рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Психология
- /
- Психологии и Социальной Работы
Реферат Курсовая Конспект
Психологии и Социальной Работы
Психологии и Социальной Работы - раздел Психология, Санкт-Петербургский Государственный Институт...
Санкт-Петербургский Государственный Институт
Психологии и Социальной Работы
КАФЕДРА ОБЩЕЙ И ДИФФЕРЕНЦИАЛЬНОЙ ПСИХОЛОГИИ
Тютюнник Е. И., Раскин В.Н.
МАТЕМАТИЧЕСКИЕ МЕТОДЫ В ПСИХОЛОГИИ
Учебно-методическое пособие
Санкт-ПетербургАннотация
Учебно-методическое пособие составлено на основе требований государственного образовательного стандарта высшего профессионального образования по направлению подготовки 030300.62 «Психология» (квалификация (степень) «бакалавр»).
В пособии представлено содержание учебного материала по дисциплине «Математические методы в психологии», контрольные вопросы и список литературы, необходимой для усвоения учебного материала.
Пособие рассчитано не только на студентов психологических специальностей, но и на широкий круг практических психологов, а также специалистов смежных специальностей, занимающихся анализом результатов психологических исследований.
КРАТКОЕ ОГЛАВЛЕНИЕ
Введение. 8
Методические указания для студентов. 10
Контрольные вопросы для самостоятельной подготовки и самопроверки. 12
Глава 1. Описательная статистика. 14
1. 1. Математическая статистика и психология. Измерения в психологии и виды шкал 14
1. 2. Описание результатов исследования. 26
1. 3. Параметры статистических совокупностей. 36
1. 4. Характеристики взаимосвязи признаков. 61
Глава 2. Индуктивная статистика. 80
2. 1. Решение задачи сравнения выборок. Понятие статистических критериев и их виды 80
2. 2. Выявление различий в уровне исследуемого признака. 93
2. 3. Оценка достоверности сдвига в значениях исследуемого признака. 102
2. 4. Выявление различий в распределении признака. 108
2. 5. Многофункциональные статистические критерии. 111
2. 6. Дисперсионный анализ. 118
2. 7. Многомерные методы обработки данных. 124
Список литературы.. 139
Приложение 1. Статистические таблицы с критическими значениями. 141
Приложение 2. Глоссарий. 160
Приложение 3. Англо-русский словарь статистических терминов. 166
ОГЛАВЛЕНИЕ
Введение. 8
Методические указания для студентов. 10
Контрольные вопросы для самостоятельной подготовки и самопроверки. 12
Глава 1. Описательная статистика. 14
1. 1. Математическая статистика и психология. Измерения в психологии и виды шкал 14
Типы измерений и измерительные шкалы.. 19
Этапы обработки результатов психологического исследования. 25
1. 2. Описание результатов исследования. 26
Табличный способ представления результатов исследования. 27
Графический способ. 29
Алгоритм построения сгруппированного (или табулированного) ряда. 31
Параметрический способ представления результатов исследования. 33
Общий обзор параметров распределений. 34
1. 3. Параметры статистических совокупностей. 36
Мода. 37
Квантили. 38
Медиана. 38
Среднее арифметическое значение. 42
Среднее геометрическое значение. 43
Дисперсия. 44
Стандартное отклонение. 45
Коэффициент асимметрии. 46
Коэффициент эксцесса. 47
Коэффициент вариации. 48
Исключение выскакивающих значений. 49
Нормальный закон распределения и другие виды распределений. 51
Проверка «нормальности» эмпирического распределения. 54
Стандартизация данных и стандартизованные шкалы в психологии. 56
1. 4. Характеристики взаимосвязи признаков. 61
Понятие статистической зависимости. 61
Общий обзор мер связи. 64
Коэффициент контингенции. 64
Критерий «хи-квадрат» Пирсона. 65
Ранжирование. 68
Рангово-бисериальный коэффициент корреляции. 69
Бисериальный коэффициент корреляции. 70
Коэффициент взаимной сопряженности Чупрова. 71
Коэффициент взаимной сопряженности Пирсона. 72
Ранговой коэффициент корреляции Спирмена. 73
Коэффициент линейной корреляции Пирсона. 75
Корреляционное отношение. 77
Глава 2. Индуктивная статистика. 80
2. 1. Решение задачи сравнения выборок. Понятие статистических критериев и их виды 80
Статистические гипотезы.. 80
Уровень статистической значимости. 82
Этапы принятия статистического решения. 85
Классификация исследовательских задач, решаемых с помощью статистических методов. 86
Решение задачи сравнения выборок. 87
Обзор наиболее часто применяемых параметрических критериев. 90
Общий обзор непараметрических критериев. 90
2. 2. Выявление различий в уровне исследуемого признака. 93
Параметрический критерий Стьюдента для сравнения независимых выборок 94
Поправка Снедекора. 97
Правило принятия решения описано выше. 97
Непараметрический критерий Розенбаума (критерий «хвостов») 97
Непараметрический критерий Манна-Уитни. 99
2. 3. Оценка достоверности сдвига в значениях исследуемого признака. 102
Параметрический критерий Стьюдента для сравнения зависимых выборок 103
Непараметрический критерий знаков. 104
Непараметрический критерий Вилкоксона. 106
2. 4. Выявление различий в распределении признака. 108
Критерий «хи-квадрат» Пирсона. 108
Критерий Колмогорова-Смирнова. 108
2. 5. Многофункциональные статистические критерии. 111
Критерий φ* — «Угловое преобразование» Фишера. 112
Критерий Макнамары.. 115
2. 6. Дисперсионный анализ. 118
Введение в дисперсионный анализ ANOVA.. 118
Однофакторный дисперсионный анализ. 119
2. 7. Многомерные методы обработки данных. 124
Множественный регрессионный анализ. 127
Дискриминантный анализ («классификация с обучением») 128
Кластерный анализ («классификация без обучения») 128
Многомерное шкалирование. 128
Факторный анализ. 128
Компьютерные пакеты прикладных статистических программ. 138
Список литературы.. 139
Приложение 1. Статистические таблицы с критическими значениями. 141
1.1. Критические значения отношения для исключения выскакивающих значений 141
1.2. Критические значения коэффициента ранговой корреляции Спирмена 142
1.3. Критические значения коэффициента линейной корреляции Пирсона 143
1.4. Критические значения критерия хи-квадрат Пирсона. 144
1.5. Критические значения критерия Стьюдента. 145
1.6. Критические значения критерия Фишера. 146
1.7. Критические значения непараметрического критерия Манна-Уитни. 148
1.8. Критические значения непараметрического критерия Вилкоксона. 154
1.9. Таблицы для перевода процентных долей в величины центрального угла для расчета критерия «угловое преобразование» Фишера. 155
1.10. Таблица вероятностей Р для биномиального распределения при р = q = 0,5 159
Приложение 2. Глоссарий. 160
Приложение 3. Англо-русский словарь статистических терминов. 166
Введение
Цели и задачи изучения дисциплины «Математические методы в психологии» и сфера профессионального использования
Психологу в своей научной и практической работе постоянно приходится отбирать, классифицировать и упорядочивать те конкретные результаты, которые он… Одно из достижений отечественной науки последних десятилетий — широкое… Главная цель изучения учебной дисциплины "Математические методы в психологии" — сформировать у студентов…Методические указания для студентов
· Важно учитывать, что данная дисциплина является базовой для профессионала-психолога. Полученные в ходе её изучения знания необходимы для анализа… · Студенту предлагается внимательно прочитать лекционные материалы, каждая…Контрольные вопросы для самостоятельной подготовки и самопроверки
1. Приведите определение случайного события.
2. Почему результаты психологических исследований считаются случайными событиями?
3. Придумайте примеры для каждой измерительной шкалы. Обоснуйте свое мнение.
4. В каких случаях предпочтительнее пользоваться относительными частотами?
5. В каких случаях чаще всего пользуются процентными частотами?
6. Что такое вариационный ряд?
7. В каких случаях результаты целесообразно представлять в виде сгруппированного распределения?
8. Что отражают меры положения?
9. О чем свидетельствует такой параметр как мода?
10. О чем свидетельствует такой параметр как медиана?
11. О чем свидетельствуют такие параметры как процентили?
12. О чем свидетельствует такой параметр как среднее арифметическое значение?
13. О чем свидетельствует такой параметр как среднее геометрическое значение?
14. О чем свидетельствует такой параметр как среднее гармоническое значение?
15. Что отражают меры изменчивости?
16. О чем свидетельствует такой параметр как дисперсия?
17. О чем свидетельствует такой параметр как стандартное отклонение?
18. О чем свидетельствуют такие параметры как коэффициент асимметрии?
19. О чем свидетельствует такой параметр как коэффициент эксцесса?
20. О чем свидетельствует такой параметр как коэффициент вариации?
21. Проанализируйте какой-либо график дифференциального распределения.
22. Что такое нормальный закон распределения?
23. Чему равна статистическая норма в психодиагностических методиках?
24. Что такое Z-показатели?
25. Каковы основные параметры Z-распределения?
26. Почему необходимо преобразовывать Z-распределение и нормировать Z-показатели?
27. Приведите формулы основных стандартизованных шкал в психодиагностических методиках.
28. В каких случаях необходимо проверять исходные данные на наличие в них выскакивающих значений?
29. Что такое стохастическая зависимость?
30. Какими свойствами обладают связи между признаками?
31. Приведите общее правило вывода при оценке взаимозависимостей между признаками.
32. Какая мера связи пригодна для оценки зависимостей между признаками, измеренными по шкале наименований?
33. Какая мера связи пригодна для оценки зависимостей между признаками, измеренными по шкале наименований и шкале порядка?
34. Какая мера связи пригодна для оценки зависимостей между признаками, измеренными по шкале наименований и какой-либо количественной шкале (интервальной или пропорциональной)?
35. Какая мера связи пригодна для оценки зависимостей между признаками, измеренными по шкале порядка?
36. Какая мера связи пригодна для оценки зависимостей между признаками, измеренными по шкале порядка и какой-либо количественной шкале (интервальной или пропорциональной)?
37. Какая мера связи пригодна для оценки зависимостей между признаками, измеренными по шкале какой-либо количественной шкале (интервальной или пропорциональной)?
38. В каком случае более адекватной мерой является корреляционное отношение и для каких шкал оно применяется?
39. Что такое корреляционная плеяда?
40. Что такое критерий различий?
41. Приведите классификацию критериев различий.
42. В чем различие между односторонними и двусторонними критериями?
43. Какова сущность дисперсионного анализа?
44. Приведите классификации многомерных методов исследования.
45. Какова основная задача и условия применения множественного регрессионного анализа?
46. Какова основная задача и условия применения кластерного анализа?
47. Какова основная задача и условия применения дискриминантного анализа?
48. Какова основная задача и условия применения факторного анализа?
49. Какова основная задача и условия применения многомерного шкалирования?
50. Какие метрики используются в основных методах кластерного анализа и многомерного шкалирования?
Глава 1. Описательная статистика
Математическая статистика и психология. Измерения в психологии и виды шкал
Методические рекомендации к изучению темы
Особое внимание следует обратить на измерительные шкалы, так как весь дальнейший аппарат математической статистики будет «привязан» к типам… После изучения материала лекции ответьте на контрольные вопросы, ответы…Материалы лекции.
Математическая статистика занимается математическим описанием случайных явлений, т. е. построением вероятностных моделей, а также проверкой их… Статистика появилась более ста лет назад. Бельгийский математик Адольф Кетле… Результаты, полученные А. Кетле, произвели огромное впечатление на Френсиса Гальтона (1822-1911 г.), который во 2-й…Типы измерений и измерительные шкалы
Измерение — приписывание числовых форм объектам или событиям в соответствии с определенными правилами (Стивенс, 1960 г.). На рисунке 1 приведена схема, в которой отражены типы измерений, методы,… При измерении методом регистрации правила измерения таковы, что они позволяют лишь установить, что один объект…Результаты, полученные тем или иным методом измерения, допускают различные математические процедуры. Обработка этих результатов зависит от того, по какой шкале были измерены психологические признаки. Поэтому прежде чем приступать к обработке и выбору процедур математико-статистического анализа данных, необходимо ответить себе на вопрос — по какой шкале были измерены данные признаки.
Генеральная совокупность и выборочное исследование. Статистическая достоверность
Исследование обычно начинается с некоторого предположения, требующего проверки с привлечением фактов. Это предположение — гипотеза — формулируется… Для проверки подобных предположений на фактах необходимо измерить… Генеральная совокупность— это все множество объектов, в отношении которого формулируется исследовательская…Этапы обработки результатов психологического исследования
Таблица 1 № п/п Испы-туемый Психологические признаки Возраст Пол Агрессив-ность … С составления такой таблицы исходных данных начинается работа в любом пакете статистического анализа на компьютере. …Описание результатов исследования
Методические рекомендации к изучению темы
После изучения материала лекции ответьте на контрольные вопросы, ответы занесите в конспект.Материалы лекции.
Случайное событие— событие, которое в основных условиях иногда происходит, а иногда нет, и при этом в каждый данный момент невозможно предугадать… Случайная величина— переменная, которая может принимать значения из… Вариацияxi — отдельное значение случайной величины. В исходную матрицу первичных данных записываются вариации по…Результаты исследования экстраверсии
На практике исследователь пользуется какой-либо одной частотой (при необходимости — несколькими). Какие именно частоты выбрать для построения… - Если выборка небольшого объема, то можно использовать абсолютные частоты.… - Если в исследовании сравнивается несколько выборок разного объема (имеют разное количество испытуемых), то…Алгоритм построения сгруппированного (или табулированного) ряда
I. Определение размаха выборки: R= xmax – xmin II. Выбор количества разрядов kПример.
Ученикам начальной школы (38 человек) был предложен тест для проверки скорости чтения. Были получены следующие оценки скорости чтения (количество слов за минуту):
90 66 106 84 105 83 104 82 97 97 59 95 78 70 47 95 100 69 44 80 75 75 51 109 89 58 59 72 74 75 81 71 68 112 62 91 93 84
Результаты расчетов:
R= xmax – xmin = 112 – 44 = 68
Пусть k = 8 Тогда 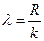
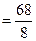 =8,5 ≈ 9
=8,5 ≈ 9
Пусть начало первого интервала будет x01=41.
Тогда верхняя граница первого интервала будет x1=41+(9-1)=49
Начало второго интервала на 1 балл больше, то есть x02=50.
Верхняя граница второго интервала x2=50+(9-1)=58. И так далее…
Таблица 5
| № п/п | Xi (начало и конец интервалов) | fi | Fi |
| 104—112 | |||
| 95—103 | |||
| 86—94 | |||
| 77—85 | |||
| 68—76 | |||
| 59—67 | |||
| 50—58 | |||
| 41—49 | |||
| S=38 |
Построим на основании этого примера графики — полигоны частот и гистограммы дифференциального и интегрального распределений (рис. 6-9).
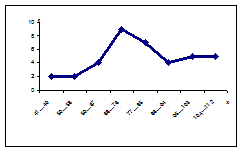 Рис. 6. Полигон частот дифференциального распределения
Рис. 6. Полигон частот дифференциального распределения
| 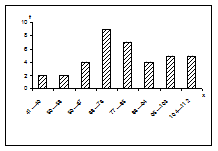 Рис. 7. Гистограмма дифференциального распределения
Рис. 7. Гистограмма дифференциального распределения
|
 Рис.8. Полигон частот интегрального распределения
Рис.8. Полигон частот интегрального распределения
|  Рис. 9. Гистограмма интегрального распределения
Рис. 9. Гистограмма интегрального распределения
|
Параметрический способ представления результатов исследования — это описание результатов, полученных на выборке с помощью параметров распределений.
