рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Вид работы: Рефераты
- /
- Особенности практического кодирования
Реферат Курсовая Конспект
Особенности практического кодирования
Особенности практического кодирования - Реферат, раздел Образование, Реферат на тему: Классификация помехоустойчивых кодов. Особенности практического кодирования КРАТКАЯ КЛАССИФИКАЦИЯ ПОМЕХОУСТОЙЧИВЫХ КОДОВ Предположим, Что Все Представляющие Интерес Данные Могут Быть...
Предположим, что все представляющие интерес данные могут быть представлены в виде двоичной (закодированной двоично) информации, т. е. в виде последовательности нулей и единиц. Задача формулируется стандартно. Эта двоичная информация подлежит передаче по каналу, подверженному случайным ошибкам. Задача кодирования состоит в таком добавлении к информационным символам дополнительных символов, чтобы на приемнике эти искажения могли быть найдены и исправлены. Иначе говоря, последовательность символов данных представляется в виде некоторой более длинной последовательности символов, избыточность которой достаточна для защиты данных.
Двоичный код мощности М и длины n представляет собой множество из М двоичных слов длины n, называемых кодовыми словами. Обычно М = 2k, где k - некоторое целое число; такой код называется двоичным (n,k)-кодом.
Например, можно построить следующий код: 10101 10010 01110 11111 Это очень бедный (и очень маленький) код с M = 4 и n=5, но он удовлетворяет приведенному выше определению. Данный код можно использовать для представления 2-битовых двоичных чисел, используя следующее (произвольное) соответствие:
00<-> 10101, 01<-> 10010, 10<-> 01110, 11<-> lllll.
Если получено одно из четырех 5-битовых кодовых слов, то полагаем, что соответствующие ему два бита являются правильной информацией. Если произошла ошибка, то мы получим 5-битовое слово, отличающееся от кодовых слов. Тогда попытаемся найти наиболее вероятно переданное слово и возьмем его в качестве оценки исходных двух битов информации. Например, если мы приняли 01100, то полагаем, что передавалось 01110, и, следовательно, информационное слово равнялось 10.
В приведенном примере код не является хорошим, так как он не позволяет исправлять много конфигураций ошибок. Желательно выбирать коды так, чтобы каждое кодовое слово по возможности больше отличалось от каждого другого кодового слова; в частности, это желательно в том случае, когда длина блока велика.
Mожет показаться, что достаточно определить требования к "хорошему коду" и затем предпринять машинный поиск по множеству всех возможных кодов. Но сколько кодов существует для данных n и k? Каждое кодовое слово представляет собой последовательность n двоичных символов, и всего имеется 2k таких слов; следовательно, код описывается n2k двоичными символами. Всего существует 2n2k способов выбора этих двоичных символов; следовательно, число различных (n,k)-кодов равно этому числу. Конечно, очень многие из этих кодов не представляют интереса (как в случае, когда два кодовых слова равны), так что надо либо проверять это по ходу поиска, либо развить некоторую теорию, позволяющую исключить такие коды.
Например, выберем (n,k) = (40,20) - код, весьма умеренный по современным стандартам. Тогда число таких кодов превзойдет величину 1010000000 - невообразимо большое число! Следовательно, неорганизованные процедуры поиска бессильны.
В общем случае блоковые коды определяются над произвольным конечным алфавитом, скажем над алфавитом из q символов {0, 1, 2, ..., q - 1}. На первый взгляд введение алфавитов, отличных от двоичного, может показаться излишним обобщением. Из соображений эффективности, однако, многие современные каналы являются недвоичными, и коды для этих каналов должны быть недвоичными. На самом деле коды для недвоичных каналов часто оказываются достаточно хорошими, и сам этот факт может служить причиной для использования недвоичных каналов. Двоичные данные источника тривиальным образом представляются символами q-ичного алфавита, особенно если q равно степени двойки, как это обычно и бывает на практике.
Определение. Блоковый код мощности М над алфавитом из q символов определяется как множество из М (q-ичных последо-вательностей длины q, называемых кодовыми, словами.
Если q = 2, то символы называются битами. Обычно М = qk для некоторого целого k, и мы будем интересоваться только этим случаем, называя код (n,k)-кодом. Каждой последовательности из k q-ичных символов можно сопоставить последовательность из n q-ичных символов, являющуюся кодовым словом.
