рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Е годы XX в.
Реферат Курсовая Конспект
Е годы XX в.
Е годы XX в. - раздел Образование, Операционные системы Это Поколение Связано В Первую Очередь С Эвм На Основе Больших И Сверхбольших...
Это поколение связано в первую очередь с ЭВМ на основе больших и сверхбольших интегральных микросхем. Основными классами ЭВМ этого поколения являются ЭВМ общего использования, мини и микро ЭВМ, персональные ЭВМ и суперЭВМ (многопроцессорные). В настоящее время распространены персональные ЭВМ и суперЭВМ.
Это поколение включает в себя все основные черты ОС предыдущих поколений, а также имеют следующие особенности:
1. Управление работой сетей ЭВМ.
2. Управление работой сложных многопроцессорных вычислительных комплексов.
3. Появление ОС ПК.
4. ОС этого поколения начали использовать «дружественный» интерфейс пользователя. Т.е. ОС строятся в расчете на неподготовленных или малоподготовленных пользователей.
ПОНЯТИЕ ПРОЦЕССА. ПЕРЕХОД ПРОЦЕССА ИЗ СОСТОЯНИЯ В СОСТОЯНИЕ.
Процесс – программа, находящаяся в стадии выполнения.
Процессы могут проходить через ряд дискретных состояний. Смену состояний процесса могут вызывать различные события:
1. Состояние выполнения. Процесс находится в этом состоянии, если ему выделили центральный процессор.
2. Состояние готовности. Процесс находится в этом состоянии, если он сразу может использовать CPU, когда его предоставляют в распоряжение процессора.
3. Состояние блокировки. Процесс находится в этом состоянии, если он ожидает завершения какого-либо события.
 Когда в систему поступает некоторое задание, она создает соответствующий процесс, который затем устанавливается в конец списка готовых процессов. Затем процесс постепенно передвигается в начало списка готовых процессов по мере завершения выполнения предыдущих процессов. Когда процесс оказался первым в списке и ему выделился CPU, то говорят, что происходит смена состояния процесса. Он переходит из состояния готовности в состояние выполнения.
Когда в систему поступает некоторое задание, она создает соответствующий процесс, который затем устанавливается в конец списка готовых процессов. Затем процесс постепенно передвигается в начало списка готовых процессов по мере завершения выполнения предыдущих процессов. Когда процесс оказался первым в списке и ему выделился CPU, то говорят, что происходит смена состояния процесса. Он переходит из состояния готовности в состояние выполнения.
Когда готовому процессу представляется CPU, то это событие называется «запуск». Все это происходит при помощи части ОС, которая называется «Диспетчером». Затем процесс начинает выполняться.
Чтобы предотвратить захват всех ресурсов ЭВМ одним процессом, ОС устанавливает при помощи специального устройства – таймера прерываний некоторый промежуток времени (квант времени), в течение которого данному процессу разрешено пользоваться CPU. По истечении этого времени таймер прерываний вырабатывает специальный сигнал, по которому управление CPU передается ОС, а выполняющийся процесс будет переведен в состояние готовности и помещен в конец списка готовых процессов.
Если выполняющийся процесс до истечения отпущенного ему кванта времени инициирует операцию вводавывода, то тем самым добровольно освобождает CPU (CPU должен управлять выполнением операции вводавывода).
Эта смена состояний называется блокировкой. Из состояния блокировки процесс переводится в состояние готовности. Таким образом, возможны 4 возможные смены состояний.
БЛОК УПРАВЛЕНИЯ ПРОЦЕССОМ.
Блок управления процессом – это структура, в которой содержится информация о процессе:
1) Текущее состояние процесса
2) Уникальный идентификатор процесса
3) Приоритет процесса
4) Указатели на область памяти, которая выделена процессу
5) Указатели на выделенные процессу аппаратные ресурсы.
Блок управления процессом – это центральный пункт, в котором ОС хранит всю ключевую информацию о процессе. Когда ОС переключает CPU с процесса на процесс, то она при этом использует информацию, хранящуюся в блоке управления процессом. В большинстве случаев для хранения блока управления процессом используется специальный регистр процессора.
Часто, в машинном языке процессора имеются специальные команды, которые обеспечивают быструю запись блока управления процессом и быстрое считывание этой информации.
О каждом процессе имеется специальная информация, называемая блоком управления процесса.
ОПЕРАЦИИ НАД ПРОЦЕССАМИ.
Над процессами можно производить следующие операции:
1) Создание процесса
2) Уничтожение процесса
3) Изменение приоритета процесса
4) Блокировка процесса
5) Запуск процесса
6) Пробуждение процесса
Запуск процесса состоит из многих операций:
1) Присваивание процессу уникального идентификатора
2) Включение этого идентификатора в список процессов, известных системе
3) Определение начального приоритета процесса
4) Создание блока управления процессом
5) Выделение процессу ресурсов.
Процесс может породить другой процесс. В этом случае порождающий процесс называется родительским, а порожденный – дочерним.
 Для создания дочернего процесса необходим только родительский процесс. При таком подходе создается иерархическая структура процесса.
Для создания дочернего процесса необходим только родительский процесс. При таком подходе создается иерархическая структура процесса.
Уничтожение процесса означает его удаление из системы. При этом все ресурсы, выделенные данному процессу, освобождаются, имя процесса удаляется из всех списков и информация, хранящаяся в блоке управления процессом, уничтожается.
Уничтожение процесса усложняется, если это родительский процесс. В некоторых системах при уничтожении родительского процесса уничтожаются и все дочерние.
ПОНЯТИЕ ПРЕРЫВАНИЯ.
Прерывание – это важная процедура, которая позволяет изменить нормальную последовательность команд, выполняемых процессором.
Процессор должен реагировать на события, которые происходят вне его. Эту реакцию можно организовать 2 способами:
1) Процессор должен постоянно просматривать все устройства, которые могут потребовать его внимания. Такой способ является неэффективным, т.к. большая часть времени процессора может уйти на сканирование.
2) Использование прерываний. Сущность прерывания заключается в следующем:
Устройство, которое требует внимания процессора, сообщает об этом с помощью специального сигнала (запрос на прерывание). По этому сигналу управление CPU передается ОС. ОС запоминает состояние прерванного процесса и хранит эту информацию в специальном регистре микропроцессора. Такой регистр называется СТЭК. Затем ОС анализирует, от какого устройства произошло прерывание и затем передает управление программе, которая управляет устройством, выдавшим запрос на прерывание.
Такая программа называется «обработчик прерывания».
Прерывание может быть вызвано не только каким-либо устройством, но и выполняющимся процессом.
В начале прерывания использовались в основном для управления процессором устройствами вводавывода. А затем прерывания стали использоваться для организации внутренней работы ЭВМ. В соответствии с этим существуют следующие типы прерываний:
1) Аппаратные прерывания – прерывания от устройств компьютера.
2) Программные прерывания – прерывания, которые вырабатывают процессы, находящиеся в стадии выполнения.
3) Логические прерывания. Эти прерывания вырабатывает сам процессор, когда встречается с каким-либо необходимым условием:
a. Деление на 0
b. Переполнение регистров микропроцессора
c. Пошаговое выполнение программ
d. Режим контрольных точек.
Каждое прерывание имеет 2 параметра:
1) Номер прерывания
2) Вектор прерывания.
Вектор прерывания – это адрес ячейки памяти, где хранится программа-обработчик данного прерывания.
