рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Компьютеры
- /
- Потоки.
Реферат Курсовая Конспект
Потоки.
Потоки. - раздел Компьютеры, Изучение операционной системы Windows В Любом Процессе Должен Быть Хотя Бы Один Поток. Подобно Процессам, Потоки Об...
В любом процессе должен быть хотя бы один поток. Подобно процессам, потоки обладают определенными свойствами, поэтому мы поговорим о функциях, позволяющих обращаться к этим свойствам и при необходимости модифицировать их.
В главе 4.1 сказано, что процесс фактически состоит из двух компонентов объекта ядра "процесс" и адресного пространства так вот, любой поток тоже состоит из двух компонентов:
· объекта ядра, через который операционная система управляет потоком. Там же хранится статистическая информация о потоке;
· стека потока, который содержит параметры всех функций и локальные переменные, необходимые потоку для выполнения кода.
Процессы инертны. Процесс ничего не исполняет, он просто служит контейнером потоков. Потоки всегда создаются в контексте какого-либо процесса, и вся их жизнь проходит только в его границах. На практике это означает, что потоки исполняют код и манипулируют данными в адресном пространстве процесса. Поэтому, если два и более потоков выполняется в контексте одного процесса, все они делят одно адресное пространство. Потоки могут исполнять один и тот же код и манипулировать одними и теми же данными, а также совместно использовать описатели объектов ядра, поскольку таблица описателей создается не в отдельных потоках, а в процессах.
Как видите, процессы используют куда больше системных ресурсов, чем потоки. Причина кроется в адресном пространстве. Создание виртуального адресного пространства для процесса требует значительных системных ресурсов. При этом ведется масса всяческой статистики, на что уходит немало памяти. В адресное пространство загружаются EXE- и DLL-файлы, а значит, нужны файловые ресурсы. С другой стороны, потоку требуются лишь соответствующий объект ядра и стек, объем статистических сведений о потоке невелик и много памяти не занимает.
Так как потоки расходуют существенно меньше ресурсов, чем процессы, старайтесь решать свои задачи за счет использования дополнительных потоков и избегайте создания новых процессов. Только не принимайте этот совет за жесткое правило — многие проекты как paз лучше реализовать на основе множества процессов Нужно просто помнить об издержках и соразмерять цель и средства.
Поток может быть создан при помощи функции CreateThread. Рассмотрим параметры этой функции.
· 1-й параметр. Указатель на структуру атрибутов доступа. Имеет значение только для Windows NT. Обычно полагается NULL.
· 2-й параметр. Размер стека потока. Если параметр равен нулю, то берется размер стека по умолчанию, равный размеру стека родительского потока.
· 3-й параметр. Указатель на потоковую функцию, с вызова которой начинается исполнение потока.
· 4-й параметр. Параметр для потоковой функции.
· 5-й параметр. Флаг, определяющий состояние потока. Если флаг равен 0, то выполнение потока начинается немедленно. Если значение флага потока равно CREATE_SUSPENDED (4H), то поток находится в состояние ожидания и запускается по выполнению функции ResumeThread.
· 6-й параметр. Указатель на переменную, куда будет помещен дескриптор потока.
Как уже было сказано, выполнение потока начинается с потоковой функции. Окончание работы этой функции приводит к естественному окончанию работы потока. Поток также может закончить свою работу, выполнив функцию ExitThread с указанием кода выхода. Наконец, порождающий поток может закончить работу порожденного потока при помощи функции TerminateThread.
2. Управление памятью в операционных системах
Оперативная память — это важнейший ресурс любой вычислительной системы, поскольку без нее (как, впрочем, и без центрального процессора) невозможно выполнение ни одной программы. От выбранных механизмов распределения памяти между выполняющимися процессорами в значительной степени зависит эффективность использования ресурсов системы, ее производительность, а также возможности, которыми могут пользоваться программисты при создании своих программ. Желательно так распределять память, чтобы выполняющаяся задача имела возможность обратиться по любому адресу в пределах адресного пространства той программы, в которой идут вычисления.
С другой стороны, поскольку любой процесс имеет потребности в операциях ввода-вывода, и процессор достаточно часто переключается с одной задачи на другую, желательно в оперативной памяти расположить достаточное количество активных задач с тем, чтобы процессор не останавливал вычисления из-за отсутствия очередной команды или операнда. Некоторые ресурсы, которые относятся к неразделяемым, из-за невозможности их совместного использования делают виртуальными. Таким образом, чтобы иметь возможность выполняться, каждый процесс может получить некий виртуальный ресурс. Виртуализация ресурсов делается программным способом средствами операционной системы, а значит, для них тоже нужно иметь ресурс памяти. Поэтому вопросы организации разделения памяти для выполняющихся процессов и потоков являются очень актуальными, ибо выбранные и реализованные алгоритмы решения этих вопросов в значительной степени определяют и потенциальные возможности системы, и общую ее производительность, и эффективность использования имеющихся ресурсов.
