рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Компьютеры
- /
- ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМ
Реферат Курсовая Конспект
ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМ
ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМ - раздел Компьютеры, Федеральное Агентство По Образованию Сибирский Государственный Аэрок...
Федеральное агентство по образованию
Сибирский государственный аэрокосмический университет
имени академика М. Ф. Решетнева
ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМ
Учебное пособие
для студентов, обучающихся по направлению
«Информатика и вычислительная техника»
Красноярск 2009
УДК 681.3(075)
ББК 32.973.2-02я7
Организация ЭВМ и систем: учебное пособие по курсу «Организация ЭВМ и систем» для студентов спец. очной формы обучения /сост.: К. В. Богданов, В. А. Сарычев ; Сиб. гос. аэрокосмич. ун-т. — Красноярск, 2009. — 258 с.
Учебное пособие посвящено систематизированному изложению некоторых основных вопросов организации структуры и функционирования вычислительных машин и систем. Рассматриваются вопросы функционирования классических фон-неймановских машин, история развития вычислительной техники и типов архитектур, вопросы организации системы команд вычислительных машин, принципы работы и архитектура процессора, построенного по классической фон-неймановской схеме.
© Сибирский государственный аэрокосмический
университет имени академика М. Ф. Решетнева, 2009
СОДЕРЖАНИЕ
ВВЕДЕНИЕ. 7
ГЛАВА 1. Становление и эволюция цифровой вычислительной техники. 8
1.1. Определение понятия «архитектура». 9
1.2. Уровни детализации структуры вычислительной машины.. 9
1.3. Эволюция средств автоматизации вычислений. 11
1.3.1. Нулевое поколение (1492-1945) 13
1.3.2. Первое поколение(1937-1953) 17
1.3.3. Второе поколение (1954-1962) 20
1.3.4. Третье поколение (1963-1972) 21
1.3.5. Четвертое поколение (1972-1984) 23
1.3.6. Пятое поколение (1984-1990) 24
1.3.7. Шестое поколение (1990–) 25
1.4. Концепция машины с хранимой в памяти программой. 26
1.4.1. Принцип двоичного кодирования. 28
1.4.2. Принцип программного управления. 28
1.4.3. Принцип однородности памяти. 29
1.4.4. Принцип адресности. 29
1.5. Фон-неймановская архитектура. 29
1.6 Типы структур вычислительных машин и систем. 32
1.6.1. Структуры вычислительных машин. 32
1.6.2. Структуры вычислительных систем. 33
1.6.3. Перспективные направления исследований в области архитектуры.. 35
Контрольные вопросы.. 36
ГЛАВА 2. Архитектура системы команд. 37
2.1. Понятие архитектуры системы команд. 37
2.2. Классификация архитектур системы команд. 38
2.2.1. Классификация по составу и сложности команд. 39
2.2.2. Классификация по месту хранения операндов. 42
2.3. Форматы команд. 50
2.3.1. Длина команды.. 51
2.3.2. Разрядность полей команды.. 52
2.3.3. Количество адресов в команде. 53
2.4. Выбор адресности команд. 55
2.4.1. Адресность и емкость запоминающего устройства. 55
2.4.2. Адресность и время выполнения программы.. 55
2.4.3. Адресность и эффективность использования памяти. 56
2.5. Способы адресации операндов. 56
2.5.1. Непосредственная адресация. 57
2.5.2. Прямая адресация. 58
2.5.3. Косвенная адресация. 59
2.5.4. Регистровая адресация. 60
2.5.5. Косвенная регистровая адресация. 60
2.5.6. Адресация со смещением. 61
2.5.7. Относительная адресация. 62
2.5.8. Базовая регистровая адресация. 63
2.5.9. Индексная адресация. 65
2.5.10. Страничная адресация. 66
2.6. Цикл команды.. 67
2.7. Основные показатели вычислительных машин. 68
Контрольные вопросы.. 69
ГЛАВА 3. Программная модель процессора на примере Intel i8086. 71
3.1. Программная архитектура i80х86. 71
3.2. Микропроцессор i8086. 73
3.3. Доступ к ячейкам памяти. 76
3.4. Команды микропроцессора. 79
3.5. Основные группы команд и их краткая характеристика. 80
3.6. Способы адресации в архитектуре i80x86. 81
Контрольные вопросы.. 84
Лабораторная работа №1. Программная архитектура процессора i8086. 85
ГЛАВА 4. Интерфейсы и шины в вычислительной системе. 87
4.1. Структура взаимосвязей вычислительной машины.. 87
4.2. Типы шин. 90
4.2.1. Шина «процессор-память». 91
4.2.2. Шина ввода/вывода. 91
4.2.3. Системная шина. 91
4.3. Иерархия шин. 92
4.3.1. Вычислительная машина с одной шиной. 93
4.3.2. Вычислительная машина с двумя видами шин. 93
4.3.3. Вычислительная машина с тремя видами шин. 94
4.4. Физическая реализация шин. 94
4.4.1. Механические аспекты.. 94
4.4.2. Электрические аспекты.. 95
4.5. Распределение линий шины.. 99
4.6. Выделенные и мультиплексируемые линии. 102
4.7. Арбитраж шин. 103
4.7.1. Схемы приоритетов. 103
4.7.2. Схемы арбитража. 104
4.8. Основные интерфейсы современных ВМ на базе архитектуры IA-32. 105
4.8.1. Интерфейс PCI 105
4.8.2. Порт AGP. 108
4.8.3. PCI Express. 110
Лабораторная работа №2. Мультиплексоры и демультиплексоры.. 112
ГЛАВА 5. Системы ввода/вывода. Организация обмена в вычислительной системе 116
5.1. Основные функции модуля ввода-вывода. 116
5.1.1. Локализация данных. 116
5.1.2. Управление и синхронизация. 117
5.1.3. Обмен информацией. 117
5.2. Методы управления вводом/выводом. 118
5.3. Система прерываний и исключений в архитектуре IA-32. 119
5.4. Расширенный программируемый контроллер прерываний (APIC) 123
Лабораторная работа №3. Прерывания и работа с монитором. 125
ГЛАВА 6. Основные направления в архитектуре процессоров. 128
6.1. Конвейеризация вычислений. 128
6.1.1. Синхронные линейные конвейеры.. 129
6.1.2. Метрики эффективности конвейеров. 130
6.1.3. Нелинейные конвейеры.. 131
6.2. Конвейер команд. 131
6.3. Конфликты в конвейере команд. 132
6.4. Методы решения проблемы условного перехода. 136
6.5. Предсказание переходов. 139
6.5.1. Статическое предсказание переходов. 139
6.5.2. Динамическое предсказание переходов. 141
6.6. Суперконвейерные процессоры.. 142
6.7. Архитектуры с полным и сокращенным набором команд. 143
6.8. Основные черты RISC-архитектуры.. 145
6.9. Преимущества и недостатки RISC.. 146
6.10. Суперскалярные процессоры.. 147
Лабораторная работа №4. Исполнительные устройства ВМ.. 153
ГЛАВА 7. Подсистема памяти. 168
7.1. Характеристики систем памяти. 168
7.2. Иерархия запоминающих устройств. 170
7.3. Основная память. 174
7.4. Блочная организация основной памяти. 175
7.5. Организация микросхем памяти. 176
7.6. Синхронные и асинхронные запоминающие устройства. 179
7.7. Оперативные запоминающие устройства. 180
7.9. Статические оперативные запоминающие устройства. 183
7.10. Динамические оперативные запоминающие устройства. 185
Лабораторная работа №5. Расширенная работа с памятью и передача управления в программе. 193
ГЛАВА 8. Внешние накопители. 196
8.1. Магнитные диски. 196
8.1.1. Организация данных и форматирование. 196
8.1.2. Внутреннее устройство дисковых систем. 197
8.2. Массивы магнитных дисков с избыточностью.. 202
8.2.1. Концепция массива с избыточностью.. 202
8.2.2. Повышение производительности дисковой подсистемы.. 203
8.2.3. Повышение отказоустойчивости дисковой подсистемы.. 203
8.2.4. RAID уровня 0. 205
8.2.5. RAID уровня 1. 206
8.2.6. RAID уровня 2. 207
8.2.7. RAID уровня 3. 208
8.2.8. RAID уровня 4. 209
8.2.9. RAID уровня 5. 211
8.2.10. RAID уровня 6. 211
8.2.11. RAID уровня 7. 212
8.2.12. RAID уровня 10. 213
8.2.13. RAID уровня 53. 214
8.2.14. Особенности реализации RAID-систем. 214
8.3. Оптическая память. 215
Контрольные вопросы.. 218
ГЛАВА 9. Основы параллельных вычислений. 219
9.1. Уровни параллелизма. 219
9.1.1. Параллелизм уровня задания. 220
9.1.2. Параллелизм уровня программ. 222
9.1.3. Параллелизм уровня команд. 223
9.2. Метрики параллельных вычислений. 223
9.2.1. Профиль параллелизма программы.. 224
9.2.2. Ускорение, эффективность, загрузка и качество. 226
9.3. Закон Амдала. 228
9.4. Закон Густафсона. 231
9.5. Классификация параллельных вычислительных систем. Классификация Флинна 232
Контрольные вопросы.. 235
ГЛАВА 10. Архитектура многопроцессорных систем. 236
10.1. Классификация многопроцессорных систем. 236
10.2. Организация коммуникационной среды в системах с разделяемой памятью. 241
10.3. Когерентность кэш- памяти в SMP- системах. 244
10.4. Когерентность кэш- памяти в MPP-системах. 252
10.5. Организация прерываний в мультипроцессорных системах. 254
ЗАКЛЮЧЕНИЕ. 257
БИБЛИОГРАФИЧЕСКИЙ СПИСОК.. 258
ВВЕДЕНИЕ
Современные вычислительные машины (ВМ) и системы (ВС) являются одним из самых значимых достижений научной и инженерной мысли, влияние которого на прогресс во всех областях человеческой деятельности трудно переоценить. Поэтому понятно то пристальное внимание, которое уделяется изучению ВМ и ВС в направлении «Информатика и вычислительная техника» высшего профессионального образования.
Вычислительная техника прошла уже достаточно долгий исторический путь, и потому достаточно сложно понять принципы функционирования современных ВМ и ВС, не обладая багажом фундаментальных знаний. Кроме того, в последнее время наблюдается «уход» учебных пособий в частные вопросы информационных технологий. В противовес этому авторы попытались осветить в данном учебном пособии основные принципы построения и функционирования ВМ и ВС вообще, стараясь не останавливаться на какой либо конкретной архитектуре. Исключение сделано лишь для архитектуры I8086, которая в силу своей распространённости, наиболее доступна студентам для изучения и практической работы.
