В курсе описаны фундаментальные принципы проектирования и реализации операционных систем
Основы операционных систем
Авторы: К.А. Коньков, В.Е. КарповИнформация о курсе
В курсе описаны фундаментальные принципы проектирования и реализации операционных систем.
Курс базируется на семестровом курсе «Введение в операционные системы», читаемом авторами в МФТИ и может рассматриваться как учебник для студентов, специализирующихся в области информатики. Курс включает теоретические главы, а также обширный иллюстрационный материал, позволяющий ознакомиться с отдельными аспектами функционирования операционных систем на практике.
Теоретическая часть состоит из 16 лекций. Она имеет традиционное построение и содержит следующие разделы: введение, понятие и реализация процессов, взаимодействие процессов, проблемы взаимоблокировок, организация памяти, структура файловой системы, описание системы ввода-вывода, сети и безопасность операционных систем. Большинство разделов состоит из нескольких тематически связанных глав. В курсе много иллюстраций. В конце каждой теоретической главы перечисляются наиболее важные концепции и идеи, приводятся наборы тестов, которые могут быть использованы для самоконтроля.
Материалы практических занятий дополняют лекционный курс и используются для иллюстрации реализации теоретических положений на примере операционной системы UNIX. На практике рассматриваются организация процессов, различные способы их взаимодействия, устройство файловой системы, системы ввода-вывода, начала сетевого программирования. Текст, размещенный в практической части курса, содержит многочисленные ссылки на лекционный материал.
Цель
Курс предназначен для преподавателей и студентов вузов, специализирующихся в области информатики, а также специалистов, интересующихся проблемами операционных систем и системного программирования.
Предварительные знания
Рекомендуемый уровень предварительной подготовки:
- знакомство с компьютером и его внутренним устройством на уровне пользователя; - знакомство с алгоритмическим языком Си.
Предварительные курсы
· Операционная система UNIX
Дополнительные курсы
· Основы операционных систем. Практикум
· Операционная система Linux
· Организация UNIX-систем и ОС Solaris 9
· Администрирование ОС Solaris 9
1.
Введение
В данной лекции вводится понятие операционной системы; рассматривается эволюция развития операционных систем; описываются функции операционных систем и подходы к построению операционных систем.
2.
Процессы
В лекции описывается основополагающее понятие процесса, рассматриваются его состояния, модель представления процесса в операционной системе и операции, которые могут выполняться над процессами операционной системой.
3.
Планирование процессов
В этой лекции рассматриваются вопросы, связанные с различными уровнями планирования процессов в операционных системах. Описываются основные цели и критерии планирования, а также параметры, на которых оно основывается. Приведены различные алгоритмы планирования.
4.
Кооперация процессов и основные аспекты ее логической организации
Одной из функций операционной системы является обеспечение санкционированного взаимодействия процессов. Лекция посвящена основам логической организации такого взаимодействия. Рассматривается расширение понятия процесс – нить исполнения (thread).
5.
Алгоритмы синхронизации
Для корректного взаимодействия процессов недостаточно одних организационных усилий операционной системы. Необходимы определенные внутренние изменения в поведении процессов. В настоящей лекции рассматриваются вопросы, связанные с такими изменениями, приводятся программные алгоритмы корректной организации взаимодействия процессов.
6.
Механизмы синхронизации
Для повышения производительности вычислительных систем и облегчения задачи программистов существуют специальные механизмы синхронизации. Описание некоторых из них – семафоров Дейкстры, мониторов Хора, очередей сообщений – приводится в этой лекции.
7.
Тупики
В лекции рассматриваются вопросы взаимоблокировок, тупиковых ситуаций и "зависаний" системы
8.
Организация памяти компьютера. Простейшие схемы управления памятью
В настоящей лекции рассматриваются простейшие способы управления памятью в ОС. Физическая память компьютера имеет иерархическую структуру. Программа представляет собой набор сегментов в логическом адресном пространстве. ОС осуществляет связывание логических и физических адресных пространств.
9.
Виртуальная память. Архитектурные средства поддержки виртуальной памяти
Рассмотрены аппаратные особенности поддержки виртуальной памяти. Разбиение адресного пространства процесса на части и динамическая трансляция адреса позволили выполнять процесс даже в отсутствие некоторых его компонентов в оперативной памяти. Следствием такой стратегии является возможность выполнения больших программ, размер которых может превышать размер оперативной памяти.
10.
Аппаратно-независимый уровень управления виртуальной памятью
Большинство ОС используют сегментно-страничную виртуальную память. Для обеспечения нужной производительности менеджер памяти ОС старается поддерживать в оперативной памяти актуальную информацию, пытаясь угадать, к каким логическим адресам последует обращение в недалеком будущем.
11.
Файлы с точки зрения пользователя
В настоящей лекции вводится понятие и рассматриваются основные функции и интерфейс файловой системы.
12.
Реализация файловой системы
Реализация файловой системы связана с такими вопросами, как поддержка понятия логического блока диска, связывания имени файла и блоков его данных, проблемами разделения файлов и управления дисковым пространством.
13.
Система управления вводом-выводом
В лекции рассматриваются основные физические и логические принципы организации ввода-вывода в вычислительных системах.
14.
Сети и сетевые операционные системы
В лекции рассматриваются особенности взаимодействия процессов, выполняющихся на разных операционных системах, и вытекающие из этих особенностей функции сетевых частей операционных систем.
15.
Основные понятия информационной безопасности
Рассмотрены подходы к обеспечению безопасности информационных систем. Ключевые понятия информационной безопасности: конфиденциальность, целостность и доступность информации, а любое действие, направленное на их нарушение, называется угрозой. Основные понятия информационной безопасности регламентированы в основополагающих документах. Существует несколько базовых технологий безопасности, среди которых можно выделить криптографию.
16.
Защитные механизмы операционных систем
Решение вопросов безопасности операционных систем обусловлено их архитектурными особенностями и связано с правильной организацией идентификации и аутентификации, авторизации и аудита.
Лекция: Введение
В данной лекции вводится понятие операционной системы; рассматривается эволюция развития операционных систем; описываются функции операционных систем и подходы к построению операционных систем. Операционная система (ОС) – это программа, которая обеспечивает возможность рационального использования оборудования компьютера удобным для пользователя образом. Вводная лекция рассказывает о предмете, изучаемом в рамках настоящего курса. Вначале мы попытаемся ответить на вопрос, что такое ОС. Затем последует анализ эволюции ОС и рассказ о возникновении основных концепций и компонентов современных ОС. В заключение будет представлена классификация ОС с точки зрения особенностей архитектуры и использования ресурсов компьютера.
Что такое операционная система
Структура вычислительной системы
Во-вторых, вычислительная система состоит из программного обеспечения. Все программное обеспечение принято делить на две части: прикладное и… Рис. 1.1. Слои программного обеспечения компьютерной системыЧто такое ОС
Большинство пользователей имеет опыт эксплуатации операционных систем, но тем не менее они затруднятся дать этому понятию точное определение. Давайте кратко рассмотрим основные точки зрения.
Операционная система как виртуальная машина
Архитектура большинства компьютеров на уровне машинных команд очень неудобна для использования прикладными программами. Например, работа с диском…Операционная система как менеджер ресурсов
Операционная система как защитник пользователей и программ
Операционная система как постоянно функционирующее ядро
Как мы видим, существует много точек зрения на то, что такое операционная система. Невозможно дать ей адекватное строгое определение. Нам проще…Первый период (1945–1955 гг.). Ламповые машины. Операционных систем нет
Первые шаги в области разработки электронных вычислительных машин были предприняты в конце Второй мировой войны. В середине 40-х были созданы первые… Вычислительная система выполняла одновременно только одну операцию (ввод-вывод… Существенная часть времени уходила на подготовку запуска программы, а сами программы выполнялись строго…Второй период (1955 г.–начало 60-х). Компьютеры на основе транзисторов. Пакетные операционные системы
Изменяется сам процесс прогона программ. Теперь пользователь приносит программу с входными данными в виде колоды перфокарт и указывает необходимые… Смена запрошенных ресурсов вызывает приостановку выполнения программ, в… Появляются первые системы пакетной обработки, которые просто автоматизируют запуск одной программы из пакета за другой…Третий период (начало 60-х – 1980 г.). Компьютеры на основе интегральных микросхем. Первые многозадачные ОС
Повышению эффективности использования процессорного времени мешает низкая скорость работы механических устройств ввода-вывода (быстрый считыватель… Магнитные ленты были устройствами последовательного доступа, то есть… Дальнейшее повышение эффективности использования процессора было достигнуто с помощью мультипрограммирования. Идея…Четвертый период (с 1980 г. по настоящее время). Персональные компьютеры. Классические, сетевые и распределенные системы
Следующий период в эволюции вычислительных систем связан с появлением больших интегральных схем (БИС). В эти годы произошло резкое возрастание степени интеграции и снижение стоимости микросхем. Компьютер, не отличающийся по архитектуре от PDP-11, по цене и простоте эксплуатации стал доступен отдельному человеку, а не отделу предприятия или университета. Наступила эра персональных компьютеров. Первоначально персональные компьютеры предназначались для использования одним пользователем в однопрограммном режиме, что повлекло за собой деградацию архитектуры этих ЭВМ и их операционных систем (в частности, пропала необходимость защиты файлов и памяти, планирования заданий и т. п.).
Компьютеры стали использоваться не только специалистами, что потребовало разработки "дружественного" программного обеспечения.
Однако рост сложности и разнообразия задач, решаемых на персональных компьютерах, необходимость повышения надежности их работы привели к возрождению практически всех черт, характерных для архитектуры больших вычислительных систем.
В середине 80-х стали бурно развиваться сети компьютеров, в том числе персональных, работающих под управлением сетевых или распределенных операционных систем.
В сетевых операционных системах пользователи могут получить доступ к ресурсам другого сетевого компьютера, только они должны знать об их наличии и уметь это сделать. Каждая машина в сети работает под управлением своей локальной операционной системы, отличающейся от операционной системы автономного компьютера наличием дополнительных средств (программной поддержкой для сетевых интерфейсных устройств и доступа к удаленным ресурсам), но эти дополнения не меняют структуру операционной системы.
Распределенная система, напротив, внешне выглядит как обычная автономная система. Пользователь не знает и не должен знать, где его файлы хранятся – на локальной или удаленной машине – и где его программы выполняются. Он может вообще не знать, подключен ли его компьютер к сети. Внутреннее строение распределенной операционной системы имеет существенные отличия от автономных систем.
В дальнейшем автономные операционные системы мы будем называть классическими операционными системами.
Просмотрев этапы развития вычислительных систем, мы можем выделить шесть основных функций, которые выполняли классические операционные системы в процессе эволюции:
· Планирование заданий и использования процессора.
· Обеспечение программ средствами коммуникации и синхронизации.
· Управление памятью.
· Управление файловой системой.
· Управление вводом-выводом.
· Обеспечение безопасности
Каждая из приведенных функций обычно реализована в виде подсистемы, являющейся структурным компонентом ОС. В каждой операционной системе эти функции, конечно, реализовывались по-своему, в различном объеме. Они не были изначально придуманы как составные части операционных систем, а появились в процессе развития, по мере того как вычислительные системы становились все более удобными, эффективными и безопасными. Эволюция вычислительных систем, созданных человеком, пошла по такому пути, но никто еще не доказал, что это единственно возможный путь их развития. Операционные системы существуют потому, что на данный момент их существование – это разумный способ использования вычислительных систем. Рассмотрение общих принципов и алгоритмов реализации их функций и составляет содержание большей части нашего курса, в котором будут последовательно описаны перечисленные подсистемы.
Основные понятия, концепции ОС
В процессе эволюции возникло несколько важных концепций, которые стали неотъемлемой частью теории и практики ОС. Рассматриваемые в данном разделе понятия будут встречаться и разъясняться на протяжении всего курса. Здесь дается их краткое описание.
Системные вызовы
Системные вызовы (system calls) – это интерфейс между операционной системой и пользовательской программой. Они создают, удаляют и используют… Основное отличие состоит в том, что при системном вызове задача переходит в… В этом режиме работает код ядра операционной системы, причем исполняется он в адресном пространстве и в контексте…Файлы
Файлы предназначены для хранения информации на внешних носителях, то есть принято, что информация, записанная, например, на диске, должна находиться внутри файла. Обычно под файлом понимают именованную часть пространства на носителе информации.
Главная задача файловой системы (file system) – скрыть особенности ввода-вывода и дать программисту простую абстрактную модель файлов, независимых от устройств. Для чтения, создания, удаления, записи, открытия и закрытия файлов также имеется обширная категория системных вызовов (создание, удаление, открытие, закрытие, чтение и т.д.). Пользователям хорошо знакомы такие связанные с организацией файловой системы понятия, как каталог, текущий каталог, корневой каталог, путь. Для манипулирования этими объектами в операционной системе имеются системные вызовы. Файловая система ОС описана в лекциях 11–12.
Процессы, нити
Концепция процесса в ОС одна из наиболее фундаментальных. Процессы подробно рассмотрены в лекциях 2–7. Там же описаны нити, или легковесные процессы.
Архитектурные особенности ОС
До сих пор мы говорили о взгляде на операционные системы извне, о том, что делают операционные системы. Дальнейший наш курс будет посвящен тому, как они это делают. Но мы пока ничего не сказали о том, что они представляют собой изнутри, какие подходы существуют к их построению.
Монолитное ядро
Во многих операционных системах с монолитным ядром сборка ядра, то есть его компиляция, осуществляется отдельно для каждого компьютера, на который… Монолитное ядро – старейший способ организации операционных систем. Примером… Даже в монолитных системах можно выделить некоторую структуру. Как в бетонной глыбе можно различить вкрапления…Виртуальные машины
Рис. 1.3. Вариант виртуальной машины Первой реальной системой такого рода была система CP/CMS, или VM/370, как ее называют сейчас, для семейства машин…Микроядерная архитектура
Рис. 1.4. Микроядерная архитектура операционной системы Остальные компоненты системы взаимодействуют друг с другом путем передачи сообщений через микроядро.Смешанные системы
Другим примером смешанного подхода может служить возможность запуска операционной системы с монолитным ядром под управлением микроядра. Так устроены… Наиболее тесно элементы микроядерной архитектуры и элементы монолитного ядра… Таким образом, Windows NT можно с полным правом назвать гибридной операционной системой.Классификация ОС
Существует несколько схем классификации операционных систем. Ниже приведена классификация по некоторым признакам с точки зрения пользователя.
Реализация многозадачности
· многозадачные (Unix, OS/2, Windows); · однозадачные (например, MS-DOS). Многозадачная ОС, решая проблемы распределения ресурсов и конкуренции, полностью реализует мультипрограммный режим в…Поддержка многопользовательского режима
По числу одновременно работающих пользователей ОС можно разделить на:
· однопользовательские (MS-DOS, Windows 3.x);
· многопользовательские (Windows NT, Unix).
Наиболее существенное отличие между этими ОС заключается в наличии у многопользовательских систем механизмов защиты персональных данных каждого пользователя.
Многопроцессорная обработка
Многопроцессорные ОС разделяют на симметричные и асимметричные. В симметричных ОС на каждом процессоре функционирует одно и то же ядро, и задача… В асимметричных ОС процессоры неравноправны. Обычно существует главный…Системы реального времени
Они используются для управления различными техническими объектами или технологическими процессами. Такие системы характеризуются предельно… Столь жесткие ограничения сказываются на архитектуре систем реального времени,… Приведенная классификация ОС не является исчерпывающей. Более подробно особенности применения современных ОС…Заключение
Мы рассмотрели различные взгляды на то, что такое операционная система; изучили историю развития операционных систем; выяснили, какие функции обычно выполняют операционные системы; наконец, разобрались в том, какие существуют подходы к построению операционных систем. Следующую лекцию мы посвятим выяснению понятия "процесс" и вопросам планирования процессов.
Приложение 1.