2.1 Память и отображения, виртуальное адресное пространство
Если не принимать во внимание программирование на машинном языке (эта технология практически не используется уже очень давно), то можно сказать, что программист обращается к памяти с помощью некоторого набора логических имен, которые чаще всего являются символьными, а не числовыми, и для которого отсутствует отношение порядка. Другими словами, в общем случае множество переменных в программе не упорядочено, хотя отдельные переменные могут иметь частичную упорядоченность (например, элементы массива). Имена переменных и входных точек программных модулей составляют пространство символьных имен. Иногда это адресное пространство называют логическим.
С другой стороны, при выполнении программы мы имеем дело с физической оперативной памятью, собственно с которой и работает процессор, извлекая из нее команды и данные и помещая в нее результаты вычислений. Физическая память представляет собой упорядоченное множество ячеек реально существующей оперативной памяти, и все они пронумерованы, то есть к каждой из них можно обратиться, указав ее порядковый номер (адрес). Количество ячеек физической памяти ограниченно и фиксировано.
Системное программное обеспечение должно связать каждое указанное пользователем символьное имя с физической ячейкой памяти, то есть осуществить отображение пространства имен на физическую память компьютера. В общем случае это отображение осуществляется в два этапа (рис. 2.1): сначала системой программирования, а затем операционной системой. Это второе отображение осуществляется с помощью соответствующих аппаратных средств процессора — подсистемы управления памятью, которая использует дополнительную информацию, подготавливаемую и обрабатываемую операционной системой.
Между этими этапами обращения к памяти имеют форму виртуального адреса. При этом можно сказать, что множество всех допустимых значений виртуального адреса для некоторой программы определяет ее виртуальное адресное пространство, или виртуальную память. Виртуальное адресное пространство программы зависит, прежде всего, от архитектуры процессора и от системы программирования и практически не зависит от объема реальной физической памяти компьютера. Можно еще сказать, что адреса команд и переменных в машинной программе, подготовленной к выполнению системой программирования, как раз и являются виртуальными адресами.
Как мы знаем, система программирования осуществляет трансляцию и компоновку программы, используя библиотечные программные модули. В результате работы системы программирования, полученные виртуальные адреса могут иметь как двоичную форму, так и символьно-двоичную. Это означает, что некоторые программные модули (их, как правило, большинство) и их переменные получают какие-то числовые значения, а те модули, адреса для которых пока не могут быть определены, имеют по-прежнему символьную форму, и их окончательная привязка к физическим ячейкам будет осуществлена на этапе загрузки программы в память перед ее непосредственным выполнением.
2.2 Виртуальное адресное пространство
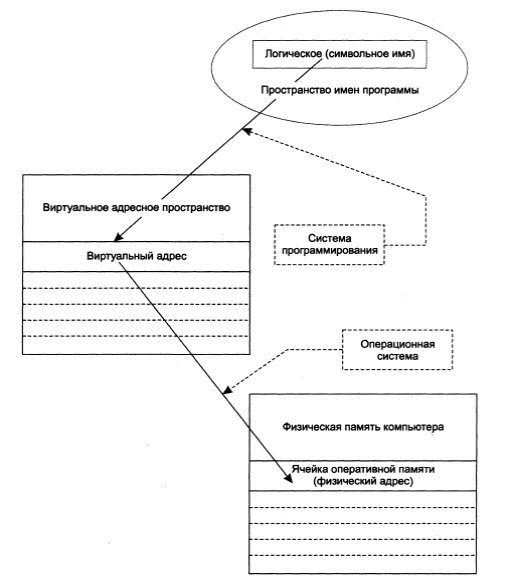
Рис. 2.1. Память и отображения
Одним из частных случаев отображения пространства символьных имен на физическую память является полная тождественность виртуального адресного пространства физической памяти. При этом нет необходимости осуществлять второе отображение. В таком случае говорят, что система программирования генерирует абсолютную двоичную программу; в этой программе все двоичные адреса таковы, что программа может исполняться только тогда, когда ее виртуальные адреса будут точно соответствовать физическим. Часть программных модулей любой операционной системы обязательно должна быть абсолютными двоичными программами. Эти программы размещаются по фиксированным адресам физической памяти, и с их помощью уже можно впоследствии реализовывать размещение остальных программ, подготовленных системой программирования таким образом, что они могут работать на различных физических адресах (то есть на тех адресах, на которые их разместит операционная система). В качестве примера таких программ можно назвать программы загрузки операционной системы.
Другим частным случаем этой общей схемы трансляции адресного пространства является тождественность виртуального адресного пространства исходному логическому пространству имен. Здесь уже отображение выполняется самой операционной системой, которая во время исполнения использует таблицу символьных имен. Такая схема отображения используется чрезвычайно редко, так как отображение имен на адреса необходимо выполнять для каждого вхождения имени (каждого нового имени), и особенно много времени тратится на квалификацию имен. Данную схему можно было встретить в интерпретаторах, в которых стадии трансляции и исполнения практически неразличимы. Это характерно для простейших компьютерных систем, в которых вместо операционной системы использовался встроенный интерпретатор (например, Basic).