Параметры распределений — это числовые характеристики, которые отражают основные тенденции выраженности и изменчивости признака в данной выборке.
Существуют две группы параметров: меры положения или меры центральной тенденции, отражающие выраженность признака, и меры изменчивости или меры рассеивания, характеризующие изменчивость признака. Выбор параметров, с помощью которых будут описываться результаты исследования, зависит, во-первых, от того, по какой шкале измерен данный признак, и, во-вторых, от исследовательских задач.
Для облегчения принятия решения о выборе параметров следует воспользоваться таблицей 6.
Таблица 6
Общий обзор параметров распределений
Контрольные вопросы для самопроверки: 1. Приведите определение случайного события. 2. Почему результаты психологических исследований считаются случайными событиями?Параметры статистических совокупностей
Методические рекомендации к изучению темы
При изучении темы следует обратить особое внимание на вычисление медианы по формуле, а именно как найти медиальный интервал и фактическое нижнее… Исключение выскакивающих значений целесообразно проводить только в выборках… Обратите внимание на распространенность нормального распределения.Материалы лекции.
В шкале наименований отдельные качества свойства, которые регистрируются у измеряемых объектов, могут быть обозначены словами, какими-либо символами… В качестве меры положения используется только один параметр, который носит… Мода (Mode) — Мо — это значение признака, которое имеет наибольшую частоту. Для того чтобы найти моду, необходимо…Результаты исследования экстраверсии
В данном примере Мо=12, так как именно этому значению признака соответствует наибольшая частота f=6. В предыдущей теме был рассмотрен пример построения сгруппированного… Таблица 5 № п/п Xi (начало и конец интервалов) fi Fi …Меры изменчивости, или меры рассеивания
А) при небольшом количестве испытуемых , гдеРассмотрим пример расчета параметров для сгруппированного распределения.
Таблица 9
| № п/п | Xi (начало и конец интервалов) | fi | Fi | Xср i |

|

|
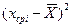
|
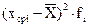
|
| 104—112 | 108×5=540 | 108–80,5=27,5 | 27,52=756,25 | 756,25×5=3781,25 | ||||
| 95—103 | 99×5=495 | 99–80,5=18,5 | 18,52=342,25 | 342,25×5=1711,25 | ||||
| 86—94 | 90×4=360 | 90-80,5=9,5 | 9,52=90,25 | 90,25×4=361,00 | ||||
| 77—85 | 81×7=567 | 81–80,5=0,5 | 0,52=0,25 | 0,25×7=1,75 | ||||
| 68—76 | 72×9=648 | 72–80,5= –8,5 | (–8,5) 2=72,25 | 72,25×9=650,25 | ||||
| 59—67 | 63×4=252 | 63–80,5= –17,5 | (–17,5) 2=306,25 | 306,25×4=1225,00 | ||||
| 50—58 | 54×2=108 | 54–80,5= –26,5 | (–26,5) 2=702,25 | 702,25×2=1404,50 | ||||
| 41—49 | 45×2=90 | 45–80,5= –35,5 | (–35,5)2=1260,25 | 1260,25×2=2520,50 | ||||
| S=38 | S=3060 | S=11655,50 |
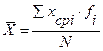 =
= =80,5
=80,5
 =
=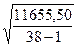 =17,7
=17,7
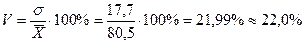
Исключение выскакивающих значений
Выскакивающими называются крайние значения (максимальные или минимальные), далеко отстоящие от ближайших к ним значений.
Способ проверки крайних значений «на выскакивание» основан на оценке соотношения «расстояния» крайних значений (вариант) и ближайших к ним и размаха всех значений.
Данный способ проверки описан в книге: Ашмарин И. В., Воробьев А. А. Статистические методы в микробиологических исследованиях. — Л., 1962.
Проверка на выскакивание наибольшего значения
где xn — наибольшее значение, которое подозревается в выскакивании; xn-1 — значение, следующее за наибольшим в сторону убывания;Проверка на выскакивание наименьшего значения
где xn — наибольшее значение x2 — значение, следующее за наименьшим в сторону возрастанияНормальный закон распределения и другие виды распределений
|
Нормальный закон распределения
Нормальный закон[4] распределения во всех естественных науках имеет… Самой общей характеристикой нормального распределения является простое наблюдение того закономерного факта, что очень…Гамма-распределение
Рис. 15. Гамма-распределение Гамма-распределение находит в психологии все более широкое применение…Экспоненциальное распределение
Экспоненциальное распределение обладает следующими свойствами: 1) крайняя асимметрия частостей; 2) равенство среднего арифметического и стандартного отклонения.
Наиболее широко экспоненциальный закон распределения используется в психологических приложениях теории надежности и теории массового обслуживания. В частности ему следует распределение времени между различными ошибочными действиями человека, выполняющего некоторую работу.
Биномиальное распределение
В психологии биномиальное распределение используется всегда, когда требуется определить априорную вероятность появления изучаемого события в серии…Проверка «нормальности» эмпирического распределения
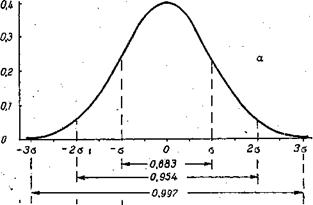
Чтобы установить является ли эмпирическое распределение изучаемой случайной величины нормальным, необходимо сопоставить сведения о свойствах этой… Основой качественного сопоставления служит основное "физическое"… Если такое условие имеет место, то можно ожидать, что изучаемая случайная величина распределена нормально. Например,…Стандартизация данных и стандартизованные шкалы в психологии
При условии нормального распределения первичных данных приведение различных методик к единой шкале осуществляется путем построения шкалы стандартных… где zi — стандартизованная величина для xiТест Векслера
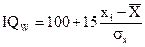
Тест Амтхауэра
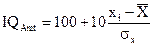
Шкала стенов Кеттелла (например, опросники 16 PF Кеттелла, МИС. УСК и т. п.)

Шкала стенайнов Гилфорда
Шкала Т-баллов (например, опросники MMPI, CPI, САТ, ГТ и т. п.) В руководстве по конструированию тестов, принятом Американской психологической ассоциацией, указывается, что типичным…Процентильные нормы для детей 5;5 – 11 лет
Примечание: в ячейках таблицы — общее количество баллов по тесту, полученное испытуемым Таблица 11 Процентили Уровни Интерпретация 95 и выше I Очень…Характеристики взаимосвязи признаков
Методические рекомендации к изучению темы
При работе с алгоритмами мер связи внимательно изучите возможные ограничения в применении и все шаги алгоритма. После изучения материала лекции ответьте на контрольные вопросы, решите…Материалы лекции.
Понятие статистической зависимости
Зависимость (взаимосвязь) между случайными событиями состоит в том, что появление одного из событий изменяет вероятность появления другого… Факт взаимосвязи между случайными событиями состоит в совместном изменении… Например, у некоторой группы людей измерялись два признака. Признак xi, который может принимать одно из четырех…Общий обзор мер связи
Коэффициент контингенции
Если оба признака измерены по шкале наименований и каждый из них может иметь только два значения, то мерой связи является коэффициент контингенции… Удобнее всего этот коэффициент рассчитывать по 4-хпольной таблице… Таблица 14 Значения признаков X1 = 0 X2 = 1 Σ Y1 = 0 f00 =…Критерий «хи-квадрат» Пирсона
Назначения критерия
Критерий χ2 применяется в двух целях;
1) для сопоставления эмпирического распределения признака с теоретическим (равномерным, нормальным или каким-то иным);
2) для сопоставления двух, трех или более эмпирических распределений одного и того же признака, то есть для проверки их однородности;
3) для оценки стохастической (вероятностной) независимости в системе случайных событий;
и т.д.
Описание критерия
Преимущество метода состоит в том, что он позволяет сопоставлять распределения признаков, представленных в любой шкале, начиная от шкалы…Ограничения критерия
2. Теоретическая частота для каждой ячейки таблицы не должна быть меньше 5: f ≥ 5. Это означает, что если число разрядов задано заранее и не… 3. Выбранные разряды должны "вычерпывать" все распределение, то есть… 4. Необходимо вносить "поправку на непрерывность" при сопоставлении распределений признаков, которые…Прежде чем рассматривать меры связи дальше, необходимо освоить такую процедуру как ранжирование.
Ранжирование
Ранжирование — это процедура, при которой значения признака заменяются рангами.
Ранг — это порядковое место значения в упорядоченном ряду всех значений.
Правила ранжирования
Если, например, N=7, то наибольшее значение получит ранг 7 (за исключением тех случаев, которые описаны правилом 2). 2. В случае, если несколько значений равны, им начисляется ранг,… Например, три наименьших значения равны 15 секундам. Следующее значение в ряду значений равно 17 секундам. Первые три…Бисериальные коэффициенты корреляции
Рангово-бисериальный коэффициент корреляции используется в том случае, когда второй признак измерен по шкале порядка. Расчет этого коэффициента производится по формуле:Коэффициент взаимной сопряженности Чупрова
Этот коэффициент рассчитывается с помощью критерия хи-квадрат Пирсона, расчетное значение которого подставляется в формулу: при k≠m, где k — число градаций одного признака, m — число градаций…Коэффициент взаимной сопряженности Пирсона
Этот коэффициент также рассчитывается с помощью критерия хи-квадрат Пирсона, расчетное значение которого подставляется в формулу: , где N — общий объем выборки.Ранговой коэффициент корреляции Спирмена
Метод ранговой корреляции Спирмена позволяет определить тесноту (силу) и направление корреляционной связи между двумя признаками или двумя… Для подсчета коэффициента ранговой корреляции ранговой корреляции… 1) два признака, измеренные в одной и той же группе испытуемых;Ограничения коэффициента ранговой корреляции
2. Коэффициент ранговой корреляции Спирмена при большом количестве одинаковых рангов по одной или обеим сопоставляемым переменным дает…Алгоритм расчета ранговой корреляции Спирмена
Таблица 20 № п/п X1 X2 R X1 R X2 di di2 1 2 3 4 5 … Заполнить в таблице столбцы 2 и 3 первичными данными. 2. Проранжировать значения переменной 1, начисляя ранг 1 наименьшему значению, в соответствии с правилами…Коэффициент линейной корреляции Пирсона
Коэффициент линейной корреляции Пирсона также может изменяться от –1,00 до +1,00. Знак указывает на направление взаимосвязи, а абсолютное значение… Коэффициент корреляции Пирсона рассчитывается по следующей формуле:Алгоритм расчета коэффициента линейной корреляции Пирсона
2. Для дальнейших расчетов целесообразно воспользоваться таблицей следующего вида: Таблица 21 № xi yi xi– yi– … В столбцы 2 и 3 занесены первичные данные.Рассчитайте поправки для различных случаев связанных рангов: а=2; а=3; а=4; а=5 и а=6.
Таблица 24 Черты личности Мать Сын Застреваемость Педантичность … Материалы для изучения:Решение задачи сравнения выборок. Понятие статистических критериев и их виды
Методические рекомендации к изучению темы
Особое внимание следует обратить на следующий материал: статистическая значимость, число степеней свободы, классификация критериев различий и… После изучения материала лекции ответьте на контрольные вопросы и выполните…Материалы лекции.
Статистические гипотезы
Подчеркнем еще раз, что полученные в результате эксперимента на какой-либо выборке данные служат основанием для суждения о генеральной совокупности.… Как указывает Г.В. Суходольский: «Под статистической гипотезой обычно понимают… Сущность проверки статистической гипотезы заключается в том, чтобы установить, согласуются ли экспериментальные данные…Уровень статистической значимости
Исторически сложилось так, что в прикладных науках, использующих статистику, и в частности в психологии, считается, что низшим уровнем… Величины 0,05, 0,01 и 0,001 — это так называемые стандартные уровни… Заметим, что в современных статистических пакетах на ЭВМ используются не стандартные уровни значимости, а уровни,…Этапы принятия статистического решения
1.Формулировка нулевой и альтернативной гипотез. 2.Определение объема выборки N. 3.Выбор соответствующего уровня значимости или вероятности отклонения нулевой гипотезы. Это может быть величина…Классификация исследовательских задач, решаемых с помощью статистических методов
Подчеркнем еще раз, что, прежде чем выполнить любой психологический эксперимент, необходимо четко сформулировать его задачи, определить экспериментальную гипотезу и все этапы её статистической проверки, а также выбрать соответствующий статистический метод, наиболее эффективный для решения поставленных в исследовании задач.
Подавляющее большинство задач, решаемых психологом в эксперименте, предполагает те или иные сопоставления. Это могут быть сопоставления одних и тех же показателей в разных группах испытуемых или, напротив, разных показателей в одной и той же группе. Для определения степени эффективности каких-либо воздействий (обучение, тренировка, тренинг, психотерапия и т.п.) сравниваются показатели «до» и «после» этих воздействий. Например, сравниваются показатели уровня тревожности у подростков до и после психотренинга, что позволяет определить его эффективность. Или в лонгитюдном исследовании сопоставляются результаты у одних и тех же испытуемых по одним и тем же методикам, но в разном возрасте, что позволяет выявить временную динамику анализируемых показателей. Иногда возникает задача сравнить индивидуальные показатели, полученные при различных внешних условиях, для выявления связи между показателями и факторов, объединяющих эти связи.
Два выборочных распределения сравниваются между собой или с теоретическим законом распределения, чтобы выявить различия или, напротив, сходство в типах распределений. Например, сравнение распределений времени решения простой и сложных задач позволит построить классификацию задач и типологию испытуемых.
В общем, психологические задачи, решаемые с помощью методов математической статистики, условно можно разделить на несколько групп.
1. Задачи, требующие описать в целом результаты, полученные на выборке или в генеральной совокупности.
2. Задачи, требующие установления зависимости между признаками.
3. Задачи, требующие установления сходства или различия.
4. Задачи, требующие группировки и классификации данных.
5. Задачи, ставящие целью анализ источников вариативности получаемых психологических признаков.
6. Задачи, предполагающие возможность прогноза на основе имеющихся данных.
Эта неполная классификация носит предварительный характер. По мере ознакомления с методами математической статистики, излагаемыми в курсе, вы получите более детальное представление о типологии задач и главное — методов, которые могут быть адекватно использованы для их решения. С методами решения первой задачи вы уже познакомились в теме, посвященной анализу взаимосвязей между признаками.
Решение задачи сравнения выборок
Для решения задачи сравнения выборок пользуются статистическими критериями. Критерий вообще — это решающее правило, обусловливающее поведение в ситуации выбора. Статистическим критерием называется правило, обеспечивающее надежное поведение, т. е. принятие истинной и отклонение ложной гипотезы с высокой вероятностью. Слова статистический критерий обозначают также метод расчета определенного числа и само это число.
Критерии делятся на параметрические и непараметрические; односторонние и двусторонние.
При направленной статистической гипотезе используется односторонний критерий, при ненаправленной гипотезе — двусторонний критерий. Двусторонний критерий более строг, поскольку он проверяет различия в обе стороны, и поэтому то эмпирическое значение критерия, которое ранее соответствовало уровню значимости 0,05, теперь соответствует лишь уровню 0,10.