В государственном образовательном стандарте высшего профессионального образования содержание дисциплины «Организация ЭВМ и систем» определено следующим образом:
· основные характеристики, области применения ЭВМ различных классов;
· функциональная и структурная организация процессора;
· организация памяти ЭВМ;
· основные стадии выполнения команды;
· организация прерываний в ЭВМ;
· организация ввода-вывода;
· периферийные устройства;
· архитектурные особенности организации ЭВМ различных классов;
· параллельные системы;
· понятие о многомашинных и многопроцессорных вычислительных системах.
Все эти вопросы освещены в данном учебном пособии. Кроме того, рассмотрены не только классические основы, но и современные научные и практические достижения, характеризующие динамику развития современных аппаратных средств компьютерной техники.
Каждая глава учебного пособия раскрывает фундаментальные принципы и особенности организации какого-либо компонента ВМ или ВС. В конце каждой главы приводятся либо контрольные вопросы для закрепоения материала главы, либо задания на лабораторную работу, которая основывается на материале главы. Лабораторные работы по моделированию аппаратных средств выполняются в среде Electronics Workbench, по работе с системой команд – с помощью пакета TASM.
ГЛАВА 1. Становление и эволюция цифровой вычислительной техники
Изучение любого вопроса принято начинать с договоренностей о терминологии. В нашем случае определению подлежат понятия вычислительная машина (ВМ) и вычислительная система (ВС). Сразу же оговорим, что предметом рассмотрения будут исключительно цифровые машины и системы, то есть устройства, оперирующие дискретными величинами. В литературе можно найти множество самых различных определений терминов «вычислительная машина» и «вычислительная система». Причина такой терминологической неопределенности кроется в невозможности дать удовлетворяющее всех четкое определение, достойное роли стандарта. Любая из известных формулировок несет в себе стремление авторов отразить наиболее существенные, по их мнению, моменты, в силу чего не может быть всеобъемлющей. В подтверждение этого тезиса приведем несколько определений термина «вычислительная машина», взятых из различных литературных источников. Итак, вычислительная машина — это:
1. Устройство, которое принимает данные, обрабатывает их в соответствии с хранимой программой, генерирует результаты и обычно состоит из блоков ввода, вывода, памяти, арифметики, логики и управления.
2. Функциональный блок, способный выполнять реальные вычисления, включающие множественные арифметические и логические операции, без участия человека в процессе этих вычислений.
3. Устройство, способное:
· хранить программу или программы обработки и по меньшей мере информацию, необходимую для выполнения программы;
· быть свободно перепрограммируемым в соответствии с требованиями пользователя;
· выполнять арифметические вычисления, определяемые пользователем;
· выполнять без вмешательства человека программу обработки, требующую изменения действий путем принятия логических решений в процессе обработки.
Не отдавая предпочтения ни одной из известных формулировок терминов «вычислительная машина» и «вычислительная система», тем не менее воспользуемся наиболее общим их определением, условившись, что по мере необходимости смысловое их наполнение может уточняться.
Термином вычислительная машина будем обозначать комплекс технических и программных средств, предназначенный для автоматизации подготовки и решения задач пользователей.
В свою очередь, вычислительную систему определим как совокупность взаимосвязанных и взаимодействующих процессоров или вычислительных машин, периферийного оборудования и программного обеспечения, предназначенную для подготовки и решения задач пользователей.
1.1. Определение понятия «архитектура»
Рассмотрение принципов построения и функционирования вычислительных машин и систем предварим определением термина архитектура в том виде, как он будет далее.
Под архитектурой вычислительной машины обычно понимается логическое построение ВМ, то есть то, какой машина представляется программисту. Впервые термин «архитектура вычислительной машины» (computer architecture) был употреблен фирмой IBM при разработке машин семейства IBM 360 для описания тех средств, которыми может пользоваться программист, составляя программу на уровне машинных команд.
Подобную трактовку называют «узкой», и охватывает она перечень и формат команд, формы представления данных, механизмы ввода/вывода, способы адресации памяти и т. п. Из рассмотрения выпадают вопросы физического построения вычислительных средств: состав устройств, число регистров процессора, емкость памяти, наличие специального блока для обработки вещественных чисел, тактовая частота центрального процессора и т. д. Этот круг вопросов принято определять понятием организация или структурная организация.
Архитектура (в узком смысле) и организация — это две стороны описания ВМ и ВС. Поскольку для наших целей, помимо теоретической строгости, такое деление не дает каких-либо преимуществ, то в дальнейшем будем пользоваться термином «архитектура», правда, в «широком» его толковании, объединяющем как архитектуру в узком смысле, так и организацию ВМ. Применительно к вычислительным системам термин «архитектура» дополнительно распространяется на вопросы распределения функций между составляющими ВС и взаимодействия этих составляющих.
Уровни детализации структуры вычислительной машины
Вычислительная машина как законченный объект являет собой плод усилий специалистов в самых различных областях человеческих знаний. Каждый… Круг вопросов, рассматриваемых в данном курсе, по большей части относится к…Эволюция средств автоматизации вычислений
· самозарождение «живых» вычислительных систем из «неживых» элементов (в биологии это явление известно как абиогенез); · поступательное продвижение по древу эволюции — от протопроцессорных… · прогресс в технологии вычислительных систем как следствие полезных мутаций и вариаций;Нулевое поколение (1492-1945)
Для полноты картины упомянем два события, произошедшие до нашей эры: первые счеты — абак, изобретенные в древнем Вавилоне за 3000 лет до н. э., и… «Механическая» эра (нулевое поколение) в эволюции ВТ связана с механическими,… Хронология основных событий «механической» эры выглядит следующим образом.Первое поколение(1937-1953)
На роль первой в истории электронной вычислительной машины в разные периоды претендовало несколько разработок. Общим у них было использование схем… Первой электронной вычислительной машиной чаще всего называют… Вторым претендентом на первенство считается вычислитель Colossus, построенный в 1943 году в Англии в местечке…Второе поколение (1954-1962)
Второе поколение характеризуется рядом достижений в элементной базе, структуре и программном обеспечении. Принято считать, что поводом для… Первой ВМ, выполненной полностью на полупроводниковых диодах и транзисторах,… Со вторым поколением ВМ ассоциируют еще одно принципиальное технологическое усовершенствование – переход от устройств…Третье поколение (1963-1972)
Третье поколение ознаменовалось резким увеличением вычислительной мощности ВМ, ставшим следствием больших успехов в области архитектуры, технологии… В первых ВМ третьего поколения использовались интегральные схемы с малой… В 1964 году Сеймур Крей (Seymour Cray, 1925-1996) построил вычислительную систему CDC 6600, в архитектуру которой…Четвертое поколение (1972-1984)
Отсчет четвертого поколения обычно ведут с перехода на интегральные микросхемы большой (large-scale integration, LSI) и сверхбольшой (very… Конец 70-х и начало 80-х годов — это время становления и последующего… Одним из наиболее значимых событий в области архитектуры ВМ стала идея вычислительной машины с сокращенным набором…Пятое поколение (1984-1990)
Главным поводом для выделения вычислительных систем второй половины 80-х годов в самостоятельное поколение стало стремительное развитие ВС с… В рамках пятого поколения в архитектуре вычислительных систем сформировались… Характерным примером первого подхода может служить система Sequent Balance 8000, в которой имеется большая основная…Концепция машины с хранимой в памяти программой
Исходя из целей данного раздела, введем новое определение термина «вычислительная машина» как совокупности технических средств, служащих для… Алгоритм – одно из фундаментальных понятий математики и вычислительной… Помимо этой стандартизированной формулировки существуют и другие определения. Приведем более распространенные из них.…Принцип двоичного кодирования
Согласно этому принципу, вся информация, как данные, так и команды, кодируются двоичными цифрами 0 и 1. Каждый тип информации представляется…Принцип программного управления
Все вычисления, предусмотренные алгоритмом решения задачи, должны быть представлены в виде программы, состоящей из последовательности управляющих…Принцип однородности памяти
Команды и данные хранятся в одной и той же памяти и внешне в памяти неразличимы. Распознать их можно только по способу использования. Это позволяет… Концепция вычислительной машины, изложенная в статье фон Неймана,…Принцип адресности
Структурно основная память состоит из пронумерованных ячеек, причем процессору в произвольный момент доступна любая ячейка. Двоичные коды команд и данных разделяются на единицы информации, называемые словами, и хранятся в ячейках памяти, а для доступа к ним используются номера соответствующих ячеек — адреса.
Фон-неймановская архитектура
В любой ВМ имеются средства для ввода программ и данных к ним. Информация поступает из подсоединенных к ЭВМ периферийных устройств (ПУ) ввода.…Типы структур вычислительных машин и систем
Достоинства и недостатки архитектуры вычислительных машин и систем изначально зависят от способа соединения компонентов. При самом общем подходе можно говорить о двух основных типах структур вычислительных машин и двух типах структур вычислительных систем.
Структуры вычислительных машин
В настоящее время примерно одинаковое распространение получили два способа построения вычислительных машин: с непосредственными связями и на основе… Типичным представителем первого способа может служить классическая… В варианте с общей шиной все устройства вычислительной машины подключены к магистральной шине, служащей единственным…Структуры вычислительных систем
Понятие «вычислительная система» предполагает наличие множества процессоров или законченных вычислительных машин, при объединении которых… В вычислительных системах с общей памятью (рис. 5) имеется общая основная…Перспективные направления исследований в области архитектуры
Основные направления исследований в области архитектуры ВМ и ВС можно условно разделить на две группы: эволюционные и революционные. К первой… Большинство из исследований, относимых к эволюционным, связано с… Наблюдаемые нами достижения в области вычислительных средств широкого применения пока обусловлены именно…Контрольные вопросы
1. По каким признакам можно разграничить понятия «вычислительная система» и «вычислительная машина»?
2. Какой уровень детализации вычислительной машины позволяет определить, можно ли данную ВМ причислить к фон-неймановским?
3. По каким признакам выделяют поколения вычислительных машин?
4. Какой из принципов фон-неймановской концепции вычислительно машины можно рассматривать в качестве наиболее существенного?
5. Оцените достоинства и недостатки архитектур вычислительных машин с непосредственными связями и общей шиной.
ГЛАВА 2. Архитектура системы команд
Понятие архитектуры системы команд
Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять данная ВМ. В свою очередь, под архитектурой…Классификация архитектур системы команд
В истории развития вычислительной техники как в зеркале отражаются изменения, происходившие во взглядах разработчиков на перспективность той или иной архитектуры системы команд. Сложившуюся на настоящий момент ситуацию в области АСК иллюстрирует рис. 9.

Рис. 9. Хронология развития архитектур системы команд.
Среди мотивов, чаще всего предопределяющих переход к новому типу АСК, остановимся на двух наиболее существенных. Первый — это состав операций, выполняемых вычислительной машиной, и их сложность. Второй — место хранения операндов, что влияет на количество и длину адресов, указываемых в адресной части команд обработки данных. Именно они взяты в качестве критериев излагаемых ниже вариантов классификации архитектур системы команд.