Возможны и промежуточные варианты. В простейшем случае транслятор-компилятор генерирует относительные адреса, которые, по сути, являются виртуальными адресами, с последующей настройкой программы на один из непрерывных разделов. Второе отображение осуществляется перемещающим загрузчиком. После загрузки программы виртуальный адрес теряется, и доступ выполняется непосредственно к физическим ячейкам. Более эффективное решение достигается в том случае, когда транслятор вырабатывает в качестве виртуального адреса относительный адрес и информацию о начальном адресе, а процессор, используя подготавливаемую операционной системой адресную информацию, выполняет второе отображение не один раз (при загрузке программы), а при каждом обращении к памяти.
Термин виртуальная память фактически относится к системам, которые сохраняют виртуальные адреса во время исполнения. Так как второе отображение осуществляется в процессе исполнения задачи, то адреса физических ячеек могут изменяться. При правильном применении такие изменения улучшают использование памяти, избавляя программиста от деталей управления ею, и даже повышают надежность вычислений.
2.3 Распределение памяти статическими и динамическими разделами
Для организации мультипрограммного и/или мульти задачного режима необходимо обеспечить одновременное расположение в оперативной памяти нескольких задач (целиком или частями). Память задаче может выделяться одним сплошным участком (в этом случае говорят о методах неразрывного распределения памяти) или несколькими порциями, которые могут быть размещены в разных областях памяти (тогда говорят о методах разрывного распределения).
Начнем с методов неразрывного распределения памяти. Самая простая схема распределения памяти между несколькими задачами предполагает, что память, не занятая ядром операционной системы, может быть разбита на несколько непрерывных частей — разделов (partitions, regions). Разделы характеризуются именем, типом, границами (как правило, указываются начало раздела и его длина).
Разбиение памяти на несколько непрерывных (неразрывных) разделов может быть фиксированным (статическим) либо динамическим (то есть процесс выделения нового раздела памяти происходит непосредственно при появлении новой задачи). Вначале мы кратко рассмотрим статическое распределение памяти на разделы.
2.4 Разделы с фиксированными границами
Разбиение всего объема оперативной памяти на несколько разделов может осуществляться единовременно (то есть в процессе генерации варианта операционной системы, который потом и эксплуатируется) или по мере необходимости оператором системы. Однако и во втором случае при разбиении памяти на разделы вычислительная система более ни для каких целей в этот момент не используется. Пример разбиения памяти на несколько разделов приведен на рис. 2.2.
В каждом разделе в каждый момент времени может располагаться по одной программе (задаче). В этом случае по отношению к каждому разделу можно применить все те методы создания программ, которые используются для однопрограммных систем. Возможно использование оверлейных структур, что позволяет создавать большие сложные программы и в то же время поддерживать коэффициент мультипрограммирования на должном уровне. Первые мультипрограммные операционные системы строились по этой схеме. Использовалась эта схема и много лет спустя при создании недорогих вычислительных систем, поскольку является несложной и обеспечивает возможность параллельного выполнения программ. Иногда в некотором разделе размещалось по нескольку небольших программ, которые постоянно в нем и находились. Такие программы назывались ОЗУ-резидентными (или просто резидентными). Та же схема используется и в современных встроенных системах; правда, для них характерно, что все программы являются резидентными, и внешняя память во время работы вычислительного оборудования не используется.

Рис. 2.2. Распределение памяти разделами с фиксированными границами
При небольшом объеме памяти и, следовательно, небольшом количестве разделов увеличить число параллельно выполняемых приложений (особенно когда эти приложения интерактивны и во время своей работы фактически не используют процессорное время, а в основном ожидают операций ввода-вывода) можно за счет замены их в памяти, или свопинга (swapping). При свопинге задача может быть целиком выгружена на магнитный диск (перемещена во внешнюю память), а на ее место загружается либо более привилегированная, либо просто готовая к выполнению другая задача, находившаяся на диске в приостановленном состоянии. При свопинге из основной памяти во внешнюю (обратно) перемещается вся программа, а не ее отдельная часть.
Серьезная проблема, которая возникает при организации мультипрограммного режима работы вычислительной системы, — защита как самой операционной системы от ошибок и преднамеренного вмешательства процессов в ее работу, так и самих процессов друг от друга.
В самом деле, программа может обращаться, к любым ячейкам в пределах своего виртуального адресного пространства. Если система отображения памяти не содержит ошибок, и в самой программе их тоже нет, то возникать ошибок при выполнении программы не должно. Однако в случае ошибок адресации, что случается не так уж и редко, исполняющаяся программа может начать «обработку» чужих данных или кодов с непредсказуемыми последствиями. Одной из простейших, но достаточно эффективных мер является введение регистров защиты памяти. В эти регистры операционная система заносит граничные значения области памяти раздела текущего исполняющегося процесса. При нарушении адресации возникает прерывание, и управление передается супервизору операционной системы. Обращения задач к операционной системе за необходимыми сервисами осуществляются не напрямую, а через команды программных прерываний, что обеспечивает передачу управления только в предопределенные входные точки кода операционной системы и в системном режиме работы процессора, при котором регистры защиты памяти игнорируются. Таким образом, выполнение функции защиты требует введения специальных аппаратных механизмов, используемых операционной системой.