Этапы принятия решения для статистических критериев одни и те же: эмпирическое (или расчетное) значение критерия сравнивается с критическим значением и делается вывод. По их соотношению мы можем судить, подтверждается или опровергается нулевая гипотеза. Каким именно должно быть это соотношение, указывается в правиле принятия решения (правиле вывода) этого критерия. Обратите внимания на то, что для одних критериев для принятия альтернативной гипотезы и отклонения нулевой гипотезы необходимо, чтобы Чэмп≥Чкр; для других критериев — Чэмп≤Чкр.
В большинстве случаев критические значения критерия находятся по соответствующим таблицам критических значений в зависимости от числа наблюдений (объема выборки) N. Однако есть критерии (например, критерий хи-квадрат Пирсона или критерий Стьюдента), для которых критическое значение находится в зависимости от так называемого числа степеней свободы, которое обозначается, как правило, буквой «ню»: ν.
Число степеней свободы νили df равно числу классов вариационного ряда минус число условий, при которых он был сформирован, иначе: количество возможных направлений изменчивости переменной. Это понятие можно пояснить на простом примере. Пусть у нас имеется уравнение х1+х2+х3=10. Данная сумма может получаться при различных значениях переменных, например, 2+5+3=10; 3+3+4=10;1+0+9=10; +6+7–3=10 и т.п. Два слагаемых могут быть любыми числами, а последнее должно дополнять сумму первых двух до десяти, то есть оно является не свободным, а «связанным». Таким образом, возможное число изменений равно двум, а в общем случае для N слагаемых это число равно N–1.
Если признак измерен по шкале наименований, например, определялся тип темперамента людей (число градаций значений признака или классов равно 4-м). В первые три класса может войти любое количество испытуемых, а в последний класс должно войти столько, сколько будет дополнять общее количество испытуемых в первых трех группах до общего объема выборки N.
В общем случае можно сказать, что число степеней свободы определяется как число объектов в выборке, число классов или интервалов квантования за вычетом количества характеристик, определяющих переменную. Так, например, сумма определяется только одной характеристикой — числом слагаемых; признак, измеренный по шкале наименований, также одной — числом значений признака (числом градаций или классов); признак, измеренный в интервальной шкале и имеющий нормальное распределение, определяется числом интервалов квантования, средним арифметическим и стандартным отклонением.
Для каждого случая (статистического критерия) определение числа степеней свободы имеет свою специфику. Поэтому в каждом алгоритме расчета критерия указывается правило (формула) для определения числа степеней свободы.
Параметрические критериислужат для проверки гипотез о параметрах распределений или для их оценивания (т. е. является ли параметр, полученный на выборке испытуемых, и параметром генеральной совокупности). Они включают в формулу расчета параметры распределения (например, критерий Стьюдента, критерий Фишера и др.). Для их расчета необходимо прежде подсчитать параметры распределения. Параметрические критерии применяются сравнения параметров признаков, измеренных по количественной шкале (интервальной или пропорциональной) при условии нормального распределения признака.
Непараметрические критерии —критерии, не включающие в формулу расчета параметры распределения и основанные на оперировании частотами или рангами (например, критерий знаков, критерий Ван-дер-Вардена и др.). Непараметрические критерии применяются для сравнения признаков измеренных в основном по шкалам порядка, интервальным или пропорциональным; некоторые критерии могут применяться даже в шкале наименований. Непараметрические критерии безразличны к форме распределения признака, они не требуют нормального распределения.
Под мощностью критерияпонимается его способность правильно отбрасывать ложную гипотезу. Она определяется эмпирическим путем. При этом оказывается, что одни и те же задачи могут быть решены с помощью разных критериев; при этом обнаруживается, что некоторые критерии позволяют выявить различия там, где другие оказываются неспособными это сделать, или выявляют более высокий уровень значимости различий.
Основанием выбора критерия может быть не толькомощность, но и другие его характеристики:
а) простота расчетов;
б) более широкий диапазон использования (например, по отношению к данным, измеренным по шкале наименований, или по отношению к большим N);
в) применимость по отношению к неравным объемам выборки;
г) большая информативность результатов.
Кроме этого, необходимо учитывать, с какого вида выборками мы имеем дело в данном исследовании.
Выборки бывают двух видов: независимые и зависимые.
Независимые выборки (не связанные выборки) — это две выборки, составленные из разных людей, у которых были измерены одни и те же признаки по одним и тем же методикам, например, экспериментальная и контрольная группы, женщины и мужчины, здоровые и больные, 9а и 9б классы и т.п.
Зависимые выборки (связанные выборки) — это одна и та же группа людей, у которых были измерены одни и те же признаки в двух (или более) различных ситуациях, например, «до — после», «фон — стресс».
Для того, чтобы выбрать критерий различий, необходимо ответить себе на три или четыре вопроса:
По какой шкале измерен признак?
Если признак измерен по шкале наименований или шкале порядка, то выбирается непараметрический критерий. Если признак измерен по интервальной или пропорциональной шкале, то выбор критерия зависит от ответа на второй вопрос.
Является ли распределение признака нормальным?
Если признак измерен по интервальной и пропорциональной шкале и его распределение можно считать нормальным, то выбирается параметрический критерий. При ненормальном распределении должен быть выбран непараметрический критерий.
С какого вида выборками имеем дело в данном исследовании?
Для сравнения зависимых выборок выбираются одни критерии, для независимых — другие (или в случае параметрических критериев различаются алгоритмы их расчета).
Каковы ограничения в применении критерия?
Обращаю внимание, что ответ на 2-й вопрос необходим только, если признак измерен по интервальной или пропорциональной шкале.
При выборе критериев сравнения целесообразно воспользоваться обзорными таблицами (таблицы 26 и 27) для параметрических и непараметрических критериев.
Таблица 26
Обзор наиболее часто применяемых параметрических критериев
Таблица 27Общий обзор непараметрических критериев
Контрольные вопросы: 1. Что такое статистическая гипотеза?Выявление различий в уровне исследуемого признака
Методические рекомендации к изучению темы
После изучения материала лекции ответьте на контрольные вопросы, ответы занесите в конспект.Материалы лекции.
Параметрический критерий Стьюдента для сравнения независимых выборок
Назначение критерия
А) для сравнения любых двух параметров распределений или проверки гипотез о случайности различий между параметрами (Н0); Б) для интервального оценивания (является ли параметр, полученный на… В) для оценки статистической значимости мер связи (коэффициентов корреляции).Назначение критерия
а) для сравнения двух дисперсий; б) для проверки гипотезы о значимости коэффициентов детерминации; в) для проверки гипотезы об однородности ряда средних арифметических значений.Статистически значимое различие дисперсий указывает на то, что генеральные совокупности, из которых взяты выборки, также имеют разные дисперсии. В этом случае рекомендуется при сравнении средних арифметических значений с помощью критерия Стьюдента вводить в критерий поправку по Снедекору.
Поправка Снедекора
Если сравниваются выборки равного объема, то есть N1= N2=N, то табличное значение находят для числа степеней свободы, вычисленное по формуле: ν… Если сравниваются выборки разного объема, то вычисляют среде взвешенное… Для каждой из выборок находят свое число степеней свободы по формулам: ν1 = N1 – 1 и ν2 = N2 – 1.Правило принятия решения описано выше.
Непараметрический критерий Розенбаума (критерий «хвостов»)
Назначение критерия
Этот метод сравнивает два ряда упорядоченных значений и определяет, достаточно ли сильно они различаются или насколько велика область значений в… Чем больше область неперекрещивающихся значений (чем больше «хвосты»), тем… Расчетное (эмпирическое) значение критерия Q отражает то, насколько велика зона совпадения между рядами. Поэтому чем…Ограничения критерия
2. Выборки должны быть независимыми. 3. В каждой выборке должно быть не меньше 11 наблюдений. Объемы выборок должны… а) если в каждой выборке меньше 50 наблюдений, то абсолютная величина разности между N1 и N2 должна быть больше 10…Алгоритм расчета критерия Розенбаума
2. Найти самое высокое значение в выборке 2. 3. Подсчитать количество значений в выборке 1, которые выше максимального… 4. Найти в выборке 1 самое маленькое значение.Непараметрический критерий Манна-Уитни
Назначение критерия
Этот метод определяет, достаточно ли мала зона перекрещивающихся значений между двумя рядами упорядоченных значений. При этом 1-м рядом (выборкой… Чем меньше область перекрещивающихся значений, тем более вероятно, что… Расчетное (эмпирическое) значение критерия U отражает то, насколько велика зона совпадения между рядами. Поэтому чем…Ограничения критерия
2. Выборки должны быть независимыми. 3. В каждой выборке должно быть не менее 3 наблюдений: n1, n2 ³ 3;… 4.В каждой выборке должно быть не более 60 наблюдений: n1, n2 £ 60.Однако уже при n1, n2 ³ 20 ранжирование…Алгоритм подсчета критерия Манна-Уитни.
1. Для расчета критерия необходимо мысленно все значения 1-й выборки и 2-й выборки объединить в одну общую объединенную выборку и упорядочить их. … Все расчеты удобно производить в таблице (таблица 28), состоящей из 4-х… При этом:Оценка достоверности сдвига в значениях исследуемого признака
Методические рекомендации к изучению темы
При изучении данной темы необходимо обратить внимание на то, что критерий Стьюдента применяется для сравнения любых двух параметров распределений,… При самостоятельном изучении критерия Фридмана и критерия тенденций Пейджа… После изучения материала лекции ответьте на контрольные вопросы и выполните самостоятельные задания, ответы занесите в…Материалы лекции.
Нередко, сравнивая «на глазок» результаты «до» и «после» какого либо воздействия (например, тренинга), психолог видит тенденции повторного измерения… При работе с этой группой критериев необходимо ввести понятие сдвига значений.Параметрический критерий Стьюдента для сравнения зависимых выборок
Назначение критерия
А) для сравнения любых двух параметров распределений или проверки гипотез о случайности различий между параметрами (Н0); Б) для интервального оценивания (является ли параметр, полученный на… В) для оценки статистической значимости мер связи (коэффициентов корреляции).Непараметрический критерий знаков
Назначение критерия.
Критерий знаков дает возможность установить, насколько однонаправленно изменяются значения признака при повторном измерении связанной, однородной выборки, или иначе — для установления общего направления сдвига исследуемого признака.
Он позволяет установить, в какую сторону в выборке в целом изменяются значения признака при переходе от первого измерения ко второму: увеличиваются или, наоборот, уменьшаются показатели.
Ограничения критерия.
2. Минимальное количество испытуемых, прошедших измерения в двух условиях — 5 человек. Максимальное количество испытуемых — 300 человек, что… 3. Нулевые сдвиги из рассмотрения исключаются, и количество наблюдений N… 4. Критерий знаков неприменим, когда величины типичного и нетипичного сдвигов оказываются равными.Непараметрический критерий Вилкоксона
Назначение критерия
Критерий применяется для сопоставления показателей, измеренных в двух разных условиях на одной и той же выборке испытуемых.
Он позволяет установить не только направленность изменений, но и их выраженность. С его помощью мы определяем, является ли сдвиг показателей в каком-то одном направлении более интенсивным, чем в другом.
Ограничения критерия
2. Минимальное количество испытуемых, прошедших измерения в двух условиях — 5 человек. Максимальное количество испытуемых — 50 человек, что… 3. Нулевые сдвиги из рассмотрения исключаются, и количество наблюдений N…Алгоритм подсчета критерия Вилкоксона
Таблица 31 №№ п/п х1i х2i di=x1i – x2i |di| R|di| … 2. Вычислить разность между индивидуальными значениями во втором и первом замерах ("после – до").…Выявление различий в распределении признака
Методические рекомендации к изучению темы
При изучении данной темы необходимо учесть то, что оба критерия непараметрические, они оперируют частотами. Обратите особое внимание на правила принятия решения для рассмотренных критериев: эти правила могут быть противоположны. Внимательно изучите ограничения в применении критериев.
После изучения материала лекции ответьте на контрольные вопросы, ответы занесите в конспект.
Материалы лекции.
Критерий «хи-квадрат» Пирсона
Критерий «хи-квадрат» Пирсона рассматривался в теме № 4. Напоминаем, что он может решать несколько задач, в том числе и сравнение распределений. Напомним его назначение.
Назначения критерия
1) для сопоставления эмпирического распределения признака с теоретическим - равномерным, нормальным или каким-то иным; 2) для сопоставления двух, трех или более эмпирических распределений одного и… 3) для оценки стохастической (вероятностной) независимости в системе случайных событий;Критерий Колмогорова-Смирнова
Назначение критерия
а) эмпирического с теоретическим, например, равномерным или нормальным; б) одного эмпирического распределения с другими эмпирическим распределением. …Алгоритм расчета критерия
1. Расчеты целесообразно провести, пользуясь следующей таблицей. Таблица 32 № п/п xi f1i f2i p1i …Крит.= 1,36 для уровня значимости р=0,95
Крит.= 1,63 для уровня значимости р=0,99
Если λэмп. < λкрит., то различия между распределениями статистически не достоверны. Контрольные вопросы: 1. Какие задачи решает критерий хи-квадрат Пирсона?Многофункциональные статистические критерии
Методические рекомендации к изучению темы
После изучения материала лекции ответьте на контрольные вопросы, ответы занесите в конспект. При самостоятельном изучении биномиального критерия…Материалы лекции.
Многофункциональные критерии построены на сопоставлении долей, выраженных в долях единицы или в процентах. Суть критериев состоит в определении… Критерий φ*применяется в тех случаях, когда обследованы две выборки…Критерий φ* — «Угловое преобразование» Фишера
Назначение критерия
Критерий оценивает достоверность различий между процентными долями двух выборок, в которых зарегистрирован интересующий нас эффект. Суть углового преобразования Фишера состоит в переводе процентных долей в…На уровне значимости р=0,95 и φ*=2,31 на уровне значимости р=0,99.
Если φ*расч> φ*табл, то различия между сравниваемыми процентными долями статистически значимы.
Если φ*расч≤ φ*табл, то различия между сравниваемыми процентными долями статистически незначимы.
Критерий Макнамары
Назначение критерия
Критерий Макнамары очень прост, однако его использование имеет некоторые особенности и требует определенных навыков в статистических расчетах и работе с таблицами критических величин. Этот критерий относится также к числу непараметрических критериев и предназначен для работы с данными, полученными в самой простой из номинальных в дихотомической шкале. Критерий позволяет оценить различия между значениями признака, полученные в двух замерах на одной и той же выборке испытуемых.
Ограничения в использовании критерия
Для применения критерия Макнамары необходимо соблюдать следующие условия:
1. Измерение должно быть проведено дихотомической шкале (в шкале наименований, при этом признак может иметь всего два значения).
2. Выборка должна быть зависимой.
Алгоритм расчет критерия
Таблица 34 Замеры Второй замер Σ Значения признака Первый вариант… В таблице 34 «А» обозначает число испытуемых, которые в первый и второй замеры выбрали первый вариант ответа; «С» —…Возможна ситуация, в которой В = С. В этом случае критерий Макнамары не может быть применен и следует воспользоваться критерием хи-квадрат.
2. Работа по критерию Макнамары начинается с выяснения вопроса о том, будет ли сумма чисел, стоящих в ячейках В и С, меньше или равна 20 или эта сумма будет превышать число 20. В первом случае, то есть когда сумма чисел В+С ≤ 20 используется один способ расчета по критерию — способ А. Если сумма чисел, стоящих в ячейках В + С > 20 — используется другой способ, способ Б.