Классификация по составу и сложности команд
Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная цель которых — облегчить процесс программирования. Переход к ЯВУ, однако, породил серьезную проблему: сложные операторы, характерные для ЯВУ, существенно отличаются от простых машинных операций, реализуемых в большинстве вычислительных машин. Проблема получила название семантического разрыва между ЯВУ и системой команд ЭВМ, а ее следствием становится недостаточно эффективное выполнение программ на ВМ. Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин в настоящее время выбирают один из трех подходов и, соответственно, один из трех типов АСК:
· архитектуру с полным набором команд: CISC (Complex Instruction Set Computer);
· архитектуру с сокращенным набором команд: RISC (Reduced Instruction Set Computer);
· архитектуру с командными словами сверхбольшой длины: VLIW (Very Long Instruction Word).
В вычислительных машинах типа CISC проблема семантического разрыва решается за счет расширения системы команд, дополнения ее сложными командами, семантически аналогичными операторам ЯВУ. Основоположником CISC-архитектуры считается компания IBM, которая начала применять данный подход с семейства машин IBM 360 и продолжает его в своих мощных современных универсальных ВМ, таких как IBM ES/9000. Аналогичный подход характерен и для компании Intel в ее микропроцессорах серии 8086 и Pentium. Для CISC-архитектуры типичны:
· наличие в процессоре сравнительно небольшого числа регистров общего назначения;
· большое количество машинных команд, некоторые из них аппаратно реализуют сложные операторы ЯВУ;
· разнообразие способов адресации операндов; множество форматов команд различной разрядности;
· наличие команд, где обработка совмещается с обращением к памяти.
К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины 1980-х годов, и значительную часть производящихся в настоящее время.
Рассмотренный способ решения проблемы семантического разрыва вместе с тем ведет к усложнению аппаратуры ВМ, главным образом устройства управления, что, в свою очередь, негативно сказывается на производительности ВМ в целом. Это заставило более внимательно проанализировать программы, получаемые после компиляции с ЯВУ. Был предпринят комплекс исследований, в результате которых обнаружилось, что доля дополнительных команд, эквивалентных операторам ЯВУ, в общем объеме программ не превышает 10-20%, а для некоторых наиболее сложных команд даже 0,2%. В то же время объем аппаратных средств, требуемых для реализации дополнительных команд, возрастает весьма существенно. Так, емкость микропрограммной памяти при поддержании сложных команд может увеличиваться на 60%.
Детальный анализ результатов упомянутых исследований привел к серьезному пересмотру традиционных решений, следствием чего стало появление RISC-архитектуры. Термин RISC впервые был использован Д. Паттерсоном и Д. Дитцелем в 1980 году. Идея заключается в ограничении списка команд ВМ наиболее часто используемыми простейшими командами, оперирующими данными, размещенными только в регистрах процессора. Обращение к памяти допускается лишь с помощью специальных команд чтения и записи. Резко уменьшено количество форматов команд и способов указания адресов операндов. Сокращение числа форматов команд и их простота, использование относительно небольшого количества способов адресации, отделение операций обработки данных от операций обращения к памяти позволяет существенно упростить аппаратные средства ВМ и повысить их быстродействие. RISC-архитектура разрабатывалась таким образом, чтобы уменьшить Твыч за счет сокращения CPI и τпр. Как следствие, реализация сложных команд за счет последовательности из простых, но быстрых RISC-команд оказывается не менее эффективной, чем аппаратный вариант сложных команд в CISC-архитектуре.
Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ компании Cray Research. Достаточно успешно реализуется RISC-архитектура и в современных ВМ, например в процессорах Alpha фирмы DEC, серии РА фирмы Hewlett-Packard, семействе PowerPC и т. п.
Отметим, что в последних микропроцессорах фирмы Intel и AMD широко используются идеи, свойственные RISC-архитектуре, так что многие различия между CISC и RISC постепенно стираются.
Помимо CISC- и RISC-архитектур в общей классификации был упомянут еще один тип АСК — архитектура с командными словами сверхбольшой длины (VLIW). Концепция VLIW базируется на RISC-архитектуре, где несколько простых RISC-команд объединяются в одну сверхдлинную команду и выполняются параллельно. В плане АСК архитектура VLIW сравнительно мало отличается от RISC. Появился лишь дополнительный уровень параллелизма вычислений, в силу чего архитектуру VLIW логичнее адресовать не к вычислительным машинам, а к вычислительным системам.
| Таблица 2 | |||
| Характеристика | CISC | RISC | VLIW |
| Длина команды | Варьируется | Единая | Единая |
| Расположение полей в команде | Варьируется | Неизменное | Неизменное |
| Количество регистров | Несколько (часто специализированных) | Много регистров общего назначения | Много регистров общего назначения |
| Доступ к памяти | Может выполняться как часть команд различных типов | Выполняется только специальными командами | Выполняется только специальными командами |
Классификация по месту хранения операндов
Количество команд и их сложность, безусловно, являются важнейшими факторами, однако не меньшую роль при выборе АСК играет ответ на вопрос о том, где могут храниться операнды и каким образом к ним осуществляется доступ. С этих позиций различают следующие виды архитектур системы команд:
· стековую;
· аккумуляторную;
· регистровую;
· с выделенным доступом к памяти.
Выбор той или иной архитектуры влияет на принципиальные моменты: сколько адресов будет содержать адресная часть команд, какова будет длина этих адресов, насколько просто будет происходить доступ к операндам и какой, в конечном итоге, будет общая длина команд.
Стековая архитектура
Стек образует множество логически взаимосвязанных ячеек (рис. 10), взаимодействующих по принципу «последним вошел, первым вышел» (LIFO, Last In…Аккумуляторная архитектура
Типичная архитектура ВМ на базе аккумулятора показана на рис. 12. Для загрузки в аккумулятор содержимого ячейки х предусмотрена команда загрузки… Запись содержимого аккумулятора в ячейку х осуществляется командой сохранения store х, при выполнении которой выходы…Регистровая архитектура
В машинах данного типа процессор включает в себя массив регистров (регистровый файл), известных как регистры общего назначения (РОН). Эти регистры,… Размер регистров обычно фиксирован и совпадает с размером машинного слова. К… Регистровая архитектура допускает расположение операндов в одной из двух запоминающих сред: основной памяти или…Архитектура с выделенным доступом к памяти
Состав и информационные тракты ВМ с выделенным доступом к памяти показаны на рис. 14. Две из трех шин, расположенных между массивом РОН и АЛУ,…Форматы команд
· подлежащую выполнению операцию; · адреса исходных данных (операндов), над которыми выполняется операция; · адрес, по которому должен быть помещен результат операции.Длина команды
Рис. 15. Непосредственная адресация. КОп – поле кода операции, СА – поле сопособа адресации.Разрядность полей команды
Как уже говорилось, в любой команде можно выделить операционную и адресную части. Длины соответствующих полей определяются различными факторами, которые целесообразно рассмотреть по отдельности.
Разрядность поля кода операции
|
 RКОп = int( log2 NKOп),
RКОп = int( log2 NKOп),
где int означает округление в большую сторону до целого числа.
При заданной длине кода команды приходится искать компромисс между разрядностью поля кода операции и адресного поля. Большее количество возможных операций предполагает длинное поле кода операции, что ведет к сокращению адресного поля, то есть к сужению адресного пространства. Для устранения этого противоречия длину поля кода операции иногда варьируют. Изначально под код операции отводится некое фиксированное число разрядов, однако для отдельных команд это поле расширяется за счет нескольких битов, отнимаемых у адресного поля. Так, например, может быть увеличено число различных команд пересылки данных. Необходимо отметить, что «урезание» части адресного поля ведет к сокращению возможностей адресации, и подобный прием рекомендуется только в тех командах, где подобное сокращение может быть оправданным.
Разрядность адресной части
Разрядности полей RAi и RСА рассчитываются по формулам: RAi = int( log2 Ni ) RСА = int( log2 NCA )Количество адресов в команде
Для определения количества адресов, включаемых в адресную часть, будем использовать термин адресность. В «максимальном» варианте необходимо указать…Выбор адресности команд
При выборе количества адресов в адресной части команды обычно руководствуются следующими критериями:
· емкостью запоминающего устройства, требуемой для хранения программы;
· временем выполнения программы;
· эффективностью использования ячеек памяти при хранении программы.
Адресность и емкость запоминающего устройства
Емкость запоминающего устройства для хранения программы ЕА можно оценить из соотношения
ЕА=NA * RKA
где NA — количество программ в программе; RK — разрядность команды, определяемая в соответствии с формулой (3); А — индекс, указывающий адресность команд программы. При выборе количества адресов по критерию «емкость ЗУ» предпочтение следует отдавать одноадресным командам.
Адресность и время выполнения программы
Время выполнения одной команды складывается из времени выполнения операции и времени обращения к памяти. Для трехадресной команды последнее суммируется из четырех составляющих… · выборки команды;Адресность и эффективность использования памяти
С данных позиций можно отдать предпочтение одноадресным командам, для которых характерна максимальная эффективность использования адресов, так как, например, в командах передачи управления нужен только один адрес.
Способы адресации операндов
Вопрос о том, каким образом в адресном поле команды может быть указано местоположение операндов, считается одним из центральных при разработке… Приступая к рассмотрению способов адресации, вначале определим понятия… Исполнительным адресом операнда (Лисп) называется двоичный код номера ячейки памяти, служащей источником или…Непосредственная адресация
При непосредственной адресации (НА) в адресном поле команды вместо адреса содержится непосредственно сам операнд (рис. 15). Этот способ может… Когда операндом является число, оно обычно представляется в дополнительном… Помимо того, что в адресном поле могут быть указаны только константы, еще одним недостатком данного способа адресации…Прямая адресация
При прямой или абсолютной адресации (ПА) адресный код прямо указывает номер ячейки памяти, к которой производится обращение (рис. 22), то есть…Косвенная адресация
Одним из путей преодоления проблем, свойственных прямой адресации, может служить прием, когда с помощью ограниченного адресного поля команды… При косвенной адресации содержимое адресного поля команды остается…Регистровая адресация
Регистровая адресация (РА) напоминает прямую адресацию. Различие состоит в том, что адресное поле инструкции указывает не на ячейку памяти, а на… Двумя основными преимуществами регистровой адресации являются: короткое…Косвенная регистровая адресация
Косвенная регистровая адресация (КРА) представляет собой косвенную адресацию, где исполнительный адрес операнда хранится не в ячейке основной…Адресация со смещением
При адресации со смещением исполнительный адрес формируется в результате суммирования содержимого адресного поля команды с содержимым одного или… Адресация со смещением предполагает, что адресная часть команды включает в… Если же составляющая адреса может располагаться в произвольном регистре общего назначения, то для указания…Относительная адресация
При относительной адресации (ОА) для получения исполнительного адреса операнда содержимое подполя Aк команды складывается с содержимым счетчика…Базовая регистровая адресация
В случае базовой регистровой адресации (БРА) регистр, называемый базовым, содержит полноразрядный адрес, а подполе Ас — смещение относительно этого…Индексная адресация
При индексной адресации (ИА) подполе Ас содержит адрес ячейки памяти, а регистр (указанный явно или неявно) — смещение относительно этого адреса.…Страничная адресация
Страничная адресация (СТА) предполагает разбиение адресного пространства на страницы. Страница определяется своим начальным адресом, выступающим в…Цикл команды
Программа в фон-неймановской ЭВМ реализуется центральным процессором (ЦП) посредством последовательного исполнения образующих эту программу команд.… · выборку команды; · формирование адреса следующей команды;Основные показатели вычислительных машин
Использование конкретной вычислительной машины имеет смысл, если ее показатели соответствуют показателям, определяемым требованиями к реализации… Целесообразно рассматривать два вида быстродействия: номинальное и среднее.… оп/с.Контрольные вопросы
1. Какие характеристики вычислительной машины охватывает понятие «архитектура системы команд»?
