рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Психология
- /
- ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
Реферат Курсовая Конспект
ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ - раздел Психология, Математические методы психологического исследования. Анализ и интерпретация данных. Учебное пособие К Первичным Описательным Статистикам {Descriptive Statistics) Обычно О...
К первичным описательным статистикам {Descriptive Statistics) обычно относят числовые характеристики распределения измеренного на выборке признака. Каждая такая характеристика отражает в одном числовом значении свойство распределения множества результатов измерения: с точки зрения их расположения на числовой оси либо с точки зрения их изменчивости. Основное назначение каждой из первичных описательных статистик — замена множества значений признака, измеренного на выборке, одним числом (например, средним значением как мерой центральной тенденции). Компактное описание группы при помощи первичных статистик позволяет интерпретировать результаты измерений, в частности, путем сравнения первичных статистик разных групп.
МЕРЫ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
Мера центральной тенденции{Central Tendency) — это число, характеризующее выборку по уровню выраженности измеренного признака.
Существуют три способа определения «центральной тенденции», каждому из которых соответствует своя мера: мода, медиана и выборочное среднее.
Мода{Mode) — это такое значение из множества измерений, которое встречается наиболее часто. Моде, или модальному интервалу признака, соответствует наибольший подъем (вершина) графика распределения частот. Если график распределения частот имеет одну вершину, то такое распределение называется унимодальным.
ПРИМЕР_______________________________________________________________
Среди 8 значений признака (3, 7, 3, 5, 7, 8, 7, 6) мода Мо = 7 как наиболее часто встречающееся значение. В табл. 3.2 предыдущего параграфа Мо = 3, а в табл. 3.3 модальным является интервал 50—54.
ГЛАВА 4. ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
Когда два соседних значения встречаются одинаково часто и чаще, чем любое другое значение, мода есть среднее этих двух значений.
Распределение может иметь и не одну моду. Когда все значения встречаются одинаково часто, принято считать, что такое распределение не имеет моды.
Бимодальное распределение имеет на графике распределения две вершины, даже если частоты для двух вершин не строго равны. В последнем случае выделяют большую и меньшую моду. Во всей группе может быть и несколько локальных вершин распределения частот. Тогда выделяют наибольшую моду и локальные моды.
Еще раз отметим, что мода — это значение признака, а не его частота.
Медиана{Median) — это такое значение признака, которое делит упорядоченное (ранжированное) множество данных пополам так, что одна половина всех значений оказывается меньше медианы, а другая — больше. Таким образом, первым шагом при определении медианы является упорядочивание (ранжирование) всех значений по возрастанию или убыванию. Далее медиана определяется следующим образом:
□ если данные содержат нечетное число значений (8, 9, 10, 13, 15), то ме
диана есть центральное значение, т. е. Md= 10;
□ если данные содержат четное число значений (5, 8, 9, 11), то медиана
есть точка, лежащая посередине между двумя центральными значения
ми, т. е. М/=(8+9)/2 = 8,5.
Среднее(Mean) (Мх — выборочное среднее, среднее арифметическое) — определяется как сумма всех значений измеренного признака, деленная на количество суммированных значений.
Если некоторый признак X измерен в группе испытуемых численностью N, мы получим значения: хи х2, ..., xh ..., xN (где / — текущий номер испытуемого, от 1 до N). Тогда среднее значение Мх определяется по формуле:
Мх= — Ух,. (4.1)
Свойства среднего.Если к каждому значению переменной прибавить одно и то же число с, то среднее увеличится на это число (уменьшится на это число, если оно отрицательное):
 1 N
1 N
^(*,+O=-^-I>;+c) = Mx+c. (4.2)
А если каждое значение переменной умножить на одно и то же число с, то среднее увеличится в с раз (уменьшится в с раз, если делить на с):
 M(XrC)=^i(xrc)=Mx-c. (4.3)
M(XrC)=^i(xrc)=Mx-c. (4.3)
Далее мы неоднократно будем обращаться к такой величине, как отклонение от среднего: (*,•— Мх). Из первого, очевидного свойства среднего следует
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
еще одно важное свойство, не столь очевидное: сумма всех отклонений от среднего равна нулю:
£(*,.-Л/х) = 0. (4.4)
Соответственно, среднее отклонение от среднего также равно 0.
ВЫБОР МЕРЫ ЦЕНТРАЛЬНОЙ ТЕНДЕНЦИИ
Каждая мера центральной тенденции обладает характеристиками, которые делают ее ценной в определенных условиях.
Для номинативных данных, разумеется, единственной подходящей мерой центральной тенденции является мода, или модальная категория — та градация номинативной переменной, которая встречается наиболее часто.
Для порядковых и метрических переменных, распределение которых унимодальное и симметричное, мода, медиана и среднее совпадают. Чем больше отклонение от симметричности, тем больше расхождение между значениями этих мер центральной тенденции. По этому расхождению можно судить о том, насколько симметрично или асимметрично распределение.
Наиболее очевидной и часто используемой мерой центральной тенденции является среднее значение. Но его использование ограничивается тем, что на величину среднего влияет каждое отдельное значение. Если какое-нибудь значение в группе увеличится на с, то среднее увеличится на c/N. Таким образом, среднее значение весьма чувствительно к «выбросам» — экстремально малым или большим значениям переменной.
На величину моды и медианы величина каждого отдельного значения не влияет. Например, если в группе из 20 измерений переменной наибольшее значение утроится по величине, то не изменится ни мода, ни медиана. Величина среднего при этом заметно изменится. Иначе говоря, мода и медиана не чувствительны к «выбросам».