Способ А. Пусть сумма (В + С) ≤ 20, тогда дальнейший расчет по критерию Макнамары производится следующим образом:
3. Находится наименьшая величина из величин В и С, которая обозначается буквой m, т.е т m=min (В или С).
3. Находится сумма величина В + С, которая обозначается буквой n, т.е. n= В + С.
4. По таблице приложения в данном пособии (таблицы критических значений биномиального распределения) на пересечении строк и столбцов таблицы m и n находится величина Мэмп.. Особо подчеркнем, что, в отличие от всех критериев, по таблице приложения 10 находятся не критические величины, а именно эмпирическое значение критерия Макнамары. Это принципиальное отличие этого критерия от всех других.
Примечание. Нули в таблице приложения 8 опущены, поэтому к любому числу, найденному по этой таблице, нужно слева добавить нуль и занятую, так чтобы получить необходимую величину в виде: 0,«число, взятое из таблицы».
5. Правило вывода:
Величины Мкрит. в случае способа А являются постоянными и равны соответственно Мкрит.=0,025 для 5% уровня значимости и Мкрит.=0,005 для 1% уровня значимости.
Если Мэмп. ≤ Мкрит., различия между замерами статистически значимы.
Если Мэмп. > Мкрит., различия между замерами статистически незначимы.
Способ Б. Пусть сумма (В + С) > 20.
3. Производится расчет Мэмп. по следующей формуле:

4. Правило вывода:
Находятся критические величины Мкрит. по таблице критических значений для критерия хи-квадрат с числом степеней свободы ν=1(для четырехпольных таблиц). Однако поскольку величина степени свободы критерия хи-квадрат в данном случае всегда постоянна и равна 1, то критические величины Мкрит. так же, как и в случае способа А, всегда одни и те же и равны Мкрит. =3,841 для 5% уровня значимости и Мкрит. = 6,635 для 1% уровня значимости.
Если Мэмп. ≥ Мкрит., различия между замерами статистически значимы.
Если Мэмп. < Мкрит., различия между замерами статистически незначимы.
Обратите внимание, что для способов А и Б правила принятия решения разные (противоположны).
Контрольные вопросы: 1. В каких случаях следует использовать критерий «угловое преобразование»… 2. Почему критерий «угловое преобразование» Фишера может применяться для сравнения признаков, измеренных по любой…Дисперсионный анализ
Методические рекомендации к изучению темы
После изучения материала лекции ответьте на контрольные вопросы, ответы занесите в конспект и сохраните его до экзамена. При самостоятельном…Материалы лекции.
Введение в дисперсионный анализ ANOVA
Дисперсионный анализ, предложенный Р. Фишером, является статистическим методом, предназначенным для выявления влияния ряда отдельных факторов на результаты экспериментов, или иначе дисперсионный анализ — это анализ изменчивости признака под влиянием каких-либо контролируемых переменных факторов.
Этот метод базируется на предположении о том, что если на объект (группу испытуемых) влияет несколько независимых факторов и их влияние складывается, то общую дисперсию значений признака, характеризующую объект (группу испытуемых), можно разложить на сумму дисперсий, возникающих в результате воздействия каждого отдельного фактора, а также обусловленных случайными влияниями (остаточная дисперсия). Сравнение дисперсий, обусловленных влиянием различных факторов, со случайной (остаточной) дисперсией позволяет оценить значимость вклада каждого из факторов, т.е. оценить достоверность этих влияний.
В основе дисперсионного анализа лежит предположение, что одни переменные могут рассматриваться как причины, а другие как следствия. При этом в психологических исследованиях именно переменные, рассматриваемые как причины, считаются факторами (независимыми переменными), а вторые переменные, рассматриваемые как следствия, — результативными признаками (зависимыми переменными). Независимые переменные называют иногда регулируемыми факторами именно потому, что в эксперименте психолог имеет возможность варьировать ими и анализировать получающийся результат.
Таким образом, дисперсионный анализ может выступать как метод, направленный на изучение изменчивости признака под влиянием каких-либо контролируемых факторов. Он позволяет выявить взаимодействие двух или большего числа факторов в их влиянии на один и тот же результативный признак (зависимую переменную).
Сущность дисперсионного анализа (ANOVA — Analysis Of VAriance) заключается в расчленении общей дисперсии изучаемого признака на отдельные компоненты, обусловленные влиянием конкретных факторов, и проверке гипотез о значимости влияния этих факторов на исследуемый признак. Сравнивая компоненты дисперсии друг с другом посредством F-критерия Фишера, можно определить, какая доля общей вариативности результативного признака обусловлена действием регулируемых факторов.
Исходным материалом для дисперсионного анализа служат данные исследования трех и более выборок, которые могут быть как равными, так и неравными по численности, как связанными, так и несвязанными. По количеству выявляемых регулируемых факторов дисперсионный анализ может быть однофакторным (при этом изучается влияние одного фактора на результаты эксперимента), двухфакторным (при изучении влияния двух факторов) и многофакторным.
Однофакторный дисперсионный анализ
В данной теме будет рассмотрен только однофакторный дисперсионный анализ, используемый для несвязанных выборок. Оперируя как основным понятием… • общая дисперсия, вычисленная по всей совокупности экспериментальных… • внутригрупповая дисперсия, характеризующая вариативность признака в каждой выборке;Общая сумма квадратов отклонений = сумма квадратов отклонений от групповых средних + сумма квадратов отклонений групповых средних от общей средней.
Перепишем это положение в виде второго уравнения:
Qo = Q1 + Q2,
где: Qo — общая сумма квадратов отклонений;
Q1 — сумма квадратов отклонений от групповых средних;
Q2 — сумма квадратов отклонений групповых средних от общей средней.
Теперь эти же обозначения представим в виде расчетных формул:
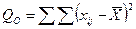


Для получения дисперсии необходимо поделить каждую из этих величин на соответствующую величину степеней свободы.
Пусть  — число степеней свободы, учитываемое при расчете общей дисперсии,
— число степеней свободы, учитываемое при расчете общей дисперсии,  — число степеней свободы, учитываемое при расчете внутригрупповой дисперсии (согласно первому уравнению оно равно N – p),
— число степеней свободы, учитываемое при расчете внутригрупповой дисперсии (согласно первому уравнению оно равно N – p),  — число степеней свободы, учитываемое при расчете межгрупповой дисперсии (согласно первому уравнению оно равно p–1).
— число степеней свободы, учитываемое при расчете межгрупповой дисперсии (согласно первому уравнению оно равно p–1).
Тогда = + =N – p + p – 1 = N – 1, и вычисление оценок дисперсий будет осуществляться таким образом:
 и
и 
Дисперсия S12 — характеризует рассеяние внутри групп (случайная вариация признака), эту величину называют также остаточной дисперсией.
Дисперсия S22 — характеризует рассеяние групповых средних (систематическая вариация).
Заключительным этапом дисперсионного анализа является вычисление отношения дисперсий по формуле следующей формуле:

При этом межгрупповая дисперсия S22 всегда находится в числителе, а внутригрупповая S12 (случайная) — в знаменателе.
Оценка уровня значимости статистической гипотезы в дисперсионном анализе осуществляется с помощью F критерия Фишера.
Правило вывода:
Если влияние фактора отсутствует, то вычисленное отношение не превзойдет критический предел (Fэмп. £ Fкрит.), тогда следует принять нулевую гипотезу Н0 об отсутствии влияний фактора на экспериментальные данные.
Напротив, если влияние фактора велико, то (Fэмп. > Fкрит.), в этом случае необходимо принять альтернативную гипотезу Н1 о наличии влияния фактора на экспериментальные данные.
В дисперсионном анализе нулевую гипотезу Н0 можно сформулировать так: средние величины анализируемого результативного фактора одинаковы для всех его градаций. Соответственно альтернативная гипотеза Н1 будет утверждать, что средние величины результативного фактора различны для всех его градаций.
Поскольку для дисперсионного анализа необходимо получить общую сумму квадратов отклонений (обозначаемую как Qo), то согласно определению дисперсии необходимо из каждого элемента экспериментальной совокупности данных вычесть общее среднее, полученные величины возвести в квадрат и сложить. Поскольку подобную вычислительную процедуру проделать достаточно сложно, то для вычислений по методу однофакторного дисперсионного анализа используются более простые уравнения.
При этом расчет оценок дисперсий удобно проводить по специальной таблице, получившей название таблицы дисперсионного анализа (таблица 36).
Таблица 36
| Характер вариации | Сумма квадратов | Число степеней свободы | Оценка дисперсии |
| Межгрупповая | 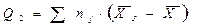
| p – 1 | 
|
| Внутригрупповая |
| N – p | 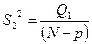
|
| Итого |
| N – 1 |
При этом величины Qo , Q1 и Q2 можно вычислить по следующим упрощенным формулам:
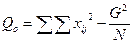

Поскольку Q1 = QО – Q2 , то

Для применения однофакторного дисперсионного анализа (как, кстати, и любого другого дисперсионного анализа) необходимо соблюдать следующие условия:
1. Измерение должно быть произведено в шкале равных интервалов (интервальной) или равных отношений (пропорциональной).
2. Результативный признак должен быть распределен нормально в исследуемой выборке.
3. Для адекватного использования метода требуется не менее трех градаций фактора и не менее двух испытуемых в каждой градации.
Контрольные вопросы:
1. Основное назначение дисперсионного анализа?
2. Каким условиям должны отвечать исходные данные для применения дисперсионного анализа?
3. Как оценить нормальность распределения признака в выборке?
4. В чем заключается различие двух видов дисперсионного анализа — однофакторного и двухфакторного?
5. Каковы основные этапы выполнения однофакторного дисперсионного анализа?
Самостоятельное практическое задание:
1. Самостоятельно изучите особенности дисперсионного анализа для зависимых выборок и запишите алгоритм его проведения.
2. Самостоятельно изучите двух факторный дисперсионный анализ и запишите алгоритмы его проведения для независимых и зависимых выборок.
Материалы для изучения темы:
а) основная литература:
1. Ермолаев О. Ю. Математическая статистика для психологов [Текст]: учебник / О. Ю. Ермолаев. - 5-е изд. - М.: МПСИ: Флинта, 2011. - 336 с. – С. 178-201.
2. Наследов А.Д. Математические методы психологического исследования: Анализ и интерпретация данных [Текст]: учебное пособие / А. Д. Наследов. - 3-е изд., стереотип. - СПб.: Речь, 2007. - 392 с. - С. 185-234.
3. Сидоренко Е. В. Методы математической обработки в психологии [Текст] / Е. В. Сидоренко. - СПб.: Речь, 2010. - 350 с.: ил. - С. 224-260.
б) дополнительная литература:
1. Гласс Дж. Статистические методы в педагогике и психологии [Текст]. / Дж. Гласс, Дж. Стенли— М., 1976. – 494 с. - С. 305-342; 259-436.
2. Кутейников А.Н. Математические методы в психологии [Текст]: учебно-методический комплекс / А. Н. Кутейников. - СПб.: Речь, 2008. - 172 с.: табл. - С. 114-133.
3. Суходольский Г.В. Основы математической статистики для психологов [Текст]: учебник / Г. В. Суходольский. - СПб.: Изд-во СПбГУ, 1998. - 464 с. - С. 340-372.
Многомерные методы обработки данных
Методические рекомендации к изучению темы
Факторный анализ рассмотрен более подробно ввиду более широкого его использования. После изучения материала лекции ответьте на контрольные вопросы, ответы…Материалы лекции.
Наследов А. Д. вводит понятие эмпирической математической модели (ЭММ), которые идентичны мыслительным операциям. Эти модели он называет… Непосредственно сравнивать, различать, определять взаимосвязь и т.д. мы можем… Многомерные методы анализа — дальнейшее развитие ЭММ в отношении многостороннего описания изучаемых явлений. Как и…Множественный регрессионный анализ
1) изучение взаимосвязи одной переменной («зависимой», результирующей) от нескольких других («независимых», исходных); 2) выявление среди «независимых» переменных наиболее существенных, важных для… Обычно множественный регрессионный анализ (МРА) применяется для изучения возможности предсказания некоторого…Если исходить из предположения о том, что корреляции могут быть объяснены влиянием скрытых причин — факторов, то основное назначение факторного анализа — анализ корреляций множества признаков.
Рассмотрим результаты факторного анализа на простом примере. Предположим, исследователь измерил на выборке из 50 испытуемых 5 показателей интеллекта: счет в уме, продолжение числовых рядов, осведомленность, словарный запас, установление сходства. Все показатели статистически значимо взаимосвязаны на уровне р < 0,05, кроме показателя № 4 с № 1 и 2 (табл. 37).
Таблица 37
Матрица корреляций пяти показателей интеллекта
Применив факторный анализ, исследователь выделил два фактора. Основной результат, который подлежит интерпретации исследователем, — таблица… Таблица 38Факторные нагрузки после варимакс-вращения
Не рассматривая пока шаги, приводящие к этому результату, попытаемся проинтерпретировать полученные данные (интерпретация фактора производится… Интерпретация факторов — одна из основных задач факторного анализа. Ее решение заключается в идентификации факторов…Эксплораторный-разведочный.
Используется для анализа результатов исследования для того, чтобы сформулировать рабочие гипотезы о причинах обнаруженных связей. Выполняется на ориентировочной стадии работы.
Конфирматорный.
Применяется на более поздних стадиях исследования для проверки гипотез. Когда в рамках какой-либо теории или модели сформулированы чёткие гипотезы, факторы между переменными и факторами достаточно определены, и исследователь может их прямо указать. В этом случае факторный анализ является средством проверки соответствия сформулированной гипотезы полученным эмпирическим данным.
Факторный анализ может выполняться различными методами (о различии методов см. учебник Наследова).
Анализ главных компонент.При использовании этого метода общность каждой переменной получается автоматически, путем суммирования квадратов ее нагрузок по всем главным компонентам. Вопрос о приближении восстановленных коэффициентов корреляции к исходным корреляциям не решается. В результате факторная структура искажается в сторону преувеличения абсолютных величин факторных нагрузок.
Факторный анализ образов— это метод главных компонент, применяемый к так называемой редуцированной корреляционной матрице, у которой вместо единиц на главной диагонали располагаются оценки общностей. Общность каждой переменной оценивается предварительно, как квадрат коэффициента множественной корреляции (КМК) этой переменной со всеми остальными. Такая оценка, с точки зрения теоретиков факторного анализа, приводит к более точным результатам, чем в анализе главных компонент. Но значения общностей недооцениваются, что также приводит к искажениям факторной структуры, хотя и меньшим, чем в предыдущем случае.
Метод главных осейпозволяет получить более точное решение. На первом шаге общности вычисляются по методу главных компонент. На каждом последующем шаге собственные значения и факторные нагрузки вычисляются исходя из предыдущих значений общностей. Окончательное решение получается при выполнении заданного числа итераций или достижении минимальных различий между общностями на данном и предыдущем шагах.