2. Какие особенности аккумуляторной архитектуры можно считать ее достоинствами и недостатками?
3. Какие доводы можно привести за и против увеличения числа регистров общего назначения в ВМ с регистровой архитектурой системы команд?
4. Какие факторы определяют выбор формата команд?
5. Какая особенность фон-неймановской архитектуры позволяет отказаться от указания в команде адреса очередной команды?
6. С какими ограничениями связано использование непосредственной адресации?
7. В каких случаях может быть удобна многоуровневая косвенная адресация?
8. В чем проявляются сходства и различия между базовой и индексной адресацией?
9. Каким образом можно охарактеризовать производительность вычислительной машины?
10. Что понимается под номинальным и средним быстродействием ВМ?
ГЛАВА 3. Программная модель процессора на примере Intel i8086
Программная архитектура i80х86
Совокупность архитектурных решений, архитектуру команд и правила написания программ на низкоуровневом языке принято называть программной моделью… При выполнении любой программы в любой момент времени можно выделить несколько… 1. Сегмент кода.Сегмент кода.
В сегменте кода обычно записываются команды микропроцессора, которые выполняются последовательно друг за другом. Для определения адреса следующей… В сегменте кода можно также описывать данные, однако это целесообразно делать…Переменные в программе.
Во всех остальных сегментах выделяется место для переменных, используемых в программе. Разделение на сегменты данных, сегмент стека и сегмент… Переменные в программе можно разбить на две большие группы. Во-первых,…Сегмент данных.
Сегмент данных предназначен для хранения переменных, определяемых программистом. Для определения адреса начала сегмента данных используется сегментный регистр DS. Для определения другой компоненты адреса (относительного смещения в данном сегменте) в языке ассемблера предполагается несколько способов, количество которых больше, чем количество способов для определения адреса команды, что обеспечивает большую гибкость при написании программ.
Сегмент стека.
Для хранения временных значений, для которых нецелесообразно выделять переменные, предназначена специальная область памяти, называемая стеком. Для… В отличие от сегмента данных и кода, в которых можно явно адресовать любую…Микропроцессор i8086
С точки зрения программиста микропроцессор представляется в виде набора регистров. Регистры предназначены для хранения некоторых данных и поэтому, в… Все внутренние регистры микропроцессоров являются шестнадцатиразрядными и… 1. Регистры данных.Доступ к ячейкам памяти
Как уже отмечалось, в состав любой микропроцессорной системы обязательно должна входить память, в которой располагаются программы и необходимые для… В отличии от регистров микропроцессора доступ к ячейкам памяти осуществляется… В микропроцессоре i8086 шина адреса состоит из 20 линий, следовательно этот микропроцессор может адресовать 220 байт.…Команды микропроцессора
Программа, работающая в микропроцессорной системе, в конечном виде представляет собой набор байтов, воспринимаемый микропроцессором как код той или… Инструкция микропроцессора может содержать следующие поля (рис. 34):Основные группы команд и их краткая характеристика
Для упрощения процесса программирования на языке ассемблера используется мнемоническая запись команд микропроцессора (обычно в виде сокращений… Все команды микропроцессоров семейства i80х86 можно разбить на следующие… 1. Команды пересылки данных.Способы адресации в архитектуре i80x86
Рассмотренные выше способы адресации могут быть в полной мере применены при написании программы на языке ассемблера. Рассмотрим методы реализации… При вычислении адреса, используются две составляющие адреса сегмент и… При необходимости вычисления адреса в команде можно переопределить соответствующий сегмент двумя способами. Во-первых,…Регистровая адресация
В качестве операндов (как приемников, так и источников) можно использовать внутренние регистры микропроцессора, как 8ми разрядные (АН, AL, ВН, BL, СН, CL, DH, DL), так и 16ти разрядные (АХ, ВХ, СХ, DX, SP, ВР, SI, DI). Кроме них в операциях пересылки можно использовать и сегментные регистры CS, SS, DS, ES.
Непосредственная адресация
В качестве операнда – источника данных можно использовать константу, непосредственно записываемую в команде микропроцессора. Данные могут быть байтами и словами, причем считается, что значения этих переменных могут быть положительными или отрицательными. Если при записи команды используется константа меньшей размерности, чем приемник, то эта константа будет автоматически увеличена (с учетом знака) до нужной величины.
Адресация ячеек памяти
Более точно, в командах используется исполнительный адрес, который определяет адрес начала области памяти. Длина (размерность) этой области…Прямая адресация
Прямая адресация используется в тех случаях, когда явно известен адрес операнда. При выделении памяти с помощью стандартных директив, в качестве… При прямой адресации можно использовать выражение, состоящее из некоторой…Косвенная адресация
Косвенная адресация (и ее разновидности) позволяет легко организовывать доступ к сложным элементам данных, используемых в языках программирования… Для того, чтобы отличить косвенную адресацию от регистровой мнемоническое… При косвенной адресации использование того или иного регистра данных или индексного регистра неявно определяет…Косвенная адресация по базе
Такая адресация характерна для доступа к полям структуры, начальный адрес которой находится в регистре, а смещение соответствующего поля задается… В микропроцессорах i8086 в качестве базовых регистров используются только [ВХ]…Косвенно индексная адресация
По сути, косвенно индексная адресация эквивалентна косвенной адресации по базе, т.к. правила получения исполнительного адреса такие же – к содержимому регистра также добавляется некоторая константа записываемая непосредственно в команде, и полученная сумма определяет смещение операнда в памяти.
В микропроцессорах i8086 в качестве индексных регистров используются только два, регистра – [SI] и [DI].
Адресация по базе с индексированием
Такой способ адресации подходит при обеспечении доступа к полю структуры в случае, если из таких структур организован массив – константа заедает… В стандартной адресации по базе с индексированием в качестве регистров базы…Контрольные вопросы
1. На какие группы разделены регистры микропроцессора i8086?
2. Какие способы адресации применяются в данном микропроцессоре?
3. Зачем нужны индексные регистры?
4. Какова максимальная и минимальная длина команды в архитектуре i80x86?
5. Каков максимальный объём доступной оперативной памяти в реальном режиме i80x86?
6. Какие группы регистров позволяют адресовать отдельно старшую младшую части?
7. Для чего нужен сегмент стека? Каким образом производится доступ к информации, хранящейся в нём?
Лабораторная работа №1. Программная архитектура процессора i8086
На языке ассемблера процессора i8086 с использованием любого удобного пакета (рекомендуется TASM) реализуйте следующие задачи: 1. Протабулировать функцию у = а(х+b) а=3; b=1; 1 < x < 10; Шаг изменения x=1ГЛАВА 4. Интерфейсы и шины в вычислительной системе
Структура взаимосвязей вычислительной машины
Совокупность трактов, объединяющих между собой основные устройства ВМ (центральный процессор, память и модули ввода/вывода), образует структуру… · центральным процессором и памятью; · центральным процессором и модулями ввода/вывода;Типы шин
Важным критерием, определяющим характеристики шины, может служить ее целевое назначение. По этому критерию можно выделить: · шины «процессор-память»; · шины ввода/вывода;Системная шина
С целью снижения стоимости некоторые ВМ имеют общую шину для памяти и устройств ввода/вывода. Такая шина часто называется системной. Системная шина… Системная шина в состоянии содержать несколько сотен линий. Совокупность линий…Иерархия шин
Если к шине подключено большое число устройств, ее пропускная способность падает, поскольку слишком частая передача прав управления шиной от одного устройства к другому приводит к ощутимым задержкам. По этой причине во многий ВМ предпочтение отдается использованию нескольких шин, образующих определенную иерархию.
Вычислительная машина с одной шиной
В структурах взаимосвязей с одной шиной имеется одна системная шина, обеспечивающая обмен информацией между процессором и памятью, а также между УВВ…Вычислительная машина с двумя видами шин
Хотя контроллеры устройств ввода/вывода (УВВ) могут быть подсоединены непосредственно к системной шине, больший эффект достигается применением…Вычислительная машина с тремя видами шин
Для подключения быстродействующих периферийных устройств в систему шин может быть добавлена высокоскоростная шина расширения.Физическая реализация шин
Кратко остановимся на различных аспектах физической реализации шин в вычислительных машинах и системах.
Механические аспекты
Основная шина, объединяющая устройства вычислительной машины, обычно размещается на так называемой объединительной или материнской плате. Шину… Дочерние платы вставляются в разъемы на материнской плате. В дополнение к… Контактные пружины в разъемах обеспечивают независимое подключение сигнальных линий, расположенных по обеим сторонам…Электрические аспекты
Все устройства, использующие шину, электрически подсоединены к ее сигнальным линиям, представляющим собой электрические проводники. Меняя уровни… Схему, меняющую напряжение на сигнальной шине, обычно называют драйвером или… При реализации шины необходимо предусмотреть возможность отключения драйвера от сигнальной линии на период, когда он…Распределение линий шины
Любая транзакция на шине начинается с выставления ведущим устройством адресной информации. Адрес позволяет выбрать ведомое устройство и установить… На ША могут выдаваться адреса ячеек памяти, номера регистров ЦП, адреса портов… Разнообразной может быть и структура адреса. Так, в адресе может конкретизироваться лишь определенная часть ведомого,…Выделенные и мультиплексируемые линии
В некоторых ВМ линии адреса и данных объединены в единую мультиплексируемую шину адреса/данных. Такая шина функционирует в режиме разделения… Мультиплексирование адресов и данных предполагает наличие мультиплексора на… Мультиплексирование позволяет сократить общее число линий, но требует усложнения логики связи с шиной. Кроме того,…Арбитраж шин
В реальных системах на роль ведущего вправе одновременно претендовать сразу несколько из подключенных к шине устройств, однако управлять шиной в каждый момент времени может только одно из них. Чтобы исключить конфликты, шина должна предусматривать определенные механизмы арбитража запросов и правила предоставления шины одному из запросивших устройств. Решение обычно принимается на основе приоритетов претендентов.