Некоторые сведения об архитектуре компьютера
Рис. 1.5. Некоторые компоненты компьютера Основная память используется для запоминания программ и данных в двоичном виде и организована в виде упорядоченного…Взаимодействие с периферийными устройствами
Любая операция ввода-вывода предполагает диалог между ЦП и контроллером устройства. Когда процессору встречается команда, связанная с… В свою очередь, любые изменения с внешними устройствами имеют следствием… В современных компьютерах также имеется возможность непосредственного взаимодействия между контроллером и основной…Лекция: Процессы
Начиная с этой лекции мы будем знакомиться с внутренним устройством и механизмами действия операционных систем, разбирая одну за другой их основные…Понятие процесса
Рассмотрим следующий пример. Два студента запускают программу извлечения квадратного корня. Один хочет вычислить квадратный корень из 4, а второй –… Рассматривая системы пакетной обработки, мы ввели понятие "задание"… Это происходит потому, что термины "программа" и "задание" предназначены для описания статических,…Состояния процесса
Как видим, каждый процесс может находиться как минимум в двух состояниях: процесс исполняется и процесс не исполняется. Диаграмма состояний процесса… Рис. 2.1. Простейшая диаграмма состояний процессаОперации над процессами и связанные с ними понятия
Набор операций
В дальнейшем, когда мы будем говорить об алгоритмах планирования, в нашей модели появится еще одна операция, не имеющая парной: изменение приоритета… Операции создания и завершения процесса являются одноразовыми, так как…Process Control Block и контекст процесса
Ее состав и строение зависят, конечно, от конкретной операционной системы. Во многих операционных системах информация, характеризующая процесс,… Информацию, для хранения которой предназначен блок управления процессом,…Одноразовые операции
Сложный жизненный путь процесса в компьютере начинается с его рождения. Любая операционная система, поддерживающая концепцию процессов, должна обладать средствами для их создания. В очень простых системах (например, в системах, спроектированных для работы только одного конкретного приложения) все процессы могут быть порождены на этапе старта системы. Более сложные операционные системы создают процессы динамически, по мере необходимости. Инициатором рождения нового процесса после старта операционной системы может выступить либо процесс пользователя, совершивший специальный системный вызов, либо сама операционная система, то есть, в конечном итоге, тоже некоторый процесс. Процесс, инициировавший создание нового процесса, принято называть процессом-родителем (parent process), а вновь созданный процесс – процессом-ребенком (child process). Процессы-дети могут в свою очередь порождать новых детей и т. д., образуя, в общем случае, внутри системы набор генеалогических деревьев процессов – генеалогический лес. Пример генеалогического леса изображен на рисунке 2.4. Следует отметить, что все пользовательские процессы вместе с некоторыми процессами операционной системы принадлежат одному и тому же дереву леса. В ряде вычислительных систем лес вообще вырождается в одно такое дерево.
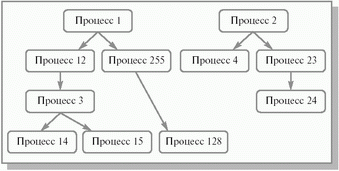
Рис. 2.4. Упрощенный генеалогический лес процессов. Стрелочка означает отношение родитель–ребенок
При рождении процесса система заводит новый PCB с состоянием процесса рождение и начинает его заполнять. Новый процесс получает собственный уникальный идентификационный номер. Поскольку для хранения идентификационного номера процесса в операционной системе отводится ограниченное количество битов, для соблюдения уникальности номеров количество одновременно присутствующих в ней процессов должно быть ограничено. После завершения какого-либо процесса его освободившийся идентификационный номер может быть повторно использован для другого процесса.
Обычно для выполнения своих функций процесс-ребенок требует определенных ресурсов: памяти, файлов, устройств ввода-вывода и т. д. Существует два подхода к их выделению. Новый процесс может получить в свое распоряжение некоторую часть родительских ресурсов, возможно разделяя с процессом-родителем и другими процессами-детьми права на них, или может получить свои ресурсы непосредственно от операционной системы. Информация о выделенных ресурсах заносится в PCB.
После наделения процесса-ребенка ресурсами необходимо занести в его адресное пространство программный код, значения данных, установить программный счетчик. Здесь также возможны два решения. В первом случае процесс-ребенок становится дубликатом процесса-родителя по регистровому и пользовательскому контекстам, при этом должен существовать способ определения, кто для кого из процессов-двойников является родителем. Во втором случае процесс-ребенок загружается новой программой из какого-либо файла. Операционная система Unix разрешает порождение процесса только первым способом; для запуска новой программы необходимо сначала создать копию процесса-родителя, а затем процесс-ребенок должен заменить свой пользовательский контекст с помощью специального системного вызова. Операционная система VAX/VMS допускает только второе решение. В Windows NT возможны оба варианта (в различных API).
Порождение нового процесса как дубликата процесса-родителя приводит к возможности существования программ (т. е. исполняемых файлов), для работы которых организуется более одного процесса. Возможность замены пользовательского контекста процесса по ходу его работы (т. е. загрузки для исполнения новой программы) приводит к тому, что в рамках одного и того же процесса может последовательно выполняться несколько различных программ.
После того как процесс наделен содержанием, в PCB дописывается оставшаяся информация, и состояние нового процесса изменяется на готовность. Осталось сказать несколько слов о том, как ведут себя процессы-родители после рождения процессов-детей. Процесс-родитель может продолжать свое выполнение одновременно с выполнением процесса-ребенка, а может ожидать завершения работы некоторых или всех своих "детей".
Мы не будем подробно останавливаться на причинах, которые могут привести к завершению жизненного цикла процесса. После того как процесс завершил свою работу, операционная система переводит его в состояние закончил исполнение и освобождает все ассоциированные с ним ресурсы, делая соответствующие записи в блоке управления процессом. При этом сам PCB не уничтожается, а остается в системе еще некоторое время. Это связано с тем, что процесс-родитель после завершения процесса-ребенка может запросить операционную систему о причине "смерти" порожденного им процесса и/или статистическую информацию о его работе. Подобная информация сохраняется в PCB отработавшего процесса до запроса процесса-родителя или до конца его деятельности, после чего все следы завершившегося процесса окончательно исчезают из системы. В операционной системе Unix процессы, находящиеся в состоянии закончил исполнение, принято называть процессами-зомби.
Следует заметить, что в ряде операционных систем (например, в VAX/VMS) гибель процесса-родителя приводит к завершению работы всех его "детей". В других операционных системах (например, в Unix) процессы-дети продолжают свое существование и после окончания работы процесса-родителя. При этом возникает необходимость изменения информации в PCB процессов-детей о породившем их процессе для того, чтобы генеалогический лес процессов оставался целостным. Рассмотрим следующий пример. Пусть процесс с номером 2515 был порожден процессом с номером 2001 и после завершения его работы остается в вычислительной системе неограниченно долго. Тогда не исключено, что номер 2001 будет использован операционной системой повторно для совсем другого процесса. Если не изменить информацию о процессе-родителе для процесса 2515, то генеалогический лес процессов окажется некорректным – процесс 2515 будет считать своим родителем новый процесс 2001, а процесс 2001 будет открещиваться от нежданного потомка. Как правило, "осиротевшие" процессы "усыновляются" одним из системных процессов, который порождается при старте операционной системы и функционирует все время, пока она работает.
Многоразовые операции
Одноразовые операции приводят к изменению количества процессов, находящихся под управлением операционной системы, и всегда связаны с выделением или освобождением определенных ресурсов. Многоразовые операции, напротив, не приводят к изменению количества процессов в операционной системе и не обязаны быть связанными с выделением или освобождением ресурсов.
В этом разделе мы кратко опишем действия, которые производит операционная система при выполнении многоразовых операций над процессами. Более подробно эти действия будут рассмотрены далее в соответствующих лекциях.
Запуск процесса. Из числа процессов, находящихся в состоянии готовность, операционная система выбирает один процесс для последующего исполнения. Критерии и алгоритмы такого выбора будут подробно рассмотрены в лекции 3 – "Планирование процессов". Для избранного процесса операционная система обеспечивает наличие в оперативной памяти информации, необходимой для его дальнейшего выполнения. То, как она это делает, будет в деталях описано в лекциях 8-10. Далее состояние процесса изменяется на исполнение, восстанавливаются значения регистров для данного процесса и управление передается команде, на которую указывает счетчик команд процесса. Все данные, необходимые для восстановления контекста, извлекаются из PCB процесса, над которым совершается операция.
Приостановка процесса. Работа процесса, находящегося в состоянии исполнение, приостанавливается в результате какого-либо прерывания. Процессор автоматически сохраняет счетчик команд и, возможно, один или несколько регистров в стеке исполняемого процесса, а затем передает управление по специальному адресу обработки данного прерывания. На этом деятельность hardware по обработке прерывания завершается. По указанному адресу обычно располагается одна из частей операционной системы. Она сохраняет динамическую часть системного и регистрового контекстов процесса в его PCB, переводит процесс в состояние готовность и приступает к обработке прерывания, то есть к выполнению определенных действий, связанных с возникшим прерыванием.
Блокирование процесса. Процесс блокируется, когда он не может продолжать работу, не дождавшись возникновения какого-либо события в вычислительной системе. Для этого он обращается к операционной системе с помощью определенного системного вызова. Операционная система обрабатывает системный вызов (инициализирует операцию ввода-вывода, добавляет процесс в очередь процессов, дожидающихся освобождения устройства или возникновения события, и т. д.) и, при необходимости сохранив нужную часть контекста процесса в его PCB, переводит процесс из состояния исполнение в состояние ожидание. Подробнее эта операция будет рассматриваться в лекции 13.
Разблокирование процесса. После возникновения в системе какого-либо события операционной системе нужно точно определить, какое именно событие произошло. Затем операционная система проверяет, находился ли некоторый процесс в состоянии ожидание для данного события, и если находился, переводит его в состояние готовность, выполняя необходимые действия, связанные с наступлением события (инициализация операции ввода-вывода для очередного ожидающего процесса и т. п.). Эта операция, как и операция блокирования, будет подробно описана в лекции 13.
Переключение контекста
Давайте для примера упрощенно рассмотрим, как в реальности может протекать операция разблокирования процесса, ожидающего ввода-вывода (см. рис.… Рис. 2.5. Выполнение операции разблокирования процесса. Использование термина "код пользователя" не…Заключение
Понятие процесса характеризует некоторую совокупность набора исполняющихся команд, ассоциированных с ним ресурсов и текущего момента его выполнения, находящуюся под управлением операционной системы. В любой момент процесс полностью описывается своим контекстом, состоящим из регистровой, системной и пользовательской частей. В операционной системе процессы представляются определенной структурой данных – PCB, отражающей содержание регистрового и системного контекстов. Процессы могут находиться в пяти основных состояниях: рождение, готовность, исполнение, ожидание, закончил исполнение. Из состояния в состояние процесс переводится операционной системой в результате выполнения над ним операций. Операционная система может выполнять над процессами следующие операции: создание процесса, завершение процесса, приостановка процесса, запуск процесса, блокирование процесса, разблокирование процесса, изменение приоритета процесса. Между операциями содержимое PCB не изменяется. Деятельность мультипрограммной операционной системы состоит из цепочек перечисленных операций, выполняемых над различными процессами, и сопровождается процедурами сохранения/восстановления работоспособности процессов, т. е. переключением контекста. Переключение контекста не имеет отношения к полезной работе, выполняемой процессами, и время, затраченное на него, сокращает полезное время работы процессора.
Лекция: Планирование процессов
В этой лекции рассматриваются вопросы, связанные с различными уровнями планирования процессов в операционных системах. Описываются основные цели и… Я планов наших люблю громадьё... В. В. МаяковскийУровни планирования
Планирование заданий используется в качестве долгосрочного планирования процессов. Оно отвечает за порождение новых процессов в системе, определяя… Планирование использования процессора применяется в качестве краткосрочного… В некоторых вычислительных системах бывает выгодно для повышения производительности временно удалить какой-либо…Критерии планирования и требования к алгоритмам
Независимо от поставленных целей планирования желательно также, чтобы алгоритмы обладали следующими свойствами. Были предсказуемыми. Одно и то… Многие из приведенных выше целей и свойств являются противоречивыми. Улучшая…Параметры планирования
Все параметры планирования можно разбить на две большие группы: статические параметры и динамические параметры. Статические параметры не изменяются… К статическим параметрам вычислительной системы можно отнести предельные… К статическим параметрам процессов относятся характеристики, как правило присущие заданиям уже на этапе загрузки. …Вытесняющее и невытесняющее планирование
В случаях 1 и 2 процесс, находившийся в состоянии исполнение, не может дальше исполняться, и операционная система вынуждена осуществлять… Невытесняющее планирование используется, например, в MS Windows 3.1 и ОС Apple… Вытесняющее планирование обычно используется в системах разделения времени. В этом режиме планирования процесс может…Алгоритмы планирования
First-Come, First-Served (FCFS) Простейшим алгоритмом планирования является алгоритм, который принято… Такой алгоритм выбора процесса осуществляет невытесняющее планирование. Процесс, получивший в свое распоряжение…Гарантированное планирование
то i-й пользователь несправедливо обделен процессорным временем. Если же τi>>Ti/N то система явно благоволит к пользователю с номером i. Вычислим для процессов… и будем предоставлять очередной квант времени готовому процессу с наименьшей величиной этого отношения. Предложенный…Приоритетное планирование
Алгоритмы назначения приоритетов процессов могут опираться как на внутренние параметры, связанные с происходящим внутри вычислительной системы, так… Планирование с использованием приоритетов может быть как вытесняющим, так и… Пусть в очередь процессов, находящихся в состоянии готовность, поступают те же процессы, что и в примере для…Заключение
Одним из наиболее ограниченных ресурсов вычислительной системы является процессорное время. Для его распределения между многочисленными процессами в системе приходится применять процедуру планирования процессов. По степени длительности влияния планирования на поведение вычислительной системы различают краткосрочное, среднесрочное и долгосрочное планирование процессов. Конкретные алгоритмы планирования процессов зависят от поставленных целей, класса решаемых задач и опираются на статические и динамические параметры процессов и компьютерных систем. Различают вытесняющий и невытесняющий режимы планирования. При невытесняющем планировании исполняющийся процесс уступает процессор другому процессу только по собственному желанию, при вытесняющем планировании исполняющийся процесс может быть вытеснен из состояния исполнения помимо своей воли.
Простейшим алгоритмом планирования является невытесняющий алгоритм FCFS, который, однако, может существенно задерживать короткие процессы, не вовремя перешедшие в состояние готовность. В системах разделения времени широкое распространение получила вытесняющая версия этого алгоритма – RR.
Среди всех невытесняющих алгоритмов оптимальным с точки зрения среднего времени ожидания процессов является алгоритм SJF. Существует и вытесняющий вариант этого алгоритма. В интерактивных системах часто используется алгоритм гарантированного планирования, обеспечивающий пользователям равные части процессорного времени.
Алгоритм SJF и алгоритм гарантированного планирования являются частными случаями планирования с использованием приоритетов. В более общих методах приоритетного планирования применяются многоуровневые очереди процессов, готовых к исполнению, и многоуровневые очереди с обратной связью. Будучи наиболее сложными в реализации, эти способы планирования обеспечивают гибкое поведение вычислительных систем и их адаптивность к решению задач разных классов.
- Лекция: Кооперация процессов и основные аспекты ее логической организации
Одной из функций операционной системы является обеспечение санкционированного взаимодействия процессов. Лекция посвящена основам логической организации такого взаимодействия. Рассматривается расширение понятия процесс – нить исполнения (thread).
Взаимодействие процессов в вычислительной системе напоминает жизнь в коммунальной квартире. Постоянное ожидание в очереди к местам общего пользования (процессору) и ежедневная борьба за ресурсы (кто опять занял все конфорки на плите?). Для нормального функционирования процессов операционная система старается максимально обособить их друг от друга. Каждый процесс имеет собственное адресное пространство (каждая семья должна жить в отдельной комнате), нарушение которого, как правило, приводит к аварийной остановке процесса (вызов милиции). Каждому процессу по возможности предоставляются свои дополнительные ресурсы (каждая семья предпочитает иметь собственный холодильник). Тем не менее для решения некоторых задач (приготовление праздничного стола на всю квартиру) процессы могут объединять свои усилия. В настоящей лекции описываются причины взаимодействия процессов, способы их взаимодействия и возникающие при этом проблемы (попробуйте отремонтировать общую квартиру так, чтобы жильцы не перессорились друг с другом).