Прерывания обозначаются – IRQ.
ЯДРО ОПЕРАЦИОННОЙ СИСТЕМЫ.
Все операции над процессами выполняются той частью ОС, которая называется ядром.
Ядро ОС – это часть кода ОС, которая наиболее интенсивно используется в процессе работы. По этой причине ядро ОС постоянно находится в памяти, в то время как другие части ОС загружаются в память и выгружаются из нее по мере надобности.
Например, в ОС MS-DOS ядро системы составляют два файла:
1) IO.SYS
2) MSDOS.SYS
Одной из основных функций ядра является обработка прерываний. В ОС MS-DOS функцию управления обработкой прерываний выполняет файл MSDOS.SYS
Кроме обработки прерываний ядро ОС обычно также выполняет следующие функции:
1) Создание и уничтожение процессов
2) Переключение процессов из состояния в состояние
3) Приостановка и оптимизация процессов
4) Организация взаимодействия между процессами
5) Манипулирование блоками управления процессов
6) Поддержка операций вводавывода
ПОНЯТИЕ ФАЙЛОВОЙ СИСТЕМЫ. ОСНОВНЫЕ ФУНКЦИИ.
Всем процессам системы нужно хранить и получать информацию. Во время работы выполняющийся процесс может хранить информацию в той области памяти, которая ему отведена, однако объем такой памяти относительно невелик и для многих прикладных программ такого объема будет недостаточно. Кроме того, после завершения работы процесса, информация, которая хранится в памяти, уничтожается. А для многих прикладных программ, такая информация должна храниться очень долго.
Третья проблема состоит в том, что иногда к одной и той же информации должны получать доступ сразу несколько процессов.
Таким образом, к устройствам, на которых должна храниться информация, должны предъявляться следующие требования:
1) Устройство должно надежно хранить большие объемы информации
2) Информация должна сохраняться после уничтожения работающих с ней процессов
3) Несколько процессов должны одновременно иметь доступ к одной и той же информации
Решение этих проблем состоит в том, что информация хранится в специальных модулях, которые называют файлами. Процессы по мере необходимости могут читать информацию из файлов и создавать новые файлы.
Информация, хранящаяся в файлах должна обладать устойчивостью, т.е. на нее не должно оказывать влияние создание или уничтожение какого-либо процесса. Файл может исчезнуть только тогда, когда владелец этого файла даст ОС команду на его уничтожение.
Файлами управляет ОС.
Структура файлов, их именование, использование, доступ к ним является важнейшими функциями ОС. Часть ОС, отвечающая за эти файлы, носит название «файловая система».
Файл – это поименованный объем информации, хранящийся в памяти ЭВМ.
ИМЕНОВАНИЕ ФАЙЛОВ.
При создании файла, процесс дает файлу имя. Когда процесс завершает свою работу, то по имени файла к нему могут получать доступ другие процессы.
Правила присваивания имен файлов разные в различных ОС. Большинство современных ОС поддерживают имена файлов, состоящие от 1 до 8 символов. Часто допускается в именах файлов использование цифр и некоторых символов. Многие современные ОС поддерживают имена файлов длиной до 256 символов, включая пробелы. Некоторые ОС в именах файлов не различают строчные и прописные буквы. А существуют ОС, в которых различаются строчные и прописные буквы (UNIX). Во многих ОС полное имя файла состоит из 2 частей, разделенных точкой. Часть имени файла, идущая после точки, называется расширением имени файла. В ОС MS-DOS для расширения используется от 1 до 3 символов. Требование к этим символам то же самое, что и к именам файлов.
В ОС UNIX число символов расширения задается пользователем.
Расширение не является обязательным параметром, а обычно используется для того, чтобы указать на назначение файла.
В MS-DOS существуют некоторые стандартные расширения, например bak.
В ОС Windows файлам, имеющим конкретное расширение, присваивается связь между этим файлом и процессом, при помощи которого созданы эти файлы.
В ОС типа UNIX расширения файлов являются просто соглашениями, и ОС не заставляет пользователя строго их придерживаться.
СТРУКТУРА ФАЙЛОВ. ТИПЫ ФАЙЛОВ.
СТРУКТУРА ФАЙЛОВ.
Файлы могут быть структурированы различными способами. Самая простая ситуация, когда файл представляет набор байтов, т.е. он не структурирован. В этом случае ОС не интересуется содержимым файла. Значения этих байтов интересуют только процессы, которые создали эти файлы. Использование ОС неструктурированных файлов обеспечивает их гибкость.
Процессы могут помещать в файлы все, что угодно и именовать их любым удобным для себя образом.
В некоторых ОС существуют файлы, которые состоят из модулей фиксированного размера. Каждая запись может иметь свою внутреннюю структуру. При работе с такими файлами ОС может работать не сразу со всем файлом, а с отдельными записями. Такие файлы использовались, когда в качестве носителей информации использовались перфокарты. Файл представлял из себя структуру, состоящую из 80 записей, т.к. перфокарта состояла из 80 колонок цифр.
Существуют и более сложные структуры файлов.
ТИПЫ ФАЙЛОВ.
Большинство ОС может поддерживать различные типы файлов. Например, в ОС UNIX, Windows и DOS имеются обычные файлы и каталоги.
Каталог – это специальный файл, который обеспечивает поддержку файловой структуры.
В каталоге хранятся имена файлов и каталогов, которые, как говорят, входят в данный каталог.
Обычные файлы также делятся на два типа:
1) Текстовые (ASCII). В таблице ASCII каждому символу присвоен свой номер. Текстовые файлы состоят из текстовых строк. Каждая строка завершается специальным символом. Например, в ОС UNIX в конце строки помещается символ перевода строки. А в ОС MS-DOS в конце строки могут размещаться как символ перевода строки, так и символ перевода каретки. Главным отличием ASCII файлов от всех остальных то, что они могут отображаться на экране, и выводиться на печать без какого-либо преобразования и их можно редактировать практически любым текстовым редактором.
2) Двоичные. При выводе их на экран отображается бессмысленный набор символов. У двоичных файлов всегда имеется своя внутренняя структура. Для того, чтобы ОС могла запускать программный файл на выполнение, этот файл должен состоять из определенных разделов. Например, в ОС UNIX файл должен состоять из следующих разделов:
1. Заголовок
2. Текст
3. Данные
4. Некоторые специальные биты
5. Таблица символов
Заголовок начинается со специального кода, который сообщает ОС, что это исполняемый (или программный) файл.
Все ОС должны, как правило, распознавать хотя бы один тип файлов – собственные программные файлы.
ДОСТУП К ФАЙЛАМ.
Существует 2 типа доступа к файлам:
1) Последовательный доступ.
При последовательном доступе для записи файла в устройство внешней памяти выделяется объем, равный объему файла. Достоинством этого способа является то, что очень легко найти файл, где он располагается в устройстве внешней памяти.
Недостатком такого способа является неэффективное использование пространства памяти. Может возникнуть ситуация, когда при удалении файла в пространстве памяти достаточно свободного места для нового файла, а записать новый файл нельзя, т.к. в памяти нет свободного места такого объема.
Такой тип доступа к файлам используется, когда в качестве устройств внешней памяти используются устройства для записи на магнитную ленту.
2) Произвольный доступ.
В этом виде доступа пространство памяти для записи файла выделяется в виде порции, которая называется cluster. Под запись всегда выделяется первый свободный кластер от начала диска. Однако по мере стирания и записи файла может возникнуть ситуация, когда один файл будет разбросан по пространству памяти. Это явление носит название фрагментация файла.
