Структурное моделирование
Подтверждающий факторный анализ предполагает, что мы уже получили модель и её остается только проверить на адекватность и корректность.
Структурное моделирование предполагает, что мы изначально представляем, как примерно должна выглядеть полученная модель.
У нас есть следующие данные:

Где «цена» является зависимой переменной, а остальные – независимыми.
Проведём структурное моделирование, чтобы сократить количество независимых переменных и упростить структуру будущей регрессионной модели.
Для дальнейшего моделирование необходимо создать диаграмму путей SEPATH, которая будет служить своеобразным макетом.
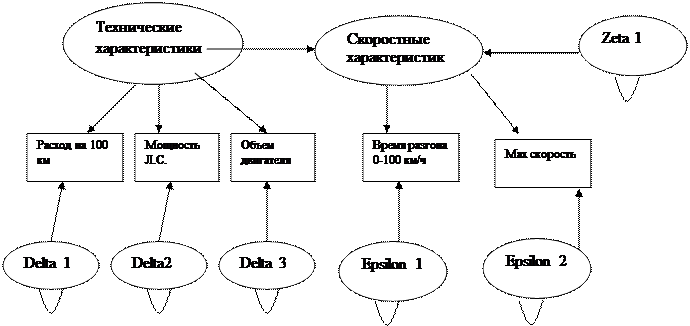
Логика составления диаграммы такова: три переменных «расход на 100 км», «Объем двигателя» и «мощность л.с.» являются техническими характеристиками, а переменные «время разгона 0-100 км/ч» и «max скорость» – скоростными характеристиками. Также необходимо внести в модель и тот факт, что между техническими и скоростными характеристиками может присутствовать связь, т.е. корреляция. Также нельзя исключать и другие связи между переменными, поэтому в случае получения некорректной модели на основании данной диаграммы, необходимо будет внести некоторое изменения.
В результате получаем модель на языке PATH1
(технические характер)-1->[расходп ]
(технические характер)-2->[мощ. л.с]
(технические характер)-3->[объем дв]
(технические характер)-1->[расходп ]
(технические характер)-2->[мощ. л.с]
(технические характер)-3->[объем дв]
(DELTA1)-->[расходп ]
(DELTA2)-->[мощ. л.с]
(DELTA3)-->[объем дв]
(DELTA1)-4-(DELTA1)
(DELTA2)-5-(DELTA2)
(DELTA3)-6-(DELTA3)
(скоростные характери)-->[время ра]
(скоростные характери)-7->[max скор]
(EPSILON1)-->[время ра]
(EPSILON2)-->[max скор]
(EPSILON1)-8-(EPSILON1)
(EPSILON2)-9-(EPSILON2)
(ZETA1)-->(скоростные характери)
(ZETA1)-10-(ZETA1)
(технические характер)-11->(скоростные характери)
Реализуем данную модель:

Необходимо отметить, что запись (скоростные характеристики)-->[время разгона 0-100км/ч] означает, что по умолчанию корреляция здесь фиксирована и равна 1. Это делается для того, чтобы точно определить на диаграмме дисперсии латентных эндогенных факторов.
Все коэффициенты корреляции между факторами и исходными переменными значимы при уровне значимости p=0. T-статистика отражает значение критерия для гипотезы, что значение параметра равно нулю. Отвержение гипотезы означает, что параметр не равен нулю с уровнем значимости p и он должен быть включен в модель.
Все дисперсии остатков значимы при p близком к нулю, за исключением Delta1, которая значима при уровне значимости > 0,518.Также значим коэффициент корреляции между двумя полученными факторами при уровне значимости p=0.
Модель нельзя считать адекватной, т.к. она имеет существенные недостатки: факторная нагрузка между «скоростные характеристики» и «время разгона 0-100 км/ч» принимается по умолчанию 1; кроме того, Delta1 значима на слишком большом уровне 0.518, т.е. гипотеза, что значение параметра равно нулю, отклоняется при вероятности ошибки в 51,8 %.
Основная итоговая статистика:
Абсолютно совпадает с результатами модели подтверждающего факторного анализа.
На основании полученных результатов можно сделать вывод, что модель хоть и удовлетворяет многим условиям адекватности, она не применима к исходным данным, так как не отображает реальные связи.
Попробуем реализовать ещё одну модель:
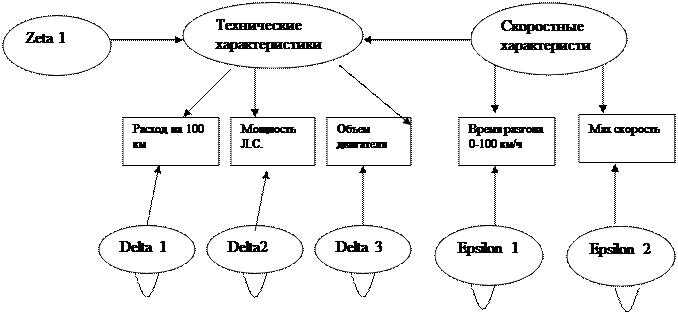
Результаты:

Все коэффициенты корреляции между факторами и исходными переменными значимы при уровне значимости p=0. T-статистика отражает значение критерия для гипотезы, что значение параметра равно нулю. Отвержение гипотезы означает, что параметр не равен нулю с уровнем значимости p и он должен быть включен в модель.
Все дисперсии остатков значимы при p близком к нулю, за исключением Delta 1, которая значима при уровне значимости > 0,518
Также значим коэффициент корреляции между двумя полученными факторами при уровне значимости p=0.