мы делаем по ходу настройки системы.
Для примера рассмотрим два различных случая. Добавление в базу данных записей о наличии продуктов или удаление их, очевидно, должно согласовываться с бизнес-логикой, поэтому кажется естественным разместить бизнес-логику на сервере. Добавление сведении о новых продуктах в базу данных требует точного их определения и однозначной идентификации. Кроме того, эти данные необходимо сделать доступными для всех клиентов, чтобы обновить их кэшированные таблицы. Удаление продукта из базы также требует проверки на наличие заказов по этому продукту и предупреждения соответствующих клиентов [Для этих семантических отношений как раз и придумали триггеры: они описывают реакцию на некоторые существенные события в базе данных. Приняв объектно-ориентированный взгляд на мир. можно формализовать это соглашение об использовании триггеров, инкапсулируя их как часть семантики операций с объектами базы данных].
Напротив, расчет стоимости заказов является более локальной операцией и его лучше выполнять в клиентской части приложения. Выполняя подсчеты, мы запрашиваем в базе данных расцепки на все элементы заказа, складываем их, пересчитываем в нужную валюту, проверяем на допустимые условия кредитования и т.д.
Итак, при выборе размещения функции в архитектуре клиент/сервер мы следуем двум правилам: во-первых, реализовывать бизнес-правила и алгоритмы там где сосредоточена необходимая информация; во-вторых, размещать эти алгоритмы в нижних слоях объектно-ориентированной архитектуры, чтобы внесение изменении не отражалось на системе в целом.
Теперь вернемся к нашему примеру и рассмотрим более внимательно класс Product. Для этого класса мы определяем следующий набор операций:
- construct
- setDescription
- setQuantity
- setLocation
- setSupplier
- productID
- description
- quantity
- location
- supplier
Эти операции являются общими для всех видов товаров. Однако, анализ частных случаев показывает, что есть продукты, для которых эти характеристики недостаточны. С учетом того, что проектируемая система является открытой, а виды товаров могут быть самыми различными, приведем несколько примеров специфических товаров и их свойств:
- Скоропортящиеся продукты, требующие определенного режима хранения.
- Едкие и токсичные химические вещества, также требующие специального обращения.
- Комплектные товары, которые поставляются в определенных сочетаниях (например, радиопередатчики и приемники) и поэтому взаимозависимы.
- Высокотехнологичные компоненты, поставки которых ограничиваются законодательством стран-экспортеров.
Перечисленные примеры наводят на мысль о необходимости создания некоторой иерархии классов товаров. Однако, перечисленные свойства настолько различны, что не образуют никакой иерархии. В данной ситуации более целесообразно воспользоваться примесями, что иллюстрирует и рис. 10-7. Обратим внимание на использование в этой диаграмме украшений ограничения, уточняющих семантику каждой абстракции.
Каков смысл наследования для абстракций, отражающих сущности реляционной базы данных? Очень большой: построение иерархии наследования сопровождается вычленением общих признаков поведения и отображением их в структуре суперклассов. Эти суперклассы будут ответственны за реализацию общего поведения для всех объектов, за исключением тех подклассов, которые уточняют это поведение (через промежуточный суперкласс) или расширяют его (через суперкласс-примесь). Такой подход не только упрощает построение системы, но и повышает устойчивость к вносимым изменениям за счет сокращения избыточности и локализации общих структур и поведения.
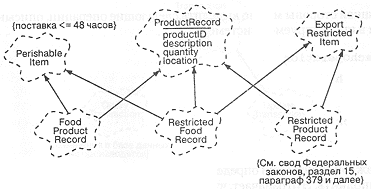
Рис. 10-7. Классы товаров.