Основным недостатком рассматриваемого способа распределения памяти является наличие порой достаточно большого объема неиспользуемой памяти (см. рис. 2.2). Неиспользуемая память может быть в каждом из разделов. Поскольку разделов несколько, то и неиспользуемых областей получается несколько, поэтому такие потери стали называть фрагментацией памяти, В отдельных разделах потери памяти могут быть очень значительными, однако использовать фрагменты свободной памяти при таком способе распределения не представляется возможным. Желание разработчиков сократить столь значительные потери привело их к следующим двум решениям:
• выделять раздел ровно такого объема, который «нужен под текущую задачу;
• размещать задачу не в одной непрерывной области памяти, а в нескольких областях.
Второе решение было реализовано в нескольких способах организации виртуальной памяти. Мы их обсудим в следующем разделе, а сейчас кратко рассмотрим первое решение.
2.5 Разделы с подвижными границами
Чтобы избавиться от фрагментации, можно попробовать размещать в оперативной памяти задачи плотно, одну за другой, выделяя ровно столько памяти, сколько задача требует. Одной из первых операционных систем, в которой был реализован такой способ распределения памяти, была OS MVT (Multiprogramming with a Variable number of Tasks — мультипрограммирование с переменным числом задач). В этой операционной системе специальный планировщик (диспетчер памяти) ведет список адресов свободной оперативной памяти. При появлении новой задачи диспетчер памяти просматривает этот список и выделяет для задачи раздел, объем которой либо равен необходимому, либо чуть больше, если память выделяется не ячейками, а некими дискретными единицами. При этом модифицируется список свободных областей памяти. При освобождении раздела диспетчер памяти пытается объединить освобождающийся раздел с одним из свободных участков, если таковой является смежным.
При этом список свободных участков памяти может быть упорядочен либо по адресам, либо по объему. Выделение памяти под новый раздел может осуществляться одним из трех основных способов:
• первый подходящий участок;
• самый подходящий участок;
• самый неподходящий участок.
В первом случае список свободных областей упорядочивается по, адресам (например, по возрастанию адресов). Диспетчер просматривает список и выделяет задаче раздел в той области, которая первой подойдет по объему. В этом случае, если такой фрагмент имеется, то в среднем необходимо просмотреть половину списка. При освобождении раздела также необходимо просмотреть половину списка. Правило «первый подходящий» приводит к тому, что память для небольших задач преимущественно будет выделяться в области младших адресов, и, следовательно, это увеличит вероятность того, что в области старших адресов будут образовываться фрагменты достаточно большого объема.
Способ «самый подходящий» предполагает, что список свободных областей упорядочен по возрастанию объема фрагментов. В этом случае при просмотре списка для нового раздела будет использован фрагмент свободной памяти, объем которой наиболее точно соответствует требуемому. Требуемый раздел будет определяться по-прежнему в результате просмотра в среднем половины списка. Однако оставшийся фрагмент оказывается настолько малым, что в нем уже вряд ли удастся разместить еще какой-либо раздел. При этом получается, что вновь образованный фрагмент попадет в начало списка, и в последующем его придется каждый раз проверять на пригодность, тогда как его малый размер вряд ли окажется подходящим. Поэтому в целом такую дисциплину нельзя назвать эффективной.
Как ни странно, самым эффективным способом, как правило, является последний, по которому для нового раздела выделяется «самый неподходящий» фрагмент свободной памяти. Для этой дисциплины список свободных областей упорядочивается по убыванию объема свободного фрагмента. Очевидно, что если есть такой фрагмент памяти, то он сразу же и будет найден, и, поскольку этот фрагмент является самым большим, то, скорее всего, после выделения из него раздела памяти для задачи оставшуюся область памяти можно будет использовать в дальнейшем.
Однако очевидно, что при любой дисциплине обслуживания, по которой работает диспетчер памяти, из-за того что задачи появляются и завершаются в произвольные моменты времени и при этом имеют разные объемы, в памяти всегда будет наблюдаться сильная фрагментация. При этом возможны ситуации, когда из-за сильной фрагментации памяти диспетчер задач не сможет образовать новый раздел, хотя суммарный объем свободных областей будет больше, чем необходимо для задачи. В этой ситуации можно организовать так называемое уплотнение памяти. Для уплотнения памяти все вычисления приостанавливаются, и диспетчер памяти корректирует свои списки, перемещая разделы в начало памяти (или, наоборот, в область старших адресов). При определении физических адресов задачи будут участвовать новые значения базовых регистров, с помощью которых и осуществляется преобразование виртуальных адресов в физические. Недостатком этого решения является потеря времени на уплотнение и, что самое главное, невозможность при этом выполнять сами вычислительные процессы.
Данный способ распределения памяти, тем не менее, применялся достаточно длительное время в нескольких операционных системах, поскольку в нем для задач выделяется непрерывное адресное пространство, а это упрощает создание систем программирования и их работу. Применяется этот способ и ныне при создании систем на базе контроллеров с упрощенной (по отношению к мощным современным процессорам) архитектурой. Например, при разработке операционной системы для современных цифровых АТС, которая использует 16-разрядные микропроцессоры Intel.
2.6 Сегментная, страничная и сегментно-страничная организация памяти.
Методы распределения памяти, при которых задаче уже может не предоставляться сплошная (непрерывная) область памяти, называют разрывными. Идея выделять память задаче не одной сплошной областью, а фрагментами позволяет уменьшить фрагментацию памяти, однако этот подход требует для своей реализации больше ресурсов, он намного сложнее.