Метод не взвешенных наименьших квадратов— минимизирует квадраты остатков (разностей) исходной и воспроизведенной корреляционных матриц (вне главной диагонали). Процесс повторяется многократно до тех пор, пока не достигается минимально возможная разница между исходными и вычисленными корреляциями при заданном числе факторов. Метод, по определению, дает минимальные ошибки факторной структуры при фиксированном числе факторов. Реализация метода в компьютерных программах позволяет проверить расхождения между исходными и вычисленными корреляциями. Наличие многочисленных расхождений может служить дополнительным аргументом в пользу увеличения числа факторов.
Обобщенный метод наименьших квадратов— отличается от предыдущего тем, что для каждой переменной вводятся специальные весовые коэффициенты. Чем больше общность переменной, тем в большей степени она влияет на факторную структуру (имеет больший вес). Это соответствует основному принципу статистического оценивания, по которому менее точные наблюдения учитываются в меньшей степени. В этом — основное преимущество этого метода перед остальными.
Метод максимального правдоподобиятакже направлен на уменьшение разности исходных и вычисленных корреляций между признаками. Дополнительно этот метод позволяет получить важный показатель полноты факторизации — статистическую оценку «качества подгонки». Однако следует помнить, что этот критерий, как и остальные формальные критерии, является дополнительным. Окончательное же решение о числе факторов принимается после содержательной интерпретации факторной структуры.
Вряд ли возможно дать общие рекомендации о преимуществе или недостатке того или иного метода. Можно лишь отметить, что анализ главных компонент дает наиболее грубое решение, а метод максимального правдоподобия позволяет статистически оценить минимально возможное число факторов для данного набора переменных. По-видимому, в каждом конкретном случае стоит сравнивать результаты применения разных методов и выбирать тот, который позволяет получить наиболее простую и доступную интерпретации факторную структуру.
Основные этапы факторного анализа:
Выбор исходных данных.
Б) Все признаки должны иметь нормальное распределение. В) Между признаками недопустимы функциональные зависимости. Г) Нежелательны корреляции, близкие к единице («1»).Предварительное решение проблемы числа факторов.
А) Указать приблизительное число факторов и получить график собственных значений факторов.
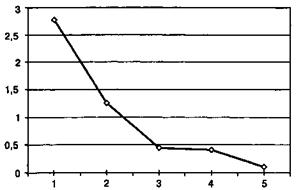
|
Рис. 20. График собственных значений факторов
На графике находится точка перегиба ломаной линии; этой точке соответствует k факторов; возможное число факторов будет равно: k±1.
Данный способ называется метод отсеивания Кеттела.
Б) Критерий величины собственного значения фактора.
Выбирается число факторов, для которых собственные значения больше 1. На этом этапе рекомендуется использовать метод факторного анализа – анализ главных компонент, и проверить несколько гипотез о числе факторов. Начинать следует с максимально возможного числа факторов; с учётом обоих критериев уменьшить их число.
Окончательное решение о числе факторов принимается только после интерпретации факторов.
Факторизация матрицы интеркорреляций.
А) Суммарная доля дисперсии – это показатель того, насколько полно выделяемые факторы могут представить данный набор признаков, а этот набор – сами… Б) Общность переменной – это показатель её участия в анализе, - показатель,…Вращение и предварительная интерпретация факторов (ротация факторов).
Ротация факторов перемещает факторы относительно переменных таким образом, что большие факторные нагрузки увеличиваются, а маленькие – уменьшаются. После вращения получается простая структура, которую легче интерпретировать. Ротация факторов может быть выполнена двумя методами:
А) Ортогональное вращение (четырёх видов).
Квартимакс. Минимизирует количество факторов, необходимых для объяснения данной переменной. Этот метод усиливает возможности для интерпретации… Эквимакс и биквартимакс представляют собой комбинации двух первых видов…Б) Косоугольное (облическое) вращение.
Интерпретацию после вращения нужно проводить в следующем порядке: · По каждой переменной (строке) выделяется наибольшая по абсолютной величине… · После просмотра всех строк начинают просмотр столбцов (т.е. факторов). По каждому фактору выписывают названия…Принятие решения о качестве факторной структуры.
Если исследователю необходимо обосновать устойчивость факторной структуры в генеральной совокупности, то добавляется ещё одно требование:… Для того, чтобы приблизиться к простой структуре, необходимо проделать ряд… А) Если по результатам интерпретации выявлен фактор, для которого ни один признак не имеет максимальной нагрузки (по…Вычисление факторных коэффициентов и оценок.
Факторные коэффицинты – это коэффициенты линейного уравнения, связывающие значения фактора и значения исходных признаков. Они показывают, с каким весом входят исходные значения каждой переменной в оценку фактора.
Факторные оценки – это значения факторов для каждого объекта (испытуемого). Это новые переменные, являющиеся независимыми и отражающие структуру взаимосвязи исходных признаков.
Компьютерные пакеты прикладных статистических программ
Работе с программой SPSS посвящена вторая часть пособия. Контрольные вопросы:Список литературы
Основная литература
1. Ермолаев О. Ю. Математическая статистика для психологов [Текст]: учебник / О. Ю. Ермолаев. - 5-е изд. - М.: МПСИ: Флинта, 2011. - 336 с.
2. Наследов А.Д. Математические методы психологического исследования: Анализ и интерпретация данных [Текст]: учебное пособие / А. Д. Наследов. - 3-е изд., стереотип. - СПб.: Речь, 2007. - 392 с.
3. Сидоренко Е. В. Методы математической обработки в психологии [Текст] / Е. В. Сидоренко. - СПб.: Речь, 2010. - 350 с.: ил.
4. Суходольский Г. В. Математические методы в психологии [Текст] / Г. В. Суходольский. - 3-е изд., испр. - Харьков: Гуманитарный центр, 2008. - 284 с.
Дополнительная литература
Бешелев С.Д. Математико-статистические методы экспертных оценок. [Текст]. / С.Д. Бешелев, Ф. Г. Гурвич– 2-е изд., перераб. и доп.— М.: Статистика, 1980. – 263 с.
1. Благинин, А. А. Математические методы в психологии и педагогике [Текст] / А. А. Благинин, В. В. Торчило. - СПб. : ЛГУ им. А. С. Пушкина, 2006. - 84 с.
2. Гласс Дж. Статистические методы в педагогике и психологии [Текст]. / Дж. Гласс, Дж. Стенли— М., 1976. – 494 с.
3. Гусев А. Н. Дисперсионный анализ в экспериментальной психологии [Текст]. / А.Н. Гусев. — М.: Уч.-метод. коллектор «Психология», 2000. – 136с.
4. Кутейников А.Н. Математические методы в психологии [Текст]: учебно-методический комплекс / А. Н. Кутейников. - СПб.: Речь, 2008. - 172 с.: табл.
5. Пахомов А. П. Проблема осмысленности психологических измерений [Электронный ресурс]. / А.П. Пахомов // Психологический журнал, №5, 2006. – с.75-82 - // Пси-фактор. – Режим доступа: http://psyfactor.org/lib/pahomov.htm
6. Раскин В. Н. Математика и психология: очевидное и невероятное (из опыта преподавания курса "Математические методы в психологии" / В. Н. Раскин [Текст]. // Вестник Санкт-Петербургского государственного института психологии и социальной работы. - СПб.,
2003г., N 1 - с.26-28.
7. Раскин В.Н. Обработка данных психологических и социальных исследований на компьютере (с использованием программы SPSS) [Текст]: учебное пособие / В. Н. Раскин. - СПб : [б. и.], 2005. - 59 с.
8. Резник А. Д. Книга для тех, кто не любит статистику, но вынужден ею пользоваться. Непараметрическая статистика в примерах, упражнениях и рисунках. [Текст]. / А.Д. Резник. — СПб.: Речь, 2008. – 265 с.; илл.
9. Савченко Т. Н. Применение методов кластерного анализа для обработки данных психологических исследований [Текст]. / Т. Н. Савченко. // Экспериментальная психология. - М.: Московский городской психолого-педагогический университет, 2010г. т.3 N 2 - с.67-86
10. Суходольский Г.В. Основы математической статистики для психологов [Текст]: учебник / Г. В. Суходольский. - СПб.: Изд-во СПбГУ, 1998. - 464 с.
11. Харари Ф. Теория графов. [Текст] / Харари Ф. — М.: Едиториал УРСС, 2003. – 297 с.
Приложение 1. Статистические таблицы с критическими значениями
Критические значения отношения для исключения выскакивающих значений
Если полученная (расчетная) величина отношения ³величине табличного отношения, то проверяемое значение переменной является выскакивающей… При этом a=0,01 — высокий уровень достоверности; a=0,05 — может быть грубая…Критические значения коэффициента ранговой корреляции Спирмена
Критические значения коэффициента линейной корреляции Пирсона
Критические значения критерия хи-квадрат Пирсона
При c2 эмп. ³ c2теор., a,nразличия статистически достоверны. n a=0,05 a=0,01 n a=0,05 a=0,01 …Критические значения критерия Стьюдента
При tрасч. ³ tтабл.,a,nразличия статистически значимы. ν α=0,05 α=0,01 …Критические значения критерия Фишера
При Fрасч. ³Fтабл.,α,ν1,ν2дисперсии статистически различаются; ν1 — число степеней свободы числителя, ν2 — число степеней свободы… α=0,01 ν2 ν1 …Критические значения непараметрического критерия Манна-Уитни
Различия между двумя выборками можно считать значимыми (р<0,05), если Uэмп ≤ табл., 0,05 и тем более достоверными (р<0,01), если Uэмп… N1 …Критические значения непараметрического критерия Вилкоксона
При Т расч. £ Т табл.,a, Nразличия статистически значимы. N a=0,05 a=0,01 N a=0,05 a=0,01 …Таблицы для перевода процентных долей в величины центрального угла для расчета критерия «угловое преобразование» Фишера
(из книги: Ермолаев О. Ю. Математическая статистика для психологов [Текст]: учебник / О. Ю. Ермолаев. - 5-е изд. - М.: МПСИ: Флинта, 2011. - 336 с. - С.308-312)
Величины угла φ (в радианах) для разных процентных долей: 
| % доля | %, сотый знак | ||||||||||||||||
Значения  
| |||||||||||||||||
| 0,0 | 0,000 | 0,020 | 0,028 | 0,035 | 0,040 | 0,045 | 0,049 | 0,053 | 0,057 | 0,060 | |||||||
| 0,1 | 0,063 | 0,066 | 0,069 | 0,072 | 0,075 | 0,077 | 0,080 | 0,082 | 0,085 | 0,087 | |||||||
| 0,2 | 0,089 | 0,092 | 0,094 | 0,096 | 0,098 | 0,100 | 0,102 | 0,104 | 0,106 | 0,108 | |||||||
| 0,3 | 0,110 | 0,111 | 0,113 | 0,115 | 0,117 | 0,118 | 0,120 | 0,122 | 0,123 | 0,125 | |||||||
| 0,4 | 0,127 | 0,128 | 0,130 | 0,131 | 0,133 | 0,134 | 0,136 | 0,137 | 0,139 | 0,140 | |||||||
| 0,5 | 0,142 | 0,143 | 0,144 | 0,146 | 0,147 | 0,148 | 0,150 | 0,151 | 0,153 | 0,154 | |||||||
| 0,6 | 0,155 | 0,156 | 0,158 | 0,159 | 0,160 | 0,161 | 0,163 | 0,164 | 0,165 | 0,166 | |||||||
| 0,7 | 0,168 | 0,169 | 0,170 | 0,171 | 0,172 | 0,173 | 0,175 | 0,176 | 0,177 | 0,178 | |||||||
| 0,8 | 0,179 | 0,180 | 0,182 | 0,183 | 0,184 | 0,185 | 0,186 | 0,187 | 0,188 | 0,189 | |||||||
| 0,9 | 0,190 | 0,191 | 0,192 | 0,193 | 0,194 | 0,195 | 0,196 | 0,197 | 0,198 | 0,199 | |||||||