Взаимодействующие процессы
Для чего процессам нужно заниматься совместной деятельностью? Какие существуют причины для их кооперации? Повышение скорости работы. Пока один… Процессы не могут взаимодействовать, не общаясь, то есть не обмениваясь… Различные процессы в вычислительной системе изначально представляют собой обособленные сущности. Работа одного…Категории средств обмена информацией
Логическая организация механизма передачи информации
Как устанавливается связь?
К этому же вопросу тесно примыкает вопрос о способе адресации при использовании средства связи. Если я передаю некоторую информацию, я должен… Различают два способа адресации: прямую и непрямую. В случае прямой адресации… При непрямой адресации данные помещаются передающим процессом в некоторый промежуточный объект для хранения данных,…Информационная валентность процессов и средств связи
Понятно, что при прямой адресации только одно фиксированное средство связи может быть задействовано для обмена данными между двумя процессами, и… К этой же группе вопросов следует отнести и вопрос о направленности связи.…Особенности передачи информации с помощью линий связи
Буферизация
При использовании канального средства связи с непрямой адресацией под емкостью буфера обычно понимается количество информации, которое может быть…Поток ввода/вывода и сообщения
Одним из наиболее простых способов передачи информации между процессами по линиям связи является передача данных через pipe (канал, трубу или, как… Если разрешить процессу, создавшему трубу, сообщать о ее местонахождении в… В модели сообщений процессы налагают на передаваемые данные некоторую структуру. Весь поток информации они разделяют…Надежность средств связи
Мы будем называть способ коммуникации надежным, если при обмене данными выполняются четыре условия. Не происходит потери информации. Не… Очевидно, что передача данных через разделяемую память является надежным… Каким образом в вычислительных системах пытаются бороться с ненадежностью коммуникаций? Давайте рассмотрим возможные…Как завершается связь?
Если кооперативные процессы прекращают взаимодействие согласованно, то такое прекращение не влияет на их дальнейшее поведение. Иная картина…Нити исполнения
В свое время внедрение идеи мультипрограммирования позволило повысить пропускную способность компьютерных систем, т. е. уменьшить среднее время… Ввести массив a Ввести массив bЗаключение
Для достижения поставленной цели различные процессы могут исполняться псевдопараллельно на одной вычислительной системе или параллельно на разных вычислительных системах, взаимодействуя между собой. Причинами для совместной деятельности процессов обычно являются: необходимость ускорения решения задачи, совместное использование обновляемых данных, удобство работы или модульный принцип построения программных комплексов. Процессы, которые влияют на поведение друг друга путем обмена информацией, называют кооперативными или взаимодействующими процессами, в отличие от независимых процессов, не оказывающих друг на друга никакого воздействия и ничего не знающих о взаимном существовании в вычислительной системе.
Для обеспечения корректного обмена информацией операционная система должна предоставить процессам специальные средства связи. По объему передаваемой информации и степени возможного воздействия на поведение процесса, получившего информацию, их можно разделить на три категории: сигнальные, канальные и разделяемую память. Через канальные средства коммуникации информация может передаваться в виде потока данных или в виде сообщений и накапливаться в буфере определенного размера. Для инициализации "общения" процессов и его прекращения могут потребоваться специальные действия со стороны операционной системы. Процессы, связываясь друг с другом, могут использовать непрямую, прямую симметричную и прямую асимметричную схемы адресации. Существуют одно- и двунаправленные средства передачи информации. Средства коммуникации обеспечивают надежную связь, если при общении процессов не происходит потери и повреждения информации, не появляется лишней информации, не нарушается порядок данных.
Усилия, направленные на ускорение решения задач в рамках классических операционных систем, привели к появлению новой абстракции внутри понятия "процесс" – нити исполнения или просто нити. Нити процесса разделяют его программный код, глобальные переменные и системные ресурсы, но каждая нить имеет собственный программный счетчик, свое содержимое регистров и свой стек. Теперь процесс представляется как совокупность взаимодействующих нитей и выделенных ему ресурсов. Нити могут порождать новые нити внутри своего процесса, они имеют состояния, аналогичные состояниям процесса, и могут переводиться операционной системой из одного состояния в другое. В системах, поддерживающих нити на уровне ядра, планирование использования процессора осуществляется в терминах нитей исполнения, а управление остальными системными ресурсами – в терминах процессов. Накладные расходы на создание новой нити и на переключение контекста между нитями одного процесса существенно меньше, чем на те же самые действия для процессов, что позволяет на однопроцессорной вычислительной системе ускорять решение задач с помощью организации работы нескольких взаимодействующих нитей.
Лекция: Алгоритмы синхронизации
Для корректного взаимодействия процессов недостаточно одних организационных усилий операционной системы. Необходимы определенные внутренние… В предыдущей лекции мы говорили о внешних проблемах кооперации, связанных с организацией взаимодействия процессов со…Interleaving, race condition и взаимоисключения
Неделимые операции могут иметь внутренние невидимые действия (взять батон хлеба в левую руку, взять нож в правую руку, произвести отрезание). Мы же… Пусть имеется две активности P: a b cКритическая секция
Здесь критический участок для каждого процесса – от операции "Обнаруживает, что хлеба нет" до операции "Возвращается в комнату"… Сделать процесс добывания хлеба атомарной операцией можно было бы следующим… Итак, для решения задачи необходимо, чтобы в том случае, когда процесс находится в своем критическом участке, другие…Программные алгоритмы организации взаимодействия процессов
Требования, предъявляемые к алгоритмам
Надо заметить, что описание соответствующего алгоритма в нашем случае означает описание способа организации пролога и эпилога для критической…Запрет прерываний
while (some condition) { запретить все прерывания critical sectionПеременная-замок
shared int lock = 0; /* shared означает, что */ /* переменная является разделяемой */Строгое чередование
shared int turn = 0; while (some condition) {Флаги готовности
shared int ready[2] = {0, 0}; Когда i-й процесс готов войти в критическую секцию, он присваивает элементу… while (some condition) {Алгоритм Петерсона
shared int ready[2] = {0, 0}; shared int turn; while (some condition) {Аппаратная поддержка взаимоисключений
Многие вычислительные системы помимо этого имеют специальные команды процессора, которые позволяют проверить и изменить значение машинного слова или… Команда Test-and-Set (проверить и присвоить 1) О выполнении команды Test-and-Set, осуществляющей проверку значения логической переменной с одновременной установкой…Заключение
Последовательное выполнение некоторых действий, направленных на достижение определенной цели, называется активностью. Активности состоят из атомарных операций, выполняемых неразрывно, как единичное целое. При исполнении нескольких активностей в псевдопараллельном режиме атомарные операции различных активностей могут перемешиваться между собой с соблюдением порядка следования внутри активностей. Это явление получило название interleaving (чередование). Если результаты выполнения нескольких активностей не зависят от варианта чередования, то такой набор активностей называется детерминированным. В противном случае он носит название недетерминированного. Существует достаточное условие Бернстайна для определения детерминированности набора активностей, но оно накладывает очень жесткие ограничения на набор, требуя практически не взаимодействующих активностей. Про недетерминированный набор активностей говорят, что он имеет race condition (условие гонки, состязания). Устранение race condition возможно при ограничении допустимых вариантов чередований атомарных операций с помощью синхронизации поведения активностей. Участки активностей, выполнение которых может привести к race condition, называют критическими участками. Необходимым условием для устранения race condition является организация взаимоисключения на критических участках: внутри соответствующих критических участков не может одновременно находиться более одной активности.
Для эффективных программных алгоритмов устранения race condition помимо условия взаимоисключения требуется выполнение следующих условий: алгоритмы не используют специальных команд процессора для организации взаимоисключений, алгоритмы ничего не знают о скоростях выполнения процессов, алгоритмы удовлетворяют условиям прогресса и ограниченного ожидания. Все эти условия выполняются в алгоритме Петерсона для двух процессов и алгоритме булочной – для нескольких процессов.
Применение специальных команд процессора, выполняющих ряд действий как атомарную операцию, – Test-and-Set, Swap – позволяет существенно упростить алгоритмы синхронизации процессов.
Лекция: Механизмы синхронизации
Для повышения производительности вычислительных систем и облегчения задачи программистов существуют специальные механизмы синхронизации. Описание… Рассмотренные в конце предыдущей лекции алгоритмы хотя и являются корректными, но достаточно громоздки и не обладают…Семафоры
Одним из первых механизмов, предложенных для синхронизации поведения процессов, стали семафоры, концепцию которых описал Дейкстра (Dijkstra) в 1965 году.
Концепция семафоров
P(S): пока S == 0 процесс блокируется; S = S – 1; V(S): S = S + 1;Решение проблемы producer-consumer с помощью семафоров
Producer: while(1) { produce_item; put_item;Мониторы
В сложных программах произвести анализ правильности использования семафоров с карандашом в руках становится очень непросто. В то же время обычные… Мониторы представляют собой тип данных, который может быть с успехом внедрен в… monitor monitor_name {Сообщения
В случае непрямой адресации мы будем обозначать их так: send(A, message) – послать сообщение message в почтовый ящик A; … Примитивы send и receive уже имеют скрытый от наших глаз механизм…Эквивалентность семафоров, мониторов и сообщений
Мы рассмотрели три высокоуровневых механизма, использующихся для организации взаимодействия процессов. Можно показать, что в рамках одной вычислительной системы, когда процессы имеют возможность использовать разделяемую память, все они эквивалентны. Это означает, что любые два из предложенных механизмов могут быть реализованы на базе третьего, оставшегося механизма.
Реализация мониторов и передачи сообщений с помощью семафоров
Для выполнения операции wait над условной переменной компилятор будет генерировать вызов функции wait, которая выполняет операцию V для семафора… Semaphore mutex = 1;Реализация семафоров и передачи сообщений с помощью мониторов
Самый простой способ такой реализации выглядит следующим образом. Заведем внутри монитора переменную-счетчик, связанный с эмулируемым семафором…Реализация семафоров и мониторов с помощью очередей сообщений
После получения сообщения синхронизирующий процесс проверяет значение счетчика, чтобы выяснить, можно ли совершить требуемую операцию. Операция V… Поскольку мы показали ранее, как из семафоров построить мониторы, мы доказали…Заключение
Для организации синхронизации процессов могут применяться специальные механизмы высокого уровня, блокирующие процесс, ожидающий входа в критическую секцию или наступления своей очереди для использования совместного ресурса. К таким механизмам относятся, например, семафоры, мониторы и сообщения. Все эти конструкции являются эквивалентными, т. е., используя любую из них, можно реализовать две оставшиеся.
Лекция: Тупики
В лекции рассматриваются вопросы взаимоблокировок, тупиковых ситуаций и "зависаний" системы
Введение
В предыдущих лекциях мы рассматривали способы синхронизации процессов, которые позволяют процессам успешно кооперироваться. Однако в некоторых случаях могут возникнуть непредвиденные затруднения. Предположим, что несколько процессов конкурируют за обладание конечным числом ресурсов. Если запрашиваемый процессом ресурс недоступен, ОС переводит данный процесс в состояние ожидания. В случае когда требуемый ресурс удерживается другим ожидающим процессом, первый процесс не сможет сменить свое состояние. Такая ситуация называется тупиком (deadlock). Говорят, что в мультипрограммной системе процесс находится в состоянии тупика, если он ожидает события, которое никогда не произойдет. Системная тупиковая ситуация, или "зависание системы", является следствием того, что один или более процессов находятся в состоянии тупика. Иногда подобные ситуации называют взаимоблокировками. В общем случае проблема тупиков эффективного решения не имеет.
Рассмотрим пример. Предположим, что два процесса осуществляют вывод с ленты на принтер. Один из них успел монополизировать ленту и претендует на принтер, а другой наоборот. После этого оба процесса оказываются заблокированными в ожидании второго ресурса (см. рис. 7.1).
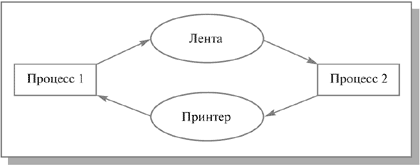
Рис. 7.1. Пример тупиковой ситуации
Определение. Множество процессов находится в тупиковой ситуации, если каждый процесс из множества ожидает события, которое может вызвать только другой процесс данного множества. Так как все процессы чего-то ожидают, то ни один из них не сможет инициировать событие, которое разбудило бы другого члена множества и, следовательно, все процессы будут спать вместе.
Выше приведен пример взаимоблокировки, возникающей при работе с так называемыми выделенными устройствами. Тупики, однако, могут иметь место и в других ситуациях. Hапример, в системах управления базами данных записи могут быть локализованы процессами, чтобы избежать состояния гонок (см. лекцию 5 "Алгоритмы синхронизации"). В этом случае может получиться так, что один из процессов заблокировал записи, необходимые другому процессу, и наоборот. Таким образом, тупики могут иметь место как на аппаратных, так и на программных ресурсах.
Тупики также могут быть вызваны ошибками программирования. Например, процесс может напрасно ждать открытия семафора, потому что в некорректно написанном приложении эту операцию забыли предусмотреть. Другой причиной бесконечного ожидания может быть дискриминационная политика по отношению к некоторым процессам. Однако чаще всего событие, которого ждет процесс в тупиковой ситуации, – освобождение ресурса, поэтому в дальнейшем будут рассмотрены методы борьбы с тупиками ресурсного типа.
Ресурсами могут быть как устройства, так и данные. Hекоторые ресурсы допускают разделение между процессами, то есть являются разделяемыми ресурсами. Например, память, процессор, диски коллективно используются процессами. Другие не допускают разделения, то есть являются выделенными, например лентопротяжное устройство. К взаимоблокировке может привести использование как выделенных, так и разделяемых ресурсов. Например, чтение с разделяемого диска может одновременно осуществляться несколькими процессами, тогда как запись предполагает исключительный доступ к данным на диске. Можно считать, что часть диска, куда происходит запись, выделена конкретному процессу. Поэтому в дальнейшем мы будем исходить из предположения, что тупики связаны с выделенными ресурсами , то есть тупики возникают, когда процессу предоставляется эксклюзивный доступ к устройствам, файлам и другим ресурсам.
Традиционная последовательность событий при работе с ресурсом состоит из запроса, использования и освобождения ресурса. Тип запроса зависит от природы ресурса и от ОС. Запрос может быть явным, например специальный вызов request, или неявным – open для открытия файла. Обычно, если ресурс занят и запрос отклонен, запрашивающий процесс переходит в состояние ожидания.
Далее в данной лекции будут рассматриваться вопросы обнаружения, предотвращения, обхода тупиков и восстановления после тупиков. Как правило, борьба с тупиками – очень дорогостоящее мероприятие. Тем не менее для ряда систем, например для систем реального времени, иного выхода нет.
Условия возникновения тупиков
Для образования тупика необходимым и достаточным является выполнение всех четырех условий. Обычно тупик моделируется циклом в графе, состоящем из узлов двух видов:…Основные направления борьбы с тупиками
Итак, основные направления борьбы с тупиками: Игнорирование проблемы в целом Предотвращение тупиков Обнаружение тупиков Восстановление …Игнорирование проблемы тупиков
Любая ОС, имеющая в ядре ряд массивов фиксированной размерности, потенциально страдает от тупиков, даже если они не обнаружены. Таблица открытых… Подход большинства популярных ОС (Unix, Windows и др.) состоит в том, чтобы…Способы предотвращения тупиков
Система, предоставляя ресурс в распоряжение процесса, должна принять решение, безопасно это или нет. Возникает вопрос: есть ли такой алгоритм,…Способы предотвращения тупиков путем тщательного распределения ресурсов. Алгоритм банкира
Суть алгоритма состоит в следующем. Предположим, что у системы в наличии n устройств, например лент. ОС принимает запрос от… Рассмотрим пример надежного состояния для системы с 3 пользователями и 11…Предотвращение тупиков за счет нарушения условий возникновения тупиков
В отсутствие информации о будущих запросах единственный способ избежать взаимоблокировки – добиться невыполнения хотя бы одного из условий раздела "Условия возникновения тупиков".