|
| Их средний доход -1000$ в месац... |
ПРИМЕР
 Если 9 человек имеют месячный доход от 5000 до 6000 рублей, со средним 5600 рублей, а доход десятого составляет 15000 рублей, то средний доход для этих 10 человек составит 6540 рублей. Эта цифра не позволяет судить о всей группе, и в качестве меры центральной тенденции следовало бы избрать медиану или моду.
Если 9 человек имеют месячный доход от 5000 до 6000 рублей, со средним 5600 рублей, а доход десятого составляет 15000 рублей, то средний доход для этих 10 человек составит 6540 рублей. Эта цифра не позволяет судить о всей группе, и в качестве меры центральной тенденции следовало бы избрать медиану или моду.
ГЛАВА 4. ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
Меры центральной тенденции чаще всего используются для сравнения групп по уровню выраженности признака. Если исследователь при этом сомневается, какую меру использовать, то можно дать простые советы.
Выборочные средние можно сравнивать, если выполняются следующие условия:
□ группы достаточно большие, чтобы судить о форме распределения;
□ распределения симметричны;
□ отсутствуют «выбросы».
Если хотя бы одно из перечисленных условий не выполняется, то следует ограничиться модой и медианой. Альтернативой является «сквозное» ранжирование представителей сравниваемых групп и сравнение средних, вычисленных для рангов этих групп.
КВАНТИЛИ РАСПРЕДЕЛЕНИЯ
Помимо мер центральной тенденции в психологии широко используются меры положения, которые называются квантилями распределения. Квантиль— это точка на числовой оси измеренного признака, которая делит всю совокупность упорядоченных измерений на две группы с известным соотношением их численности. С одним из квантилей мы уже знакомы — это медиана. Это значение признака, которое делит всю совокупность измерений на две группы с равной численностью. Кроме медианы часто используются про-центили и квартили.
Процентили(Percentiles) — это 99 точек — значений признака (Ри ..., Р99), которые делят упорядоченное (по возрастанию) множество наблюдений на 100 частей, равных по численности. Определение конкретного значения про-центиля аналогично определению медианы. Например, при определении 10-го процентиля, Р10, сначала все значения признака упорядочиваются по возрастанию. Затем отсчитывается 10% испытуемых, имеющих наименьшую выраженность признака. Р]а будет соответствовать тому значению признака, который отделяет эти 10% испытуемых от остальных 90%.
Квартили(Quartiles) — это 3 точки — значения признака (P2i, Pi0, P75), которые делят упорядоченное (по возрастанию) множество наблюдений на 4 равные по численности части. Первый квартиль соответствует 25-му проценти-лю, второй — 50-му процентилю или медиане, третий квартиль соответствует 75-му процентилю.
Процентили и квартили используются для определения частоты встречаемости тех или иных значений (или интервалов) измеренного признака или для выделения подгрупп и отдельных испытуемых, наиболее типичных или нетипичных для данного множества наблюдений.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
МЕРЫ ИЗМЕНЧИВОСТИ
Меры центральной тенденции отражают уровень выраженности измеренного признака. Однако не менее важной характеристикой является выраженность индивидуальных различий испытуемых по измеренному признаку. Меры изменчивости (Dispersion) применяются в психологии для численного выражения величины межиндивидуальной вариации признака.
Наиболее простой и очевидной мерой изменчивости является размах, указывающий на диапазон изменчивости значений. Размах (Range) — это просто разность максимального и минимального значений:
Ясно, что это очень неустойчивая мера изменчивости, на которую влияют любые возможные «выбросы». Более устойчивыми являются разновидности размаха: размах от 10 до 90-го процентиля (Р90 — Р10) или междуквартильный размах (Р75 — P2s)- Последние две меры изменчивости находят свое применение для описания вариации в порядковых данных. А для метрических данных используется дисперсия — величина, название которой в науке является синонимом изменчивости.
Дисперсия(Variance) — мера изменчивости для метрических данных, пропорциональная сумме квадратов отклонений измеренных значений от их арифметического среднего:
Чем больше изменчивость в данных, тем больше отклонения значений от среднего, тем больше величина дисперсии. Величина дисперсии получается
при усреднении всех квадратов отклонении:
N
N
(4.5)
Следует отличать теоретическую (генеральную) дисперсию — меру изменчивости бесконечного числа измерений (в генеральной совокупности, популяции в целом) и эмпирическую, или выборочную, дисперсию — для реально измеренного множества значений признака. Выборочное значение в статистике используется для оценки дисперсии в генеральной совокупности. Выше указана формула для генеральной (теоретической) дисперсии (Dx), которая, понятно, не вычисляется. Для вычислений используется формула выборочной (эмпирической) дисперсии (Dx), отличающаяся знаменателем:
N-X
(4.6)
ГЛАВА 4. ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
ПРИМЕР
 Вычислим дисперсию признакаХдля выборки N= 6:
Вычислим дисперсию признакаХдля выборки N= 6:
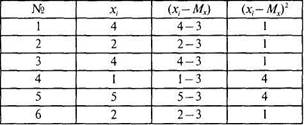
|

