Система HEARSAY
Архитектура на основе доски объявлений выросла из разработанной в конце 70 годов системы распознавания речи HEARSAY-II и HEARSAY-III. Программирование компьютера с целью распознавания речи - это одна из наиболее сложных задач к тому времени, за которые когда-либо брались специалисты в области искусственного интеллекта. Ее решение требует:
- сложной обработки сигналов;
- сопоставления физических характеристик звуковых сигналов с символическими элементами естественного языка;
- выполнения поиска в большом пространстве возможных интерпретаций, в котором объединены эти разные по своей природе элементы.
Для решения этой проблемы была выбрана методика, основанная на выделении нескольких уровней абстракции описания анализируемых данных. Самым нижним является уровень физических акустических сигналов, на котором формируется звуковой спектр анализированных сигналов. На последующих уровнях информация проходит через напластование лингвистических абстракций со все более увеличивай: уровнем общности понятий - фонемы, силлабы (созвучия), морфемы, слова, выражения и предложения.
Приступая к разработке системы, ее создатели понимали, что с каждым уровнем анализа связана отдельная отрасль знаний - анализ звуковых сигналов фонетика, лексический анализ, грамматика, семантика, ораторское искусство. Ни одна отраслей по отдельности не способна предоставить достаточно информации для того чтобы решить проблему. Представим, например, что, пользуясь методами обработки акустических сигналов, смогли разложить исходный звук на фонемы. Но без дополнительной информации все равно не удастся выделить смысл выражений, подобно следующим: I scream (я восклицаю) и ice cream (мороженое) или please let us know (пожалуйста, дайте нам знать) и please lettuce no (пожалуйста, без салата). Таким образом, хотя каждый отдельный вид (набор) знаний играет существенную роль в решении проблемы и каждый из них может быть представлен в программе более или менее независимо от остальных, автоматическое распознавание речи требует использования всех этих знаний совместно.
При распознавании речи исследователям приходится сталкиваться еще с одной проблемой, которую также можно отнести к числу ключевых, — проблемой неопределенности. Она проявляется на всех уровнях представления информации:
- данные неполные и зашумлены;
- отсутствует однозначное соответствие между данными на соседних уровня: примером может служить соответствие между уровнями фонем и лексических с при анализе фраз I scream и ice cream ;
- важную роль играют лингвистический и смысловой контексты; интерпретация соседних элементов делает более или менее вероятными разные варианты интерпретации текущего сегмента.
Более традиционные подходы к распознаванию речи основаны на использовании статистических моделей из теории передачи информации для определения корреляционной связи между сегментами. Подход, базирующийся на знаниях, потребовал существенного пересмотра методов обработки неопределенности.
Перечислим требования, которым должна удовлетворять эффективно работающая система распознавания речи, основанная знаниях.
1) Из всех возможных последовательностей операций (частных решений) хотя бы одна должна приводить к корректной интерпретации.
2) Процедура анализа имеющихся вариантов интерпретации должна давать корректному варианту более высокую оценку, чем другим конкурирующим вариантам. Другими словами, правильная интерпретация с учетом произношения должна быть оценена выше, чем другие варианты интерпретации, не учитывающие особенностей индивидуальной дикции.
3) Вычислительные ресурсы (память и время вычислений), необходимые для отыскания правильной интерпретации, не должны превышать определенный порог. Система распознавания, которая через пару дней выдаст результат, пусть и правильный, и потребует памяти объемом несколько гигабайт, вряд ли кому-нибудь будет нужна.
В приведенном списке первое и третье требования в определенной мере противоречат друг другу. Для того чтобы корректное решение изначально присутствовало в пространстве гипотез, на стадии формирования гипотез поневоле приходится быть расточительным, что при большом словаре может привести к комбинаторному взрыву элементов решений. Выход может быть найден только при использовании чрезвычайно остроумных эвристик. Таким образом, важнейшей предпосылкой достижения успеха в создании такой системы является разработка подходящей процедуры оценки вариантов (второе из перечисленных выше требований).
5.3.Использование источников знаний в системе HEARSAY
Для генерации, комбинирования и развития гипотез интерпретации в системе HEARSAY-II используется несколько источников знаний. Созданные гипотезы (интерпретации) разного уровня абстракции сохраняются на доске объявлений.
Каждый источник знаний можно считать в первом приближении набором пар "условие-действие", хотя они могут быть реализованы и в форме, отличной от порождающих правил (например, условия и действия могут быть в действительности произвольными процедурами). Поток управления в этой системе также отличается от потока управления в продукционных системах. Вместо того чтобы в каждом цикле интерпретатор анализировал выполнение условий, специфицированных в источниках знаний, источники знаний загодя объявляют об активизированных в них условиях, извещая, какой вид модификации данных будет влиять на выполнение этих условий. В результате система управляется прерываниями, а этот режим управления значительно эффективнее, чем режим циклического просмотра состояния, который является основным для продукционных экспертных систем. Такой режим напоминает использование демонов во фреймовых системах, где поток управления регулируется обновлением данных.