Если задать адрес начала текущего фрагмента программы и величину смещения относительно этого начального адреса, то можно указать необходимую нам переменную или команду. Таким образом, виртуальный адрес можно представить состоящим из двух полей. Первое поле будет указывать на ту часть программы, к которой обращается процессор, для определения местоположения этой части в памяти, а второе поле виртуального адреса позволит найти нужную нам ячейку относительно найденного адреса. Программист может либо самостоятельно разбивать программу на фрагменты, либо можно автоматизировать эту задачу, возложив ее на систему программирования.
3 Динамически подключаемые библиотеки.
Динамически подключаемые библиотеки (dynamic-link libraries, DLL) — краеугольный камень операционной системы Windows, начиная с самой первой ее версии. Использование динамических библиотек - это способ осуществления модульности в период выполнения программы. Динамическая библиотека (Dynamic Link Library - DLL) позволяет упростить и саму разработку программного обеспечения. Вместо того чтобы каждый раз перекомпилировать огромные ЕХЕ-программы, достаточно перекомпилировать лишь отдельный динамический модуль. Кроме того, доступ к динамической библиотеке возможен сразу из нескольких исполняемых модулей, что делает многозадачность более гибкой. В DLL содержатся все функции Windows API. Три самые важные DLL: Kernel32.dll (управление памятью, процессами и потоками), User32.dll (поддержка пользовательского интерфейса, в том числе функции, связанные с созданием окон и передачей сообщений) и GDI32.dll (графика и вывод текста).
В Windows есть и другие DLL, функции которых предназначены для более специализированных задач. Например, в AdvAPI32.dll содержатся функции для защиты объектов, работы с реестром и регистрации событий, в ComDlg32.dll ~ стандартные диалоговые окна (вроде File Open и File Save), a ComCrl32 dll поддерживает стандартные элементы управления.
Вот некоторые из причин, по которым стоит применять DLL:
• Расширение функциональности приложения. DLL можно загружать в адресное пространство процесса динамически, что позволяет приложению, определив, какие действия от него требуются, подгружать нужный код, Поэтому одна компания, создав какое-то приложение, может предусмотреть расширение его функциональности за счет DLL от других компаний.
• Возможность использования разных языков программирования. У Вас есть выбор, на каком языке писать ту или иную часть приложения. Так, пользовательский интерфейс приложения Вы скорее всего будете создавать на Microsoft Visual Basic, но прикладную логику лучше всего реализовать на С++. Программа на Visual Basic может загружать DLL, написанные на С++, Коболе, Фортране и др.
• Более простое управление проектом. Если в процессе разработки программного продукта отдельные его модули создаются разными группами, то при использовании DLL таким проектом управлять гораздо проще. Однако конечная версия приложения должна включать как можно меньше файлов.
• Экономия памяти. Если одну и ту же DLL использует несколько приложений, в оперативной памяти может храниться только один ее экземпляр, доступный этим приложениям. Пример — DLL-версия библиотеки C/C++. Ею пользуются многие приложения. Если всех их скомпоновать со статически подключаемой версией этой библиотеки, то код таких функций, как sprintf, strcpy, malloc и др., будет многократно дублироваться в памяти. Но если они компонуются с DLL-версией библиотеки C/C++, в памяти будет присутствовать лишь одна копия кода этих функций, что позволит гораздо эффективнее использовать оперативную память.
Разделение ресурсов. DLL могут содержать такие ресурсы, как шаблоны диалоговых окон, строки, значки и растровые изображения. Эти ресурсы доступны любым программам.
Упрощение локализации. DLL нередко применяются для локализации приложения. Например, приложение, содержащее только код без всяких компонентов пользовательского интерфейса, может загружать DLL с компонентами локализованного интерфейса
Решение проблем, связанных с особенностями различных платформ. В разных версиях Windows содержатся разные наборы функций. Зачастую разработчикам нужны новые функции, существующие в той версии системы, которой они пользуются. Если Ваша версия Windows не поддерживает эти функции, Вам не удастся запустить такое приложение: загрузчик попросту откажется его запускать. Но если эти функции будут находиться в отдельной DLL, Вы загрузите программу даже в более ранних версиях Windows, хотя воспользоваться ими Вы все равно не сможете.
• Реализация специфических возможностей. Определенная функциональность в Windows доступна только при использовании DLL Например, отдельные виды ловушек (устанавливаемых вызовом SetWindowsHookEx и SetWinEventHook можно задействовать при том условии, что функция уведомления ловушки размещена в DLL. Кроме того, расширение функциональности оболочки Windows возможно лишь за счет создания СОМ-объектов, существование которых допустимо только в DLL. Это же относится и к загружаемым Web-браузером ActiveX-элементам, позволяющим создавать Web-страницы с более богатой функциональностью.