Схемы приоритетов
Каждому потенциальному ведущему присваивается определенный уровень приоритета, который может оставаться неизменным (статический или фиксированный… Наибольшее распространение получили следующие алгоритмы динамического… · простая циклическая смена приоритетов;Схемы арбитража
Арбитраж запросов на управление шиной может быть организован по централизованной или децентрализованной схеме. Выбор конкретной схемы зависит от… При централизованном арбитраже в системе имеется специальное устройство –… В параллельном варианте центральный арбитр связан с каждым потенциальным ведущим индивидуальными двухпроводными…Основные интерфейсы современных ВМ на базе архитектуры IA-32
Интерфейс PCI
Доминирующее положение на рынке ПК достаточное длительное время занимали системы на основе шины PCI (Peripheral Component Interconnect –… Шины ISA, EISA или MCA могут управляться шиной PCI с помощью моста сопряжения… Рис. 41. Система на основе PCI.Порт AGP
С повсеместным внедрением технологий мультимедиа пропускной способности шины PCI стало не хватать для производительной работы видеокарты. Чтобы не… Одной из целей разработчиков AGP было уменьшение стоимости видеокарты, за счет… Интерфейс AGP по топологии не является шиной, т.к. обеспечивает только двухточечное соединение, т.е. один порт AGP…PCI Express
Интерфейс PCI Express (первоначальное название - 3GIO) использует концепцию PCI, однако физическая их реализация кардинально отличается. На… Одна из концептуальных особенностей интерфейса PCI Express, позволяющая…Основные функции модуля ввода-вывода
Модуль ввода/вывода в составе вычислительной машины отвечает за управление одним или несколькими ВУ и за обмен данными между этими устройствами с одной стороны, и основной памятью или регистрами ЦП – с другой. Основные функции МВВ можно сформулировать следующим образом:
· локализация данных;
· управление и синхронизация;
· обмен информацией;
· буферизация данных;
· обнаружение ошибок.
Локализация данных
Под локализацией данных будем понимать возможность обращения к одному из ВУ, а также адресации данных на нем. Адрес ВУ обычно содержится в адресной части команд ввода/вывода. Как уже… Одной из функций МВВ является проверка вхождения поступившего по шине адреса в выделенный данному модулю диапазон…Управление и синхронизация
Функция управления и синхронизации заключается в том, что МВВ должен координировать перемещение данных между внутренними ресурсами ВМ и внешними… Прежде всего, нужно принимать во внимание, что ЦП может взаимодействовать… В отличие от обмена с памятью процессы ввода/вывода и работа ЦП протекают не синхронно. Очередная порция информация…Обмен информацией
Основной функцией МВВ является обеспечение обмена информацией. Со стороны «большого» интерфейса — это обмен с ЦП, а со стороны «малого» интерфейса… 1. Выбор требуемого внешнего устройства. 2. Определение состояния МВВ и ВУ.Система прерываний и исключений в архитектуре IA-32
Прерывания и исключения - это события, которые указывают на возникновение в системе или в выполняемой в данный момент задаче определенных условий,…Расширенный программируемый контроллер прерываний (APIC)
Микропроцессоры IA-32, начиная с модели Pentium, содержат встроенный расширенный программируемый контроллер прерываний (APIC). Встроенный APIC… Встроенный APIC различает следующие источники прерываний. 1. От локальных устройств. Прерывания, генерируемые по фронту или уровню сигнала, который поступает от устройства,…ГЛАВА 6. Основные направления в архитектуре процессоров
Ранее уже были рассмотрены основные составляющие центрального процессора. В данной главе основное внимание уделено вопросам общей архитектуры процессоров как единого устройства и способам повышения их производительности.
Конвейеризация вычислений
Совершенствование элементной базы уже не приводит к кардинальному росту производительности ВМ. Более перспективными в этом плане представляются… Для пояснения идеи конвейера сначала обратимся к рис. 48, а, где показан…Синхронные линейные конвейеры
Эффективность синхронного конвейера во многом зависит от правильного выбора длительности тактового периода Тк. Минимально допустимую Тк можно… . Из-за вероятного «перекоса» в поступлении тактирующего сигнала в разные ступени конвейера предыдущую формулу следует…Метрики эффективности конвейеров
Чтобы охарактеризовать эффект, достигаемый за счет конвейеризации вычислений, обычно используют три метрики: ускорение, эффективность и… Под ускорением понимается отношение времени обработки без конвейера и при его… .Нелинейные конвейеры
Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между…Конвейер команд
Идея конвейера команд была предложена в 1956 году академиком С. А. Лебедевым. Как известно, цикл команды представляет собой последовательность… 1. Выборка команды (ВК). Чтение очередной команды из памяти и занесение ее в… 2. Декодирование команды (ДК). Определение кода операции и способов адресации операндов.Конфликты в конвейере команд
Полученное в примере число 14 характеризует лишь потенциальную производительность конвейера команд, На практике в силу возникающих в конвейере… · попыткой нескольких команд одновременно обратиться к одному и тому же… · взаимосвязью команд по данным (риск по данным);Методы решения проблемы условного перехода
Несмотря на важность аспекта вычисления исполнительного адреса точки перехода, основные усилия проектировщиков ВМ направлены на решение проблемы… · буферы предвыборки; · множественные потоки;Предсказание переходов
Предсказание переходов на сегодняшний день рассматривается как один из наиболее эффективных способов борьбы с конфликтами по управлению. Идея… К настоящему моменту известно более двух десятков различных способов…Статическое предсказание переходов
Статическое предсказание переходов осуществляется на основе некоторой априорной информации о подлежащей выполнению программе. Предсказание… Известные стратегии статического предсказания для команд УП можно… · переход происходит всегда (ПВ);Динамическое предсказание переходов
В динамических стратегиях решение о наиболее вероятном исходе команды УП принимается в ходе вычислений, исходя из информации о предшествующих… Идея динамического предсказания переходов предполагает накопление информации… При описании динамических схем предсказания переходов их часто расценивают как один из видов автоматов Мура, при этом…Суперконвейерные процессоры
Эффективность конвейера находится в прямой зависимости от того, с какой частотой на его вход подаются объекты обработки. Добиться n-кратного… · разбиением каждой ступени конвейера на п «подступеней» при одновременном… · включением в состав процессора п конвейеров, работающих с перекрытием.Архитектуры с полным и сокращенным набором команд
Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная задача которых — облегчить процесс написания программ.… Характерные для CISC способы решения проблемы семантического разрыва, вместе с… · Реализация сложных команд, эквивалентных операторам ЯВУ, требует увеличения емкости управляющей памяти в…Основные черты RISC-архитектуры
Главные усилия в архитектуре RISC направлены на построение максимально эффективного конвейера команд, то есть такого, где все команды извлекаются… Последнее условие относительно просто можно реализовать для этапа выборки.… Помимо одинаковой длины команд, важно иметь относительно простую подсистему декодирования и управления: сложное…Преимущества и недостатки RISC
Сравнивая достоинства и недостатки CISC и RISC, невозможно сделать однозначный вывод о неоспоримом преимуществе одной архитектуры над другой. Для… Для технологии RISC характерна сравнительно простая структура устройства… Унификация набора команд, ориентация на потоковую конвейерную обработку, унификация размера команд и длительности их…Суперскалярные процессоры
Поскольку возможности по совершенствованию элементной базы уже практически исчерпаны, дальнейшее повышение производительности ВМ лежит в плоскости… Суперскалярным (этот термин впервые был использован в 1987 году) называется…Лабораторная работа №4. Исполнительные устройства ВМ
Счетчики.Счетчиком называют устройство, сигналы на выходе которого отображают число импульсов, поступивших на счетный вход. JK-триггер может служить… Информация снимается с прямых и (или) инверсных выходов всех триггеров. В… Нулевое состояние всех триггеров принимается за нулевое состояние счетчика в целом. Остальные состояния нумеруются по…ГЛАВА 7. Подсистема памяти
В любой ВМ, вне зависимости от ее архитектуры, программы и данные хранятся в памяти. Функции памяти обеспечиваются запоминающими устройствами (ЗУ), предназначенными для фиксации, хранения и выдачи информации в процессе работы ВМ. Процесс фиксации информации в ЗУ называется записью, процесс выдачи информации — чтением или считыванием, а совместно их определяют как процессы обращения к ЗУ.
Характеристики систем памяти
Перечень основных характеристик, которые необходимо учитывать, рассматривая конкретный вид ЗУ, включает в себя: · место расположения; · емкость;Иерархия запоминающих устройств
Память часто называют «узким местом» фон-неймановских ВМ из-за ее серьезного отставания по быстродействию от процессоров, причем разрыв этот… Если проанализировать используемые в настоящее время типы ЗУ, выявляется… · чем меньше время доступа, тем выше стоимость хранения бита;Основная память
Основная память (ОП) представляет собой единственный вид памяти, к которой ЦП может обращаться непосредственно (исключение составляют лишь регистры… Основную память образуют запоминающие устройства с произвольным доступом.… Следствием огромных успехов в области полупроводниковых технологий стало изменение элементной базы основной памяти. На…Блочная организация основной памяти
Емкость основной памяти современных ВМ слишком велика, чтобы ее можно было реализовать на базе единственной интегральной микросхемы (ИМС).… Увеличение разрядности ЗУ реализуется за счет объединения адресных входов…Организация микросхем памяти
Интегральные микросхемы (ИМС) памяти организованы в виде матрицы ячеек, каждая из которых, в зависимости от разрядности ИМС, состоит из одного или… · два стабильных состояния, представляющие двоичные 0 и 1; · в ЗЭ (хотя бы однажды) может быть произведена запись информации, посредством перевода его в одно из двух возможных…Синхронные и асинхронные запоминающие устройства
В качестве первого критерия, по которому можно классифицировать запоминающие устройства основной памяти, рассмотрим способ синхронизации. С этих… В микросхемах, где реализован синхронный принцип, процессы чтения и записи… Асинхронный принцип предполагает, что момент начала очередного действия определяется только моментом завершения…Оперативные запоминающие устройства
Большинство из применяемых в настоящее время типов микросхем оперативной памяти не в состоянии сохранять данные без внешнего источника энергии, то… Энергозависимые ОЗУ можно подразделить на две основные подгруппы:…Статическая и динамическая оперативная память
В статических ОЗУ запоминающий элемент может хранить записанную информацию неограниченно долго (при наличии питающего напряжения). Запоминающий… Роль запоминающего элемента в статическом ОЗУ исполняет триггер. Такой триггер…Статические оперативные запоминающие устройства
Напомним, что роль запоминающего элемента в статическом ОЗУ исполняет триггер. Статические ОЗУ на настоящий момент – наиболее быстрый, правда, и…Динамические оперативные запоминающие устройства
Динамической памяти в вычислительной машине значительно больше, чем статической, поскольку именно DRAM используется в качестве основной памяти ВМ.… Чтобы оценить различия между видами DRAM, предварительно остановимся на… В отличие от SRAM адрес ячейки DRAM передается в микросхему за два шага — вначале адрес столбца, а затем строки, что…Лабораторная работа №5. Расширенная работа с памятью и передача управления в программе
Реализуйте на языке ассемблера микропроцессора i8086 следующие программы, используя команды передачи управления call и ret: 1. Определить результативность стрельбы (n/n1) в круглую мишень радиусом R=10, где n - количество попаданий; n1 -…ГЛАВА 8. Внешние накопители
Важным звеном в иерархии запоминающих устройств является внешняя, или вторичная память, реализуемая на базе различных ЗУ. Наиболее распространенные виды таких ЗУ — это магнитные и оптические диски и магнитоленточные устройства.