Нарушение условия взаимоисключения
К сожалению, не для всех устройств и не для всех данных можно организовать спулинг. Неприятным побочным следствием такой модели может быть…Нарушение условия ожидания дополнительных ресурсов
В известном смысле этот подход напоминает требование захвата всех ресурсов заранее. Естественно, что только специально организованные программы… Таким образом, один из способов – заставить все процессы затребовать нужные им… Данное решение применяется в пакетных мэйнфреймах (mainframe), которые требуют от пользователей перечислить все…Нарушение принципа отсутствия перераспределения
Во-первых, отбирать у процессов можно только те ресурсы, состояние которых легко сохранить, а позже восстановить, например состояние процессора.… Весь вопрос в цене подобного решения, которая может быть слишком высокой, если…Hарушение условия кругового ожидания
Один из способов – упорядочить ресурсы. Например, можно присвоить всем ресурсам уникальные номера и потребовать, чтобы процессы запрашивали ресурсы… Один из немногих примеров упорядочивания ресурсов – создание иерархии… Другой способ атаки условия кругового ожидания – действовать в соответствии с правилом, согласно которому каждый…Обнаружение тупиков
Рассмотрим модельную ситуацию. Процесс P1 ожидает ресурс R1. Процесс P2 удерживает ресурс R2 и ожидает ресурс R1. Процесс P3 … Вопрос состоит в том, является ли данная ситуация тупиковой, и если да, то…Восстановление после тупиков
Сложность восстановления обусловлена рядом факторов. В большинстве систем нет достаточно эффективных средств, чтобы приостановить процесс, … Самый простой и наиболее распространенный способ устранить тупик – завершить… По возможности лучше ликвидировать тот процесс, который может быть без ущерба возвращен к началу (такие процессы…Заключение
Возникновение тупиков является потенциальной проблемой любой операционной системы. Они возникают, когда имеется группа процессов, каждый из которых пытается получить исключительный доступ к некоторым ресурсам и претендует на ресурсы, принадлежащие другому процессу. В итоге все они оказываются в состоянии бесконечного ожидания.
С тупиками можно бороться, можно их обнаруживать, избегать и восстанавливать систему после тупиков. Однако цена подобных действий высока и соответствующие усилия должны предприниматься только в системах, где игнорирование тупиковых ситуаций приводит к катастрофическим последствиям.
Лекция: Организация памяти компьютера. Простейшие схемы управления памятью
В настоящей лекции рассматриваются простейшие способы управления памятью в ОС. Физическая память компьютера имеет иерархическую структуру. Программа представляет собой набор сегментов в логическом адресном пространстве. ОС осуществляет связывание логических и физических адресных пространств
Введение
Главная задача компьютерной системы – выполнять программы. Программы вместе с данными, к которым они имеют доступ, в процессе выполнения должны (по крайней мере частично) находиться в оперативной памяти. Операционной системе приходится решать задачу распределения памяти между пользовательскими процессами и компонентами ОС. Эта деятельность называется управлением памятью. Таким образом, память (storage, memory) является важнейшим ресурсом, требующим тщательного управления. В недавнем прошлом память была самым дорогим ресурсом.
Часть ОС, которая отвечает за управление памятью, называется менеджером памяти.
Физическая организация памяти компьютера
Основная память представляет собой упорядоченный массив однобайтовых ячеек, каждая из которых имеет свой уникальный адрес (номер). Процессор… Вторичную память (это главным образом диски) также можно рассматривать как… Эту схему можно дополнить еще несколькими промежуточными уровнями, как показано на рис. 8.1. Разновидности памяти…Локальность
Ключевую роль здесь играет свойство реальных программ, в течение ограниченного отрезка времени способных работать с небольшим набором адресов… Свойство локальности (соседние в пространстве и времени объекты… Кэш процессора обычно является частью аппаратуры, поэтому менеджер памяти ОС занимается распределением информации…Логическая память
Схема управления памятью, поддерживающая этот взгляд пользователя на то, как хранятся программы и данные, называется сегментацией. Сегмент – область… По-видимому, вначале сегменты памяти появились в связи с необходимостью…Связывание адресов
Связывание логического адреса, порожденного оператором программы, с физическим должно быть осуществлено до начала выполнения оператора или в момент… Рис. 8.3. Формирование логического адреса и связывание логического адреса с физическимФункции системы управления памятью
В следующих разделах лекции рассматривается ряд конкретных схем управления памятью. Каждая схема включает в себя определенную идеологию управления,…Простейшие схемы управления памятью
Схема с фиксированными разделами
Самым простым способом управления оперативной памятью является ее предварительное (обычно на этапе генерации или в момент загрузки системы) разбиение на несколько разделов фиксированной величины. Поступающие процессы помещаются в тот или иной раздел. При этом происходит условное разбиение физического адресного пространства. Связывание логических и физических адресов процесса происходит на этапе его загрузки в конкретный раздел, иногда – на этапе компиляции.
Каждый раздел может иметь свою очередь процессов, а может существовать и глобальная очередь для всех разделов(см. рис. 8.4).
Эта схема была реализована в IBM OS/360 (MFT), DEC RSX-11 и ряде других систем.
Подсистема управления памятью оценивает размер поступившего процесса, выбирает подходящий для него раздел, осуществляет загрузку процесса в этот раздел и настройку адресов.
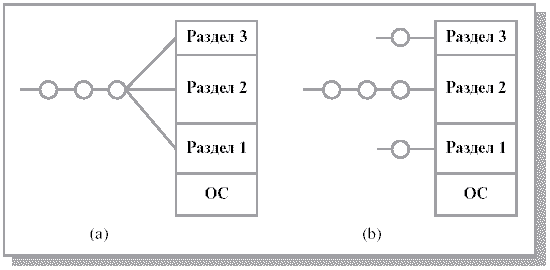
Рис. 8.4. Схема с фиксированными разделами: (a) – с общей очередью процессов, (b) – с отдельными очередями процессов
Очевидный недостаток этой схемы – число одновременно выполняемых процессов ограничено числом разделов.
Другим существенным недостатком является то, что предлагаемая схема сильно страдает от внутренней фрагментации – потери части памяти, выделенной процессу, но не используемой им. Фрагментация возникает потому, что процесс не полностью занимает выделенный ему раздел или потому, что некоторые разделы слишком малы для выполняемых пользовательских программ.
Один процесс в памяти
Защита адресного пространства ОС от пользовательской программы может быть организована при помощи одного граничного регистра, содержащего адрес…Оверлейная структура
Потребность в таком способе загрузки появляется, если логическое адресное пространство системы мало, например 1 Мбайт (MS-DOS) или даже всего 64… Рис. 8.5. Организация структуры с перекрытием. Можно поочередно загружать в память ветви A-B, A-C-D и A-C-E…Динамическое распределение. Свопинг
Выгруженный процесс может быть возвращен в то же самое адресное пространство или в другое. Это ограничение диктуется методом связывания. Для схемы… Свопинг не имеет непосредственного отношения к управлению памятью, скорее он…Схема с переменными разделами
В принципе, система свопинга может базироваться на фиксированных разделах. Более эффективной, однако, представляется схема динамического распределения или схема с переменными разделами, которая может использоваться и в тех случаях, когда все процессы целиком помещаются в памяти, то есть в отсутствие свопинга. В этом случае вначале вся память свободна и не разделена заранее на разделы. Вновь поступающей задаче выделяется строго необходимое количество памяти, не более. После выгрузки процесса память временно освобождается. По истечении некоторого времени память представляет собой переменное число разделов разного размера (рис. 8.6). Смежные свободные участки могут быть объединены.
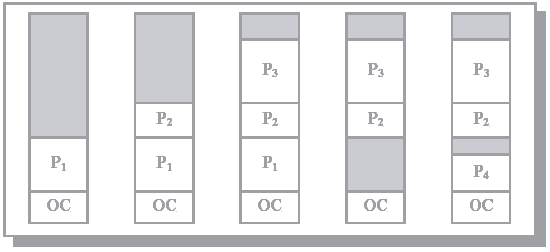
Рис. 8.6. Динамика распределения памяти между процессами (серым цветом показана неиспользуемая память)
В какой раздел помещать процесс? Наиболее распространены три стратегии.
- Стратегия первого подходящего (First fit). Процесс помещается в первый подходящий по размеру раздел.
- Стратегия наиболее подходящего (Best fit). Процесс помещается в тот раздел, где после его загрузки останется меньше всего свободного места.
- Стратегия наименее подходящего (Worst fit). При помещении в самый большой раздел в нем остается достаточно места для возможного размещения еще одного процесса.
Моделирование показало, что доля полезно используемой памяти в первых двух случаях больше, при этом первый способ несколько быстрее. Попутно заметим, что перечисленные стратегии широко применяются и другими компонентами ОС, например для размещения файлов на диске.
Типовой цикл работы менеджера памяти состоит в анализе запроса на выделение свободного участка (раздела), выборе его среди имеющихся в соответствии с одной из стратегий (первого подходящего, наиболее подходящего и наименее подходящего), загрузке процесса в выбранный раздел и последующих изменениях таблиц свободных и занятых областей. Аналогичная корректировка необходима и после завершения процесса. Связывание адресов может осуществляться на этапах загрузки и выполнения.
Этот метод более гибок по сравнению с методом фиксированных разделов, однако ему присуща внешняя фрагментация – наличие большого числа участков неиспользуемой памяти, не выделенной ни одному процессу. Выбор стратегии размещения процесса между первым подходящим и наиболее подходящим слабо влияет на величину фрагментации. Любопытно, что метод наиболее подходящего может оказаться наихудшим, так как он оставляет множество мелких незанятых блоков.
Статистический анализ показывает, что пропадает в среднем 1/3 памяти! Это известное правило 50% (два соседних свободных участка в отличие от двух соседних процессов могут быть объединены).
Одно из решений проблемы внешней фрагментации – организовать сжатие, то есть перемещение всех занятых (свободных) участков в сторону возрастания (убывания) адресов, так, чтобы вся свободная память образовала непрерывную область. Этот метод иногда называют схемой с перемещаемыми разделами. В идеале фрагментация после сжатия должна отсутствовать. Сжатие, однако, является дорогостоящей процедурой, алгоритм выбора оптимальной стратегии сжатия очень труден и, как правило, сжатие осуществляется в комбинации с выгрузкой и загрузкой по другим адресам.
Страничная память
В самом простом и наиболее распространенном случае страничной организации памяти (или paging) как логическое адресное пространство, так и физическое… Логический адрес в страничной системе – упорядоченная пара (p,d), где p –… Описываемая схема позволяет загрузить процесс, даже если нет непрерывной области кадров, достаточной для размещения…Сегментная и сегментно-страничная организация памяти
Программисты, пишущие на языках низкого уровня, должны иметь представление о сегментной организации, явным образом меняя значения сегментных… Каждый сегмент – линейная последовательность адресов, начинающаяся с 0.… Логический адрес – упорядоченная пара v=(s,d), номер сегмента и смещение внутри сегмента.Заключение
В настоящей лекции описаны простейшие способы управления памятью в ОС. Физическая память компьютера имеет иерархическую структуру. Программа представляет собой набор сегментов в логическом адресном пространстве. ОС осуществляет связывание логических и физических адресных пространств. В последующих лекциях будут рассматриваться современные решения, связанные с поддержкой виртуальной памяти.
Лекция: Виртуальная память. Архитектурные средства поддержки виртуальной памяти
Рассмотрены аппаратные особенности поддержки виртуальной памяти. Разбиение адресного пространства процесса на части и динамическая трансляция адреса… В этой и следующей лекциях речь пойдет о наиболее распространенной в настоящее время схеме управления памятью,…Понятие виртуальной памяти
Суть концепции виртуальной памяти заключается в следующем. Информация, с которой работает активный процесс, должна располагаться в оперативной… Таким образом, в наличии всех компонентов процесса в основной памяти… Возможность выполнения программы, находящейся в памяти лишь частично, имеет ряд вполне очевидных преимуществ. …Архитектурные средства поддержки виртуальной памяти
В самом распространенном случае необходимо отобразить большое виртуальное адресное пространство в физическое адресное пространство существенно…Страничная виртуальная память
После разбиения менеджером памяти виртуального адресного пространства на страницы виртуальный адрес преобразуется в упорядоченную пару (p,d), где p… Поскольку число виртуальных страниц велико, таблица страниц принимает… При отсутствии страницы в памяти в процессе выполнения команды возникает исключительная ситуация, называемая…Сегментно-страничная организации виртуальной памяти
На практике, однако, появления в системе большого количества таблиц страниц стараются избежать, организуя неперекрывающиеся сегменты в одном…Структура таблицы страниц
Итак, виртуальный адрес состоит из виртуального номера страницы и смещения. Номер записи в таблице страниц соответствует номеру виртуальной… Основную проблему для эффективной реализации таблицы страниц создают большие… Подсчитаем примерный размер таблицы страниц. В 32-битном адресном пространстве при размере страницы 4 Кбайт (Intel)…Ассоциативная память
В соответствии со свойством локальности большинство программ в течение некоторого промежутка времени обращаются к небольшому количеству страниц,… Естественное решение проблемы ускорения – снабдить компьютер аппаратным… Одна запись таблицы в ассоциативной памяти (один вход) содержит информацию об одной виртуальной странице: ее атрибуты…Инвертированная таблица страниц
Несмотря на многоуровневую организацию, хранение нескольких таблиц страниц большого размера по-прежнему представляют собой проблему. Ее значение особенно актуально для 64-разрядных архитектур, где число виртуальных страниц очень велико. Вариантом решения является применение инвертированной таблицы страниц (inverted page table). Этот подход применяется на машинах PowerPC, некоторых рабочих станциях Hewlett-Packard, IBM RT, IBM AS/400 и ряде других.
В этой таблице содержится по одной записи на каждый страничный кадр физической памяти. Существенно, что достаточно одной таблицы для всех процессов. Таким образом, для хранения функции отображения требуется фиксированная часть основной памяти, независимо от разрядности архитектуры, размера и количества процессов. Например, для компьютера Pentium c 256 Мбайт оперативной памяти нужна таблица размером 64 Кбайт строк.
Несмотря на экономию оперативной памяти, применение инвертированной таблицы имеет существенный минус – записи в ней (как и в ассоциативной памяти) не отсортированы по возрастанию номеров виртуальных страниц, что усложняет трансляцию адреса. Один из способов решения данной проблемы – использование хеш-таблицы виртуальных адресов. При этом часть виртуального адреса, представляющая собой номер страницы, отображается в хеш-таблицу с использованием функции хеширования. Каждой странице физической памяти здесь соответствует одна запись в хеш-таблице и инвертированной таблице страниц. Виртуальные адреса, имеющие одно значение хеш-функции, сцепляются друг с другом. Обычно длина цепочки не превышает двух записей.
Размер страницы
Чем больше размер страницы, тем меньше будет размер структур данных, обслуживающих преобразование адресов, но тем больше будут потери, связанные с… Как следует выбирать размер страницы? Во-первых, нужно учитывать размер… Как правило, размер страниц задается аппаратно, например в DEC PDP-11 – 8 Кбайт, в DEC VAX – 512 байт, в других…Заключение
В настоящей лекции рассмотрены аппаратные особенности поддержки виртуальной памяти. Разбиение адресного пространства процесса на части и динамическая трансляция адреса позволили выполнять процесс даже в отсутствие некоторых его компонентов в оперативной памяти. Подкачка недостающих компонентов с диска осуществляется операционной системой в тот момент, когда в них возникает необходимость. Следствием такой стратегии является возможность выполнения больших программ, размер которых может превышать размер оперативной памяти. Чтобы обеспечить данной схеме нужную производительность, отображение адресов осуществляется аппаратно при помощи многоуровневой таблицы страниц и ассоциативной памяти.