Для того чтобы двигаться дальше, введу такое понятие, как связывание. Во время трансляции связываются имена, указанные в программе как внешние, (EXTERN) с соответствующими именами из библиотек, которые указываются при помощи директивы IMPORTLIB. Такое связывание называется ранним (или статическим). Напротив, в случае с динамической библиотекой связывание происходит во время выполнения модуля. Такое связывание называется поздним (или динамическим). При этом позднее связывание может происходить в автоматическом режиме в начале запуска программы и при помощи специальных API-функций, по желанию программиста. При этом говорят о явном и неявном связывании. Сказанное иллюстрирует рис. 3.1. Заметим также, что использование динамической библиотеки экономит дисковое пространство, т.к. представленная в библиотеке процедура содержится лишь один раз, в отличие от процедур, помещаемых в модули из статических библиотек.
В среде Windows практикуются два механизма связывания: по символьным именам и по порядковым номерам. В первом случае функция, определенная в динамической библиотеке, идентифицируется по ее имени, во втором - по порядковому номеру, который должен быть задан при трансляции. Связывание по порядковому номеру в основном практиковалось в старых операционных системах Windows. На наш взгляд, связывание по имени - более удобный механизм.
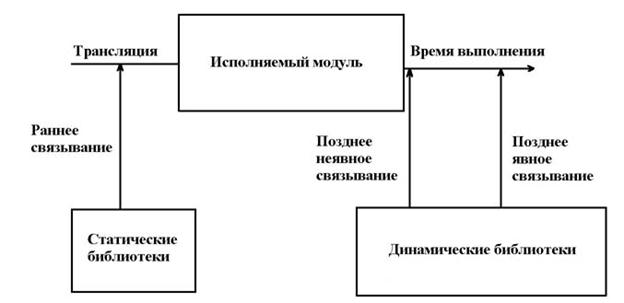
Рис. 3.1. Иллюстрация понятия связывания в ассемблере.
Динамическая библиотека может содержать также ресурсы. Так, файлы шрифтов представляют собой динамические библиотеки, единственным содержимым которых являются ресурсы. Должно сказать, что динамическая библиотека как бы становится продолжением Вашей программы, загружаясь в адресное пространство процесса. Соответственно, данные процесса доступны из динамической библиотеки, и, наоборот, данные динамической библиотеки доступны для процесса.
В любой динамической библиотеке следует определить точку входа (процедура входа). По умолчанию за точку входа принимают метку, указываемую за директивой END (например, END START). При загрузке динамической библиотеки и выгрузке динамической библиотеки автоматически вызывается процедура входа. Заметим при этом, что каким бы способом ни была загружена динамическая библиотека (явно или неявно), выгрузка динамической библиотеки из памяти будет происходить автоматически при закрытии процесса или потока. В принципе, процедура входа может быть использована для некоторой начальной инициализации переменных. Довольно часто эта процедура остается пустой. При вызове процедуры входа в нее помещаются три параметра:
· 1-й параметр. Идентификатор DLL-модуля.
· 2-й параметр. Причина вызова.
· 3-й параметр. Резерв.
Рассмотрим подробнее второй параметр процедуры входа. Вот четыре возможных значения этого параметра:
DLL_PROCESS_DETACH equ 0
DLL_PROCESS_ATTACH equ 1
DLL_THREAD_ATTACH equ 2
DLL_THREAD_DETACH equ 3
DLL_PROCESS_ATTACH - сообщает, что динамическая библиотека загружена в адресное пространство вызывающего процесса.
DLL_THREAD_ATTACH - сообщает, что текущий процесс создает новый поток. Такое сообщение посылается всем динамическим библиотекам, загруженным к этому времени процессом.
DLL_PROCESS_DETACH - сообщает, что динамическая библиотека выгружается из адресного пространства процесса.
DLL_THREAD_DETACH - сообщает, что некий поток, созданный данным процессом, в адресное пространство которого загружена данная динамическая библиотека, уничтожается.
На рис. 3.2 приводится пример простейшей динамической библиотеки. Данная динамическая библиотека, по сути, ничего не делает. Просто при загрузке библиотеки, ее выгрузки, а также вызове процедуры DLLP1 будет вызвано обычное Windows-сообщение. Обратите внимание, как определяется процесс загрузки и выгрузки библиотеки. Заметим также, что процедура входа должна возвращать ненулевое значение. Процедура DLLP1 обрабатывает также один параметр, передаваемый через стек обычным способом.