| % доля | %, последний десятичный знак | ||||||||||||||||
| Значения
| |||||||||||||||||
| 0,200 | 0,210 | 0,220 | 0,229 | 0,237 | 0,246 | 0,254 | 0,262 | 0,269 | 0,277 | ||||||||
| 0,284 | 0,291 | 0,298 | 0,304 | 0,311 | 0,318 | 0,324 | 0,330 | 0,336 | 0,342 | ||||||||
| 0,348 | 0,354 | 0,360 | 0,365 | 0,371 | 0,376 | 0,382 | 0,387 | 0,392 | 0,398 | ||||||||
| 0,403 | 0,408 | 0,413 | 0,418 | 0,423 | 0,428 | 0,432 | 0,437 | 0,442 | 0,446 | ||||||||
| 0,451 | 0,456 | 0,460 | 0,465 | 0,469 | 0,473 | 0,478 | 0,482 | 0,486 | 0,491 | ||||||||
| 0,495 | 0,499 | 0,503 | 0,507 | 0,512 | 0,516 | 0,520 | 0,524 | 0,528 | 0,532 | ||||||||
| 0,536 | 0,539 | 0,543 | 0,547 | 0,551 | 0,555 | 0,559 | 0,562 | 0,566 | 0,570 | ||||||||
| 0,574 | 0,577 | 0,581 | 0,584 | 0,588 | 0,592 | 0,595 | 0,599 | 0,602 | 0,606 | ||||||||
| 0,609 | 0,613 | 0,616 | 0,620 | 0,623 | 0,627 | 0,630 | 0,633 | 0,637 | 0,640 | ||||||||
| 0,644 | 0,647 | 0,650 | 0,653 | 0,657 | 0,660 | 0,663 | 0,666 | 0,670 | 0,673 | ||||||||
| 0,676 | 0,679 | 0,682 | 0,686 | 0,689 | 0,692 | 0,695 | 0,698 | 0,701 | 0,704 | ||||||||
| 0,707 | 0,711 | 0,714 | 0,717 | 0,720 | 0,723 | 0,726 | 0,729 | 0,732 | 0,735 | ||||||||
| 0,738 | 0,741 | 0,744 | 0,747 | 0,750 | 0,752 | 0,755 | 0,758 | 0,761 | 0,764 / | ||||||||
| 0,767 | 0,770 | 0,773 | 0,776 | 0,778 | 0,781 | 0,784 | 0,787 | 0,790 | 0,793 | ||||||||
| 0,795 | 0,798 | 0,801 | 0,804 | 0,807 | 0,809 | 0,812 | 0,815 | 0,818 | 0,820 | ||||||||
| % доля | %, последний десятичный знак | ||||||||||||||||
| Значения
| |||||||||||||||||
| 0,823 | 0,826 | 0,828 | 0,831 | 0,834 | 0,837 | 0,839 | 0,842 | 0,845 | 0,847 | ||||||||
| 0,850 | 0,853 | 0,855 | 0,858 | 0,861 | 0,863 | 0,866 | 0,868 | 0,871 | 0,874 | ||||||||
| 0,876 | 0,879 | 0,881 | 0,884 | 0,887 | 0,889 | 0,892 | 0,894 | 0,897 | 0,900 | ||||||||
| 0,902 | 0,905 | 0,907 | 0,910 | 0,912 | 0,915 | 0,917 | 0,920 | 0,922 | 0,925 | ||||||||
| 0,927 | 0,930 | 0,932 | 0,935 | 0,937 | 0,940 | 0,942 | 0,945 | 0,947 | 0,950 | ||||||||
| 0,952 | 0,955 | 0,957 | 0,959 | 0,962 | 0,964 | 0,967 | 0,969 | 0,972 | 0,974 | ||||||||
| 0,976 | 0,979 | 0,981 | 0,984 | 0,986 | 0,988 | 0,991 | 0,993 | 0,996 | 0,998 | ||||||||
| 1,000 | 1,003 | 1,005 | 1,007 | 1,010 | 1,012 | 1,015 | 1,017 | 1,019 | 1,022 | ||||||||
| 1,024 | 1,026 | 1,029 | 1,031 | 1,033 | 1,036 | 1,038 | 1,040 | 1,043 | 1,045 | ||||||||
| 1,047 | 1,050 | 1,052 | 1,054 | 1,056 | 1,059 | 1,061 | 1,063 | 1,066 | 1,068 | ||||||||
| 1,070 | 1,072 | 1,075 | 1,077 | 1,079 | 1,082 | 1,084 | 1,086 | 1,088 | 1,091 | ||||||||
| 1,093 | 1,095 | 1,097 | 1,100 | 1,102 | 1,104 | 1,106 | 1,109 | 1,111 | 1,113 | ||||||||
| 1,115 | 1,117 | 1,120 | 1,122 | 1,124 | 1,126 | 1,129 | 1,131 | 1,133 | 1,135 | ||||||||
| 1,137 | 1,140 | 1,142 | 1,144 | 1,146 | 1,148 | 1,151 | 1,153 | 1,155 | 1,157 | ||||||||
| 1,159 | 1,161 | 1,164 | 1,166 | 1,168 | 1,170 | 1,172 | 1,174 | 1,177 | 1,179 | ||||||||
| 1,182 | 1,183 | 1,185 | 1,187 | 1,190 | 1,192 | 1,194 | 1,196 | 1,198 | 1,200 | ||||||||
| 1,203 | 1,205 | 1,207 | 1,209 | 1,211 | 1,213 | 1,215 | 1,217 | 1,220 | 1,222 | ||||||||
| 1,224 | 1,226 | 1,228 | 1,230 | 1,232 | 1,234 | 1,237 | 1,239 | 1,241 | 1,243 | ||||||||
| 1,245 | 1,247 | 1,249 | 1,251 | 1,254 | 1,256 | 1,258 | 1,260 | 1,262 | 1,264 | ||||||||
| 1,266 | 1,268 | 1,270 | 1,272 | 1,274 | 1,277 | 1,279 | 1,281 | 1,283 | 1,285 | ||||||||
| 1,287 | 1,289 | 1,291 | 1,293 | 1,295 | 1,297 | 1,299 | 1,302 | 1,304 | 1,306 | ||||||||
| 1,308 | 1,310 | 1,312 | 1,314 | 1,316 | 1,318 | 1,320 | 1,322 | 1,324 | 1,326 | ||||||||
| 1,328 | 1,330 | 1,333 | 1,335 | 1,337 | 1,339 | 1,341 | 1,343 | 1,345 | 1,347 | ||||||||
| 1,349 | 1,351 | 1,353 | 1,355 | 1,357 | 1,359 | 1,361 | 1,363 | 1,365 | 1,367 | ||||||||
| 1,369 | 1,371 | 1,374 | 1,376 | 1,378 | 1,380 | 1,382 | 1,384 | 1,386 | 1,388 | ||||||||
| 1,390 | 1,392 | 1,394 | 1,396 | 1,398 | 1,400 | 1,402 | 1,404 | 1,406 | 1,408 | ||||||||
| 1,410 | 1,412 | 1,414 | 1,416 | 1,418 | 1,420 | 1,422 | 1,424 | 1,426 | 1,428 | ||||||||
| 1,430 | 1,432 | 1,434 | 1,436 | 1,438 | 1,440 | 1,442 | 1,444 | 1,446 | 1,448 | ||||||||
| 1,451 | 1,453 | 1,455 | 1,457 | 1,459 | 1,461 | 1,463 | 1,465 | 1,467 | 1,469 | ||||||||
| 1,471 | 1,473 | 1,475 | 1,477 | 1,479 | 1,481 | 1,483 | 1,485 | 1,487 | 1,489 | ||||||||
| 1,491 | 1,493 | 1,495 | 1,497 | 1,499 | 1,501 | 1,503 | 1,505 | 1,507 | 1,509 | ||||||||
| 1,511 | 1,513 | 1,515 | 1,517 | 1,519 | 1,521 | 1,523 | 1,525 | 1,527 | 1,529 | ||||||||
| % доля | %, последний десятичный знак | ||||||||||||||||
| Значения
| |||||||||||||||||
| 1,531 | 1,533 | 1,535 | 1,537 | 1,539 | 1,541 | 1,543 | 1,545 | 1,547 | 1,549 | ||||||||
| 1,551 | 1,553 | 1,555 | 1,557 | 1,559 | 1,561 | 1,563 | 1,565 | 1,567 | 1,569 | ||||||||
| 1,571 | 1,573 | 1,575 | 1,577 | 1,579 | 1,581 | 1,583 | 1,585 | 1,587 | 1,589 | ||||||||
| 1,591 | 1,593 | 1,595 | 1,597 | 1,599 | 1,601 | 1,603 | 1,605 | 1,607 | 1,609 | ||||||||
| 1,611 | 1,613 | 1,615 | 1,617 | 1,619 | 1,621 | 1,623 | 1,625 | 1,627 | 1,629 | ||||||||
| 1,631 | 1,633 | 1,635 | 1,637 | 1,639 | 1,641 | 1,643 | 1,645 | 1,647 | 1,649 | ||||||||
| 1,651 | 1,653 | 1,655 | 1,657 | 1,659 | 1,661 | 1,663 | 1,665 | 1,667 | 1,669 | ||||||||
| 1,671 | 1,673 | 1,675 | 1,677 | 1,679 | 1,681 | 1,683 | 1,685 | 1,687 | 1,689 | ||||||||
| 1,691 | 1,693 | 1,695 | 1,697 | 1,699 | 1,701 | 1,703 | 1,705 | 1,707 | 1,709 | ||||||||
| 1,711 | 1,713 | 1,715 | 1,717 | 1,719 | 1,721 | 1,723 | 1,725 | 1,727 | 1,729 | ||||||||
| 1,731 | 1,734 | 1,736 | 1,738 | 1,740 | 1,742 | 1,744 | 1,746 | 1,748 | 1,750 | ||||||||
| 1,752 | 1,754 | 1,756 | 1,758 | 1,760 | 1,762 | 1,764 | 1,766 | 1,768 | 1,770 | ||||||||
| 1,772 | 1,774 | 1,776 | 1,778 | 1,780 | 1,782 | 1,784 | 1,786 | 1,789 | 1,791 | ||||||||
| 1,793 | 1,795 | 1,797 | 1,799 | 1,801 | 1,803 | 1,805 | 1,807 | 1,809 | 1,811 | ||||||||
| 1,813 | 1,815 | 1,817 | 1,819 | 1,821 | 1,823 | 1,826 | 1,828 | 1,830 | 1,832 | ||||||||
| 1,834 | 1,836 | 1,838 | 1,840 | 1,842 | 1,844 | 1,846 | 1,848 | 1,850 | 1,853 | ||||||||
| 1,855 | 1,857 | 1,859 | 1,861 | 1,863 | 1,865 | 1,867 | 1,869 | 1,871 | 1,873 | ||||||||
| 1,875 | 1,878 | 1,880 | 1,882 | 1,884 | 1,886 | 1,888 | 1,890 | 1,892 | 1,894 | ||||||||
| 1,897 | 1,899 | 1,901 | 1,903 | 1,905 | 1,907 | 1,909 | 1,911 | 1,913 | 1,916 | ||||||||
| 1,918 | 1,920 | 1,922 | 1,924 | 1,926 | 1,928 | 1,930 | 1,933 | 1,935 | 1,937 | ||||||||
| 1,939 | 1,941 | 1,943 | 1,946 | 1,948 | 1,950 | 1,952 | 1,954 | 1,956 | 1,958 | ||||||||
| 1,961 | 1,963 | 1,965 | 1,967 | 1,969 | 1,971 | 1,974 | 1,976 | 1,978 | 1,980 | ||||||||
| 1,982 | 1,984 | 1,987 | 1,989 | 1,991 | 1,993 | 1,995 | 1,998 | 2,000 | 2,002 | ||||||||
| 2,004 | 2,006 | 2,009 | 2,011 | 2,013 | 2,015 | 2,018 | 2,020 | 2,022 | 2,024 | ||||||||
| 2,026 | 2,029 | 2,031 | 2,033 | 2,035 | 2,038 | 2,040 | 2,042 | 2,044 | 2,047 | ||||||||
| 2,049 | 2,051 | 2,053 | 2,056 | 2,058 | 2,060 | 2,062 | 2,065 | 2,067 | 2,069 | ||||||||
| 2,071 | 2,074 | 2,076 | 2,078 | 2,081 | 2,083 | 2,085 | 2,087 | 2,090 | 2,092 | ||||||||
| 2,094 | 2,097 | 2,099 | 2,101 | 2,104 | 2,106 | 2,108 | 2,111 | 2,113 | 2,115 | ||||||||
| 2,118 | 2,120 | 2,122 | 2,125 | 2,127 | 2,129 | 2,132 | 2,134 | 2,136 | 2,139 | ||||||||
| 2,141 | 2,144 | 2,146 | 2,148 | 2,151 | 2,153 | 2,156 | 2,158 | 2,160 | 2,163 | ||||||||
| 2,165 | 2,168 | 2,170 | 2,172 | 2,175 | 2,177 | 2,180 | 2,182 | 2,185 | 2,187 | ||||||||
| 2,190 | 2,192 | 2,194 | 2,197 | 2,199 | 2,202 | 2,204 | 2,207 | 2,209 | 2,212 | ||||||||
| % доля | %, последний десятичный знак | ||||||||||||||||
| Значения
| |||||||||||||||||
| 2,214 | 2,217 | 2,219 | 2,222 | 2,224 | 2,227 | 2,229 | 2,231 | 2,234 | 2,237 | ||||||||
| 2,240 | 2,242 | 2,245 | 2,247 | 2,250 | 2,252 | 2,255 | 2,258 | 2,260 | 2,263 | ||||||||
| 2,265 | 2,268 | 2,271 | 2,273 | 2,276 | 2,278 | 2,281 | 2,284 | 2,286 | 2,289 | ||||||||
| 2,292 | 2,294 | 2,297 | 2,300 | 2,302 | 2,305 | 2,308 | 2,310 | 2,313 | 2,316 | ||||||||
| 2,319 | 2,321 | 2,324 | 2,327 | 2,330 | 2,332 | 2,335 | 2,338 | 2,341 | 2,343 | ||||||||
| 2,346 | 2,349 | 2,352 | 2,355 | 2,357 | 2,360 | 2,363 | 2,366 | 2,369 | 2,372 | ||||||||
| 2,375 | 2,377 | 2,380 | 2,383 | 2,386 | 2,389 | 2,392 | 2,395 | 2,398 | 2,401 | ||||||||
| 2,404 | 2,407 | 2,410 | 2,413 | 2,416 | 2,419 | 2,422 | 2,425 | 2,428 | 2,431 | ||||||||
| 2,434 | 2,437 | 2,440 | 2,443 | 2,447 | 2,450 | 2,453 | 2,456 | 2,459 | 2,462 | ||||||||
| 2,465 | 2,469 | 2,472 | 2,475 | 2,478 | 2,482 | 2,485 | 2,488 | 2,491 | 2,495 | ||||||||
| 2,498 | 2,501 | 2,505 | 2,508 | 2,512 | 2,515 | 2,518 | 2,522 | 2,525 | 2,529 | ||||||||
| 2,532 | 2,536 | 2,539 | 2,543 | 2,546 | 2,550 | 2,554 | 2,561 | 2,564 | |||||||||
| 2,568 | 2,572 | 2,575 | 2,579 | 2,583 | 2,587 | 2,591 | 2,594 | 2,598 | 2,602 | ||||||||
| 2,606 | 2,610 | 2,614 | 2,618 | 2,622 | 2,626 | 2,630 | 2,634 | 2,638 | 2,642 | ||||||||
| 2,647 | 2,651 | 2,655 | 2,659 | 2,664 | 2,668 | 2,673 | 2,677 | 2,681 | 2,686 | ||||||||
| 2,691 | 2,295 | 2,700 | 2,705 | 2,709 | 2,714 | 2,719 | 2,724 | 2,729 | 2,734 | ||||||||
| 2,739 | 2,744 | 2,749 | 2,754 | 2,760 | 2,765 | 2,771 | 2,776 | 2,782 | 2,788 | ||||||||
| 2,793 | 2,799 | 2,805 | 2,811 | 2,818 | 2,824 | 2,830 | 2,837 | 2,844 | 2,851 | ||||||||
| 2,858 | 2,865 | 2,872 | 2,880 | 2,888 | 2,896 | 2,904 | 2,913 | 2,922 | 2,931 | ||||||||
| 99,0 | 2,941 | 2,942 | 2,943 | 2,944 | 2,945 | 2,946 | 2,948 | 2,949 | 2,950 | 2,951 | |||||||
| 99,1 | 2,952 | 2,953 | 2,954 | 2,955 | 2,956 | 2,957 | 2,958 | 2,959 | 2,960 | 2,961 | |||||||
| 99,2 | 2,963 | 2,964 | 2,965 | 2,966 | 2,967 | 2,968 | 2,969 | 2,971 | 2,972 | 2,973 | |||||||
| 99,3 | 2,974 | 2,975 | 2,976 | 2,978 | 2,979 | 2,980 | 2,981 | 2,983 | 2,984 | 2,985 | |||||||
| 99,4 | 2,987 | 2,988 | 2,989 | 2,990 | 2,992 | 2,993 | 2,995 | 2,996 | 2,997 | 2,999 | |||||||
| 99,5 | 3,000 | 3,002 | 3,003 | 3,004 | 3,006 | 3,007 | 3,009 | 3,010 | 3,012 | 3,013 | |||||||
| 99,6 | 3,015 | 3,017 | 3,018 | 3,020 | 3,022 | 3,023 | 3,025 | 3,027 | 3,028 | 3,030 | |||||||
| 99,7 | 3,032 | 3,034 | 3,036 | 3,038 | 3,040 | 3,041 | 3,044 | 3,046 | 3,048 | 3,050 | |||||||
| 99,8 | 3,052 | 3,054 | 3,057 | 3,059 | 3,062 | 3,064 | 3,067 | 3,069 | 3,072 | 3,075 | |||||||
| 99,9 | 3,078 | 3,082 | 3,085 | 3,089 | 3,093 | 3,097 | 3,101 | 3,107 | 3,113 | 3,122 | |||||||
| 100,0 | 3,142 | ||||||||||||||||
Таблица вероятностей Р для биномиального распределения при р = q = 0,5
(из книги: Ермолаев О. Ю. Математическая статистика для психологов [Текст]: учебник / О. Ю. Ермолаев. - 5-е изд. - М.: МПСИ: Флинта, 2011. - 336 с. - С.294-295)
Примечания к таблице:
* В таблице все величины даны без начального нуля и последующей запятой, так что, если в таблице дано число, например 013, - то это число следует читать как 0,013.