Магнитные диски
Информация в ЗУ на магнитных дисках (МД) хранится на плоских металлических или пластиковых пластинах (дисках), покрытых магнитным материалом.…Организация данных и форматирование
Внутреннее устройство дисковых систем
В ЗУ с фиксированными головками приходится по одной головке считывания/ записи на каждую дорожку. Головки смонтированы на жестком рычаге,… Диски с магнитным носителем устанавливаются в дисковод, состоящий из рычага,… Большинство дисков имеет магнитное покрытие с обеих сторон. В этом случае говорят о двусторонних (double-sided)…Массивы магнитных дисков с избыточностью
Концепция массива с избыточностью
Магнитные диски, будучи основой внешней памяти любой ВМ, одновременно остаются и одним из «узких мест» из-за сравнительно высокой стоимости,… Существуют пять основных схем организации данных и способов введения… · RAID представляет собой набор физических дисковых ЗУ, управляемых операционной системой и рассматриваемых как один…Повышение производительности дисковой подсистемы
Повышение производительности дисковой подсистемы в RAID достигается с помощью приема, называемого расслоением или расщеплением (striping). В его… Чаще всего логически последовательные полосы распределяются по… Как уже упоминалось, минимальный объем информации, считываемый с МД или записываемый на него за один раз, равен…Повышение отказоустойчивости дисковой подсистемы
Одной из целей концепции RAID была возможность обнаружения и коррекции ошибок, возникающих при отказах дисков или в результате сбоев. Достигается… · дублирование · код Хэмминга;RAID уровня 0
RAID уровня 0, строго говоря, не является полноценным членом семейства RAID, поскольку данная схема не содержит избыточности и нацелена только на… В основе RAID 0 лежит расслоение данных. Полосы распределены по всем дискам…RAID уровня 1
В RAID 1 избыточность достигается с помощью дублирования данных. В принципе исходные данные и их копии могут размещаться по дисковому массиву…RAID уровня 2
В системах RAID 2 используется техника параллельного доступа, где в выполнении каждого запроса на В/ВЫВ одновременно участвуют все диски. Обычно… При записи вычисляется корректирующий код, который заносится на отведенные… RAID 2 позволяет достичь высокой скорости В/ВЫВ при работе с большими последовательными записями, но становится…RAID уровня 3
RAID 3 организован сходно с RAID2. Отличие в том, что RAID 3 требует только одного дополнительного диска — диска паритета, вне зависимости от того,…RAID уровня 4
По своей идее и технике формирования избыточной информации RAID 4 идентичен RAID 3, только размер полос в RAID 4 значительно больше (обычно…RAID уровня 5
RAID 5 имеет структуру, напоминающую RAID 4. Различие заключается в том, что RAID 5 не содержит отдельного диска для хранения полос паритета, а…RAID уровня 6
RAID 6 очень похож на RAID 5. Данные также разбиваются на полосы размером в блок и распределяются по всем дискам массива. Аналогично, полосы… Рис. 81. RAID уровня 6.RAID уровня 7
Схема RAID 7, запатентованная Storage Computer Corporation, объединяет массив асинхронно работающих дисков и кэш-память, управляемые встроенной в… Схема некритична к виду решаемых задач и при работе с большими файлами не…RAID уровня 10
Данная схема совпадает с RAID 0, но в отличие от нее роль отдельных дисков выполняют дисковые массивы, построенные по схеме RAID 1 (рис. 83). Таким образом, в RAID 10 сочетаются расслоение и дублирование. Это позволяет…RAID уровня 53
В этом уровне сочетаются технологии RAID 0 и RAID 3, поэтому его правильнее было бы назвать RAID 30. В целом данная схема соответствует RAID 0, где роль отдельных дисков выполняют дисковые массивы, организованные по схеме RAID 3. Естественно, что в RAID 53 сочетаются все достоинства RAID 0 и RAID 3. Недостатки схемы такие же, что и у RAID 10.
Особенности реализации RAID-систем
Массивы RAID могут быть реализованы программно, аппаратно или как комбинация программных и аппаратных средств. При программной реализации используются обычные дисковые контроллеры и… Аппаратурная реализация RAID предполагает возложение всех или большей части функций по управлению массивом дисковых ЗУ…Оптическая память
В 1983 году была представлена первая цифровая аудиосистема на базе компакт-дисков (CD — compact disk). Компакт-диск — это односторонний диск,… Для аудио компакт-дисков и CD-ROM используется идентичная технология. Основное… Информация с диска считывается маломощным лазером, расположенным в проигрывателе. Лазер освещает поверхность…Контрольные вопросы
1. Перечислите основные компоненты HDD.
2. Какие две цели достигаются с помощью организации HDD в RAID?
3. Оцените утилизацию дискового пространства для RAID 1 и 5.
4. Какие преимущества имеются у составных RAID-массивов?
5. За счёт чего достигается повышенная отказоустойчивость RAID?
6. От чего зависит количество секторов на дорожке?
7. Каким способом можно увеличить плотность записи на пластину HDD?
8. На чём основан принцип считывания информации с CD?
9. Почему в CD используется только метод считывания с постоянной линейной скоростью?
10. За счёт чего увеличена ёмкость DVD по сравнению с CD?
ГЛАВА 9. Основы параллельных вычислений
В основе архитектуры большинства современных ВМ лежит представление алгоритма решения задачи в виде программы последовательных вычислений. Базовые архитектурные идеи ВМ, ориентированной на последовательное исполнение команд программы, были сформулированы Джоном фон Нейманом. В условиях постоянно возрастающих требований к производительности вычислительной техники все очевидней становятся ограничения классической фон-неймановской архитектуры, обусловленные исчерпанием всех основных идей ускорения последовательного счета. Дальнейшее развитие вычислительной техники связано с переходом к параллельным вычислениям как в рамках одной ВМ, так и путем создания многопроцессорных систем и сетей, объединяющих большое количество отдельных процессоров или отдельных вычислительных машин. Для такого подхода вместо термина «вычислительная машина» более подходит термин «вычислительная система» (ВС). Отличительной особенностью вычислительных систем является наличие в них средств, реализующих параллельную обработку, за счет построения параллельных ветвей в вычислениях, что не предусматривалось классической структурой ВМ. Идея параллелизма как средства увеличения быстродействия ЭВМ возникла очень давно — еще в XIX веке.
Уровни параллелизма
Методы и средства реализации параллелизма зависят от того, на каком уровне он должен обеспечиваться. Обычно различают следующие уровни… · Уровень заданий. Несколько независимых заданий одновременно выполняются на… · Уровень программ. Части одной задачи выполняются на множестве процессоров. Данный уровень достигается на…Параллелизм уровня задания
Параллелизм уровня задания возможен между независимыми заданиями или их фазами. Основным средством реализации параллелизма на уровне заданий служат многопроцессорные и многомашинные вычислительные системы, в которых задания распределяются по отдельным процессорам или машинам. Однако, если трактовать каждое задание как совокупность независимых задач, реализация данного уровня возможна и в рамках однопроцессорной В С. В этом случае несколько заданий могут одновременно находиться в основной памяти ВС, при условии, что в каждый момент выполняется только одно из них. Когда выполняемое задание требует ввода/вывода, такая операция запускается, а до ее завершения остальные ресурсы ВС передаются другому заданию. По завершении ввода/вывода ресурсы ВС возвращаются заданию, инициировавшему эту операцию. Здесь параллелизм обеспечивается за счет того, что центральный процессор и система ввода/вывода работают одновременно, обслуживая разные задания.
В качестве примера рассмотрим вычислительную систему с четырьмя процессорами. ВС обрабатывает задания, классифицируемые как малое (S), среднее (М) и большое (L). Для выполнения малых заданий требуется один, средних — два, а больших заданий — четыре процессора. Обработка каждого задания занимает одну условную единицу времени. Первоначально существует такая очередь заданий: S M L S S M L L S M M(таблица 6).
| Таблица 6 | ||
| Время | Выполняемые задания | % использования ВС |
| S, M | ||
| L | ||
| S, S, М | ||
| L | ||
| L | ||
| S, М | ||
| М |
При этом средний уровень использования ресурсов вычислительной системы равен 83,3%; на выполнение всех заданий требуется 7 единиц времени.
Для получения большей степени утилизации ресурсов ВС разрешим заданиям «выплывать» в начало очереди. Тогда можно получить следующую последовательность выполнения заданий: S M S L S M S L L M M(таблица 7).
| Таблица 7 | ||
| Время | Выполняемые задания | % использования ВС |
| S, M, S | ||
| L | ||
| S, М, S | ||
| L | ||
| L | ||
| М, М |
При этом средний процент использования ресурсов ВС составляет 100%; на выполнение всех заданий требуется 6 единиц времени.
Параллелизм возникает также, когда у независимых заданий, выполняемых в ВС, имеются несколько фаз, например вычисление, запись в графический буфер, В/ВЫВ на диск или ленту, системные вызовы.
Пусть выполняется задание и оно для своего продолжения нуждается в выполнении ввода/вывода. По сравнению с вычислениями он обычно более длителен, поэтому текущее задание приостанавливается и запускается другое задание. Исходное задание активизируется после завершения ввода/вывода. Все это требует специального оборудования: каналов В/ВЫВ или специальных процессоров В/ ВЫВ. За то, как различные задания упорядочиваются и расходуют общие ресурсы, отвечает операционная система.
Параллелизм уровня программ
О параллелизме на уровне программы имеет смысл говорить в двух случаях. Во-первых, когда в программе могут быть выделены независимые участки,… Таблица 8 Задача Зрение Манипуляция …Параллелизм уровня команд
Параллелизм на уровне команд имеет место, когда обработка нескольких команд или выполнение различных этапов одной и той же команды может… В первом варианте совмещение операций достигается за счет того, что в составе…Метрики параллельных вычислений
В силу особенностей параллельных вычислений для оценки их эффективности используют специфическую систему метрик. Наиболее распространенные из таких метрик рассматриваются ниже.