.386P; плоская модельIFDEF MASM .MODEL FLAT, stdcallELSE .MODEL FLATENDIF PUBLIC DLLP1; константы; сообщения, приходящие при открытии; динамической библиотекиDLL_PROCESS_DETACH equ 0DLL_PROCESS_ATTACH equ 1DLL_THREAD_ATTACH equ 2DLL_THREAD_DETACH equ 3 IFDEF MASM; MASM; прототипы внешних процедур EXTERN MessageBoxA@16:NEAR; директивы компоновщику для подключения библиотек includelib c:masm32libuser32.lib includelib c:masm32libkernel32.libELSE; TASM EXTERN MessageBoxA:NEAR MessageBoxA@16 = MessageBoxA includelib c:tasm32libimport32.libENDIF;--------------------------------------------------; сегмент данных_DATA SEGMENT DWORD PUBLIC USE32 'DATA' TEXT1 DB 'Вход в библиотеку',0 TEXT2 DB 'Выход из библиотеки',0 MS DB 'Сообщение из библиотеки',0 TEXT DB 'Вызов процедуры из DLL',0_DATA ENDS; сегмент кода_TEXT SEGMENT DWORD PUBLIC USE32 'CODE'; [EBP+10H] ; резервный параметр; [EBP+0CH] ; причина вызова; [EBP+8] ; идентификатор DLL-модуляDLLENTRY: MOV EAX,DWORD PTR [EBP+0CH] CMP EAX,0 JNE D1; закрытие библиотеки PUSH 0 PUSH OFFSET MS PUSH OFFSET TEXT2 PUSH 0 CALL MessageBoxA@16 JMP _EXITD1: CMP EAX,1 JNE _EXIT; открытие библиотеки PUSH 0 PUSH OFFSET MS PUSH OFFSET TEXT1 PUSH 0 CALL MessageBoxA@16_EXIT: MOV EAX,1 RET 12 ;———————————————————; [EBP+8] ; параметр процедурыDLLP1 PROC EXPORT PUSH EBP MOV EBP,ESP CMP DWORD PTR [EBP+8],1 JNE _EX PUSH 0 PUSH OFFSET MS PUSH OFFSET TEXT PUSH 0 CALL MessageBoxA@16_EX: POP EBP RET 4DLLP1 ENDP_TEXT ENDSEND DLLENTRYPuc. 3.2. Простейшая DLL-библиотека.
Программа на рис. 3.2 может быть оттранслирована как с помощью MASM32, так и TASM32. На этом стоит остановиться более подробно. Прежде всего, обратите внимание, что за процедурой, вызываемой из другого модуля, мы указали ключевое слово EXPORT. Это слово необходимо для правильной трансляции в MASM. Для TASM этого не нужно, но, к счастью, этот транслятор просто не замечает наличия какого-либо слова после PROC. Зато для TASM процедура DLLP1 должна быть определена как PUBLIC, кроме того, для трансляции в пакете TASM необходимо подготовить DEF-файл и указать его в командной строке TLINK32. Для создания динамических библиотек в строке link следует указать ключ /DLL, а в строке tlink32 -Tpd (no умолчанию работает ключ -Tpe). Ключ /ENTRY:DLLENTRY в строке link можно опустить, так как точка входа определяется из директивы END DLLENTRY.
Трансляция динамической библиотеки на Рис. 3. 2.
MASM32.
ml /c /coff /DMASM dll1.asm
link /subsystem:windows /DLL /ENTRY:DLLENTRY dll1.obj
TASM32.
tasm32 /ml dll1.asm
tlink32 -aa -Tpd dll1.obj,,,,dll1.def
Содержимое dll1.def:
EXPORTS DLLP1
На Рис. 3.3 представлена программа, которая загружает динамическую библиотеку, показанную на Рис. 3.2. Это пример позднего связывания. Библиотека должна быть вначале загружена при помощи функции LoadLibrary. Затем определяется адрес процедуры с помощью функции GetProcAddress, после чего можно осуществлять вызов. Как и следовало ожидать, MASM помещает в динамическую библиотеку вместо DLLP1 имя _DLLP1@0, тогда как TASM помещает имя без искажения. Это мы учитываем в нашей программе. Мы учитываем также возможность ошибки при вызове функций LoadLibrary и GetProcAddress. В этой связи укажем, как (в какой последовательности) ищет библиотеку функция LoadLibrary:
1. Поиск в каталоге, откуда была запущена программа.
2. Поиск в текущем каталоге.
3. В системном директории (GetSystemDirectory).
4. В директории Windows (GetWindowsDirectory).
5. В каталогах, указанных в окружении (PATH).
В конце программы мы выгружаем из памяти динамическую библиотеку, что, кстати, могли бы и не делать, т.к. по выходе из программы эта процедура выполняется автоматически.
.386P
; плоская модель
.MODEL FLAT, stdcall
; константы
; прототипы внешних процедур
IFDEF MASM
;MASM
EXTERN GetProcAddress@8:NEAR
EXTERN LoadLibraryA@4:NEAR
EXTERN FreeLibrary@4:NEAR
EXTERN ExitProcess@4:NEAR
EXTERN MessageBoxA@16:NEAR
; директивы компоновщику для подключения библиотек
includelib c:masm32libuser32.lib
includelib c:masm32libkernel32.lib
ELSE
; TASM
EXTERN GetProcAddress:NEAR
EXTERN LoadLibraryA:NEAR
EXTERN FreeLibrary:NEAR
EXTERN ExitProcess:NEAR
EXTERN MessageBoxA:NEAR
; директивы компоновщику для подключения библиотек
includelib c:tasm32libimport32.lib
GetProcAddress@8 = GetProcAddress
LoadLibraryA@4 = LoadLibraryA
FreeLibrary@4 = FreeLibrary
ExitProcess@4 = ExitProcess
MessageBoxA@16 = MessageBoxA
ENDIF
;-----------------------------------------
; сегмент данных
_DATA SEGMENT DWORD PUBLIC USE32 'DATA'
TXT DB 'Ошибка динамической библиотеки',0
MS DB 'Сообщение',0
LIBR DB 'DLL1.DLL',0
HLIB DD ?