** Знаком + в таблице обозначены значения близкие к 1.
| Т2 | ||||||||||||||||
| 031* | +** | |||||||||||||||
| + | ||||||||||||||||
| + | ||||||||||||||||
| + | ||||||||||||||||
| + | ||||||||||||||||
| + | ||||||||||||||||
| + | ||||||||||||||||
| + | ||||||||||||||||
| + | + | |||||||||||||||
| + | + | + | ||||||||||||||
| + | + | + | ||||||||||||||
| + | + | |||||||||||||||
| + | ||||||||||||||||
Приложение 2. Глоссарий
1. Альтернативная гипотеза — это гипотеза о значимости различий. Она обозначается как Н1. Альтернативная гипотеза — это то, что мы, как правило, хотим доказать; поэтому иногда ее называют экспериментальной гипотезой.
2. Вариационный (статистический) ряд— таблица, первая строка которой содержит в порядке возрастания значения признака, а вторая — меры возможности их появления (абсолютные частоты, или относительные частоты, или процентные частоты).
3. Вероятностная зависимость (стохастическая связь) — это такая связь между явлениями или событиями, при которой появление одного из событий изменяет вероятность появления другого события.
4. Вероятность— мера возможности появления признака (число, не превышающее единицу).
5. Гистограмма— график в виде столбиковой диаграммы, который отражает зависимость между значениями признака и мерами возможности их появления.
6. Диаграмма рассеяния — график, представляющий собой множество (совокупность) точек в двумерном пространстве; координатами этих точек являются значения двух признаков. Такой график отражает зависимость между этими двумя признаками.
7. Дискриминантный анализ («классификация с обучением») предсказывает принадлежность объектов (испытуемых) к одному из известных классов (шкала наименований) по измеренным метрическим (дискриминантным) переменным. Дискриминантные переменные должны быть измерены в количественной шкале, зависимая переменная — в шкале наименований.
8. Дисперсия— D=Sx2 — это средний квадрат отклонений всех значений признака от среднего арифметического.
9. Дисперсионный анализ — это анализ изменчивости признака под влиянием каких-либо контролируемых переменных факторов. Признаки должны быть измерены в количественной шкале (интервальной или пропорциональной) и иметь нормальное распределение.
10. Доверительная вероятность — вероятность, с которой принимается нулевая гипотеза, или иначе: вероятность того, что нулевая гипотеза является истинной.
11. Зависимые выборки (связанные выборки) — это одна и та же группа людей, у которых были измерены одни и те же признаки в двух (или более) различных ситуациях, например, «до — после», «фон — стресс».
12. Измерение— это приписывание числовых форм объектам или событиям в соответствии с определенными правилами.
13. Квантили— значения признака, которые делят выборку на определенное количество равных частей. Наиболее распространенные квантили — это медиана; квартили Q1, Q2, Q3(делят выборку испытуемых на 4 равные части); децили D1, D2, D3, D4, D5, D6, D7, D8, D9 (делят выборку испытуемых на 10 равных частей); процентили Р1 ……….Р99 (делят выборку испытуемых на 100 равных частей).
14. Кластерный анализ («классификация без обучения»): по измеренным характеристикам у множества объектов (испытуемых) либо по данным об их попарном сходстве (различии) разбивает это множество объектов на группы, в каждой из которых находятся объекты, более похожие друг на друга, чем на объекты других групп.
15. Корреляционное отношение — является мерой связи для оценки нелинейных взаимозависимостей между признаками, измеренными по интервальной или пропорциональной шкале.
16. Коэффициент асимметрии— As — параметр, характеризующий асимметричность распределения по сравнению с нормальным распределением.
17. Коэффициент вариации или коэффициент вариативности— V — параметр, показывающий соотношение стандартного отклонения и среднего арифметического.
18. Коэффициент контингенцииили тетрахорический коэффициентили коэффициент четырехклеточной сопряженности— φ —является мерой связи между признаками, измеренными по дихотомической шкале наименований.
19. Коэффициент линейной корреляции Пирсона— rxy —является мерой связи для оценки линейных взаимозависимостей между признаками, измеренными по интервальной или пропорциональной шкале.
20. Коэффициент ранговой корреляции Спирмена— ρ=rs — является мерой связи между признаками, измеренными по шкале порядка или при сочетании шкалы порядка с интервальной или пропорциональной шкалой.
21. Коэффициент эксцесса— Ex— параметр, характеризующий выпуклость распределения по сравнению с нормальным распределением.
22. Критерий вообще — это решающее правило, обусловливающее поведение в ситуации выбора.
23. Критерий Вилкоксона — T — непараметрический критерий различий, который позволяет оценить различия между двумя зависимыми выборками: направление и выраженность изменений во втором замере по сравнению с первым. Применяется для сравнения признаков, измеренных по шкалам порядка, интервальной или пропорциональной.
24. Критерий Колмогорова-Смирнова — λ — непараметрический критерий, который позволяет оценить различия между двумя распределениями: найти точку, в которой они наиболее сильно различаются. Применяется для сравнения распределений признаков, измеренных по шкалам порядка, интервальной или пропорциональной.
25. Критерий Макнамары — M— непараметрический критерий, который позволяет оценить различия между двумя зависимыми выборками: два замера признака, измеренного по дихотомической шкале наименований и любым другим, если их результаты могут быть сведены к дихотомической шкале.
26. Критерий Манна-Уитни — U — непараметрический критерий различий, который позволяет оценить различия между двумя независимыми выборками: направление и выраженность значений признака. Применяется для сравнения признаков, измеренных по шкалам порядка, интервальной или пропорциональной.
27. Критерий Стьюдента — t — параметрический критерий различий, который позволяет сравнить два любых параметра распределений, полученных в двух выборках. Применяется для сравнения признаков, измеренных по интервальной или пропорциональной шкале при условии нормального распределения признака.
28. Критерий угловое преобразование Фишера — φ* — непараметрический критерий различий, который позволяет оценить различия между двумя процентными долями в двух независимых выборках. Применяется для сравнения признаков, измеренных по дихотомической шкале наименований и любым другим, если их результаты могут быть сведены к дихотомической шкале.
29. Критерий Фишера — F — параметрический критерий различий, который позволяет сравнить две дисперсии, полученные в двух выборках. Применяется для сравнения признаков, измеренных по интервальной или пропорциональной шкале при условии нормального распределения признака.
30. Критерий хи-квадрат Пирсона — χ2 — непараметрический критерий, который позволяет сравнить два распределения признака: согласованность изменений в распределениях. Таким методом оцениваются различия между распределениями, а также взаимосвязь между признаками. Применяется для сравнения признаков, измеренных по шкале наименований, шкалам порядка, интервальной или пропорциональной.
31. Кумулята — график, отражающий зависимость между значениями признака и соответствующими им накопленными частотами.с которой отвергается нулевая гипотеза (истинная) и принимается альтернативная гипотеза (ложная),
32. Медиана — Ме — это значение признака, которое делит выборку испытуемых на две равные части: 50 % испытуемых имеют значения признака меньше медианы, 50 % испытуемых имеют значения признака больше медианы; медиана является частным видом квантилей.
33. Мера связи — числовая величина, отражающая тесноту (силу для всех типов измерений) и направленность (для качественно-количественного и количественного измерения) зависимости между признаками.
34. Многомерное шкалирование выявляет шкалы как критерии, по которым поляризуются объекты при их субъективном попарном сравнении.
35. Множественный регрессионный анализ предсказывает значения метрической «зависимой» переменной по множеству известных значений «независимых» переменных, измеренных у множества объектов (испытуемых). Все переменные должны быть измерены в количественной шкале.
36. Мода — Мо — это значение признака, которое имеет наибольшую частоту.
37. Мощность критерия— его способность критерия правильно отбрасывать ложную гипотезу. Она определяется эмпирическим путем.
38. Независимые выборки (не связанные выборки) — это две выборки, составленные из разных людей, у которых были измерены одни и те же признаки по одним и тем же методикам.
39. Непараметрические критерии —критерии, не включающие в формулу расчета параметры распределения и основанные на оперировании частотами или рангами (например, критерий знаков, критерий Ван-дер-Вардена и др.).Непараметрические критерииприменяются для любых шкал и любых распределений признаков.
40. Нулевая гипотеза— это гипотеза об отсутствии зависимости между признаками или отсутствии различий между выборками. Она обозначается как Н0.
41. Ошибка первого рода (р-уровень) — вероятность, с которой отвергается нулевая гипотеза, являющаяся истинной, и принимается альтернативная гипотеза, являющаяся ложной.
42. Параметрические критериислужат для проверки гипотез о параметрах распределений или для их оценивания, то есть, является ли параметр, полученный на выборке испытуемых, и параметром генеральной совокупности. Параметрические критерии применяются для оценки параметров признаков, измеренных по интервальной и пропорциональной шкале при условии нормального распределения признаков.
43. Параметры распределений — числовые характеристики, отражающие основные тенденции выраженности и изменчивости исследуемых признаков в исследуемой выборке.
44. Полигон частотили многоугольник частот— график в виде прямой ломаной линии, отражающий зависимость между значениями признака и мерами возможности их появления.
45. Распределение — график, отражающий зависимость между значениями признака и мерами возможности их появления (вероятностями или частотами).
46. Регрессия— график в виде линии, которая отражает зависимость между условными средними значениями одной переменной и значениями другой переменной.
47. Репрезентативность выборки— свойство выборочной совокупности, заключающееся в ее способности адекватно представлять основные характеристики генеральной совокупности (воспроизводятся основные свойства генеральной совокупности).
48. Среднее арифметическое значение—  — это то значение признака, которое отражает средний уровень выраженности признака в выборке испытуемых.
— это то значение признака, которое отражает средний уровень выраженности признака в выборке испытуемых.
49. Стандартное отклонение(или среднеквадратическое отклонение) —  — это среднее отклонение каждого значения признака от среднего арифметического.
— это среднее отклонение каждого значения признака от среднего арифметического.
50. Статистическая гипотеза— это предположения о свойствах и параметрах генеральной совокупности, различии выборок или зависимости между признаками.
51. Статистический критерий — правило, обеспечивающее надежное поведение, т. е. принятие истинной и отклонение ложной гипотезы с высокой вероятностью. Слова статистический критерий обозначают также метод расчета определенного числа и само это число.
52. Уровень значимости — вероятность ошибочного отклонения нулевой гипотезы.
53. Факторный анализ направлен на выявление структуры переменных как совокупности факторов, каждый из которых — это скрытая, обобщающая причина взаимосвязи группы переменных. Надежные результаты получаются, если переменные измерены в количественной шкале (интервальной или пропорциональной). Число испытуемых должно превышать число переменных (или, по крайней мере, должно быть равно ему).
54. Число степеней свободы — ν=df — количество возможных направлений изменчивости переменной.
55. Шкала наименований (номинативная, номинальная) является результатом использования при измерении метода регистрации; относится к качественному измерению.
56. Шкала порядка (порядковая, ординальная) является результатом использования при измерении метода упорядочивания; относится к качественно-количественному измерению.
57. Шкала равных интервалов (интервальная)является результатом измерения методом соотнесения (с эталонной единицей измерения), нулевая точка шкалы произвольна и не указывает на отсутствие измеряемого свойства; является метрической шкалой и относится к количественному измерению.
58. Шкала равных отношений (пропорциональная)является результатом измерения методом соотнесения (с эталонной единицей измерения), существует абсолютный нуль, который означает отсутствие измеряемого свойства; является метрической шкалой и относится к количественному измерению.
Приложение 3. Англо-русский словарь статистических терминов
Словарь позаимствован из пособия, написанного А. Д. Наследовым. (Наследов А.Д. Математические методы психологического исследования: Анализ и интерпретация данных [Текст]: учебное пособие / А. Д. Наследов. - 3-е изд., стереотип. - СПб.: Речь, 2007. - 392 с.)
Этот словарь может быть полезен при работе с компьютерными пакетами математико-статистического анализа (SРSS или STATISTICA).