Профиль параллелизма программы
Число процессоров многопроцессорной системы, параллельно участвующих в выполнении программы в каждый момент времени t, определяют понятием степень… В дальнейшем будем исходить из следующих предположений: система состоит из п…Ускорение, эффективность, загрузка и качество
Рассмотрим параллельное выполнение программы со следующими характеристиками: · О(п) — общее число операций (команд), выполненных на п-процессорной… · Т(п) — время выполнения O(п) операций на «-процессорной системе в виде числа квантов времени.Закон Амдала
Приобретая для решения своей задачи параллельную вычислительную систему, пользователь рассчитывает на значительное повышение скорости вычислений за… Джин Амдал (Gene Amdahl) — один из разработчиков всемирно известной системы… Напомним, что ускорение S — это отношение времени Ts, затрачиваемого на проведение вычислений на однопроцессорной ВС…Закон Густафсона
Известную долю оптимизма в оценку, даваемую законом Амдала, вносят исследования, проведенные уже упоминавшимся Джоном Густафсоном из NASA Ames… Рис. 88. К постановке задачи в законе Густафсона.Классификация параллельных вычислительных систем. Классификация Флинна
Даже краткое перечисление типов современных параллельных вычислительных систем (ВС) дает понять, что для ориентирования в этом многообразии необходима четкая система классификации. От ответа на главный вопрос — что заложить в основу классификации — зависит, насколько конкретная система классификации помогает разобраться с тем, что представляет собой архитектура ВС и насколько успешно данная архитектура позволяет решать определенный круг задач. Попытки систематизировать все множество архитектур параллельных вычислительных систем предпринимались достаточно давно и длятся по сей день, но к однозначным выводам пока не привели.
Среди всех рассматриваемых систем классификации ВС наибольшее признание получила классификация, предложенная в 1966 году М. Флинном [99, 100]. В ее основу положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. В зависимости от количества потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD, MIMD.
SISD
SISD (Single Instruction Stream/Single Data Stream) — одиночный поток команд и одиночный поток данных (рис. 89, а). Представителями этого класса являются, прежде всего, классические фон-неймановские ВМ, где имеется только один поток команд, команды обрабатываются последовательно и каждая команда инициирует одну операцию с одним потоком данных. То, что для увеличения скорости обработки команд и скорости выполнения арифметических операций может применяться конвейерная обработка, не имеет значения, поэтому в класс SISD одновременно попадают как ВМ CDC 6600 со скалярными функциональными устройствами, так и CDC 7600 с конвейерными. Некоторые специалисты считают, что к SISD-системам можно причислить и векторно-конвейерные ВС, если рассматривать вектор как неделимый элемент данных для соответствующей команды.
MISD
MISD (Multiple Instruction Stream/Single Data Stream) — множественный поток команд и одиночный поток данных (рис. 89, б). Из определения следует, что в архитектуре ВС присутствует множество процессоров, обрабатывающих один и тот же поток данных. Примером могла бы служить ВС, на процессоры которой подается искаженный сигнал, а каждый из процессоров обрабатывает этот сигнал с помощью своего алгоритма фильтрации. Тем не менее ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не сумели представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе. Ряд исследователей относят к данному классу конвейерные системы, однако это не нашло окончательного признания. Отсюда принято считать, что пока данный класс пуст. Наличие пустого класса не следует считать недостатком классификации Флинна. Такие классы, по мнению некоторых исследователей, могут стать чрезвычайно полезными для разработки принципиально новых концепций в теории и практике построения вычислительных систем.
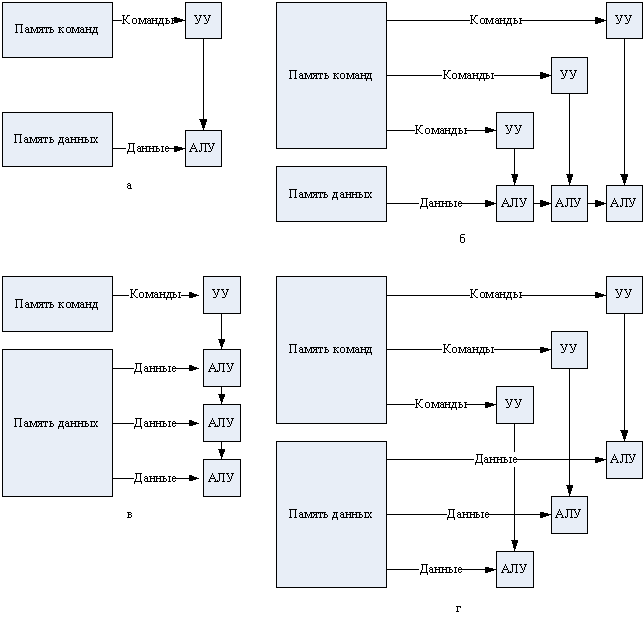
Рис. 89. Архитектура вычислительных систем по Флинну: а – SISD; б –MISD; в – SIMD; г – MIMD.
SIMD
SIMD (Single Instruction Stream/Multiple Data Stream) — одиночный поток команд и множественный поток данных (рис. 89, в). ВМ данной архитектуры позволяют выполнять одну арифметическую операцию сразу над многими данными — элементами вектора. Бесспорными представителями класса SIMD считаются матрицы процессоров, где единое управляющее устройство контролирует множество процессорных элементов. Все процессорные элементы получают от устройства управления одинаковую команду и выполняют ее над своими локальными данными. В принципе в этот класс можно включить и векторно-конвейерные ВС, если каждый элемент вектора рассматривать как отдельный элемент потока данных.
MIMD
MIMD (Multiple Instruction Stream/Multiple Data Stream) – множественный поток команд и множественный поток данных (рис. 89, г). Класс предполагает наличие в вычислительной системе множества устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных. Класс MIMD чрезвычайно широк, поскольку включает в себя всевозможные мультипроцессорные системы. Кроме того, приобщение к классу MIMD зависит от трактовки. Так, ранее упоминавшиеся векторно-конвейерные ВС можно вполне отнести и к классу MIMD, если конвейерную обработку рассматривать как выполнение множества команд (операций ступеней конвейера) над множественным скалярным потоком.
Схема классификации Флинна вплоть до настоящего времени является наиболее распространенной при первоначальной оценке той или иной ВС, поскольку позволяет сразу оценить базовый принцип работы системы, чего часто бывает достаточно. Однако у классификации Флинна имеются и очевидные недостатки, например неспособность однозначно отнести некоторые архитектуры к тому или иному классу. Другая слабость — это чрезмерная насыщенность класса MIMD. Все это породило множественные попытки либо модифицировать классификацию Флинна, либо предложить иную систему классификации.
Контрольные вопросы
1. Сравните схемы классификации параллелизма по уровню и гранулярности.
Каковы, на ваш взгляд, достоинства, недостатки и области применения этих
схем классификации?
2. Для заданной программы и конфигурации параллельной вычислительной системы рассчитайте значения метрик параллельных вычислений.
3. Поясните суть закона Амдала, приведите примеры, поясняющие его ограничения.
4. Какую проблему закона Амдала решает закон Густафсона? Как он это делает? Сформулируйте области применения этих двух законов.
5. Укажите достоинства и недостатки схемы классификации Флинна.
ГЛАВА 10. Архитектура многопроцессорных систем
Классификация многопроцессорных систем
Многопроцессорные системы по классификации Флинна относятся к архитектурам типа MIMD(Multiple Instruction Multipl Data) с множественным потоком команд при множественном потоке данных (МКМД). В многопроцессорной системе каждый процессор выполняет свою программу достаточно независимо от других процессоров. Процессоры в ходе решения общей задачи должны связываться друг с другом в соответствии с графом взаимодействия её параллельных ветвей. Это вызывает необходимость более подробно производить классификацию систем типа MIMD.
В многопроцессорных системах с общей памятью (сильносвязанных) имеется память данных и команд, доступная всем процессорам. С общей памятью процессоры связываются с помощью коммуникационной среды, основой которой может быть либо общая шина (ОШ), либо множество шин (МШ), либо перекрёстный коммутатор (ПК).
В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с распределённой памятью) вся память разделена между процессорами и каждый блок памяти доступен только локальному процессору. Память и процессор образуют фактически независимые вычислительные модули (вычислительные узлы), которые связываются между собой при помощи высокоскоростной сети обмена с коммутацией сообщений.
Сообщение – это блок информации, сформированный процессом-отправителем таким образом, чтобы он был понятен процессу-получателю. Сообщение состоит из заголовка фиксированной длины и набора данных определённого типа обычно переменной длины. В заголовок, как правило, включают следующую информацию:
• адрес - это поле, предназначенное для идентификации процессоров (вычислительных узлов), участвующих в процедуре обмена. Адрес процессора или вычислительного узла является уникальным и состоит из двух частей - адреса процессора - отправителя и адреса процессора - получателя;
• управляющие поля, в которые могут входить символы синхронизации, отмечающие начало и конец передаваемого блока (кадра) данных, символы, обозначающие тип данных, длину передаваемых данных и др.
В качестве топологической модели коммуникационной среды применяют линейные или кольцевые моноканалы, звездообразную конфигурацию, плоскую решётку, n- мерный тор, либо n- кубическую (гиперкубическую) сеть.
Базовой моделью вычислений на MIMD-системах является совокупность независимых процессов, время от времени обращающихся к разделяемым данным. Основана она на распределенных вычислениях, в которых программа делится на довольно большое число параллельных задач.
В настоящее время всё большее внимание разработчики проявляют к архитектурам типа MIMD. Это находит объяснение главным образом существованием двух факторов:
1) в архитектурах MIMD используются высокотехнологичные, дешёвые, выпускаемые массово микропроцессоры, что позволяет оптимизировать соотношение стоимость/производительность;
2) архитектура MIMD дает большую гибкость и при наличии соответствующей поддержки со стороны аппаратных средств и программного обеспечения, поскольку может работать и как однопрограммная система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, и как многопрограммная, выполняющая множество задач параллельно, а также как некоторая комбинация этих возможностей.
Одной из отличительных особенностей многопроцессорной вычислительной системы является коммуникационная среда, с помощью которой процессоры соединяются друг с другом или с памятью. Топология коммуникационной среды настолько важна для многопроцессорной системы, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, которые в общем случае зависят от алгоритмов решаемых задач и порождаемых ими вычислительных процессов.
Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти.
В многопроцессорных системах с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом "почтового ящика".
В архитектурах с распределённой памятью непосредственное разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, каналов обмена и пропускной способности памяти.
Такие системы часто называют системами с передачей сообщений. Каждый из этих механизмов обмена имеет свои преимущества. Для обмена в общей памяти это включает:
• совместимость с хорошо понятными и используемыми в однопроцессорных системах механизмами взаимодействия процессора с основной памятью;
• простота программирования, особенно это заметно в тех случаях, когда процедуры обмена между процессорами сложные или динамически меняются во время выполнения. Подобные преимущества упрощают конструирование компилятора;
• более низкая задержка обмена и лучшее использование полосы пропускания при обмене малыми порциями данных;
• возможность использования аппаратно управляемого кэширования для снижения частоты удаленного обмена, допускающая кэширование всех данных как разделяемых, так и неразделяемых.