Фрагментация файла приводит к увеличению времени, которое затрачивается на доступ к файлу.
Достоинством этого способа является эффективное использование пространства памяти, а недостатком – сложность, которая возникает при поиске файла в пространстве памяти. Т.к. файл может быть разбросан по пространству памяти, то необходим специальный справочник, в котором записана информация: в каких кластерах расположен тот или иной файл.
Такой справочник носит название «таблица размещения файлов».
Например, в ОС MS-DOS таблицу размещения файлов можно представить в виде таблицы, состоящей из двух колонок. В одной колонке расположены имена кластеров, а в другой против каждого номера кластера при помощи специальных кодов может быть записана следующая информация:
| … | |
1) Данный кластер свободный
2) Номер следующего кластера в этом же файле
3) Маркер конца файла (последний кластер в файле)
4) Этот кластер испорчен
Таблица размещения файла является очень важным элементом файловой системы и, поэтому обычно создается 2 ее экземпляра. Потеря или уничтожение таблицы размещения файлов приводит к полной невосстановимой потере информации.
АТРИБУТЫ ФАЙЛА.
Кроме имени файла каждый файл может иметь и другие параметры, которые описывают его состояние. Эти параметры называются атрибутами файла.
Атрибуты файла могут быть разными в разных ОС.
Ни в одной ОС нет всех атрибутов, которые может иметь файл, но в тех или иных системах присутствует каждый из следующих атрибутов.
| АТРИБУТ | ЗНАЧЕНИЕ |
| Дата и время создания | - |
| Объем в байтах | - |
| Защита | Кто и каким образом получает доступ к файлу |
| Пароль | - |
| Создатель | - |
| Владелец | - |
| Только для чтения | - |
| Скрытый (hidden) | - |
| Системный (system) | Файл ОС |
| Архивный | - |
| ASCII | Текстовый файл в ASCII кодах |
| Временный | Файл должен быть удален по окончании процесса |
| Блокированный | - |
| Время последнего доступа | - |
| Время последнего изменения | - |
| Максимальный размер | Количество байт, до которого можно увеличить объем файла |
| Текущий размер | - |
Атрибуты файла обычно используются процессами, которые работают с этими файлами.
ОПЕРАЦИИ С ФАЙЛАМИ.
В различных ОС существуют различный набор операций, которые можно производить с файлами.
Наиболее часто встречаются следующие операции:
1) Create (Создать)
При этом файл создается без данных, и устанавливаются некоторые его атрибуты.
2) Delete (Удалить)
Уничтожение файла.
3) Open (Открыть)
Прежде, чем процесс может использовать файл, его необходимо открыть. Операция открытия файла заключается в том, что в ОЗУ считываются атрибуты файла и адреса кластеров, в которых содержится файл.
4) Close (Закрыть)
Это операция, противоположная открытию. Из ОЗУ удаляется вся информация о файле.
5) Read (Прочитать)
Процесс, который должен работать с этими данными должен указать количество требуемых данных, и выделить для их хранения память.
6) Write (Записать)
Эта операция позволяет записывать данные в файл. При этом может возникнуть две ситуации:
А) Данные записываются в конец файла, и тогда объем файла увеличивается.
Б) Запись производится поверх данных, а старые данные уничтожаются.
7) Append (Добавить)
Запись производится всегда только в конец файла.
8) Seek (Поиск)
Эта операция позволяет при произвольном доступе установить, где находятся данные в файле.
После этой операции данные могут считываться либо производиться запись в файл.
9) Get Attributes (Получить атрибуты)
Некоторым процессам для работы с файлами необходимо знать атрибуты файла.
10) Set Attributes (Установить атрибуты)
Некоторые атрибуты могут быть установлены пользователем уже после создания файла.
11) Rename (Переименовать)
Операция позволяет изменить имя файла.
Все перечисленные выше операции часто носят название – системные вызовы.
ПОНЯТИЕ КАТАЛОГА. СИСТЕМЫ КАТАЛОГОВ.
В большинстве ОС каталог – это специальный файл, в котором хранится информация о файлах и каталогах, которые входят в данный каталог. Исторически существовали различные системы каталогов.
1) Одноуровневая каталоговая система.
 Эта система состоит из всего одного каталога. Иногда этот каталог называют корневым. Преимуществом такой системы является ее простота и способность быстро находить файлы, т.к. они могут располагаться только в одном месте. Недостаток такой системы состоит в том, что файлы с одинаковыми именами не могут существовать в одном каталоге. Такая система каталогов использовалась в первых ПК.
Эта система состоит из всего одного каталога. Иногда этот каталог называют корневым. Преимуществом такой системы является ее простота и способность быстро находить файлы, т.к. они могут располагаться только в одном месте. Недостаток такой системы состоит в том, что файлы с одинаковыми именами не могут существовать в одном каталоге. Такая система каталогов использовалась в первых ПК.
2) Двухуровневая каталоговая система.
Для решения проблемы создания двух одинаковых имен файлов можно использовать систему, в которой каждому пользователю выделяется свой собственный каталог.
 В такой системе если пользователь пытается открыть какой-то файл, который ему принадлежит, то ОС знает, где искать этот файл. Соответственно при этом требуется регистрация пользователя в ОС. Такая система каталогов может использоваться либо на многопользовательской ЭВМ, либо в простой компьютерной сети, где на главном компьютере, в сервере, располагается такая система.
В такой системе если пользователь пытается открыть какой-то файл, который ему принадлежит, то ОС знает, где искать этот файл. Соответственно при этом требуется регистрация пользователя в ОС. Такая система каталогов может использоваться либо на многопользовательской ЭВМ, либо в простой компьютерной сети, где на главном компьютере, в сервере, располагается такая система.
Благодаря такой системе исчезают конфликты имен файлов, но такой системы недостаточно для пользователей, у которых имеется большое число файлов. У такого пользователя возникает необходимость группировать файлы по каким-либо признакам. Такая возможность может быть реализована в иерархической каталоговой системе.
3) Иерархическая каталоговая система.
 Она реализуется при помощи дерева каталогов. В такой системе имеется всегда главный каталог, который носит название корневого каталога. В нем могут находиться каталоги пользователей или некоторые файлы. В свою очередь, в каталогах пользователей могут создаваться каталоги, а также файлы.
Она реализуется при помощи дерева каталогов. В такой системе имеется всегда главный каталог, который носит название корневого каталога. В нем могут находиться каталоги пользователей или некоторые файлы. В свою очередь, в каталогах пользователей могут создаваться каталоги, а также файлы.
Каждый пользователь может создавать столько каталогов, сколько ему нужно. Число создаваемых каталогов и файлов обычно ограничивается объемом справочника, в котором хранятся имена этих файлов и каталогов.
При таком способе организации файловой структуры требуется некоторый способ указания того места в структуре, где находится данный файл. Этот способ носит название – указание пути к файлу или задание абсолютного имени файла.
Путь к файлу обычно состоит из перечисления всех каталогов, начиная с корневого до каталога, в котором содержится файл, и заканчивается именем самого файла. Например, RootC1F1.
«» - slash (косая черта, разделяющая каталоги)
«» - в Windows
«/» - в Unix
Используются также и относительные имена файлов. При задании относительного имени файла используется понятие текущего или рабочего каталога. Обычно текущим каталогом является тот каталог, в котором находится пользователь. Относительное имя файла начинается с имени текущего каталога.