| 1- Sample K-S Test— | критерий (тест) Колмогорова-Смирнова |
| 1-tailed— | односторонний (направленный) уровень значимости |
| 2-tailed— | двусторонний (ненаправленный) уровень значимости |
| Absolute value— | абсолютное значение |
| Actual (value, group) — | действительное, реальное (значение, группа) |
| Add — | добавить |
| Adjusted— | исправленный (улучшенный) |
| Advanced (Model)— | специальная, более совершенная (модель) |
| Agglomeration schedule— | последовательность агломерации (объединения) |
| ALSCAL— | программа неметрического многомерного шкалирования |
| Amalgamation— | слияние, объединение |
| Analyze— | анализировать |
| ANOVA— | дисперсионный анализ |
| Approach— | подход |
| Assume— | принятие (допущение, предположение) |
| Asymmetric— | асимметричная |
| Asymp. Sig.— | примерный (приближенный) уровень значимости |
| Average Linkage— | средней связи (метод кластеризации) |
| Averaged— | усредненный |
| Axis— | ось (координат) |
| Bartlett's Test of Sphericity — | тест сферичности Бартлета |
| Based on— | основанный на (исходящий из) |
| Beta-Coefficient— | стандартизированный коэффициент регрессии |
| Between (objects, variables)— | между (объектами, переменными) |
| Between Groups Linkage — | межгрупповой (средней) связи (метод кластеризации) |
| Between-Group — | межгрупповой |
| Between-Subject— | между объектами (межгрупповой) |
| Binary Measures— | количественные показатели (меры) для бинарных данных |
| Binomial Test— | биномиальный критерий |
| Bivariate — | двумерный |
| Box's M-test— | М-тест Бокса |
| Canonical Analysis— | канонический анализ |
| Case— | случай (испытуемый) |
| Casewise deletion— | исключение из анализа случая (строки), в котором имеется пропуск хотя бы одного значения |
| Categories— | категории (номинативного признака) |
| Categorization— | операция выделения интервалов квантования (или значений переменной) при построении гистограммы и составлении таблицы частот |
| Cell— | ячейка (таблицы) |
| Central Tendency— | центральная тенденция (мера) |
| Centroid — | центроид |
| Chi I — | хи-квадрат |
| Chi-square (Test)— | хи-квадрат (критерий) |
| Classify— | классифицировать |
| Cluster Combined— | объединенные кластеры |
| Cluster Method— | метод кластеризации |
| Coefficient (s)— | коэффициент(ы) |
| Column— | столбец |
| Combine— | объединение, объединять |
| Communality— | общность |
| Compare— | сравнивать |
| Compare Means— | сравнение средних |
| Comparison — | сравнение |
| Complete Linkage — | полной связи (метод кластеризации) |
| Compute— | вычисление, вычислять |
| Conditionality— | условность, обусловленность (подгонки) |
| Confidence (Interval) — | доверительный (интервал) |
| Constant— | константа |
| Contrast— | контраст |
| Controlling for...— | контролировать (фиксировать) для... |
| Convergence— | сходимость (при подгонки) |
| Corrected (Model)— | исправленная, скорректированная (модель) |
| Correlate— | коррелировать (определять совместную изменчивость) |
| Correlation matrix— | корреляционная матрица |
| Count Measure— | количественный показатель (мера) частоты |
| Covariance— | ковариация |
| Covariate— | ковариата |
| Criteria (Criterion)— | условие (критерий) |
| Crosstabulation (Crosstab)— | сопряженность, кросстабуляция |
| Cumulative frequencies — | —кумулятивные (накопленные) частоты |
| Custom Model— | специальная модель |
| Cut Point— | точка деления |
| Data— | данные |
| Data Editor— | редактор (таблица) исходных данных в SPSS |
| Data Reduction— | сокращение данных (метод) |
| Define (Groups)— | определение, задание (групп) |
| Degrees of freedom (df)— | число степеней свободы |
| Deletion— | удаление (исключение) |
| Dendrogram— | дендрограмма (древовидный график) |
| Density Function— | функция плотности вероятности |
| Dependent Sample— | зависимая выборка |
| Dependent-Samples T Test — | критерий t-Стьюдента для зависимых выборок |
| Derived— | производный |
| Descriptive Statistics— | описательные статистики |
| df— | число степеней свободы (сокр.) |
| Difference— | разность, различие |
| Dimension — | шкала |
| Discriminant Analysis— | дискриминантный анализ |
| Dispersion— | изменчивость |
| Dissimilarity — | различие |
| Distance— | расстояние |
| Distribution — | распределение |
| Distribution Function — | функция распределения (вероятности) |
| Effect— | влияние (фактора) |
| Eigenvalue— | собственное значение |
| Enter— | исходный (метод) |
| Entry— | включение |
| Epsilon Corrected— | с Эпсилон-коррекцией |
| Equal — | одинаковые |
| Equal Variances— | одинаковые (эквивалентные) дисперсии |
| Equality (of Variances) — | эквивалентность, равенство (дисперсии) ошибка |
| Error— | оценка |
| Estimate — | Евклидово расстояние |
| Euclidean Distance— | точный, точно |
| Exact— | точный уровень значимости |
| Exact Sig.— | исключение (объектов) |
| Exclude (cases)— | ожидаемая (теоретическая) частота (значение) |
| Expected Frequency (Value) — | «объясненная» (дисперсия) |
| Explained (Variance)— | метод факторизации (экстракции факторов) |
| Extraction Method— | фактор |
| Factor— | факторный анализ |
| Factor Analysis— | факторные нагрузки |
| Factor Loadings— | коэффициенты факторных оценок |
| Factor Score coefficients— | факторные оценки |
| Factor Scores — | точный критерий Фишера |
| Fisher's Exact Test— | постоянный, фиксированный (фактор) |
| Fixed (Factor)— | для всей матрицы |
| For Matrix— | значение Р-критерия (Р-отношения) для дисперсий |
| F-ratio Variances— | частота |
| Frequency— | таблицы частот |
| Frequency tables— | критерий Фридмана |
| Friedman test (ANOVA) — | модель, включающая все факторы |
| Full factorial model— | дальнего соседа (метод кластеризации) |
| Furthest Neighbor— | общая линейная модель |
| General Linear Model— | обобщенный метод |
| Generalized least squares— | наименьших квадратов |
| GLM — | общая линейная модель (сокр.) |
| Goodness-of-fit — | качество подгонки |
| Group Membership— | принадлежность к группе |
| Group Plots— | график(и) для всей группы |
| Grouping Variable— | группирующая переменная |
| Han Hierarchical Cluster Analysis — | иерархический кластерный анализ |
| Histogram— | гистограмма |
| Homogeneity of Variances— | гомогенность (однородность) дисперсий горизонтальная (ориентация) |
| Horizontal— | факторный анализ образов |
| Image Factoring— | улучшение (с поправкой) |
| Improvement— | включение |
| Independent Sample— | независимая выборка |
| Independent-Samples T Test— | критерий t-Стьюдента для независимых выборок |
| Individual Differences (model) — | индивидуальных различий (модель) |
| INDSCALE— | программа многомерного шкалирования индивидуальных различий |
| Initial (conditions)— | начальные (условия) |
| Input File— | исходный, входящий файл |
| Interaction— | взаимодействие |
| Intercept— | свободный член (уравнения) |
| Interval— | интервальная (шкала) |
| Interval data— | данные в интервальной шкале |
| Interval Scale— | интервальная шкала |
| Inverse distribution function— | обратная функция распределения итерация |
| Iteration— | итерация |
| Iteration history— | «история» (последовательность) итераций |
| Iterations stopped...— | итерации остановлены... |
| Joining— | объединение, связь |
| Kendall's tau— | тау-Кендалла (корреляция) |
| Kendall's tau-b— | тау-b Кендалла (корреляция) |
| Kruskal-Wallis H— | критерий Н-Краскала Уоллеса |
| Kruskal-Wallis one-way analysis of variance — | однофакторный дисперсионный анализ Краскала-Уоллеса |
| Kurtosis— | эксцесс |
| Label— | метка, обозначение |
| Level— | уровень |
| Level of Measurement— | уровень (шкала) измерения |
| Levene's Test— | критерий Ливена |
| Linear Regression— | линейный регрессионный |
| Linkage— | соединение, связь |
| List— | список |
| Listwise — | построчно |
| Listwise Deletion— | исключение из анализа случая (строки), в котором имеется пропуск хотя бы одного значения |
| Loading— | нагрузка |
| Mann-Whitney U— | критерий U-Манна-Уитни |
| MANOVA— | многомерный дисперсионный анализ |
| Marginal (Means)— | отдельные (средние значения) |
| Matrices— | матрицы |
| Matrix— | матрица |
| Mauchly's Test of Sphericity — | тест сферично сти |
| MoynjiM Maximum Likelihood — | максимального правдоподобия (метод) |
| McNemar Test— | критерий Мак-Нимара |
| Mean — | среднее |
| Mean of Squares (MS) — | средний квадрат |
| Mean Substitution— | замена пропущенных значений средними |
| Means Plot— | график средних значений |
| Measurement — | измерение |
| Median — | медиана |
| Missing (Values)— | пропущенные (значения) |
| M-L (Maximum likelihood) — | максимального правдоподобия (метод, оценка) |
| Mode — | мода |
| Monte Carlo Method — | статистический метод «Монте-Карло» |
| Multidimensional Scaling — | многомерное шкалирование |
| Multiple— | множественный |
| Multiple comparisons — | множественные сравнения (средних) |
| Multivariate— | многомерный |
| Multivariate Approach— | многомерный подход |
| Nearest Neighbor— | ближайшего соседа (метод кластеризации) |
| Negative — | отрицательный |
| Next — | следующий |
| Nominal— | номинальная (шкала) |
| Nonparametric Test— | непараметрический критерий |
| Normal Curve— | нормальная кривая |
| Number— | количество (численность), номер |
| Observed Frequency— | наблюдаемая (эмпирическая) частота |
| Observed Prop.— | наблюдаемое (эмпирическое) соотношение |
| One-Sample Kolmogorov-SmirnovTest — | критерий (тест) Колмогорова-Смирнова |
| One-Sample T Test— | критерий t-Стьюдента для одной выборки |
| One-tailed (one-sided)— | односторонний критерий (для проверки односторонних гипотез); one-tailed — дословно однохвостый |
| One-Way ANOVA— | однофакторный дисперсионный анализ |
| Ordinal (Rank order)— | порядковая (ранговая) (шкала) |
| Paired-Samples T Test— | критерий t-Стьюдента для зависимых выборок |
| Pairwise— | попарно, попарный |
| Partial Correlation— | частная корреляция (коэффициент) |
| Pearson Chi-Square — | критерий хи-квадрат Пирсона |
| Pearson correlation— | корреляция Пирсона |
| Pearson r— | корреляция Пирсона |
| Percentage— | процент |
| Percentiles— | процентили |
| Mean of Squares (MS) — | фи-коэффициент сопряженности |
| Phi 4-points correlation — | (четырехклеточный) фи—коэффициент сопряженности (Пирсона) |
| Pillai's Trace— | след Пиллая |
| P-Ievel— | статистическая значимость (р-уровень) |
| Plot— | диаграмма |
| Polynomial— | полином (многочлен) |
| Post Hoc — | апостериорный (после подтверждения гипотезы) |
| P-P Plot— | график накопленных частот |
| Predicted (value, group)— | предсказанное (значение, группа) |
| Principal Axis Factoring — | факторный анализ методом главных осей |
| Principal Components— | главных компонент (анализ) |
| Prior probabilities— | априорные вероятности |
| Probability— | вероятность |
| Probability of group membership—Proximity— | вероятность принадлежности к группе |
| Proximality — | близость |
| PROXSCAL— | программа неметрического многомерного шкалирования |
| Q-Q Plot— | квантильный график |
| Quantile — | квантиль |
| Quartile — | квартиль |
| R Square (R2)— | коэффициент детерминации (квадрат коэффициента корреляции) |
| Random (Factor)— | случайный (фактор) |
| Range — | размах |
| Rank — | ранг |
| Rank (Cases)— | ранжировать (объекты) |
| Ratio— | абсолютная шкала (равных отношений) |
| Raw — | строка |
| Raw Data— | данные в строках (типа «объект-признак») |
| Rectangular (matrix)— | прямоугольная (матрица) |
| Regression— | регрессионный |
| Regression Coefficient— | коэффициент регрессии |
| Regression Line— | линия регрессии |
| Related Samples— | зависимые (связанные) выборки |
| Removal— | удаление |
| Repeated Measures— | повторные измерения |
| Repeated Measures ANOVA — | дисперсионный анализ с повторными измерениями |
| Residual— | остаток, отклонение (ошибка модели) |
| Residual analysis— | анализ остатков (ошибок) |
| Rotation (Factors)— | вращение (факторов) |
| Rotation Method— | метод вращения |
| Row — | строка |
| RSQ (R-square)— | квадрат коэффициента корреляции, коэффициент дискриминации (г-квадрат) |
| Run — | серия |
| Runs Test— | критерий серий |
| Sample— | выборка |
| Scaling model— | модель шкалирования |
| Scatter Plot— | диаграмма рассеивания |
| Scheffé test— | метод Шеффе (множественных сравнений средних) |
| Scree plot— | график собственных значений |
| Scree-test— | критерий отсеивания |
| Scrollsheet— | таблица результатов статистического анализа |
| Separate (Line)— | отдельная (линия) |
| Set — | множество |
| Shape — | уточнить |
| Sig. — | уровень значимости (р-уровень) |
| Sign— | знак |
| Sign Test— | критерий знаков |
| Significance Level— | уровень статистической значимости (р-уровень) |
| Significant— | статистически значимый |
| Similarity— | сходство |
| Simple— | простой |
| Simple Matching— | простой коэффициент совстречаемости (бинарный) |
| Single Linkage— | одиночной связи (метод кластеризации) |
| Size difference— | величина различий (бинарная) |
| Skewness— | асимметрия |
| Slope— | уклон, наклон (прямой по отношению к оси X), значение коэффициента регрессии |
| Solution— | решение (выбор) |
| Source— | источник (изменчивости, влияния) |
| Spearman's rho (r)— | корреляция Спирмена (коэффициент) |
| Specify— | определять |
| Spreadsheet— | электронная таблица для исходных данных |
| SPSS— | компьютерная программа «Статистический пакет для социальных наук» (сокр.) |
| Square asymmetric (symmetric) matrix — | квадратная асимметричная (симметричная) матрица |
| Squared (Euclidean distance) — | квадрат (Евклидова расстояния) |
| S-stress convergence— | величина сходимости 8-стресса |
| Stage — | ступень (этап, шаг) |
| Standard deviation— | стандартное отклонение (сигма) |
| Standard error— | стандартная ошибка |
| Standardized (Beta-) Coefficients — | стандартизированные (бета-) коэффициенты регрессии |
| STATISTICA— | компьютерная программа для статистического анализа данных |
| Statistical Test— | статистический критерий (тест) |
| Std. Deviation— | стандартное отклонение (сигма) |
| Std. Error— | стандартная ошибка |
| Step— | шаг |
| Stepwise Method— | пошаговый метод |
| Stimulus— | стимулы |
| Stress — | стресс, в многомерном шкалировании |
| Stub-and-Banner Tables— | таблицы сопряженности для двух и более признаков |
| Subject— | субъект |
| Subject Weight— | индивидуальный вес |
| Subset— | подмножество |
| Sum — | сумма |
| Sum of Squares(SS) — | сумма квадратов |
| Summary — | итог |
| Suppress— | скрыть |
| Symmetric— | симметричная |
| Syntax— | командный файл в SPSS |
| Table— | таблица |
| Test— | статистический критерий |
| Test Prop.— | ожидаемое (теоретическое) соотношение |
| Test Statistics— | результаты статистической проверки |
| Test Value— | заданное (тестовое) значение |
| Tied Ranks— | связанные (повторяющиеся) ранги |
| Ties (of ranks)— | связи, повторы (рангов) |
| Total— | итог (сумма) |
| Transform (Values, Measures)— | преобразование (значений, мер) |
| Tree Diagram— | древовидная диаграмма |
| Two-tailed (two-sided)— | двусторонний критерий (для проверки двусторонних гипотез) |
| Univariate (procedure, approach) — | одномерный (метод, подход) |
| Unrotated— | до вращения |
| Unstandardized Coefficient — | коэффициент регрессии (не стандартизированный) |
| Untie tied observation — | разъединять (различать) связанные (одинаковые) данные |
| Unweighted least squares — | метод не взвешенных наименьших квадратов |
| Valid n— | число случаев, по которому были проведены расчеты |
| Value— | значение |
| Var — | переменная (сокр.) |
| Variable— | переменная (признак) |
| Variable List— | список переменный |
| Variance— | дисперсия |
| Varimax | метод варимакс (вращения факторов) |
| Vertical— | вертикальная (ориентация) |
| Weight— | вес |
| Wilcoxon Signed-rank (Matched pairs) test — | критерий Т-Вилкоксона |
| Wilcoxon test— | критерий Вилкоксона |
| Wilks' Lambda— | лямбда Вилкса |
| Within— | внутри |
| Within-Group— | внутригрупповой |
| Within-Subject— | внутри объектов (внутригрупповой) |
| XI — | хи-квадрат критерий |
| Yates' corrected— | с поправкой Йетса |
| Yule's Q— | Юла Q-коэффициент |
| Z-score — | z-значение |
| |
[1] Аддитивность — (от лат. additivus – прибавляемый; матем.: свойство по значению; прил. - аддитивный) — свойство величин, состоящее в том, что значение величины, соответствующее целому объекту, равно сумме значений величин, соответствующих его частям, при любом разбиении объекта на части. Следовательно, можно утверждать, что для данных показателей соблюдается правило аддитивности: уровень характеристики целого складывается из значений данной характеристики отдельных компонентов с учетом их доли в составе целого (http://ru.wiktionary.org/wiki/аддитивность).
[2] Единицей измерения в стандартизованных шкалах является стандартное отклонение, полученное на выборке стандартизации.
[3] Полный набор событий.
[4] Закон Лапласа-Гаусса (по имени ученых, независимо открывших и исследовавших его) из-за широкого распространения в природе первоначально принимался за норму распределения любой случайной величины. Этим и обусловлено название "нормальный" закон.
[5] Знак расчетной меры взаимосвязи интерпретируется только для зависимостей между признаками, измеренными по шкале порядка, интервальной или пропорциональной шкале. Для взаимосвязей признаков, измеренных по шкале наименований, знак не интерпретируется, так как он зависит от расположения градаций (значений) признака, которые в данной шкале не могут быть упорядочены, так как в ней не применяется операция сравнения «больше — меньше».
[6] Суходольский Г.В. Основы математической статистики для психологов [Текст]: учебник / Г. В. Суходольский. - СПб.: Изд-во СПбГУ, 1998. - 464 с. - Стр. 279.
[7] При сравнении эмпирического и теоретического распределений вместо частот второго эмпирического распределения следует ввести в таблицу частоты теоретического распределения.
– Конец работы –
Используемые теги: психологии, социальной, работы0.039
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Психологии и Социальной Работы
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.117 сек.
Новости и инфо для студентов