Имеются два основных класса кодов: блоковые коды и древовидные коды; они иллюстрируются рис. 1. Блоковый код задает блок из k информационных символов n-символьным кодовым словом. Скорость R блокового кода определяется равенством R = k/n.(Скорость - величина безразмерная или, возможно, измеряемая в единицах бит/бит или символ/символ. Ее следует отличать от другого называемого тем же термином скорость понятия, измеряющего канальную скорость в бит/с. Используется и другое определение скорости: R = (k/n)logeq, единицей которого является нат/символ, где один нат равен log2e битов. Принято также определение R = (k/n) log2q, в котором скорость измеряется в единицах бит/символ.)
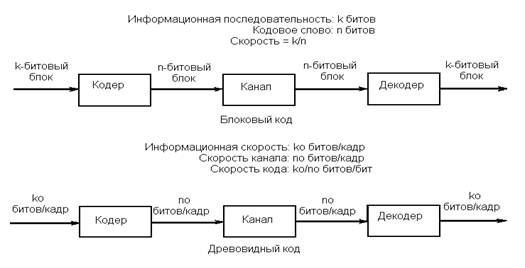
Рис. 2. Основные классы кодов.
Древовидный код более сложен. Он отображает бесконечную последовательность информационных символов, поступающую со скоростью k0 символов за один интервал времени, в непрерывную последовательность символов кодового слова со скоростью n0 символов за один интервал времени. Cосредоточим внимание на блоковых кодах.
Если сообщение состоит из большого числа битов, то в принципе лучше использовать один кодовый блок большой длины, чем последовательность кодовых слов из более короткого кода. Природа статистических флуктуаций такова, что случайная конфигурация ошибок обычно имеет вид серии ошибок. Некоторые сегменты этой конфигурации содержат больше среднего числа ошибок, а некоторые меньше. Следовательно, при одной и той же скорости более длинные кодовые слова гораздо менее чувствительны к ошибкам, чем более короткие кодовые слова, но, конечно, соответствующие кодер и декодер могут быть более сложными. Например, предположим, что 1000 информационных битов передаются с помощью (воображаемого) 2000-битового двоичного кода, способного исправлять 100 ошибок. Сравним такую возможность с передачей одновременно 100 битов с помощью 200-битового кода, исправляющего 10 ошибок на блок. Для передачи 1000 битов необходимо 10 таких блоков. Вторая схема также может исправлять 100 ошибок, но лишь тогда, когда они распределены частным образом - по 10 ошибок в 200-битовых подблоках. Первая схема может исправлять 100 ошибок независимо от того, как они расположены внутри 2000-битового кодового слова. Она существенно эффективнее.
Эти эвристические рассуждения можно обосновать теоретически, но здесь мы к этому не стремимся. Мы только хотим обосновать тот факт, что хорошими являются коды с большой длиной блока и что очень хорошими кодами являются коды с очень большой длиной блока. Такие коды может быть очень трудно найти, а будучи найденными, они могут потребовать сложных устройств для реализации операций кодирования и декодирования.
О блоковом коде судят по трем параметрам: длине блока n, информационной длине k и минимальному расстоянию d*. Минимальное расстояние является мерой различия двух наиболее похожих кодовых слов. Минимальное расстояние вводится двумя следующими определениями.
Определение. Расстоянием по Хэммингу между двумя q-ичными последовательностями х и у длины n называется число позиций, в которых они различны. Это расстояние обозначается через d(х, у).
Например, возьмем х = 10101 и у =01100; тогда имеем d (10101, 01100) = 3. В качестве другого примера возьмем х = 30102 и у = 21103; тогда d (30102, 21103) = 3.
Определение. Пусть C = {сi , i = 0, ..., М - 1} - код. Тогда минимальное расстояние кода C равно наименьшему из всех расстояний по Хэммингу между различными парами кодовых слов, т. е.
d* = min d(ci,сj).
(n, k)-код с минимальным расстоянием d* называется также (n, k, d*)-кодом.
В коде C, выбранном в примере, d (10101, 10010) =3, d (10010, 01110) = 3, d(10101, 01110) = 4, d(10010, 11111) == 3, d (10101, 11111) =2, d(01110, 11111) =2; следовательно, для этого кода d* = 2.
Предположим, что передано кодовое слово и в канале произошла одиночная ошибка. Тогда принятое слово находится на равном 1 расстоянии по Хэммингу от переданного слова. В случае, когда расстояние до каждого другого кодового слова больше чем 1, декодер исправит ошибку, если положит, что действительно переданным словом было ближайшее к принятому кодовое слово.