Лекция: Аппаратно-независимый уровень управления виртуальной памятью
Большинство ОС используют сегментно-страничную виртуальную память. Для обеспечения нужной производительности менеджер памяти ОС старается… В данной лекции рассмотрена аппаратно-независимая часть подсистемы управления виртуальной памятью,…Алгоритмы замещения страниц
Заметим, что при замещении приходится дважды передавать страницу между основной и вторичной памятью. Процесс замещения может быть оптимизирован за… Существует большое количество разнообразных алгоритмов замещения страниц. Все… Глобальные алгоритмы имеют ряд недостатков. Во-первых, они делают одни процессы чувствительными к поведению других…Алгоритм FIFO. Выталкивание первой пришедшей страницы
Аномалия Билэди (Belady) На первый взгляд кажется очевидным, что чем больше в памяти страничных кадров,… Система с тремя кадрами (9 faults) оказывается более производительной, чем с четырьмя кадрами (10 faults), для строки…Выталкивание дольше всего не использовавшейся страницы. Алгоритм LRU
Ключевое отличие между FIFO и оптимальным алгоритмом заключается в том, что один смотрит назад, а другой вперед. Если использовать прошлое для… Рис. 10.2. Пример работы алгоритма LRUВыталкивание редко используемой страницы. Алгоритм NFU
Программная реализация алгоритма, близкого к LRU, - алгоритм NFU(Not Frequently Used). Для него требуются программные счетчики, по одному на каждую страницу, которые… Таким образом, кандидатом на освобождение оказывается страница с наименьшим значением счетчика, как страница, к…Другие алгоритмы
Например, алгоритм Second-Chance - модификация алгоритма FIFO, которая позволяет избежать потери часто используемых страниц с помощью анализа флага… В компьютере Macintosh использован алгоритм NRU (Not Recently-Used), где… Имеется также и много других алгоритмов замещения. Объем этого курса не позволяет рассмотреть их подробно. Подробное…Управление количеством страниц, выделенных процессу. Модель рабочего множества
Итак, что делать, если в распоряжении процесса имеется недостаточное число кадров? Нужно ли его приостановить с освобождением всех кадров? Что… Трешинг (Thrashing) Хотя теоретически возможно уменьшить число кадров процесса до минимума, существует какое-то число активно используемых…Модель рабочего множества
Процессы начинают работать, не имея в памяти необходимых страниц. В результате при выполнении первой же машинной инструкции возникает page fault,… Таким образом, существует набор страниц (P1, P2, ... Pn), активно…Страничные демоны
Примером такого рода процесса может быть фоновый процесс - сборщик страниц, реализующий облегченный вариант алгоритма откачки, основанный на… Но если возникает требование страницы в условиях, когда список свободных… В ОС Windows 2000 аналогичную роль играет менеджер балансного набора (Working set manager), который вызывается раз в…Программная поддержка сегментной модели памяти процесса
Чаще всего виртуальная память процесса ОС разбивается на сегменты пяти типов: кода программы, данных, стека, разделяемый и сегмент файлов,… Сегмент программного кода содержит только команды. Сегмент программного кода… Сегмент данных, содержащий переменные программы и сегмент стека, содержащий автоматические переменные, могут…Отдельные аспекты функционирования менеджера памяти
Рассмотрим случай, когда система виртуальной памяти может вступить в конфликт с подсистемой ввода-вывода. Например, процесс может запросить ввод в… Второе решение - локализовать страницы в памяти, используя специальный бит… Другое использование бита локализации может иметь место и при нормальном замещении страниц. Рассмотрим следующую цепь…Заключение
Описанная система управления памятью является совокупностью программно-технических средств, обеспечивающих производительное функционирование современных компьютеров. Успех реализации той части ОС, которая относится к управлению виртуальной памятью, определяется близостью архитектуры аппаратных средств, поддерживающих виртуальную память, к абстрактной модели виртуальной памяти ОС. Справедливости ради заметим, что в подавляющем большинстве современных компьютеров аппаратура выполняет функции, существенно превышающие потребности модели ОС, так что создание аппаратно-зависимой части подсистемы управления виртуальной памятью ОС в большинстве случаев не является чрезмерно сложной задачей.
Лекция: Файлы с точки зрения пользователя
В настоящей лекции вводится понятие и рассматриваются основные функции и интерфейс файловой системы.
Введение
История систем управления данными во внешней памяти начинается еще с магнитных лент, но современный облик они приобрели с появлением магнитных дисков. До этого каждая прикладная программа сама решала проблемы именования данных и их структуризации во внешней памяти. Это затрудняло поддержание на внешнем носителе нескольких архивов долговременно хранящейся информации. Историческим шагом стал переход к использованию централизованных систем управления файлами. Система управления файлами берет на себя распределение внешней памяти, отображение имен файлов в адреса внешней памяти и обеспечение доступа к данным.
Файловая система - это часть операционной системы, назначение которой состоит в том, чтобы организовать эффективную работу с данными, хранящимися во внешней памяти, и обеспечить пользователю удобный интерфейс при работе с такими данными. Организовать хранение информации на магнитном диске непросто. Это требует, например, хорошего знания устройства контроллера диска, особенностей работы с его регистрами. Непосредственное взаимодействие с диском - прерогатива компонента системы ввода-вывода ОС, называемого драйвером диска. Для того чтобы избавить пользователя компьютера от сложностей взаимодействия с аппаратурой, была придумана ясная абстрактная модель файловой системы. Операции записи или чтения файла концептуально проще, чем низкоуровневые операции работы с устройствами.
Основная идея использования внешней памяти состоит в следующем. ОС делит память на блоки фиксированного размера, например, 4096 байт. Файл, обычно представляющий собой неструктурированную последовательность однобайтовых записей, хранится в виде последовательности блоков (не обязательно смежных); каждый блок хранит целое число записей. В некоторых ОС (MS-DOS) адреса блоков, содержащих данные файла, могут быть организованы в связный список и вынесены в отдельную таблицу в памяти. В других ОС (Unix) адреса блоков данных файла хранятся в отдельном блоке внешней памяти (так называемом индексе или индексном узле). Этот прием, называемый индексацией, является наиболее распространенным для приложений, требующих произвольного доступа к записям файлов. Индекс файла состоит из списка элементов, каждый из которых содержит номер блока в файле и сведения о местоположении данного блока. Считывание очередного байта осуществляется с так называемой текущей позиции, которая характеризуется смещением от начала файла. Зная размер блока, легко вычислить номер блока, содержащего текущую позицию. Адрес же нужного блока диска можно затем извлечь из индекса файла. Базовой операцией, выполняемой по отношению к файлу, является чтение блока с диска и перенос его в буфер, находящийся в основной памяти.
Файловая система позволяет при помощи системы справочников (каталогов, директорий) связать уникальное имя файла с блоками вторичной памяти, содержащими данные файла. Иерархическая структура каталогов, используемая для управления файлами, может служить другим примером индексной структуры. В этом случае каталоги или папки играют роль индексов, каждый из которых содержит ссылки на свои подкаталоги. С этой точки зрения вся файловая система компьютера представляет собой большой индексированный файл. Помимо собственно файлов и структур данных, используемых для управления файлами (каталоги, дескрипторы файлов, различные таблицы распределения внешней памяти), понятие "файловая система" включает программные средства, реализующие различные операции над файлами.
Перечислим основные функции файловой системы.
- Идентификация файлов. Связывание имени файла с выделенным ему пространством внешней памяти.
- Распределение внешней памяти между файлами. Для работы с конкретным файлом пользователю не требуется иметь информацию о местоположении этого файла на внешнем носителе информации. Например, для того чтобы загрузить документ в редактор с жесткого диска, нам не нужно знать, на какой стороне какого магнитного диска, на каком цилиндре и в каком секторе находится данный документ.
- Обеспечение надежности и отказоустойчивости. Стоимость информации может во много раз превышать стоимость компьютера.
- Обеспечение защиты от несанкционированного доступа.
- Обеспечение совместного доступа к файлам, так чтобы пользователю не приходилось прилагать специальных усилий по обеспечению синхронизации доступа.
- Обеспечение высокой производительности.
Иногда говорят, что файл - это поименованный набор связанной информации, записанной во вторичную память. Для большинства пользователей файловая система - наиболее видимая часть ОС. Она предоставляет механизм для онлайнового хранения и доступа как к данным, так и к программам для всех пользователей системы. С точки зрения пользователя, файл - единица внешней памяти, то есть данные, записанные на диск, должны быть в составе какого-нибудь файла.
Важный аспект организации файловой системы - учет стоимости операций взаимодействия с вторичной памятью. Процесс считывания блока диска состоит из позиционирования считывающей головки над дорожкой, содержащей требуемый блок, ожидания, пока требуемый блок сделает оборот и окажется под головкой, и собственно считывания блока. Для этого требуется значительное время (десятки миллисекунд). В современных компьютерах обращение к диску осуществляется примерно в 100 000 раз медленнее, чем обращение к оперативной памяти. Таким образом, критерием вычислительной сложности алгоритмов, работающих с внешней памятью, является количество обращений к диску.
В данной лекции рассматриваются вопросы структуры, именования, защиты файлов; операции, которые разрешается производить над файлами; организация файлового архива (полного дерева справочников). Проблемы выделения дискового пространства, обеспечения производительной работы файловой системы и ряд других вопросов, интересующих разработчиков системы, вы найдете в следующей лекции.
Общие сведения о файлах
Имена файлов
Правила именования файлов зависят от ОС. Многие ОС поддерживают имена из двух частей (имя+расширение), например progr.c (файл, содержащий текст…Типы файлов
Основные типы файлов: регулярные (обычные) файлы и директории (справочники, каталоги). Обычные файлы содержат пользовательскую информацию.… Напомним, что хотя внутри подсистемы управления файлами обычный файл… Далее речь пойдет главным образом об обычных файлах.Атрибуты файлов
Список атрибутов обычно хранится в структуре директорий (см. следующую лекцию) или других структурах, обеспечивающих доступ к данным файла.Организация файлов и доступ к ним
ОС поддерживают несколько вариантов структуризации файлов.Последовательный файл
Обработка подобных файлов предполагает последовательное чтение записей от начала файла, причем конкретная запись определяется ее положением в файле.…Файл прямого доступа
Здесь имеется в виду относительный номер, специфицирующий данный блок среди блоков диска, принадлежащих файлу. О связи относительного номера блока с… Естественно, что в этом случае для доступа к середине файла просмотр всего… Таким образом, файл, состоящий из однобайтовых записей на устройстве прямого доступа, - наиболее распространенный…Другие формы организации файлов
Первый шаг в структурировании - хранение файла в виде последовательности записей фиксированной длины, каждая из которых имеет внутреннюю структуру.… Другой способ представления файлов - последовательность записей переменной…Операции над файлами
Операционная система должна предоставить в распоряжение пользователя набор операций для работы с файлами, реализованных через системные вызовы. Чаще всего при работе с файлом пользователь выполняет не одну, а несколько операций. Во-первых, нужно найти данные файла и его атрибуты по символьному имени, во-вторых, считать необходимые атрибуты файла в отведенную область оперативной памяти и проанализировать права пользователя на выполнение требуемой операции. Затем следует выполнить операцию, после чего освободить занимаемую данными файла область памяти. Рассмотрим в качестве примера основные файловые операции ОС Unix [Таненбаум, 2002].
- Создание файла, не содержащего данных. Смысл данного вызова - объявить, что файл существует, и присвоить ему ряд атрибутов. При этом выделяется место для файла на диске и вносится запись в каталог.
- Удаление файла и освобождение занимаемого им дискового пространства.
- Открытие файла. Перед использованием файла процесс должен его открыть. Цель данного системного вызова - разрешить системе проанализировать атрибуты файла и проверить права доступа к нему, а также считать в оперативную память список адресов блоков файла для быстрого доступа к его данным. Открытие файла является процедурой создания дескриптора или управляющего блока файла. Дескриптор (описатель) файла хранит всю информацию о нем. Иногда, в соответствии с парадигмой, принятой в языках программирования, под дескриптором понимается альтернативное имя файла или указатель на описание файла в таблице открытых файлов, используемый при последующей работе с файлом . Например, на языке Cи операция открытия файла fd=open(pathname,flags,modes); возвращает дескриптор fd, который может быть задействован при выполнении операций чтения (read(fd,buffer,count); ) или записи.
- Закрытие файла. Если работа с файлом завершена, его атрибуты и адреса блоков на диске больше не нужны. В этом случае файл нужно закрыть, чтобы освободить место во внутренних таблицах файловой системы.
- Позиционирование. Дает возможность специфицировать место внутри файла, откуда будет производиться считывание (или запись) данных, то есть задать текущую позицию.
- Чтение данных из файла. Обычно это делается с текущей позиции. Пользователь должен задать объем считываемых данных и предоставить для них буфер в оперативной памяти.
- Запись данных в файл с текущей позиции. Если текущая позиция находится в конце файла, его размер увеличивается, в противном случае запись осуществляется на место имеющихся данных, которые, таким образом, теряются.
Есть и другие операции, например переименование файла, получение атрибутов файла и т. д.
Существует два способа выполнить последовательность действий над файлами [Олифер, 2001].
В первом случае для каждой операции выполняются как универсальные, так и уникальные действия (схема stateless). Например, последовательность операций может быть такой: open, read1, close, ... open, read2, close, ... open, read3, close.
Альтернативный способ - это когда универсальные действия выполняются в начале и в конце последовательности операций, а для каждой промежуточной операции выполняются только уникальные действия. В этом случае последовательность вышеприведенных операций будет выглядеть так: open, read1, ... read2, ... read3, close.
Большинство ОС использует второй способ, более экономичный и быстрый. Первый способ более устойчив к сбоям, поскольку результаты каждой операции становятся независимыми от результатов предыдущей операции; поэтому он иногда применяется в распределенных файловых системах (например, Sun NFS).
Директории. Логическая структура файлового архива
Каждый каталог содержит список каталогов и/или файлов, содержащихся в данном каталоге. Каталоги имеют один и тот же внутренний формат, где каждому… Число директорий зависит от системы. В ранних ОС имелась только одна корневая…Разделы диска. Организация доступа к архиву файлов.
Задание пути к файлу в файловых системах некоторых ОС отличается тем, с чего начинается эта цепочка имен.
В современных ОС принято разбивать диски на логические диски (это низкоуровневая операция), иногда называемые разделами (partitions). Бывает, что, наоборот, объединяют несколько физических дисков в один логический диск (например, это можно сделать в ОС Windows NT). Поэтому в дальнейшем изложении мы будем игнорировать проблему физического выделения пространства для файлов и считать, что каждый раздел представляет собой отдельный (виртуальный) диск. Диск содержит иерархическую древовидную структуру, состоящую из набора файлов, каждый из которых является хранилищем данных пользователя, и каталогов или директорий (то есть файлов, которые содержат перечень других файлов, входящих в состав каталога), необходимых для хранения информации о файлах системы.
В некоторых системах управления файлами требуется, чтобы каждый архив файлов целиком располагался на одном диске (разделе диска). В этом случае полное имя файла начинается с имени дискового устройства, на котором установлен соответствующий диск (буквы диска). Например, c:utilnundd.exe. Такой способ именования используется в файловых системах DEC и Microsoft.
В других системах (Multics) вся совокупность файлов и каталогов представляет собой единое дерево. Сама система, выполняя поиск файлов по имени, начиная с корня, требовала установки необходимых дисков.
В ОС Unix предполагается наличие нескольких архивов файлов, каждый на своем разделе, один из которых считается корневым. После запуска системы можно "смонтировать" корневую файловую систему и ряд изолированных файловых систем в одну общую файловую систему.
Технически это осуществляется с помощью создания в корневой файловой системе специальных пустых каталогов (см. также следующую лекцию). Специальный системный вызов mount ОС Unix позволяет подключить к одному из этих пустых каталогов корневой каталог указанного архива файлов. После монтирования общей файловой системы именование файлов производится так же, как если бы она с самого начала была централизованной. Задачей ОС является беспрепятственный проход точки монтирования при получении доступа к файлу по цепочке имен. Если учесть, что обычно монтирование файловой системы производится при загрузке системы, пользователи ОС Unix обычно и не задумываются о происхождении общей файловой системы.
Операции над директориями
Как и в случае с файлами, система обязана обеспечить пользователя набором операций, необходимых для работы с директориями, реализованных через системные вызовы. Несмотря на то что директории - это файлы, логика работы с ними отличается от логики работы с обычными файлами и определяется природой этих объектов, предназначенных для поддержки структуры файлового архива. Совокупность системных вызовов для управления директориями зависит от особенностей конкретной ОС. Напомним, что операции над каталогами являются прерогативой ОС, то есть пользователь не может, например, выполнить запись в каталог начиная с текущей позиции. Рассмотрим в качестве примера некоторые системные вызовы, необходимые для работы с каталогами [Таненбаум, 2002].