Обычно в ОС имеется специальная команда (в MS-DOS – cd (change directory)), с помощью которой можно установить текущий каталог.
CD C:DOSTEXT
При задании такой строки текущим каталогом станет TEXT.
cd . – переход в иерархии на один каталог выше.
cd . . – переход в корневой каталог.
ОПЕРАЦИИ С КАТАЛОГАМИ.
1) Create
Создается пустой каталог, не содержащий никаких элементов.
2) Delete
При помощи этой операции можно удалить только пустой каталог.
3) Open DIR
Как и в случае с файлами, для того, чтобы процессы могли работать с каталогом, его необходимо открыть.
4) Close DIR
Закрытие каталога.
5) Read DIR
Специальная команда, которая позволяет процессам читать информацию из открытых каталогов.
6) Rename
Переименование.
7) Link
Позволяет одному файлу содержаться сразу в нескольких каталогах.
8) Unlink
Удаляет эту связь.
ФАЙЛОВАЯ СИСТЕМА CD-ROM.
Это простейшая файловая система, т.к. такие диски записываются только один раз и, поэтому, в них не требуется учитывать свободные участки, которые появляются при стирании файла.
Информация на такие диски записывается в соответствии со специальным стандартом, для того, чтобы информацию на нем можно было прочитать независимо от ОС.
Информация на лазерный диск записывается на дорожку, которая расположена на диске в виде спирали. Биты информации на дорожке разделены на участки, которые называются логическими блоками. Обычно такой участок составляет 2352 байт. Часть этих байтов предназначена для служебных целей и, поэтому, полезная емкость каждого логического блока составляет 2048 байт.
У аудиодисков, кроме того, существуют специальные разделительные участки между композициями, а для каждой композиции записывается название автора и время воспроизведения.
Каждый лазерный диск начинается с 16 логических блоков, которые каждый производитель дисков может использовать по своему усмотрению. Например, в эти 16 блоков можно записать загрузчик ОС и получить загрузочный диск.
Затем, в 17 блоке размещается основной описатель тома (или диска). В этом описателе хранится вся основная информация об этом диске. В нее входит ОС, для которой предназначен этот диск, название диска, название издателя, подготовившего этот диск. Кроме того, там же хранится информация об авторских правах, краткое описание диска. Затем, в описателе тома обычно указывается размер логического блока и количество таких блоков на диске.
Затем идет описание корневого каталога этого диска, т.е. в каких логических блоках хранится корневой каталог.
Начиная с этого каталога, можно определить местонахождение всей файловой системы диска. Каждая запись в каталоге обычно состоит из следующих разделов:
| 1 байт | 1 байт | 8 байт | 8 байт | 7 байт | 1 байт | 2 байта | 4 байта | 1 байт | 4 байта |
| Расположение файла | Размер файла | Дата и время создания | Имя файла |
Каталоговые записи могут иметь различную длину. Обычно они имеют от 10-12 участков. Часть информации в каталоговых записях кодируется с помощью таблицы ASCII, а часть информации – это двоичные коды, причем существуют разные коды для разных ОС.
Расположение файла – записывается номер начального логического блока, где расположен этот файл.
Во втором участке записываются атрибуты этой каталоговой записи. С помощью них определяется, обычный это файл или каталог.
ФАЙЛОВАЯ СИСТЕМА MS-DOS
В файловой системе MS-DOS используется иерархическая система. Т.к. ОС MS-DOS является однопользовательской, то пользователь получает доступ сразу ко всей файловой системе.
В ОС MS-DOS реализован произвольный доступ к файлу. Отсюда, основными элементами файловой системы MS-DOS являются:
1) Специальный справочник, в котором хранится информация обо всех файлах и каталогах, записанных на диске. Этот справочник располагается в специальной служебной области магнитного диска, которая носит название «область корневого каталога». Каждая запись в области корневого каталога состоит из нескольких разделов (полей).
| 8 байт | 3 байта | 1 байт | 10 байт | 2 байта | 2 байта | 2 байта | 4 байта |
| Имя файла | Расширение | Зарезерв. | Время | Дата | № первого кластера | Размер |
В поле, отведенное под имя файла, с помощью специальных кодов указывается состояние файла. Если в этот элемент ни разу не записывалась информация, то во всех разделах записи стоят ноли. Когда файл уничтожается, то в поле имени файла в первый байт записывается специальный код и если этот файл – каталог, то в первый байт поля имени файла также записывается специальный код.
Чтобы прочитать какой-либо файл, любой процесс, работающий в системе MS-DOS должен дать задание ОС на открытие файла. В качестве параметра заданию на открытие файла он должен указать путь к файлу.
При открытии файла ОС MS-DOS просматривает каталоги, указанные в пути к файлу вплоть до последнего каталога, в котором хранится указанный файл. Из этого каталога ОС считывает информацию о файле в соответствии с форматом записи. Одним из параметров каталоговой записи является номер первого кластера, в котором записан файл. Этот параметр носит название «точка входа в таблицу файла». Затем ОС в соответствии с этим параметром из таблицы размещения файлов получает информацию, в каких кластерах находится данный файл.
Исторически в ОС MS-DOS использовалось 3 варианта таблицы размещения файлов: FAT12, FAT16, FAT32. Цифра говорит о количестве двоичных разрядов, которые используются для нумерации кластеров. В FAT32 используется 28 разрядов.
В первой версии MS-DOS работали с FAT12. Размер кластера в этой таблице составлял 512 байт, поэтому общий объем диска, с которым могла работать FAT12, мог составлять примерно 2 Мб.
Но и сама FAT занимает в памяти примерно 20 Кб. Такая система хорошо работала с гибкими магнитными дисками, но с появлением жестких дисков появлялись проблемы.
Сначала были увеличены размеры кластеров до 1, 2 и 4 Кб. При V кластера 4 Кб максимальный объем диска мог составлять 16 Мб.
Эти версии ОС MS-DOS могли работать с 4 разделами жесткого диска до 16 Мб и отсюда, общий объем диска составлял 64 Мб.
Для того, чтобы работать с дисками большего объема, была разработана версия ОС MS-DOS с поддержкой FAT16. При этом размеры кластера могли быть 1, 2, 4, 8, 14, 32 Кб.
Максимальный V диска составлял уже 2 Гб, а с 4 разделами – 8 Гб.
Размер кластера устанавливался в зависимости от максимального V диска. Сама FAT стала занимать уже достаточно большой V = 128 Кб. MS-DOS v.6.22 работает с FAT16.
32-х разрядная таблица размещения файлов впервые появилась в ОС Windows 95, и то не в самой первой версии. Теоретически, max V диска с max таблицей размещения файлов составляет 2 Тб. Размеры самой FAT зависят от V диска. Кроме поддержки дисков большого V FAT32 имеет еще одно преимущество над FAT16: при одних и тех же объемах диска размер кластера в FAT32 меньше, чем в FAT16.
ФАЙЛОВАЯ СИСТЕМА WINDOWS 9.XME
Основным отличием файловой системы Windows 9.x является то, что она основана на файловой системе MS-DOS и поддерживает имена файлов до 256 символов, включая пробелы.
Для того, чтобы ОС Windows 9.x могла работать с длинными именами файлов, нужно было разработать новую структуры каталоговой записи, однако такой подход имеет существенный недостаток: т.к. во всех версия Windows встроен MS-DOS, то при работе в сеансе MS-DOS было бы невозможно работать с длинными именами файлов.