В более общем случае если произошло t ошибок и если расстояние от принятого слова до каждого другого кодового слова больше t, то декодер исправит эти ошибки, приняв ближайшее к принятому кодовое слово в качестве действительно переданного. Это всегда будет так, если
d* >= 2t + 1.
Иногда удается исправлять конфигурацию из t ошибок даже тогда, когда это неравенство не удовлетворяется. Однако если d* < 2t + 1, то исправление любых t ошибок не может быть гарантировано, так как тогда оно зависит от того, какое слово передавалось и какова была конфигурация из t ошибок внутри блока.
Геометрическая иллюстрация дается на рис. 3.4.
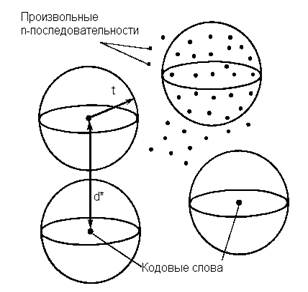
Рис. 3.4. Сферы декодирования.
В пространстве всех (q-ичных n-последовательностей выбрано некоторое множество n-последовательностей, объявленных кодовыми словами. Если d* - минимальное расстояние этого кода, а t - наибольшее целое число, удовлетворяющее условию d*>= 2t + 1, то вокруг каждого кодового слова можно описать непересекающиеся сферы радиуса t. Принятые слова, лежащие внутри сфер, декодируются как кодовое слово, являющееся центром соответствующей сферы. Если произошло не более t ошибок, то принятое слово всегда лежит внутри соответствующей сферы и декодируется правильно.
Некоторые принятые слова, содержащие более t ошибок, попадут внутрь сферы, описанной вокруг другого кодового слова, и будут декодированы неправильно. Другие принятые слова, содержащие более t ошибок, попадут в промежуточные между сферами декодирования области. В зависимости от применения последний факт можно интерпретировать одним из двух способов.
Неполный декодер декодирует только те принятые слова, которые лежат внутри сфер декодирования, описанных вокруг кодовых слов. Остальные принятые слова, содержащие более допустимого числа ошибок, декодер объявляет нераспознаваемыми. Такие конфигурации ошибок при неполном декодировании называются неисправляемыми. Большинство используемых декодеров являются неполными декодерами. Полный декодер декодирует каждое принятое слово в ближайшее кодовое слово. Геометрически это представляется следующим образом: полный декодер разрезает промежуточные области на куски и присоединяет их к сферам так, что каждая точка попадает в ближайшую сферу. Обычно некоторые точки находятся на равных расстояниях от нескольких сфер; тогда одна из этих сфер произвольно объявляется ближайшей. Если происходит более t ошибок, то полный декодер часто декодирует неправильно, но бывают и случаи попадания в правильное кодовое слово. Полный декодер используется в тех случаях, когда лучше угадывать сообщение, чем вообще не иметь никакой его оценки. Можно также рассматривать каналы, в которых кроме ошибок происходят и стирания. Это значит, что конструкцией приемника предусмотрено объявление символа стертым, если он получен ненадежно или если приемник распознал наличие интерференции или сбой. Такой канал имеет входной алфавит мощности q выходной алфавит мощности q + 1; дополнительный символ называется стиранием. Например, стирание символа 3 в сообщении 12345 приводит к слову 12-45. Это не следует путать с другой операцией, называемой выбрасыванием, которая дает 1245.
B таких каналах могут использоваться коды, контролирующие ошибки. В случае когда минимальное расстояние кода равно d*, любая конфигурация из р стираний может быть восстановлена, если d* >= р + 1. Далее, любая конфигурация из v ошибок и р стираний может быть декодирована при условии, что
d* >= 2v + 1 + р.
Для доказательства выбросим из всех кодовых слов те р компонент, в которых приемник произвел стирания. Это даст новый код, минимальное расстояние которого не меньше d* - р; следовательно, v ошибок могут быть исправлены при условии, что выполняется выписанное выше неравенство. Таким образом, можно восстановить укороченное кодовое слово с р стертыми компонентами. Наконец, так как d* > р + 1, существует только одно кодовое слово, совпадающее с полученным в нестертых компонентах; следовательно, исходное кодовое слово может быть восстановлено.
– Конец работы –
Эта тема принадлежит разделу:
Реферат на тему: Классификация помехоустойчивых кодов. Особенности практического кодирования КРАТКАЯ КЛАССИФИКАЦИЯ ПОМЕХОУСТОЙЧИВЫХ КОДОВ
кафедра РЭС... реферат на тему...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Особенности практического кодирования
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.017 сек.
Новости и инфо для студентов