Основные преимущества обмена с помощью передачи сообщений являются:
• аппаратура может быть более простой, особенно по сравнению с моделью разделяемой памяти, которая поддерживает масштабируемую когерентность кэш-памяти;
• процедуры обмена понятны, принуждают программистов (или компиляторы) уделять внимание обмену, который обычно имеет высокую, связанную с ним, стоимость.
Часто, в системах с общей памятью затраты времени на обмен не учитываются, так как проблемы обмена в значительной степени скрыты от программиста. Однако накладные расходы на обмен в этих системах имеются и определяются в основном конфликтами при доступе процессоров и других устройств к общим шинам и блокам основной памяти. Чем больше процессоров добавляется в систему, тем больше процессов соперничают при использовании одних и тех же данных и шины, что может привести к значительным задержкам хода вычислительного процесса и, следовательно, к потерям общей производительности. Причём с увеличением числа процессоров в системе возможно появление эффекта насыщения при котором рост числа процессоров не приведёт к росту производительности, и даже наоборот к её падению.
Модель системы с общей памятью очень удобна для прогаммирования, поскольку пользователь практически не задумывается о процедурах распараллеливания (они большей частью ложатся на компилятор) и процедурах взаимодействия параллельных процессов (они производятся аппаратными средствами посредством общей памяти).
В сетях с коммутацией сообщений по мере возрастания требований к обмену следует учитывать возможность перегрузки сети. Здесь межпроцессорный обмен связывает сетевые ресурсы: каналы, процессоры, буферы сообщений. Объем передаваемой информации может быть сокращен за счет тщательного разбиения задачи на параллельные ветви и тщательной диспетчеризации процесса их исполнения.
Таким образом, существующие MIMD-системы распадаются на два основных класса в зависимости от количества объединяемых процессоров, которое определяет способ организации памяти и методику их межсоединений.
К первому классу относятся системы с разделяемой (общей) основной памятью (Shared Memory multiProcessing, SMP), объединяющие до нескольких (2-16) процессоров, число которых зависит от типа применяемой коммуникационной среды. Сравнительно небольшое количество процессоров в таких системах позволяет иметь одну централизованную общую память и зачастую объединить процессоры и память с помощью лишь одной шины. При наличии у процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров.
Поскольку имеется единственная память с одним и тем же временем доступа, эти системы называют симметричными, а иногда - UMA (Uniform Memory Access). Симметричная архитектура предполагает однородность процессоров и единообразную схему их включения в многопроцессорную систему. Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным.
Структура подобной системы представлена на рис. 90.
Рис. 90. Архитектура многопроцессорной системы с разделяемой (общей) памятью.
Второй класс составляют крупномасштабные вычислительные системы с распределенной памятью. Подобные ВС получили название систем с массовым параллелизмом (Mass-Parallel Processing, MPP). Для того чтобы подключать в систему большое количество процессоров необходимо физически разделять основную память и распределять её между ними. В противном случае пропускной способности памяти просто может не хватить для удовлетворения запросов, поступающих от очень большого числа процессоров. Естественно при таком подходе также требуется реализовать связь процессоров между собой. На рис. 91 показана структура такой системы.

Рис. 91. Архитектура многопроцессорной системы с распределенной памятью.
Адресное пространство в таких системах состоит из отдельных адресных пространств, которые логически не связаны, и доступ к которым не может быть осуществлен аппаратно другим процессором. Фактически каждый модуль процессор-память представляет собой отдельный компьютер, поэтому такая структура в какой-то степени приближена к многопроцессорным системам.
MPP система менее эффективна с точки зрения пользователя из-за усложнённой процедуры программирования, которая связана с применением специальных коммуникационных библиотек для организации взаимодействия между вычислительными узлами (процессами). Необходимость же реализации модели распределенной памяти объясняется тем, что масштабируемость (способность системы к наращиванию числа процессоров) систем с общей памятью ограничена пропускной способностью памяти и коммуникационной среды.
Вообще распределение памяти между отдельными узлами системы имеет два главных преимущества. Во-первых, это эффективный с точки зрения стоимости способ увеличения пропускной способности памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во- вторых уменьшается задержка обращения к локальной памяти из-за отсутствия конфликтов при доступе к ней. Поэтому совершенно естественно появление промежуточного класса систем, объединяющего достоинства первого и второго классов. Память в таких системах распределена по вычислительным узлам и одновременно является доступной для всех процессоров. Такие ВС называются системами с распределенной разделяемой (общей) памятью (DSM - Distributed Shared Memory), а иногда NUMA ( Non-Uniform Memory Access), поскольку время доступа зависит от расположения данных в подсистеме памяти (Рис. 92). Если данные находятся в локальной памяти местного вычислительного узла, то время доступа к ним минимально, если в локальной памяти удалённого вычислительного узла, то время доступа
увеличивается в несколько раз.
Рис. 92. Архитектура многопроцессорной системы с распределённой разделяемой памятью.
Хотя структурно DSM и MPP-системы сходны, однако технически они реализуются по-разному. В DSM-системах физически отдельные, распределённые по вычислительным узлам, устройства памяти могут представляться логически как единое адресное пространство, что означает, что любой процессор может выполнять обращения к любым ячейкам памяти, предполагая, что он имеет соответствующие права доступа.
Коммуникационная же среда и вовсе другая, так как она полностью соответствует структурам SMP-систем. Поскольку, в связи с принципами локальности, вычислительный процесс в основном развивается внутри вычислительного узла и редко обращается к удалённой памяти, что резко снижает объём передаваемых данных по коммуникационной среде, то масштабируемость таких систем повышается по сравнению с SMP-системами, и число процессоров может достигать 32-х.
Что касается устройств ввода/вывода и внешних запоминающих устройств, то они также как и память, либо распределяются по узлам, либо находятся в общем пользовании.
Организация коммуникационной среды в системах с разделяемой памятью.
Коммуникационную среду, реализующую множество соединений между процессорами или вычислительными узлами в многопроцессорных системах, называют коммутатором. По способу реализации различают коммутаторы с временной и пространственной коммутацией.
При временной коммутации передача информации осуществляется методами разделения времени или мультиплексирования. Такой коммутатор называется в простейшем случае общей шиной (ОШ).
Структура многопроцессорной системы с общей шиной представлена на
рис. 93.
В каждый момент времени ОШ способна, передавать лишь одно сообщение, т. е. она представляет собой разделенную во времени шину. Это говорит о возможности возникновения конфликтных ситуаций тогда, когда нескольким модулям одновременно необходимо связаться со своими абонентами - вычислительными узлами.

Рис. 93. Структура системы с коммуникационной средой на основе
общей шины.
Процедура занятия ОШ абонентами, являющимися источниками информации, заключается в их "борьбе" за ОШ. Достоинством коммутаторов с ОШ является простота организаций и гибкость (простое добавление и изъятие модулей). Очевидно, что такой коммутатор не может обеспечить высокую пропускную способность. Для всех потоков информации здесь только один путь, поэтому временные задержки при передаче данных значительны. Из-за этого оказываются низкими общая производительность, поскольку различные пары абонентов не могут работать одновременно, и надежность системы, так как отказ в единственном пути передачи информации ведет к отказу всей системы.
Пространственную коммутацию осуществляет перекрестный коммутатор (ПК). Он представляет собой многополюсник с М входами и N выходами, допускающими одновременное установление любого количества соединений между заданными входами и выходами.
Структуру системы с перекрестным коммутатором можно представить так как показано на рис. 94. Между любыми двумя абонентами здесь устанавливается физический контакт на все время передачи информации. При этом возможные конфликты между модулями разрешаются в логических схемах коммутационной матрицы, что существенно усложняет аппаратуру коммутаторов. В отличие от систем с ОШ, где во-первых коммутационного оборудования много меньше, а во-вторых эти функции могут быть возложены на вычислительные узлы или на центральный арбитр шины.
У перекрестного коммутатора в противоположность общей шине имеется больше достоинств, но есть и существенные недостатки, к которым относятся сложность внутренних связей, ведущая к усложнению аппаратуры и плохая масштабируемость, ограниченная числом входов и выходов коммутатора.
Достоинствами ПК являются: возможность установления нескольких одновременных путей передачи информации; обеспечение большей производительности и надежности многопроцессорной системы.
Более экономичной схемой пространственной коммутации по сравнению с ПК является схема, использующая многовходовую память (рис. 95).

Рис. 94. Многопроцессорная система с коммуникационной средой на
основе перекрёстного коммутатора.

Рис. 95. Многопроцессорная система с многошинной коммуникационной средой.
Здесь имеет место меньшее количество точек, в которых нужно разрешать конфликты. Максимально возможная конфигурация системы (количество подключаемых процессоров) ограничивается числом входов блоков памяти.
Когерентность кэш- памяти в SMP- системах.
Требования, предъявляемые современными процессорами к полосе пропускания памяти можно существенно сократить путем применения больших многоуровневых… В первых разработках подобного рода машин удавалось разместить весь процессор и кэш на одной плате, которая затем вставлялась в заднюю панель, с помощью которой реализовывалась шинная…Когерентность кэш- памяти в MPP-системах.
Существуют два различных способа построения крупномасштабных систем с распределенной памятью. Простейший способ заключается в том, чтобы исключить… Наиболее известным примером такой системы является компьютер T3D компании Cray… Чтобы обойти проблемы когерентности, разделяемые (общие) данные не кэшируются. Конечно, с помощью программного…Организация прерываний в мультипроцессорных системах.
Рассмотрим реализацию прерываний в наиболее простых симметричных многопроцессорных системах, в которых используется несколько процессоров,… Характерным примером является система прерываний, реализованная в процессорах… Одной из наиболее серьезных проблем при реализации мультипроцессорных систем является организация обслуживания внешних…ЗАКЛЮЧЕНИЕ
Охватить все аспекты строения и организации вычислительных машин в одном издании (да и в рамках одного курса) не представляется возможным. Знания в…БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Авен, О. И. Оценка качества и оптимизации вычислительных систем / О.И. Авен, Н. Я . Турин, А. Я. Коган. – М.: Наука, 1982. – 464 с. 2. Воеводин, В. В. Параллельные вычисления / В. В. Воеводин, Вл.В. Воеводин.… 3. Воеводин, Вл. В. Методы описания и классификации вычислительных систем / Вл. В. Воеводин, А. П. Капитонова. – М.:…– Конец работы –
Используемые теги: Организация, ЭВМ, систем0.069
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: ОРГАНИЗАЦИЯ ЭВМ И СИСТЕМ
Что будем делать с полученным материалом:
Если этот материал оказался полезным для Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.186 сек.
Новости и инфо для студентов