Поэтому Microsoft приняла решение разработать такую файловую систему, чтобы из Windows 9.x и встроенной MS-DOS был полный доступ ко всем файлам, в том числе и с длинными именами файлов. Структура каталоговой записи, использующаяся в MS-DOS, имеет длину 32 байта, однако 10 байт из них не задействовано. Эти 10 байт были использованы в ОС семейства Windows 9.x. На их место было добавлено 5 новых полей. Таким образом, структура каталоговой записи в Windows 9.x имеет следующий вид:
| 8 байт | 3 байта | 1 байт | 1 байт | 1 байт | 4 байта | 2 байта | 4 байта | 2 байта | 4 байта |
| Имя файла | Расширение | NT | Дата и время создания | Дата и время последней записи | Размер |

В ОС Windows 9.x каждому файлу присваивается сразу 2 имени. Длинное имя в формате 256 символов и имя в формате MS-DOS – 8 символов.
Доступ к файлу может быть получен по любому имени. Когда создается файл с длинным именем, то автоматически создается по определенному алгоритму имя в формате MS-DOS.
Для этого берутся первые шесть символов длинного имени, затем «~» и цифра 1. Если есть файлы с совпадающими первыми 6 символами, ставится цифра 2. При этом из длинного имени удаляются пробелы и точки.
Длинное имя хранится в следующем формате:
| 1 байт | 10 байт | 1 байт | 1 байт | 1 байт | 12 байт | 2 байта | 4 байта |
| 5 символов | 6 символов | 2 символа |
ОС отличает фрагменты длинного имени от имени в формате MS-DOS тем, что в каталоговую запись в часть длинного имени в поле «Атрибуты» записывается специальный код. Этот код неизвестен ОС MS-DOS, и она игнорирует эти записи.
СИСТЕМА ВВОДАВЫВОДА. ОСНОВНЫЕ ФУНКЦИИ.
Одной из важнейших функций ОС является управление вводом-выводом. ОС должна давать команды устройствам ввода-вывода, управлять обработкой прерываний, и обрабатывать ошибки. ОС должна также обеспечивать простой и удобный интерфейс между устройствами ввода-вывода и остальной системой. ПО ввода-вывода составляет существенную часть кода ОС.
ТИПЫ УТСРОЙСТВ ВВОДАВЫВОДА.
Устройства ввода-вывода можно условно разделить на две большие группы:
1) Блочные. Это устройства, хранящие информацию в виде блоков определенного размера, причем каждый блок имеет свой адрес. С этой точки зрения, к блочным устройствам относятся магнитные диски, лазерные диски. Важнейшей особенностью блочных устройств является то, что каждый блок может быть прочитан независимо от остальных.
2) Символьные. Эти устройства передают поток данный (или принимают), который не имеет блочной структуры. Символьные устройства не являются адресуемыми и не выполняют операцию поиска. К символьным относятся принтеры, модемы, сканеры и т.д.
Однако существуют устройства, не относящиеся ни к блочным, ни к символьным. Примером такого устройства является таймер в компьютере. Вся работа часов состоит в инициировании прерываний в строго определенный момент времени.
Устройства ввода-вывода работают в очень большом диапазоне скоростей передачи информации, что создает определенные трудности для ОС. ОС должна обеспечивать безошибочную обработку данных, которые передаются в большом диапазоне скоростей.
Например, клавиатура передает информацию со скоростью 10 байт в секунду, мышь – 100 байт в секунду, лазерный принтер – 100 Кб/с, 40х CD-ROM – 6 Мб/с, обычная компьютерная сеть – 100 Мб/с.
КОНТРОЛЛЕРЫ УСТРОЙСТВ ВВОДАВЫВОДА.
Каждое устройство ввода-вывода обычно состоит из механической части и электронной. Электронная часть называется контроллером (или адаптером). Обычно контроллер выполнен в виде платы, которая вставляется в разъем материнской платы.
Некоторые контроллеры могут управлять сразу несколькими устройствами. Обычно контроллеры должны быть изготовлены в соответствии с определенным стандартом, поэтому различные фирмы могут выполнять механические и электронные части.
Интерфейс между механическим устройством и контроллером обычно является интерфейсом очень низкого уровня.
Например, магнитный диск может быть разбит с определенным количеством кластеров на дорожку с V кластера в 512 Мб. На самом деле с диска в контроллер поступает последовательный поток байтов, который состоит из заголовка, полезных байтов и заканчивается контрольной суммой. Работа контроллера заключается в том, чтобы преобразовать последовательный2 поток байтов в блок байтов и провести коррекцию ошибок, если это необходимо. Обычно блок байтов формируется путем накапливания байтов в специальной памяти контроллера, который носит название «буфер», а коррекция ошибок производится путем подсчета контрольной суммы, которая должна совпадать с суммой, указанной в заголовке.
ОТОБРАЖАЕМЫЙ НА АДРЕСНОЕ ПРОСТРАНСТВО ВВОД-ВЫВОД.
У каждого контроллера есть специальная сверхбыстродействующая память – регистры. Через эти регистры процессор может общаться с устройствами ввода-вывода. При помощи специальных команд, записанных в эти регистры, можно выключить устройство, считать данные с устройства или записать туда данные.
Кроме регистров, в каждом контроллере имеется буфер.
Буфер – это память, в которой храниться информация, считываемая из устройства и записываемая в него.
Существует два способа, с помощью которых можно получить доступ к регистрам и буферам:
1) 
 Каждому регистру устройств ввода-вывода назначается специальный адрес. Этот адрес носит название «порт ввода-вывода». Он представляет из себя многоразрядное двоичное число (обычно 16 разрядов). При помощи специальных команд процессор может записывать по этим адресам различную управляющую информацию. Порты ввода-вывода никак не связаны с общим адресным пространством. Такая схема адресации ввода-вывода использовалась в ЭВМ 2-го и 3-го поколения.
Каждому регистру устройств ввода-вывода назначается специальный адрес. Этот адрес носит название «порт ввода-вывода». Он представляет из себя многоразрядное двоичное число (обычно 16 разрядов). При помощи специальных команд процессор может записывать по этим адресам различную управляющую информацию. Порты ввода-вывода никак не связаны с общим адресным пространством. Такая схема адресации ввода-вывода использовалась в ЭВМ 2-го и 3-го поколения.
2) В общем адресном пространстве часть адресов выделяется устройствам ввода-вывода. Эта схема носит название «отображаемый на адресное пространство ввод-вывод».
В современных компьютерах с процессорами Pentium используется гибридная схема. В этой схеме выделяется отдельное адресное пространство для регистров устройств ввода-вывода, а часть адресного пространства резервируется под буферы устройств ввода-вывода.
 Эти схемы работают следующим образом:
Эти схемы работают следующим образом:
Когда CPU хочет прочитать данные либо из памяти, либо из порта ввода-вывода, то он выставляет нужный адрес на шину адреса, а на управляющую шину выставляет команду «Чтение». В зависимости от адреса, на этот сигнал реагирует либо память, либо устройство ввода-вывода. Если, как во 2 случае, пространство адресов общее, то каждое устройство ввода-вывода и каждый модуль памяти сравнивают выставленный на адресную шину адрес с диапазоном адресов, который им выделен. Если адрес попадает в этот диапазон, то они реагируют.