- Создание директории. Вновь созданная директория включает записи с именами '.' и '..', однако считается пустой.
- Удаление директории. Удалена может быть только пустая директория.
- Открытие директории для последующего чтения. Hапример, чтобы перечислить файлы, входящие в директорию, процесс должен открыть директорию и считать имена всех файлов, которые она включает.
- Закрытие директории после ее чтения для освобождения места во внутренних системных таблицах.
- Поиск. Данный системный вызов возвращает содержимое текущей записи в открытой директории. Вообще говоря, для этих целей может использоваться системный вызов Read, но в этом случае от программиста потребуется знание внутренней структуры директории.
- Получение списка файлов в каталоге.
- Переименование. Имена директорий можно менять, как и имена файлов.
- Создание файла. При создании нового файла необходимо добавить в каталог соответствующий элемент.
- Удаление файла. Удаление из каталога соответствующего элемента. Если удаляемый файл присутствует только в одной директории, то он вообще удаляется из файловой системы, в противном случае система ограничивается только удалением специфицируемой записи.
Очевидно, что создание и удаление файлов предполагает также выполнение соответствующих файловых операций. Имеется еще ряд других системных вызовов, например связанных с защитой информации.
Защита файлов
Общие проблемы безопасности ОС рассмотрены в лекциях 15-16. Информация в компьютерной системе должна быть защищена как от физического разрушения (reliability), так и от несанкционированного доступа (protection).
Здесь мы коснемся отдельных аспектов защиты, связанных с контролем доступа к файлам.
Контроль доступа к файлам
Списки прав доступа
Для решения этих проблем создают классификации пользователей, например, в ОС Unix все пользователи разделены на три группы. Владелец (Owner). … Это позволяет реализовать конденсированную версию списка прав доступа. В…Заключение
Итак, файловая система представляет собой набор файлов, директорий и операций над ними. Имена, структуры файлов, способы доступа к ним и их атрибуты - важные аспекты организации файловой системы. Обычно файл представляет собой неструктурированную последовательность байтов. Главная задача файловой системы - связать символьное имя файла с данными на диске. Большинство современных ОС поддерживает иерархическую систему каталогов или директорий с возможным вложением директорий. Безопасность файловой системы, базирующаяся на ведении списков прав доступа, - одна из важнейших концепций ОС.
Лекция: Реализация файловой системы
Реализация файловой системы связана с такими вопросами, как поддержка понятия…Общая структура файловой системы
Нижний уровень - оборудование. Это в первую очередь магнитные диски с подвижными головками - основные устройства внешней памяти, представляющие… Непосредственно с устройствами (дисками) взаимодействует часть ОС, называемая… В структуре системы управления файлами можно выделить базисную подсистему, которая отвечает за выделение дискового…Управление внешней памятью
Прежде чем описывать структуру данных файловой системы на диске, необходимо рассмотреть алгоритмы выделения дискового пространства и способы учета свободной и занятой дисковой памяти. Эти задачи связаны между собой.
Методы выделения дискового пространства
Ключевым, безусловно, является вопрос, какой тип структур используется для учета отдельных блоков файла, то есть способ связывания файлов с блоками диска. В ОС используется несколько методов выделения файлу дискового пространства. Для каждого из методов запись в директории, соответствующая символьному имени файла, содержит указатель, следуя которому можно найти все блоки данного файла.
Выделение непрерывной последовательностью блоков
Эта схема имеет два преимущества. Во-первых, ее легко реализовать, так как выяснение местонахождения файла сводится к вопросу, где находится первый… Непрерывное выделение используется в ОС IBM/CMS, в ОС RSX-11 (для выполняемых… Этот способ распространен мало, и вот почему. В процессе эксплуатации диск представляет собой некоторую совокупность…Связный список
Рис. 12.2. Хранение файла в виде связного списка дисковых блоков Внешняя фрагментация для данного метода отсутствует. Любой свободный блок может быть использован для удовлетворения…Таблица отображения файлов
Одним из вариантов предыдущего способа является хранение указателей не в дисковых блоках, а в индексной таблице в памяти, которая называется таблицей отображения файлов (FAT - file allocation table) (см. рис. 12.3). Этой схемы придерживаются многие ОС (MS-DOS, OS/2, MS Windows и др.)
По-прежнему существенно, что запись в директории содержит только ссылку на первый блок. Далее при помощи таблицы FAT можно локализовать блоки файла независимо от его размера. В тех строках таблицы, которые соответствуют последним блокам файлов, обычно записывается некоторое граничное значение, например EOF.
Главное достоинство данного подхода состоит в том, что по таблице отображения можно судить о физическом соседстве блоков, располагающихся на диске, и при выделении нового блока можно легко найти свободный блок диска, находящийся поблизости от других блоков данного файла. Минусом данной схемы может быть необходимость хранения в памяти этой довольно большой таблицы.
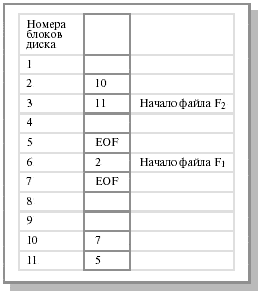
Рис. 12.3. Метод связного списка с использованием таблицы в оперативной памяти
Индексные узлы
Индексирование поддерживает прямой доступ к файлу, без ущерба от внешней фрагментации. Индексированное размещение широко распространено и… Обычно применяется комбинация одноуровневого и многоуровневых индексов. Первые…Управление свободным и занятым дисковым пространством
Дисковое пространство, не выделенное ни одному файлу, также должно быть управляемым. В современных ОС используется несколько способов учета используемого места на диске. Рассмотрим наиболее распространенные.
Учет при помощи организации битового вектора
Главное преимущество этого подхода состоит в том, что он относительно прост и эффективен при нахождении первого свободного блока или n… Описываемый метод учета свободных блоков используется в Apple Macintosh. Несмотря на то что размер описанного битового вектора наименьший из всех возможных структур, даже такой вектор может…Учет при помощи организации связного списка
Подобная схема не всегда эффективна. Для трассирования списка нужно выполнить много обращений к диску. Однако, к счастью, нам необходим, как… Иногда прибегают к модификации подхода связного списка, организуя хранение… Существуют и другие методы, например, свободное пространство можно рассматривать как файл и вести для него…Размер блока
Для систем со страничной организацией памяти характерна сходная проблема с размером страницы. Проведенные исследования показали, что большинство файлов имеют небольшой… Можно также учесть, что в системах с виртуальной памятью желательно, чтобы единицей пересылки диск-память была…Структура файловой системы на диске
Рис. 12.5. Примерная структура файловой системы на диске В начале раздела находится суперблок, содержащий общее описание файловой системы, например: тип файловой …Реализация директорий
Для доступа к файлу ОС использует путь (pathname), сообщенный пользователем. Запись в директории связывает имя файла или имя поддиректории с блоками… Рис. 12.6. Реализация директорийПримеры реализации директорий в некоторых ОС
Директории в ОС MS-DOS
Рис. 12.7. Вариант записи в директории MS-DOS В ОС MS-DOS, как и в большинстве современных ОС, директории могут содержать поддиректории (специфицируемые битом…Директории в ОС Unix
Рис. 12.8. Вариант записи в директории Unix В более поздних версиях Unix форма записи претерпела ряд изменений, например имя файла описывается структурой. Однако…Поиск в директории
Список файлов в директории обычно не является упорядоченным по именам файлов. Поэтому правильный выбор алгоритма поиска имени файла в директории имеет большое влияние на эффективность и надежность файловых систем.
Линейный поиск
Метод прост, но требует временных затрат. Для создания нового файла вначале нужно проверить директорию на наличие такого же имени. Затем имя нового… Реальный недостаток данного метода - последовательный поиск файла. Информация…Хеш-таблица
Хеширование (см. например, [Ахо, 2001]) - другой способ, который может использоваться для размещения и последующего поиска имени файла в директории. В данном методе имена файлов также хранятся в каталоге в виде линейного списка, но дополнительно используется хеш-таблица. Хеш-таблица, точнее построенная на ее основе хеш-функция, позволяет по имени файла получить указатель на имя файла в списке. Таким образом, можно существенно уменьшить время поиска.
В результате хеширования могут возникать коллизии, то есть ситуации, когда функция хеширования, примененная к разным именам файлов, дает один и тот же результат. Обычно имена таких файлов объединяют в связные списки, предполагая в дальнейшем осуществление в них последовательного поиска нужного имени файла. Выбор подходящего алгоритма хеширования позволяет свести к минимуму число коллизий. Однако всегда есть вероятность неблагоприятного исхода, когда непропорционально большому числу имен файлов функция хеширования ставит в соответствие один и тот же результат. В таком случае преимущество использования этой схемы по сравнению с последовательным поиском практически утрачивается.
Другие методы поиска
Помимо описанных методов поиска имени файла, в директории существуют и другие. В качестве примера можно привести организацию поиска в каталогах файловой системы NTFS при помощи так называемого B-дерева, которое стало стандартным способом организации индексов в системах баз данных (см. [Ахо, 2001]).
Монтирование файловых систем
Функция mount (монтировать) связывает файловую систему из указанного раздела на диске с существующей иерархией файловых систем, а функция umount… Процедура монтирования состоит в следующем. Пользователь (в Unix это… mount(special pathname,directory pathname,options);Связывание файлов
Ядро позволяет пользователю связывать каталоги, упрощая написание программ, требующих пересечения дерева файловой системы (см. рис. 12.11). Часто… Это удобно, но создает ряд дополнительных проблем. Простейший способ реализовать связывание файла - просто дублировать информацию о нем в обеих директориях. При этом,…Кооперация процессов при работе с файлами
Разделяемый файл - разделяемый ресурс. Как и в случае любого совместно используемого ресурса, процессы должны синхронизировать доступ к совместно… Например, если несколько пользователей одновременно редактируют какой-либо… Рассмотрим вначале грубый подход, то есть временный захват пользовательским процессом файла или записи (части файла…Примеры разрешения коллизий и тупиковых ситуаций
Логика работы системы в сложных ситуациях может проиллюстрировать особенности организации мультидоступа.
Рассмотрим в качестве примера образование потенциального тупика при создании связи (link), когда разрешен совместный доступ к файлу [Bach, 1986].
Два процесса, выполняющие одновременно следующие функции:
процесс A: link("a/b/c/d","e/f/g");
процесс B: link("e/f","a/b/c/d/ee");
могут зайти в тупик. Предположим, что процесс A обнаружил индекс файла "a/b/c/d" в тот самый момент, когда процесс B обнаружил индекс файла "e/f". Фраза "в тот же самый момент" означает, что системой достигнуто состояние, при котором каждый процесс получил искомый индекс. Когда же теперь процесс A попытается получить индекс файла "e/f", он приостановит свое выполнение до тех пор, пока индекс файла "f" не освободится. В то же время процесс B пытается получить индекс каталога "a/b/c/d" и приостанавливается в ожидании освобождения индекса файла "d". Процесс A будет удерживать заблокированным индекс, нужный процессу B, а процесс B, в свою очередь, будет удерживать заблокированным индекс, необходимый процессу A.
Для предотвращения этого классического примера взаимной блокировки в файловой системе принято, чтобы ядро освобождало индекс исходного файла после увеличения значения счетчика связей. Тогда, поскольку первый из ресурсов (индекс) свободен при обращении к следующему ресурсу, взаимной блокировки не происходит.
Поводов для нежелательной конкуренции между процессами много, особенно при удалении имен каталогов. Предположим, что один процесс пытается найти данные файла по его полному символическому имени, последовательно проходя компонент за компонентом, а другой процесс удаляет каталог, имя которого входит в путь поиска. Допустим, процесс A делает разбор имени "a/b/c/d" и приостанавливается во время получения индексного узла для файла "c". Он может приостановиться при попытке заблокировать индексный узел или при попытке обратиться к дисковому блоку, где этот индексный узел хранится. Если процессу B нужно удалить связь для каталога с именем "c", он может приостановиться по той же самой причине, что и процесс A. Пусть ядро впоследствии решит возобновить процесс B раньше процесса A. Прежде чем процесс A продолжит свое выполнение, процесс B завершится, удалив связь каталога "c" и его содержимое по этой связи. Позднее процесс A попытается обратиться к несуществующему индексному узлу, который уже был удален. Алгоритм поиска файла, проверяющий в первую очередь неравенство значения счетчика связей> нулю, должен сообщить об ошибке.
Можно привести и другие примеры, которые демонстрируют необходимость тщательного проектирования файловой системы для ее последующей надежной работы.
Hадежность файловой системы
Жизнь полна неприятных неожиданностей, а разрушение файловой системы зачастую более опасно, чем разрушение компьютера. Поэтому файловые системы должны разрабатываться с учетом подобной возможности. Помимо очевидных решений, например своевременное дублирование информации (backup), файловые системы современных ОС содержат специальные средства для поддержки собственной совместимости.
Целостность файловой системы
И если вследствие непредсказуемой остановки системы на диске будут сохранены изменения только для части этих объектов (нарушена атомарность файловой… В современных ОС предусмотрены меры, которые позволяют свести к минимуму ущерб…Порядок выполнения операций
Рассмотрим пример создания жесткой связи для файла [Робачевский, 1999]. Для этого файловой системе необходимо выполнить следующие операции: … Если аварийный останов произошел между 1-й и 2-й операциями, то в каталогах…Журнализация
Для отката необходимо, чтобы для каждой протоколируемой в журнале операции существовала обратная. Например, для каталогов и реляционных СУБД это… Журнализация реализована в NTFS, Ext3FS, ReiserFS и других системах. Чтобы…Проверка целостности файловой системы при помощи утилит
Возможны также эвристические проверки. Hапример, нахождение индексного узла, номер которого превышает их число на диске или поиск в пользовательских… К сожалению, приходится констатировать, что не существует никаких средств,…Управление "плохими" блоками
Первый способ - хранить список плохих блоков в контроллере диска. Когда контроллер инициализируется, он читает плохие блоки и замещает дефектный… Решение на уровне ОС может быть следующим. Прежде всего, необходимо тщательно…Производительность файловой системы
Поскольку обращение к диску - операция относительно медленная, минимизация количества таких обращений - ключевая задача всех алгоритмов, работающих с внешней памятью. Наиболее типичная техника повышения скорости работы с диском - кэширование.
Кэширование
Аккуратная реализация кэширования требует решения нескольких проблем. Во-первых, емкость буфера кэша ограничена. Когда блок должен быть загружен в…Оптимальное размещение информации на диске
Кроме того, рекомендуется периодически осуществлять дефрагментацию диска (сборку мусора), поскольку в популярных методиках выделения дисковых блоков…Реализация некоторых операций над файлами
В предыдущей лекции перечислены основные операции над файлами. В данном разделе будет описан порядок работы некоторых системных вызовов для работы с файловой системой, следуя главным образом [Bach, 1986], с учетом совокупности введенных в данной лекции понятий.
Системные вызовы, работающие с символическим именем файла
Системные вызовы, связывающие pathname с дескриптором файла
fd = creat(pathname,modes); fd = open(pathname,flags,modes); Другие операции над файлами, такие как чтение, запись, позиционирование головок чтения-записи, воспроизведение…Связывание файла
link(source file name, target file name); где source file name - существующее имя файла, а target file name - новое… Сначала ОС определяет местонахождение индекса исходного файла и увеличивает значение счетчика связей в индексном узле.…Удаление файла
unlink(pathname); Если удаляемое имя является последней связью файла с каким-либо каталогом,… Для того чтобы забрать дисковые блоки, ядро в цикле просматривает таблицу содержимого индексного узла, освобождая все…Системные вызовы, работающие с файловым дескриптором
Открытый файл может использоваться для чтения и записи последовательностей байтов. Для этого поддерживаются два системных вызова read и write, работающие с файловым дескриптором (или handle в терминологии Microsoft), полученным при ранее выполненных системных вызовах open или creat.