|
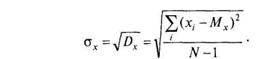
|

|
На практике чаще используется именно стандартное отклонение, а не дисперсия. Это связано с тем, что сигма выражает изменчивость в исходных единицах измерения признака, а дисперсия — в квадратах исходных единиц.
Свойства дисперсии:
1. Если значения измеренного признака не отличаются друг от друга (рав
ны между собой) — дисперсия равна нулю. Это соответствует отсутствию из
менчивости в данных.
2. Прибавление одного и того же числа к каждому значению переменной
не меняет дисперсию:
Dx + C = Dx, так как X [(*,■+с) - (Мх+с)]2 = Х(х,-- Мх)2.
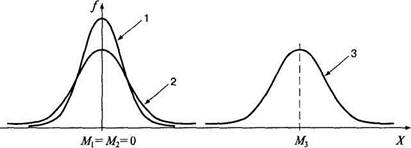
Рис. 4.1. Графики распределения частот: с разной дисперсией (D^Dj), одинаковой дисперсией (D2= D}) и разными средними арифметическими (М2<М1)
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
Прибавление константы к каждому значению переменной сдвигает график распределения этой переменной на эту константу (меняется среднее), но изменчивость (дисперсия) при этом остается неизменной.
3. Умножение каждого значения переменной на константу с изменяет дисперсию в с2 раз:

При объединении двух выборок с одинаковой дисперсией, но с разными средними значениями дисперсия увеличивается.
ПРИМЕР______________________________________________________________
Если одна группа содержит значения: 1,1,1,1, 1, а другая группа —значения 3,3, 3, 3, 3, то дисперсии этих групп одинаковы и равны 0. Если же объединить эти две группы, то дисперсия будет равна не 0, а 1.
Вообще говоря, справедливо утверждение: при объединении двух групп к внутригрупповой дисперсии каждой группы добавляется дисперсия, обусловленная различием между группами (их средними). И чем больше различие между средними значениями, тем больше увеличивается дисперсия объединенных групп.

|
Стандартизацияили z-преобразование данных — это перевод измерений в стандартную Z-шкалу (Z-scores) со средним Mz = О и Dz (или аг) = 1. Сначала для переменной, измеренной на выборке, вычисляют среднее Мх стандартное отклонение <зх. Затем все значения переменной х, пересчитываются по формуле:
(4.8)
В результате преобразованные значения (^-значения) непосредственно выражаются в единицах стандартного отклонения от среднего. Если для одной выборки несколько признаков переведены в ^-значения, появляется возможность сравнения уровня выраженности разных признаков у того или иного испытуемого. Для того чтобы избавиться от неизбежных отрицательных и дробных значений, можно перейти к любой другой известной шкале: IQ (среднее 100, сигма 15); Т-оценок (среднее 50, сигма 10); 10-балльной — стенов (среднее 5,5, сигма 2) и др. Перевод в новую шкалу осуществляется путем умножения каждого г-значения на заданную сигму и прибавления среднего:
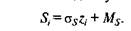 (4.9)
(4.9)
Асимметрия (Skewness) — степень отклонения графика распределения частот от симметричного вида относительно среднего значения. Если исходные данные переведены в ^-значения, показатель асимметрии вычисляется по формуле:
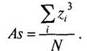 As = -
As = -
N
(4.10)

|

|
|

 X X
X X
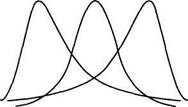
Рис.4.2. Распределения частот с разными значениями асимметрии и эксцесса
Для симметричного распределения асимметрия равна 0. Если чаще встречаются значения меньше среднего, то говорят о левосторонней, или положительной асимметрии (As > 0). Если же чаще встречаются значения больше среднего, то асимметрия — правосторонняя, или отрицательная (As<0). Чем больше отклонение от нуля, тем больше асимметрия.
Эксцесс(Kurtosis) — мера плосковершинности или остроконечности графика распределения измеренного признака. Если исходные данные переведены в ^-значения, показатель эксцесса определяется формулой:
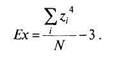 (4.11)
(4.11)
Островершинное распределение характеризуется положительным эксцессом (Ех > 0), а плосковершинное — отрицательным (-3 < Ех < 0). «Средневер-шинное» (нормальное) распределение имеет нулевой эксцесс (Ех = 0).
Задачи и упражнения
1. По результатам измерения общительности у юношей (1) и девушек (2)
были построены сглаженные графики распределения частот (рис. 4.3).
2. Определите по графику: а) как различаются средние Мх и М2; б) как раз
личаются дисперсии D{ и /)2?
3. Вычислите дисперсии для двух групп:

Какой будет дисперсия 8 значений, полученных путем объединения групп? Объясните полученный результат.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
– Конец работы –
Эта тема принадлежит разделу:
Математические методы психологического исследования. Анализ и интерпретация данных. Учебное пособие
Рецензенты В М А иахвердов доктор психологических наук профессор кафедры... общей психологии СПбГУ... В М Буре кандидат физико математических наук доцент факультета приклаnдной математики процессов управления...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: ПЕРВИЧНЫЕ ОПИСАТЕЛЬНЫЕ СТАТИСТИКИ
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.038 сек.
Новости и инфо для студентов