Каждая из этих схем имеет свои достоинства и недостатки. Например, к достоинствам 2 схемы относится то, что не требуется различные команды процессора при обращении к памяти и при обращении к устройствам ввода-вывода.
К недостаткам такой схемы относится более сложное устройство механизма адресации.
В порты ввода-вывода входят адреса регистров и буферов.
ПРЯМОЙ ДОСТУП К ПАМЯТИ.
Независимо от того, по какой схеме происходит адресация устройств ввода-вывода, процессор должен работать с контроллерами устройств ввода-вывода для обмена с ними информацией. Процессор может получать информацию от устройств ввода-вывода побайтно, но этот способ будет не эффективным, т.к. потребует огромного количества процессорного времени.
На практике используется другая схема, называемая «прямой доступ к памяти» (Direct Memory Access (DMA)). Для реализации этой схемы используется специальное устройство, которое называется контроллер прямого доступа к памяти. При использовании этого контроллера перенос данных от устройств ввода-вывода в память будет производиться без непосредственного участия CPU.
Рассмотрим вначале, как происходит работа контроллера устройства ввода-вывода без DMA.
Вначале контроллер считывает с механической части блок последовательно бит за битом до тех пор, пока весь блок не окажется в буфере. Затем контроллер проверяет контрольную сумму, чтобы убедиться, что считывание прошло без ошибок. После этого контроллер выдает сигнал-запрос на прерывание, в результате чего ОС с помощью обработчика прерываний считывает из буфера в память информацию, хранящуюся в буфере. Обычно программа-обработчик считывает информацию путем организации цикла, считывая за 1 цикл единицу информации (байт или машинное слово).
 При использовании DMA происходит следующая процедура:
При использовании DMA происходит следующая процедура:
Вначале CPU программирует DMA контроллер, записывая в его регистры информацию, какие данные и куда необходимо поместить. Затем процессор инициирует контроллер ввода-вывода, заставляя его записать блок данных из механической части в буфер.
Затем приступает к работе контроллер DMA. Контроллер DMA посылает устройству ввода-вывода запрос на чтение, а дальше происходит процесс, аналогичный описанному выше, когда чтением информации с устройства ввода-вывода и записью ее в память занималась программа-обработчик прерывания.
Т.е. контроллер DMA в этой ситуации заменяет CPU.
Таким образом, использование прямого доступа к памяти позволяет резко уменьшить нагрузку на CPU при некоторых операциях ввода-вывода.
Контроллеры DMA могут отличаться друг от друга по степени сложности. Существуют контроллеры, которые могут одновременно обслуживать сразу несколько устройств ввода-вывода.
ПРОГРАММНЫЙ ВВОД-ВЫВОД.
Сутью программного ввода-вывода является то, что в этом случае всю работу выполняет CPU. Рассмотрим программный ввод-вывод на примере:
Пользователю необходимо напечатать на принтере строку «ABCD». В начале пользователь должен набрать эту строку путем помещения символов в область памяти, которая выделена данному процессу. Затем процесс должен получить с помощью ОС принтер в свое распоряжение. Если принтер в это время занят, то процессу будет сообщен код ошибки или процесс будет заблокирован до тех пор, пока принтер не будет освобожден.
Когда процесс получит в свое распоряжение принтер, то он даст задание ОС напечатать строку на принтере. При этом ОС переписывает информацию из памяти, принадлежащей процессу, в свою, служебную, область памяти. Затем ОС по одному символу будет копировать эту строку, передавая информацию в контроллер принтера.
Обычно принтеры не печатают по одному символу, а накапливают информацию в буфере. После накапливания информации в буфере принтер все печатает.
Программный ввод-вывод очень легко реализовать, однако его недостаток заключается в том, что все время будет занят CPU. Даже если один символ будет печататься очень быстро, то все равно время, которое затрачивается на его печать не сравнимо со скоростью работы процессора.
При этом CPU будет большую часть времени тратить на ожидание готовности принтера.
Такой способ организации ввода-вывода обычно используется в очень простых системах.
УПРАВЛЯЕМЫЙ ПРЕРЫВАНИЯМИ ВВОД-ВЫВОД.
Например, если рассмотреть ситуацию, когда принтер не будет накапливать строку в буфере, а будет печатать символ сразу. Если принтер печатает со скоростью 100 символов в секунду, то на печать одного символа уйдет примерно 10 миллисекунд. Это означает, что в течение этого времени процессор будет простаивать. Это для процессора очень большое время.
Поэтому возникла идея использовать время простоя микропроцессора для запуска другого процесса. Поэтому принтер в начале печати символа выдает запрос на прерывание. После этого ОС может запустить другой процесс. Процесс, который попросил распечатать строку, будет заблокирован на время печати строки.
После того, как строка будет напечатана, принтер выдает сигнал-запрос на прерывание, и обработчик прерывания разблокирует процесс пользователя, который подготовит для печати следующую строку.
ВВОД-ВЫВОД С ИСПОЛЬЗОВАНИЕМ DMA.
Очевидный недостаток управляемого с помощью прерываний ввода-вывода в том, что прерывания будут происходить при печати каждого символа. Поскольку обработка прерываний занимает определенное время, то такая схема является достаточно неэффективной.
Решение этой проблемы заключается в использовании прямого доступа к памяти. Идея состоим в том, чтобы позволить контроллеру DMA поставлять принтеру символы по одному, не занимая при этом CPU. По существу, этот метод аналогичен программному управлению с той только разницей, что роль CPU будет выполнять контроллер DMA.
Наибольший выигрыш в использовании DMA состоит в уменьшении количества прерываний с одного на каждый печатаемый символ, до одного на печатаемый буфер. Если обрабатываемых символов много, а обработка прерываний производится достаточно медленно, то этот способ дает достаточный выигрыш.
ОБРАБОТЧИКИ ПРЕРЫВАНИЙ.
ПО ввода-вывода обычно реализуется в виде 4-х уровней.
| ПО ввода-вывода уровня пользователя |
| Устройство-независимое ПО операционной системы |
| Драйверы устройств |
| Обработчики прерываний |
| Аппаратура ввода-вывода |
Обработчики прерываний – это программы, которые непосредственно работают с устройствами ввода-вывода. Обычно работу обработчиков прерываний вызывает драйвер. Сама работа обработчиков прерываний пользователю непосредственно не видна, однако является достаточно сложной.
Обработчики прерываний выполняют следующие действия:
1) Обработчик прерывания должен сохранять информацию во всех регистрах микропроцессора, которая там имелась на момент начала обработки прерывания.
2) Настраивают стэк для процедуры обработки прерывания.
3) Выдает подтверждение контроллеру прерываний. Если такой контроллер отсутствует, то разрешает прерывание.
4) Запускает процедуру обработки прерывания. Она извлекает информацию из регистров контроллера устройства, вызвавшего прерывание.
5) Выбирает процесс, которому необходимо передать управление. Загружает регистры нового процесса. Начинает выполнение нового процесса.
ДРАЙВЕРЫ УСТРОЙСТВ.
Каждый контроллер устройства ввода-вывода имеет набор регистров, используемых для того, чтобы давать команды устройству и читать состояние устройства. Число таких регистров зависит от конкретного устройства.
Для управления каждым устройством ввода-вывода требуется специальная программа, которая называется драйвером. Например, драйвер мыши должен принимать от мыши информацию, в каком месте находится указатель (или курсор) по вертикали и по горизонтали. А также, какие кнопки мыши нажаты.