Функции ввода-вывода из файла
number = read(fd,buffer,count); где fd - дескриптор файла, возвращаемый функцией open, buffer - адрес… Синтаксис вызова системной функции write (писать):Современные архитектуры файловых систем
На верхнем уровне располагается так называемый диспетчер файловых систем (например, в Windows 95 этот компонент называется installable filesystem… Каждая файловая система (иногда говорят - драйвер файловой системы) на этапе… Та же идея поддержки нескольких файловых систем в рамках одной ОС может быть реализована по-другому, например исходя…Заключение
Реализация файловой системы связана с такими вопросами, как поддержка понятия логического блока диска, связывания имени файла и блоков его данных, проблемами разделения файлов и проблемами управления дискового пространства.
Наиболее распространенные способы выделения дискового пространства: непрерывное выделение, организация связного списка и система с индексными узлами.
Файловая система часто реализуется в виде слоеной модульной структуры. Нижние слои имеют дело с оборудованием, а верхние - с символическими именами и логическими свойствами файлов.
Директории могут быть организованы различными способами и могут хранить атрибуты файла и адреса блоков файлов, а иногда для этого предназначается специальная структура (индексные узлы).
Проблемы надежности и производительности файловой системы - важнейшие аспекты ее дизайна.
Лекция: Система управления вводом-выводом
В лекции рассматриваются основные физические и логические принципы организации ввода-вывода в вычислительных системах.Физические принципы организации ввода-вывода
Общие сведения об архитектуре компьютера
В простейшем случае процессор, память и многочисленные внешние устройства связаны большим количеством электрических соединений – линий, которые в совокупности принято называть локальной магистралью компьютера. Внутри локальной магистрали линии, служащие для передачи сходных сигналов и предназначенные для выполнения сходных функций, принято группировать в шины. При этом понятие шины включает в себя не только набор проводников, но и набор жестко заданных протоколов, определяющий перечень сообщений, который может быть передан с помощью электрических сигналов по этим проводникам. В современных компьютерах выделяют как минимум три шины:
- шину данных, состоящую из линий данных и служащую для передачи информации между процессором и памятью, процессором и устройствами ввода-вывода, памятью и внешними устройствами;
- адресную шину, состоящую из линий адреса и служащую для задания адреса ячейки памяти или указания устройства ввода-вывода, участвующих в обмене информацией;
- шину управления, состоящую из линий управления локальной магистралью и линий ее состояния, определяющих поведение локальной магистрали. В некоторых архитектурных решениях линии состояния выносятся из этой шины в отдельную шину состояния.
Количество линий, входящих в состав шины, принято называть разрядностью (шириной) этой шины. Ширина адресной шины, например, определяет максимальный размер оперативной памяти, которая может быть установлена в вычислительной системе. Ширина шины данных определяет максимальный объем информации, которая за один раз может быть получена или передана по этой шине.
Операции обмена информацией осуществляются при одновременном участии всех шин. Рассмотрим, к примеру, действия, которые должны быть выполнены для передачи информации из процессора в память. В простейшем случае необходимо выполнить три действия.
- На адресной шине процессор должен выставить сигналы, соответствующие адресу ячейки памяти, в которую будет осуществляться передача информации.
- На шину данных процессор должен выставить сигналы, соответствующие информации, которая должна быть записана в память.
- После выполнения действий 1 и 2 на шину управления выставляются сигналы, соответствующие операции записи и работе с памятью, что приведет к занесению необходимой информации по нужному адресу.
Естественно, что приведенные выше действия являются необходимыми, но недостаточными при рассмотрении работы конкретных процессоров и микросхем памяти. Конкретные архитектурные решения могут требовать дополнительных действий: например, выставления на шину управления сигналов частичного использования шины данных (для передачи меньшего количества информации, чем позволяет ширина этой шины); выставления сигнала готовности магистрали после завершения записи в память, разрешающего приступить к новой операции, и т. д. Однако общие принципы выполнения операции записи в память остаются неизменными.
В то время как память легко можно представить себе в виде последовательности пронумерованных адресами ячеек, локализованных внутри одной микросхемы или набора микросхем, к устройствам ввода-вывода подобный подход неприменим. Внешние устройства разнесены пространственно и могут подключаться к локальной магистрали в одной точке или множестве точек, получивших название портов ввода-вывода. Тем не менее, точно так же, как ячейки памяти взаимно однозначно отображались в адресное пространство памяти, порты ввода-вывода можно взаимно однозначно отобразить в другое адресное пространство – адресное пространство ввода-вывода. При этом каждый порт ввода-вывода получает свой номер или адрес в этом пространстве. В некоторых случаях, когда адресное пространство памяти (размер которого определяется шириной адресной шины) задействовано не полностью (остались адреса, которым не соответствуют физические ячейки памяти) и протоколы работы с внешним устройством совместимы с протоколами работы с памятью, часть портов ввода -вывода может быть отображена непосредственно в адресное пространство памяти (так, например, поступают с видеопамятью дисплеев), правда, тогда эти порты уже не принято называть портами. Надо отметить, что при отображении портов в адресное пространство памяти для организации доступа к ним в полной мере могут быть задействованы существующие механизмы защиты памяти без организации специальных защитных устройств.
В ситуации прямого отображения портов ввода-вывода в адресное пространство памяти действия, необходимые для записи информации и управляющих команд в эти порты или для чтения данных из них и их состояний, ничем не отличаются от действий, производимых для передачи информации между оперативной памятью и процессором, и для их выполнения применяются те же самые команды. Если же порт отображен в адресное пространство ввода-вывода, то процесс обмена информацией инициируется специальными командами ввода-вывода и включает в себя несколько другие действия. Например, для передачи данных в порт необходимо выполнить следующее.
- На адресной шине процессор должен выставить сигналы, соответствующие адресу порта, в который будет осуществляться передача информации, в адресном пространстве ввода-вывода.
- На шину данных процессор должен выставить сигналы, соответствующие информации, которая должна быть передана в порт.
- После выполнения действий 1 и 2 на шину управления выставляются сигналы, соответствующие операции записи и работе с устройствами ввода-вывода (переключение адресных пространств!), что приведет к передаче необходимой информации в нужный порт.
Существенное отличие памяти от устройств ввода-вывода заключается в том, что занесение информации в память является окончанием операции записи, в то время как занесение информации в порт зачастую представляет собой инициализацию реального совершения операции ввода-вывода. Что именно должны делать устройства, приняв информацию через свой порт, и каким именно образом они должны поставлять информацию для чтения из порта, определяется электронными схемами устройств, получившими название контроллеров. Контроллер может непосредственно управлять отдельным устройством (например, контроллер диска), а может управлять несколькими устройствами, связываясь с их контроллерами посредством специальных шин ввода-вывода (шина IDE, шина SCSI и т. д.).
Современные вычислительные системы могут иметь разнообразную архитектуру, множество шин и магистралей, мосты для перехода информации от одной шины к другой и т. п. Для нас сейчас важными являются только следующие моменты.
- Устройства ввода-вывода подключаются к системе через порты.
- Могут существовать два адресных пространства: пространство памяти и пространство ввода-вывода.
- Порты, как правило, отображаются в адресное пространство ввода-вывода и иногда – непосредственно в адресное пространство памяти.
- Использование того или иного адресного пространства определяется типом команды, выполняемой процессором, или типом ее операндов.
- Физическим управлением устройством ввода-вывода, передачей информации через порт и выставлением некоторых сигналов на магистрали занимается контроллер устройства.
Именно единообразие подключения внешних устройств к вычислительной системе является одной из составляющих идеологии, позволяющих добавлять новые устройства без перепроектирования всей системы.
Структура контроллера устройства
Регистр состояния содержит биты, значение которых определяется состоянием устройства ввода-вывода и которые доступны только для чтения… Регистр управления получает данные, которые записываются вычислительной… Регистр выходных данных служит для помещения в него данных для чтения вычислительной системой, а регистр входных…Опрос устройств и прерывания. Исключительные ситуации и системные вызовы
При необходимости вывода новой порции информации все эти шаги повторяются. Если процессор интересует, корректно или некорректно была выведена… Как видим, на первом шаге (и, возможно, после шага 4) процессор ожидает… Для того чтобы процессор не дожидался состояния готовности устройства ввода-вывода в цикле, а мог выполнять в это…Логические принципы организации ввода-вывода
Структура системы ввода-вывода
В области технического обеспечения удалось выделить несколько основных принципов взаимодействия внешних устройств с вычислительной системой, т. е.… Похожий подход оказался продуктивным и в области программного подключения… Два нижних уровня этой слоеной системы составляет hardware: сами устройства, непосредственно выполняющие операции, и…Систематизация внешних устройств и интерфейс между базовой подсистемой ввода-вывода и драйверами
Такое деление является весьма условным. В одних операционных системах сетевые устройства могут не выделяться в отдельную группу, в некоторых других… Для этого мы рассмотрим только две группы устройств: символьные и блочные. Как… К символьным устройствам обычно относятся устройства ввода информации, которые спонтанно генерируют входные данные:…Функции базовой подсистемы ввода-вывода
Блокирующиеся, неблокирующиеся и асинхронные системные вызовы
Буферизация и кэширование
Под словом кэш (cache – "тайник, запас"), этимологию которого мы не будем здесь рассматривать, обычно понимают область быстрой памяти,… Функции буферизации и кэширования не обязательно должны быть локализованы в…Spooling и захват устройств
Рассмотрим в качестве внешнего устройства принтер. Хотя принтер не может печатать информацию, поступающую одновременно от нескольких процессов,… В некоторых операционных системах вместо использования spooling для устранения… Обеспечение spooling и механизма захвата устройств является прерогативой базовой подсистемы ввода-вывода.Обработка прерываний и ошибок
Одна и та же процедура обработки прерывания может применяться для нескольких устройств ввода-вывода (например, если эти устройства используют одну… Действия по обработке прерывания и компенсации возникающих ошибок могут быть…Планирование запросов
После завершения выполнения текущего запроса операционная система (по ходу обработки возникшего прерывания) должна решить, какой из запросов в… Задача планирования использования устройства обычно возлагается на базовую… В следующем разделе мы рассмотрим некоторые алгоритмы планирования, связанные с удовлетворением запросов, на примере…Алгоритмы планирования запросов к жесткому диску
Прежде чем приступить к непосредственному изложению самих алгоритмов, давайте вспомним внутреннее устройство жесткого диска и определим, какие параметры запросов мы можем использовать для планирования.
Строение жесткого диска и параметры планирования
При работе диска набор пластин вращается вокруг своей оси с высокой скоростью, подставляя по очереди под головки соответствующих дорожек все их… Рис. 13.2. Схема жесткого дискаЗаключение
Функционирование любой вычислительной системы обычно сводится к выполнению двух видов работы: обработка информации и операции по осуществлению ее ввода-вывода. С точки зрения операционной системы "обработкой информации" являются только операции, совершаемые процессором над данными, находящимися в памяти на уровне иерархии не ниже чем оперативная память. Все остальное относится к "операциям ввода-вывода", т. е. к обмену информацией с внешними устройствами.
Несмотря на все многообразие устройств ввода-вывода, управление их работой и обмен информацией с ними строятся на относительно небольшом количестве принципов. Основными физическими принципами построения системы ввода-вывода являются следующие: возможность использования различных адресных пространств для памяти и устройств ввода-вывода; подключение устройств к системе через порты ввода-вывода, отображаемые в одно из адресных пространств; существование механизма прерывания для извещения процессора о завершении операций ввода-вывода; наличие механизма прямого доступа устройств к памяти, минуя процессор.
Механизм, подобный механизму прерываний, может использоваться также и для обработки исключений и программных прерываний, однако это целиком лежит на совести разработчиков вычислительных систем.
Для построения программной части системы ввода-вывода характерен "слоеный" подход. Для непосредственного взаимодействия с hardware используются драйверы устройств, скрывающие от остальной части операционной системы все особенности их функционирования. Драйверы устройств через жестко определенный интерфейс связаны с базовой подсистемой ввода-вывода, в обязанности которой входят: организация работы блокирующихся, неблокирующихся и асинхронных системных вызовов, буферизация и кэширование входных и выходных данных, осуществление spooling и монопольного захвата внешних устройств, обработка ошибок и прерываний, возникающих при операциях ввода-вывода, планирование последовательности запросов на выполнение этих операций. Доступ к базовой подсистеме ввода-вывода осуществляется посредством системных вызовов.
Часть функций базовой подсистемы может быть делегирована драйверам устройств и самим устройствам ввода-вывода.
Лекция: Сети и сетевые операционные системы
В лекции рассматриваются особенности взаимодействия процессов, выполняющихся на разных операционных системах, и вытекающие из этих особенностей…Для чего компьютеры объединяют в сети
Сетевые и распределенные операционные системы
В сетевых операционных системах для того, чтобы задействовать ресурсы другого сетевого компьютера, пользователи должны знать о его наличии и уметь… Распределенная система, напротив, внешне выглядит как обычная автономная… Изучение строения распределенных операционных систем не входит в задачи нашего курса. Этому вопросу посвящены другие…Взаимодействие удаленных процессов как основа работы вычислительных сетей
Давайте теперь, абстрагировавшись от физического уровня организации связи и не обращая внимания на то, какие именно физические средства – оптическое…Основные вопросы логической организации передачи информации между удаленными процессами
Разумеется, степень важности этих вопросов во многом зависит от того, с какой точки зрения мы рассматриваем взаимодействие удаленных процессов.… Выбор способа соединения участников сетевого взаимодействия физическими… В современных сетевых вычислительных комплексах решение вопросов организации взаимоисключений при использовании общей…Понятие протокола
"Общение" локальных процессов напоминает общение людей, проживающих в одном городе. Если взаимодействующие процессы находятся под… Каким образом два человека, находящиеся в разных городах, а тем более странах,… Аналогичная ситуация возникает и при общении удаленных процессов, работающих под управлением разных операционных…Многоуровневая модель построения сетевых вычислительных систем
Как уже отмечалось при обсуждении "слоеного" строения операционных систем на первой лекции, при таком подходе уровень N системы… Самым нижним уровнем в слоеных сетевых вычислительных системах является… На самом верхнем уровне находятся пользовательские процессы, которые инициируют обмен данными. Количество и функции…Проблемы адресации в сети
Несколько раньше, обсуждая отличия взаимодействия удаленных процессов от взаимодействия локальных процессов, мы говорили, что удаленные адресаты…Одноуровневые адреса
Двухуровневые адреса
Удаленная адресация и разрешение адресов
С подобными задачами мы уже сталкивались, обсуждая организацию памяти в вычислительных системах (отображение имен переменных в их адреса в процессе… Первый способ решения заключается в том, что на каждом сетевом компьютере… В современной сетевой паутине этот подход является неприемлемым. Дело даже не в размерах подобного файла, а в частоте…Локальная адресация. Понятие порта
Для локальной адресации процессов и промежуточных объектов при удаленной связи обычно организуется новое специальное адресное пространство, например… Необходимо отметить, что в системе может существовать несколько таких адресных… Полные адреса. Понятие сокета (socket)Проблемы маршрутизации в сетях
Маршрутизация от источника передачи данных легко реализуется на промежуточных компонентах сети, но требует полного знания маршрутов на конечных… Для работы алгоритмов одношаговой маршрутизации, которые являются основой… Во-первых, числовые адреса топологически близко расположенных комплексов (например, комплексов, принадлежащих одной…Связь с установлением логического соединения и передача данных с помощью сообщений
Рассматривая канальные средства связи для локальных процессов в лекции 4, мы говорили о существовании двух моделей передачи данных по каналам связи… Транспортные протоколы связи удаленных процессов, которые предназначены для… Необходимо отметить, что с точки зрения процессов, обменивающихся информацией, датаграммы, конечно, могут быть связаны…Синхронизация удаленных процессов
Заключение
Основными причинами объединения компьютеров в вычислительные сети являются потребности в разделении ресурсов, ускорении вычислений, повышении надежности и облегчении общения пользователей.
Вычислительные комплексы в сети могут находиться под управлением сетевых или распределенных вычислительных систем. Основой для объединения компьютеров в сеть служит взаимодействие удаленных процессов. При рассмотрении вопросов организации взаимодействия удаленных процессов нужно принимать во внимание основные отличия их кооперации от кооперации локальных процессов.