Источники знаний связываются с уровнями доски объявлений следующим образом. Условия, специфицированные в источнике знаний, будут удовлетворяться в результате обновления данных на определенном уровне доски объявлений. Источник знаний также может записывать данные в определенный уровень, причем не обязательно в тот же, который влияет на выполнение условий. Большинство источников знаний в системе HEARSAY-П организовано так, что они распознают данные на определенном уровне лингвистического анализа, а выполняемые ими операции относятся к следующему по порядку уровню. Например, некоторый источник активизируется данными на силлабическом уровне и формирует лексическую гипотезу на уровне слов.
Имеет семь уровень понимания от акустических параметров звуковых волн до понимания смысла вопроса Рисунок 5.1.
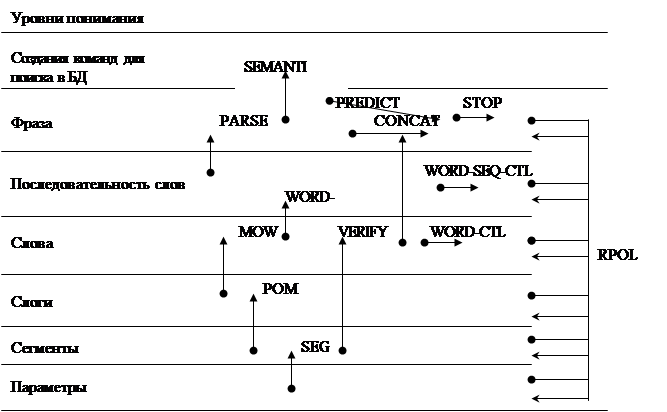
Рисунок 5.1Структура знаний системы HEARSAY
Знания распределены по источникам знаний, ● - место сопоставления данных в условиях, ← место занесения действиях. Источник знаний – набор модулей типа “условие – действие”:
SEG- преобразует речевые сигналы в дискретную форму, измеряет параметры, образует сегменты.
POW- на основе сегментов создает гипотезы о слогах.
MOW- на основе слогов гипотезы о простых словах.
WORD-CTL- управляет числом гипотез, созданных MOW.
WORD-SEQ- на основе гипотезы о словах и грамматических правил создает гипотезы о последовательности слов.
WORD-SEQ-CTL- управляет числом гипотез.
PARSE- делает грамматических разбор последовательности слов, если все верно, создает гипотезы о фразе.
PREDICT- предсказывает слова, т.е. предшествуют или следуют за фразой.
VERIFY- оценивает степень соответствия между гипотезой о сегментах и парой связанных слов.
CONCAT- на основе проверенных пар связанных слов создает гипотезу о фразе.
RPOL- оценивает степень доверия другим гипотезам на основе информации в гипотезах, созданных другими источниками.
STOP- оценивает необходимость остановки процесса (конечно ли предложение) и выбирает гипотезу, которая считается наиболее верной.
SEMANT- интерпретирует смысл для системы поиска информации.
Гипотезы оцениваются по шкале от 0 до 100. Оценка действует на данном уровне.
Рисунок 5.2 демрнстрирует модель доски объявлений в HEARSAY-II.
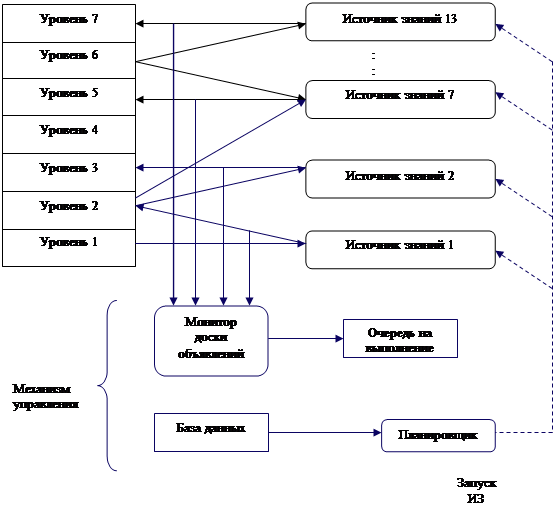 |
Рисунок 5.2 Модель доски объявлений в HEARSAY-II
Это распределенная область данных, каждый ИЗ обращается к соответствующей области доски объявлений, вносит гипотезы или дает им оценки в других областях. Эту систему можно рассматривать как распределенную иерархическую высокоуровневую продукционную систему. Можно счатать что все ИЗ действуют асинхронно и паралельно. Планирование осущемтвляется механизмом управления: действует ИЗ с максимальным приоритетом. Поэтому при параллельной обработке информации или муультиплексорной системе участвуют в решении единой задачи независимо и асинхронно друг от друга.