Т.к. устройство ввода-вывода обычно производят разные изготовители, то они же и создают драйверы для этих устройств. ОС только тогда становится широко распространенной, когда для нее существуют драйверы к большинству производимых устройств ввода-вывода.
Каждый драйвер устройства обычно поддерживает только один тип устройства. Драйверы пишутся для каждого конкретного устройства. Драйвер, чтобы получить доступ к регистрам контроллера должен являться частью ОС. Технически возможно включение драйверов в состав пользовательских программ, однако это не эффективно, т.к., например, текстовый редактор должен будет включать в себя драйверы всех выпущенных принтеров.
Т.к. в ОС будут устанавливаться программы (драйверы), написанные другими программистами, то необходима определенная архитектура, позволяющая производить подобную установку. Это означает, что должна существовать модель драйвера со строго определенным набором функций и способов его взаимодействия с ОС.
Поэтому существует определенная классификация драйверов в соответствии с типом обслуживаемых ими устройств.
В большинстве ОС определен стандартный интерфейс, который должен поддерживать все блочные драйвера, и второй стандартный интерфейс, который должен поддерживать все символьные драйвера. Эти интерфейсы включают в себя наборы процедур, которые может вызывать ОС при обращении к драйверу. К этим процедурам относятся процедура обращения к блокам, процедура записи символов строки.
Ранее ОС включали в себя набор всех необходимых драйверов. При появлении нового устройства необходимо было добавить в ОС кусок кода и заново ее компилировать. Такая схема долго использовалась в ОС UNIX.
С появлением ПК и большого разнообразия устройств ввода-вывода такая схема стала очень неудобной. Вместо этого современные ОС используют модель динамического подключения драйвера во время подключения к системе.
В ОС MS-DOS эта процедура выглядит следующим образом:
Во время загрузки ОС MS-DOS выполняются команды специального файла конфигурации ОС Config.sys. В этом файле существует специальная команда device, с помощью которой к системе подключаются драйверы устройств. Когда необходимо работать с мышью, то ОС автоматически подключает драйвер мыши. Процедура подключения драйверов к системе автоматизирована и осуществляется при помощи механизма Plug&Play.
Наиболее типичные функции драйвера:
1) Обработка запросов записи и чтения
2) Необходимо инициализировать устройства ввода-вывода
3) Управление энергопотреблением
4) Включение и выключение устройств
СХЕМА РАБОТЫ УСТРОЙСТВА ВВОДАВЫВОДА.
Рассмотрим эту схему на примере запуска программы:
1) Пользователь инициализирует запуск какого-либо программного файла.
2) ОС на основании справочной информации, хранящейся в области корневого каталога и таблицы размещения файлов, находящейся в ОЗУ.
3) Затем ОС передает управление драйверу устройства ввода-вывода, в котором находится данный файл.
4) При помощи команд драйвера ОС переписывает файл с магнитного диска в буфер контроллера.
5) Когда буфер заполнен, то устройство ввода-вывода выдает сигнал-запрос на прерывание.
6) По этому сигналу ОС, используя информацию, находящуюся в таблице прерываний, запускает процесс обработки прерывания.
7) Обработчик прерывания переносит информацию из буфера контроллера в ОЗУ.
8) После того, как файл будет полностью скопирован в память, ОС полностью передаст ему управление.
НЕЗАВИСИМОЕ ОТ УСТРОЙСТВ ПО ВВОДАВЫВОДА.
В некоторых ОС могут существовать функции, связанные с вводом-выводом, не зависящим от конкретных устройств ввода-вывода. К таким функциям относятся:
1) Единообразный интерфейс для взаимодействия драйверов с ОС. Это набор привил, по которым создатели драйверов должны создавать свои программы для работы с конкретной ОС.
2) Буферизация. В некоторых ОС существует функция создания дополнительных буферов при работе с устройствами ввода-вывода. Буфер – это часть ОЗУ, которая резервируется для хранения информации, записанной или считанной с устройств ввода-вывода. Например, в ОС MS-DOS в файле CONFIG.SYS существует специальная команда BUFFERS, с помощью которой можно создать определенное число дисковых буферов. С помощью этих буферов ускоряется ввод-вывод информации с магнитный дисков.
3) Сообщения об ошибках. Эта часть ПО отвечает за индикацию сообщений об ошибках, связанных с вводом-выводом.
4) Захват и освобождение выделенных устройств. Эта часть ПО связана с распределением времени управления ОС различными устройствами.
ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ ВВОДАВЫВОДА УРОВНЯ ПОЛЬЗОВАТЕЛЯ.
Хотя большая часть ПО ввода-вывода является частью ОС, однако некоторые функции, связанные с вводом-выводом, могут включаться в пользовательские программы. Такое ПО используется в многозадачных системах. Наиболее характерным примером такого ПО является Spooling.
Spooling – это предварительное накопление данных.
В многозадачной системе, например, можно каждому процессу, которому требуется работа с принтером, создать специальный файл для обмена с принтером, но если процесс откроет этот файл, а не будет обращаться к принтеру в течение какого-то времени, то другие процессы в это время не смогут обращаться к принтеру.
Вместо этого создается специальный процесс, который называется ДЕМОН и специальный каталог, который называется каталогом спулинга. В этот каталог программы (процессы) размещают файлы, которые они хотят напечатать, а возможностью печатать файл из этого каталога обладает только ДЕМОН.
Спулинг используется не только для принтеров, например передачу файлов по сети осуществляет ДЕМОН. Чтобы посылать файл в другой компьютер, пользователь помещает его в каталог сетевого демона. Затем сетевой демон извлекает этот файл и посылает его по сети. Такая система работает в сервисе Интернета «Usenet News».
Вся эта система работает вне ОС.
СХЕМА РАБОТЫ ПО ВВОДА-ВЫВОДА.
| ПО ввода-вывода уровня пользователя | Spooling, обращение к ОС в вводе-выводе. |
| Устройство-независимое ПО операционной системы | Обеспечение единого интерфейса для драйверов устройств, буферизация, вывод сообщения об ошибках. |
| Драйверы устройств | Управление устройствами ввода-вывода при помощи команд, помещенных в регистры. |
| Обработчики прерываний | Перенос информации из буфера устройства ввода-вывода в память и наоборот, передача управления драйверу. |
| Аппаратура ввода-вывода | Выполнение операции ввода-вывода. |
УПРАВЛЕНИЕ ПАМЯТЬЮ. ОСНОВНЫЕ ФУНКЦИИ.
Длительное время память представляла собой один из самых дорогостоящих ресурсов компьютера. Первые ПК имели память объемом 16-32 Кб и только Macintoch имел 64 Кб.
В настоящее время, благодаря успехам в развитии микроэлектроники ОЗУ достигла размеров 512 Мб - 1 Гб. В соответствии с принципом фон Неймана память имеет иерархическую структуру.
На верхней ступени иерархии находятся регистры микропроцессора, далее идет ОЗУ.
В современных процессорах, для того, чтобы уменьшить разность между сверхбыстродействующей памятью и ОЗУ, между ними включается согласующая память, которая называется Кэш-память.
И на самой низкой ступени иерархии располагается внешняя память, которая имеет самый большой V, но минимальное быстродействие.
Одной из основных задач ОС является координация работы всех этих видов памяти. В первых компьютерах в виду того, что память представляла собой один из самых дорогостоящих ресурсов, главной задачей ОС являлось оптимизированное ОЗУ благодаря рациональной организации и управления ею.