IFDEF MASM
NAMEPROC DB '_DLLP1@0',0
ELSE
NAMEPROC DB 'DLLP1',0
ENDIF
_DATA ENDS
; сегмент кода
_TEXT SEGMENT DWORD PUBLIC USE32 'CODE'
START:
; загрузить библиотеку
PUSH OFFSET LIBR
CALL LoadLibraryA@4
CMP EAX,0
JE _ERR
MOV HLIB,EAX
; получить адрес процедуры
PUSH OFFSET NAMEPROC
PUSH HLIB
CALL GetProcAddress@8
CMP EAX,0
JNE YES_NAME
; сообщение об ошибке
_ERR:
PUSH 0
PUSH OFFSET MS
PUSH OFFSET TXT
PUSH 0
CALL MessageBoxA@16
JMP _EXIT
YES_NAME:
PUSH 1 ; параметр
CALL EAX
; закрыть библиотеку
PUSH HLIB
CALL FreeLibrary@4
; библиотека автоматически закрывается также
; при выходе из программы
; выход
_EXIT:
PUSH 0
CALL ExitProcess@4
_TEXT ENDS
END START
Рис. 3.3. Вызов динамической библиотеки. Явное связывание.
Трансляция программы на рис. 3.3 ничем не отличается от трансляции обычных программ.
MASM32.
ml /c /coff /DMASM dllex.asm
link /subsystem:windows dllex.obj
TASM32.
tasm32 /ml dllex.asm
tlink32 -aa dllex.obj
4 Обработка исключений
4.1 Обработчики завершения
Структурная обработка исключений (structured exception handling, SEH). Преимущество SEH в том, что при написании кода можно сосредоточиться на решении своей задачи. Если при выполнении программы возникнут неприятности, система сама обнаружит их и сообщит Вам.
Хотя полностью игнорировать ошибки в программе при использовании SEH нельзя, она все же позволяет отделить основную работу от рутинной обработки ошибок, к которой можно вернуться позже.
Главное, почему Microsoft ввела в Windows поддержку SEH, было ее стремление упростить разработку операционной системы и повысить ее надежность. А нам SЕН поможет сделать надежнее наши программы.
Основная нагрузка по поддержке SEH ложится на компилятор, а не на операционную систему. Он генерирует специальный код на входах и выходах блоков исключений (exception blorks), создает таблицы вспомогательных структур данных для поддержки SEH и предоставляет функции обратного вызова, к которым система могла бы обращаться для прохода по блокам исключений Компилятор отвечает и за формирование стековых фреймов (stack frames) и другой внутренней информации, используемой операционной системой. Добавить поддержку SEH в компилятор — задача не из легких, поэтому не удивляйтесь, когда увидите, что разные поставщики по-разному реализуют SEH в своих компиляторах. К счастью, на детали реализации можно не обращать внимания, а просто задействовать возможности компилятора в поддержке SEH.
Различия в реализации SEH разными компиляторами могли бы затруднить описание конкретных примеров использования SEH. Но большинство поставщиков компиляторов придерживается синтаксиса, рекомендованного Microsoft Синтаксис и ключевые слова в моих примерах могут отличаться от применяемых в других компиляторах, по основные концепции SEH везде одинаковы. В этой главе я использую синтаксис компиляюра Microsoft Visual C++.
Не путайте SEH с обработкой исключении в С++, которая представляет собой еще одну форму обработки исключений, построенную на применении ключевых слов языка С++ catch и throw При этом Microsoft Visual C++ использует преимущества поддержки SEH, уже обеспеченной компилятором и операционными системами Windows.
SEH предоставляет две основные возможности, обработку завершения (termination handling) и обработку исключений (exception handling). B этой главе мы рассмотрим обработку завершения.
Обработчик завершения гарантирует, что блок кода (собственно обработчик) будет выполнен независимо от того, как происходит выход из другого блока кода — защищенного участка программы. Синтаксис обработчика завершения при работе с компилятором Microsoft Visual C++ выглядит так:
__try
{ // защищенный блок }
_finally
{ // обработчик завершения }
Ключевые слова _try и __flnally обозначают два блока обработчика завершения, В предыдущем фрагменте кода совместные действия операционной системы и компилятора гарантируют, что код блока finаllу обработчика завершения будет выполнен независимо от того, как произойдет выход из защищенного блока. И неважно, разместите Вы в защищенном блоке операторы return, goto или даже longjump — обработчик завершения все равно будет вызван. Далее я покажу Вам несколько примеров использования обработчиков завершения.
4.2 Примеры использования обработчиков завершения
Поскольку при использовании SEH компилятор и операционная система вместе контролируют выполнение Вашего кода, то лучший, на мой взгляд, способ продемонстрировать работу SEH — изучать исходные тексты программ и рассматривать порядок выполнения операторов в каждом из примеров.
Поэтому в следующих разделах приведен ряд фрагментов исходного кода, а связанный с каждым из фрагментов текст поясняет, как компилятор и операционная система изменяют порядок выполнения кода.
– Конец работы –
Эта тема принадлежит разделу:
Изучение операционной системы Windows
Федеральное агентство по образованию... Государственное образовательное учреждение высшего профессионального... Ижевский государственный технический университет...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Потоки.
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.044 сек.
Новости и инфо для студентов