Базой для взаимодействия локальных процессов служит организация общей памяти, в то время как для удаленных процессов – это обмен физическими пакетами данных.
Организация взаимодействия удаленных процессов требует от сетевых частей операционных систем поддержки определенных протоколов. Сетевые средства связи обычно строятся по "слоеному" принципу. Формальный перечень правил, определяющих последовательность и формат сообщений, которыми обмениваются сетевые компоненты различных вычислительных систем, лежащие на одном уровне, называется сетевым протоколом. Каждый уровень слоеной системы может взаимодействовать непосредственно только со своими вертикальными соседями, руководствуясь четко закрепленными соглашениями – вертикальными протоколами или интерфейсами. Вся совокупность интерфейсов и сетевых протоколов в сетевых системах, построенных по слоеному принципу, достаточная для организации взаимодействия удаленных процессов, образует семейство протоколов или стек протоколов.
Удаленные процессы, в отличие от локальных, при взаимодействии обычно требуют двухуровневой адресации при своем общении. Полный адрес процесса состоит из двух частей: удаленной и локальной.
Для удаленной адресации используются символьные и числовые имена узлов сети. Перевод имен из одной формы в другую (разрешение имен) может осуществляться с помощью централизованно обновляемых таблиц соответствия полностью на каждом узле или с использованием выделения зон ответственности специальных серверов. Для локальной адресации процессов применяются порты. Упорядоченная пара из адреса узла в сети и порта получила название socket.
Для доставки сообщения от одного узла к другому могут использоваться различные протоколы маршрутизации.
С точки зрения пользовательских процессов обмен информацией может осуществляться в виде датаграмм или потока данных.
Лекция: Основные понятия информационной безопасности
Рассмотрены подходы к обеспечению безопасности информационных систем. Ключевые понятия информационной безопасности: конфиденциальность, целостность и доступность информации, а любое действие, направленное на их нарушение, называется угрозой. Основные понятия информационной безопасности регламентированы в основополагающих документах. Существует несколько базовых технологий безопасности, среди которых можно выделить криптографию.
Введение
В октябре 1988 г. в США произошло событие, названное специалистами крупнейшим нарушением безопасности американских компьютерных систем из когда-либо случавшихся. 23-летний студент выпускного курса Корнельского университета Роберт Т. Моррис запустил в компьютерной сети ARPANET программу, представлявшую собой редко встречающуюся разновидность компьютерных вирусов – сетевых "червей". В результате атаки был полностью или частично заблокирован ряд общенациональных компьютерных сетей, в частности Internet, CSnet, NSFnet, BITnet, ARPANET и несекретная военная сеть Milnet. В итоге вирус поразил более 6200 компьютерных систем по всей Америке, включая системы многих крупнейших университетов, институтов, правительственных лабораторий, частных фирм, военных баз, клиник, агентства NASA. Общий ущерб от этой атаки оценивается специалистами минимум в 100 млн. долл. Р. Моррис был исключен из университета с правом повторного поступления через год и приговорен судом к штрафу в 270 тыс. долл. и трем месяцам тюремного заключения.
Важность решения проблемы информационной безопасности в настоящее время общепризнана, подтверждением чему служат громкие процессы о нарушении целостности систем. Убытки ведущих компаний в связи с нарушениями безопасности информации составляют триллионы долларов, причем только треть опрошенных компаний смогли определить количественно размер потерь. Проблема обеспечения безопасности носит комплексный характер, для ее решения необходимо сочетание законодательных, организационных и программно-технических мер.
Таким образом, обеспечение информационной безопасности требует системного подхода и нужно использовать разные средства и приемы – морально-этические, законодательные, административные и технические. Нас будут интересовать последние. Технические средства реализуются программным и аппаратным обеспечением и решают разные задачи по защите, они могут быть встроены в операционные системы либо могут быть реализованы в виде отдельных продуктов. Во многих случаях центр тяжести смещается в сторону защищенности операционных систем.
Есть несколько причин для реализации дополнительных средств защиты. Hаиболее очевидная – помешать внешним попыткам нарушить доступ к конфиденциальной информации. Не менее важно, однако, гарантировать, что каждый программный компонент в системе использует системные ресурсы только способом, совместимым с установленной политикой применения этих ресурсов. Такие требования абсолютно необходимы для надежной системы. Кроме того, наличие защитных механизмов может увеличить надежность системы в целом за счет обнаружения скрытых ошибок интерфейса между компонентами системы. Раннее обнаружение ошибок может предотвратить "заражение" неисправной подсистемой остальных.
Политика в отношении ресурсов может меняться в зависимости от приложения и с течением времени. Операционная система должна обеспечивать прикладные программы инструментами для создания и поддержки защищенных ресурсов. Здесь реализуется важный для гибкости системы принцип – отделение политики от механизмов. Механизмы определяют, как может быть сделано что-либо, тогда как политика решает, что должно быть сделано. Политика может меняться в зависимости от места и времени. Желательно, чтобы были реализованы по возможности общие механизмы, тогда как изменение политики требует лишь модификации системных параметров или таблиц.
К сожалению, построение защищенной системы предполагает необходимость склонить пользователя к отказу от некоторых интересных возможностей. Например, письмо, содержащее в качестве приложения документ в формате Word, может включать макросы. Открытие такого письма влечет за собой запуск чужой программы, что потенциально опасно. То же самое можно сказать про Web-страницы, содержащие апплеты. Вместо критического отношения к использованию такой функциональности пользователи современных компьютеров предпочитают периодически запускать антивирусные программы и читать успокаивающие статьи о безопасности Java.
Угрозы безопасности
Считается, что безопасная система должна обладать свойствами конфиденциальности, доступности и целостности. Любое потенциальное действие, которое… Конфиденциальная (confidentiality) система обеспечивает уверенность в том, что… Защита информации ориентирована на борьбу с так называемыми умышленными угрозами, то есть с теми, которые, в отличие…Формализация подхода к обеспечению информационной безопасности
Наиболее известна оранжевая (по цвету обложки) книга Министерства обороны США [DoD, 1993]. В этом документе определяется четыре уровня безопасности… В качестве примера рассмотрим требования класса C2, которому удовлетворяют ОС… Сегодня на смену оранжевой книге пришел стандарт Common Criteria, а набор критериев Controlled Access Protection…Криптография как одна из базовых технологий безопасности ОС
Шифрование – процесс преобразования сообщения из открытого текста (plaintext) в шифротекст (ciphertext) таким образом, чтобы: его могли … В алгоритмах шифрования предусматривается наличие ключа. Ключ – это некий… В методе шифрования с секретным или симметричным ключом имеется один ключ, который используется как для шифрования,…Шифрование с использованием алгоритма RSA
Применяемые в RSA прямая и обратная функции просты. Они базируются на применении теоремы Эйлера из теории чисел. Прежде чем сформулировать теорему Эйлера, необходимо определить важную функцию…Теорема Эйлера
xΦ(n)mod n = 1 или в более общем виде xkΦ(n)+1mod n = 1Заключение
Информационная безопасность относится к числу дисциплин, развивающихся чрезвычайно быстрыми темпами. Только комплексный, систематический, современный подход способен успешно противостоять нарастающим угрозам.
Ключевые понятия информационной безопасности: конфиденциальность, целостность и доступность информации, а любое действие, направленное на их нарушение, называется угрозой.
Основные понятия информационной безопасности регламентированы в основополагающих документах.
Существует несколько базовых технологий безопасности, среди которых можно выделить криптографию.
Лекция: Защитные механизмы операционных систем
Решение вопросов безопасности операционных систем обусловлено их…Идентификация и аутентификация
Обычно аутентификация базируется на одном или более из трех пунктов: то, чем пользователь владеет (ключ или магнитная карта); то, что …Пароли, уязвимость паролей
Когда пользователь идентифицирует себя при помощи уникального идентификатора или имени, у него запрашивается пароль. Если пароль, сообщенный… Недостатки паролей связаны с тем, что трудно сохранить баланс между удобством… Есть два общих способа угадать пароль. Один связан со сбором информации о пользователе. Люди обычно используют в…Шифрование пароля
Например, в ряде версий Unix в качестве односторонней функции используется модифицированный вариант алгоритма DES. Введенный пароль длиной до 8… В ОС Windows NT преобразование исходного пароля также осуществляется… Хранятся только кодированные пароли. В процессе аутентификации представленный пользователем пароль кодируется и…Авторизация. Разграничение доступа к объектам ОС
Как уже говорилось в предыдущей лекции, компьютерная система может быть смоделирована как набор субъектов (процессы, пользователи) и объектов. Под… Операции зависят от объектов. Hапример, процессор может только выполнять… Желательно добиться того, чтобы процесс осуществлял авторизованный доступ только к тем ресурсам, которые ему нужны для…Домены безопасности
Рис. 16.1. Специфицирование прав доступа к ресурсам Связь конкретных субъектов, функционирующих в операционных системах, может быть организована следующим образом. …Матрица доступа
Список прав доступа. Access control list
Элементами списка могут быть процессы, пользователи или группы пользователей. При реализации широко применяется предоставление доступа по умолчанию…Мандаты возможностей. Capability list
Примерами систем, использующих перечни возможностей, являются Hydra, Cambridge CAP System [Denning, 1996].Другие способы контроля доступа
Существует также схема lock-key, которая является компромиссом между списками прав доступа и перечнями возможностей. В этой схеме каждый объект… Как и в случае мандатов, список ключей для домена должен управляться ОС.…Смена домена
Недопустимость повторного использования объектов
Выявление вторжений. Аудит системы защиты
Основным инструментом выявления вторжений является запись данных аудита. Отдельные действия пользователей протоколируются, а полученный протокол… Аудит, таким образом, заключается в регистрации специальных данных о различных… Если фиксировать все события, объем регистрационной информации, скорее всего, будет расти слишком быстро, а ее…Анализ некоторых популярных ОС с точки зрения их защищенности
Большое значение имеет структура файловой системы. Hапример, в ОС с дискреционным контролем доступа каждый файл должен храниться вместе с… В принципе, меры безопасности не обязательно должны быть заранее встроены в ОС…MS-DOS
ОС MS-DOS функционирует в реальном режиме (real-mode) процессора i80x86. В ней невозможно выполнение требования, касающегося изоляции программных модулей (отсутствует аппаратная защита памяти). Уязвимым местом для защиты является также файловая система FAT, не предполагающая у файлов наличия атрибутов, связанных с разграничением доступа к ним. Таким образом, MS-DOS находится на самом нижнем уровне в иерархии защищенных ОС.
NetWare, IntranetWare
OS/2
OS/2 работает в защищенном режиме (protected-mode) процессора i80x86. Изоляция программных модулей реализуется при помощи встроенных в этот процессор механизмов защиты памяти. Поэтому она свободна от указанного выше коренного недостатка систем типа MS-DOS. Но OS/2 была спроектирована и разработана без учета требований по защите от несанкционированного доступа. Это сказывается прежде всего на файловой системе. В файловых системах OS/2 HPFS (high performance file system) и FAT нет места ACL. Кроме того, пользовательские программы имеют возможность запрета прерываний. Следовательно, сертификация OS/2 на соответствие какому-то классу защиты не представляется возможной.
Считается, что такие операционные системы, как MS-DOS, Mac OS, Windows, OS/2, имеют уровень защищенности D (по оранжевой книге). Но, если быть точным, нельзя считать эти ОС даже системами уровня безопасности D, ведь они никогда не представлялись на тестирование.
Unix
Рост популярности Unix и все большая осведомленность о проблемах безопасности привели к осознанию необходимости достичь приемлемого уровня безопасности ОС, сохранив при этом мобильность, гибкость и открытость программных продуктов. В Unix есть несколько уязвимых с точки зрения безопасности мест, хорошо известных опытным пользователям, вытекающих из самой природы Unix (см., например, раздел "Типичные объекты атаки хакеров" в книге [Дунаев, 1996]). Однако хорошее системное администрирование может ограничить эту уязвимость.
Относительно защищенности Unix сведения противоречивы. В Unix изначально были заложены идентификация пользователей и разграничение доступа. Как оказалось, средства защиты данных в Unix могут быть доработаны, и сегодня можно утверждать, что многие клоны Unix по всем параметрам соответствуют классу безопасности C2.
Обычно, говоря о защищенности Unix, рассматривают защищенность автоматизированных систем, одним из компонентов которых является Unix-сервер. Безопасность такой системы увязывается с защитой глобальных и локальных сетей, безопасностью удаленных сервисов типа telnet и rlogin/rsh и аутентификацией в сетевой конфигурации, безопасностью X Window-приложений. Hа системном уровне важно наличие средств идентификации и аудита.
В Unix существует список именованных пользователей, в соответствии с которым может быть построена система разграничения доступа.
В ОС Unix считается, что информация, нуждающаяся в защите, находится главным образом в файлах.
По отношению к конкретному файлу все пользователи делятся на три категории:
- владелец файла;
- члены группы владельца;
- прочие пользователи.
Для каждой из этих категорий режим доступа определяет права на операции с файлом, а именно:
- право на чтение;
- право на запись;
- право на выполнение (для каталогов - право на поиск).
В итоге девяти (3х3) битов защиты оказывается достаточно, чтобы специфицировать ACL каждого файла.
Аналогичным образом защищены и другие объекты ОС Unix, например семафоры, сегменты разделяемой памяти и т. п.
Указанных видов прав достаточно, чтобы определить допустимость любой операции с файлами. Например, для удаления файла необходимо иметь право на запись в соответствующий каталог. Как уже говорилось, права доступа к файлу проверяются только на этапе открытия. При последующих операциях чтения и записи проверка не выполняется. В результате, если режим доступа к файлу меняется после того, как файл был открыт, это не сказывается на процессах, уже открывших этот файл. Данное обстоятельство является уязвимым с точки зрения безопасности местом.
Наличие всего трех видов субъектов доступа: владелец, группа, все остальные - затрудняет задание прав "с точностью до пользователя", особенно в случае больших конфигураций. В популярной разновидности Unix - Solaris имеется возможность использовать списки управления доступом (ACL), позволяющие индивидуально устанавливать права доступа отдельных пользователей или групп.
Среди всех пользователей особое положение занимает пользователь root, обладающий максимальными привилегиями. Обычные правила разграничения доступа к нему не применяются - ему доступна вся информация на компьютере.
В Unix имеются инструменты системного аудита - хронологическая запись событий, имеющих отношение к безопасности. К таким событиям обычно относят: обращения программ к отдельным серверам; события, связанные с входом/выходом в систему и другие. Обычно регистрационные действия выполняются специализированным syslog-демоном, который проводит запись событий в регистрационный журнал в соответствии с текущей конфигурацией. Syslog-демон стартует в процессе загрузки системы.
Таким образом, безопасность ОС Unix может быть доведена до соответствия классу C2. Однако разработка на ее основе автоматизированных систем более высокого класса защищенности может быть сопряжена с большими трудозатратами.
Windows NT/2000/XP
Компоненты защиты NT частично встроены в ядро, а частично реализуются подсистемой защиты. Подсистема защиты контролирует доступ и учетную… ОС Windows 2000 сертифицирована по стандарту Common Criteria. В дальнейшем… Ключевая цель системы защиты Windows NT - следить за тем, кто и к каким объектам осуществляет доступ. Система защиты…Заключение
Решение вопросов безопасности операционных систем обусловлено их архитектурными особенностями и связано с правильной организацией идентификации и аутентификации, авторизации и аудита.
Наиболее простой подход к аутентификации - применение пользовательского пароля. Пароли уязвимы, значительная часть попыток несанкционированного доступа в систему связана с компрометацией паролей.
Авторизация связана со специфицированием совокупности аппаратных и программных объектов, нуждающихся в защите. Для защиты объекта устанавливаются права доступа к нему. Набор прав доступа определяет домен безопасности. Формальное описание модели защиты осуществляется с помощью матрицы доступа, которая может храниться в виде списков прав доступа или перечней возможностей.
Аудит системы заключается в регистрации специальных данных о различных событиях, происходящих в системе и так или иначе влияющих на состояние безопасности компьютерной системы.
Среди современных ОС вопросы безопасности лучше всего продуманы в ОС Windows NT.