Под организацией памяти понимается, каким образом предоставляется и используется ОЗУ. Будет ли пользователь помещать в память 1 процесс или одновременно несколько процессов. Если в ОЗУ размещено несколько процессов, то будет ли ОС выделять каждому процессу определенный V ОЗУ или будет разбивать память на части различных размеров, которые носят название разделы. Будут ли программы пользователя (процессы) требовать конкретных разделов памяти или будут выполняться в любых разделах. От этих требований зависит, как ОС управляет памятью.
ПОНЯТИЕ О РАСПРЕДЕЛЕНИИ ПАМЯТИ.
Распределению памяти обычно подлежит вся часть ОЗУ, не занятая ОС. Обычно ОС располагается в самых младших адресах памяти, т.е. те, которые начинаются с 0.
ОС для управления памятью должна выполнять следующие функции:
1) Должна отслеживать участки свободной и занятой памяти.
2) Выделять память процессам и освобождать память при завершении процесса.
3) Вытеснять процессы из ОЗУ на магнитный диск в том случае, когда размера памяти не хватает для размещения всех процессов.
4) Возвращать процессы в ОЗУ, когда в ней освобождается место.
5) Настраивать адреса процессов на конкретную область физической памяти.
ТИПЫ АДРЕСОВ.
 Символьные имена присваивает программист при написании программы на языке высокого уровня или ассемблере. Они представляют из себя идентификаторы переменных в программах на алгоритмических языках.
Символьные имена присваивает программист при написании программы на языке высокого уровня или ассемблере. Они представляют из себя идентификаторы переменных в программах на алгоритмических языках.
Виртуальные адреса вырабатывает компилятор или транслятор при переводе программы с языка высокого уровня в машинный язык. Т.к. во время компиляции программы в общем случае неизвестно, в какую область памяти будет закружена программа, то транслятор присваивает переменным и командам условные адреса (виртуальные адреса). Обычно считается по умолчанию, что программа будет размещена, начиная с нулевого адреса.
Совокупность виртуальных адресов, выделенных откомпилированной программе называется виртуальным адресным пространством. Каждый процесс имеет свое собственное виртуальное адресное пространство.
Максимальный размер виртуального адресного пространства ограничивается разрядностью адреса, присущего данной архитектуре компьютера.
Практически никогда максимальный размер виртуального адресного пространства не совпадает с физическим V памяти, установленной на данном компьютере.
Физические адреса – это номера ячеек памяти, где в действительности будут расположены переменные и команды.
Превращение виртуальных адресов в физические может осуществляться 2 способами:
1) Замену виртуальных адресов на физические может производить специальная программа ОС, которая называется перемещающийся загрузчик. Перемещающийся загрузчик, на основании имеющихся у него исходных данных о начальном адресе физической памяти, в которую предстоит загружать программу, и информации, предоставленной ему транслятором об адресозависимых константах программы, выполняет загрузку программы в память, совмещая ее с заменой виртуальных адресов физическими.
2) Программа загружается в память в неизменном виде в виртуальных адресах, при этом ОС фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к ОЗУ выполняется преобразование виртуального адреса в физический.
Второй способ является более гибким, т.к. он допускает перемещение программы в памяти во время ее выполнения, в то время, как перемещающийся загрузчик жестко привязывает программу к определенному участку памяти. Однако второй способ имеет свой недостаток: при выполнении программы нужно производить больше вычислений.
РАСПРЕДЕЛЕНИЕ ПАМЯТИ.

РАСПРЕДЕЛЕНИЕ ПАМЯТИ ФИКСИРОВАННЫМИ РАЗДЕЛАМИ.
Самым простым способом управления ОЗУ является разделение ее на несколько разделов фиксированной величины. Это может производиться вручную оператором во время старта системы, либо происходить автоматически во время запуска системы. При этом может быть 2 варианта распределения памяти при выполнении процесса:
1) Все процессы помещаются в общую очередь и, когда наступает их очередь выполнения, они помещаются в соответствующий раздел памяти.
2) Могут существовать очереди к разделам. В данном случае система управления памятью должна решать следующие задачи:
1. Сравнивать размер программы, поступающей на выполнение с V свободных разделов и выбирать подходящий для данной программы свободный раздел памяти.
2. Загружать программу в раздел и осуществлять настройку адресов.
Этот способ легко реализовывается, но имеет существенный недостаток:
1) Число одновременно выполняемых программ определяется числом разделов.
2) Даже если программа имеет небольшой объем, она все равно будет занимать целиком весь раздел, что приводит к неэффективному использованию памяти.
Такая система управления памятью использовалась в серии машин IBM 360. В современных ОС практически не используется.
РАСПРЕДЕЛЕНИЕ ПАМЯТИ РАЗДЕЛАМИ ПЕРЕМЕННОЙ ВЕЛИЧИНЫ.
В этом случае память заранее не делится на разделы. Вначале вся память свободна. Затем каждой вновь поступающей задаче, выделяется необходимый V памяти. Если достаточный V памяти отсутствует, то задача не принимается на выполнение и стоит в очереди. После завершения задачи память освобождается, и на это место может быть загружена другая задача.
 Следовательно, в произвольный момент времени ОЗУ будет представлять из себя случайную последовательность свободных и занятых участков произвольного размера.
Следовательно, в произвольный момент времени ОЗУ будет представлять из себя случайную последовательность свободных и занятых участков произвольного размера.
Задачи ОС при данном методе управления памятью:
1) Ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти.
2) При поступлении новой задачи – анализ запроса, проверка таблицы свободных областей, выбор раздела, который достаточен для помещения этой задачи.
3) Загрузка задачи в выделенный не занятый раздел и корректировка работы таблиц свободных и занятых областей.
4) После завершения задачи – корректировка свободных и занятых областей.
В этом случае программный код не перемещается. Виртуальные адреса в физические могут быть преобразованы при помощи перемещающегося загрузчика. При выборе раздела для вновь поступившей задачи могут производиться разные алгоритмы:
1) В первый попавшийся раздел доступного размера.
2) В раздел, имеющий наименьший доступный размер.
3) В раздел, имеющий наибольший доступный размер.
Все они имеют свои плюсы и минусы по сравнению с методом управления памятью фиксированными разделами. Этот метод имеет более высокую гибкость, но и один недостаток: фрагментацию памяти.
Фрагментация памяти – образование несмежных свободных участков памяти небольшого V. В такие участки нельзя загрузить ни одну вновь поступающую программу.
РАСПРЕДЕЛЕНИЕ ПАМЯТИ ПЕРЕМЕЩАЮЩИМИСЯ РАЗДЕЛАМИ.
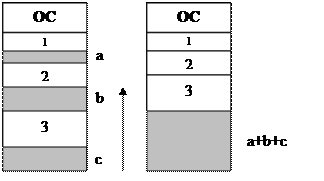 Одним из методов борьбы с фрагментацией памяти является перемещение всех занятых участков либо в сторону старших адресов, либо в сторону младших.
Одним из методов борьбы с фрагментацией памяти является перемещение всех занятых участков либо в сторону старших адресов, либо в сторону младших.
В этом случае в дополнение к тем функциям, которые выполняет ОС при управлении памятью разделами перемещающегося V, добавляется необходимость копировать содержимое разделов из одного места памяти в др
– Конец работы –
Эта тема принадлежит разделу:
Операционные системы
На сайте allrefs.net читайте: Операционные системы.
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Е годы XX в.
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.044 сек.
Новости и инфо для студентов