Суперкомпьютер Nebulae Туманность
TOP500 суперкомпьютеров: "Туманность" готова поглотить "Ягуара"...
01.06.2010 [13:41], Иван Терехов
В рамках открытия Международной суперкомпьютерной конференции ISC`10 в немецком Ганновере, была опубликована новая редакция рейтинга TOP500 самых мощных вычислительных систем. И хотя на этот раз лидер не изменился, в спину ему дышит новичок - потенциальный фаворит. Авторы 35-го списка TOP500 отмечают, что интенсивное развитие суперкомпьютерной отрасли в Китае, речь о котором ведется на протяжении последних лет, начинает давать свои результаты. Впервые за 15 лет, в течение которых составляется рейтинг, КНР смогла в него попасть, причем сразу на второе место.

Суперкомпьютер Nebulae (Туманность), установленный в Национальном суперкомпьютерном центре в Шеньжене по результатам тестирования пакетом Linpack показал производительность на уровне 1,271 петафлопс, оказавшись на втором месте – между Ягуаром (Cray Jaguar – 1,75 петафлопс) и IBM Roadrunner (1,04 петафлопс).

Разработанный китайской компанией Dawning Information Industry, суперкомпьютер состоит из блейд-серверов TC3600, построенных на базе процессоров Intel Xeon 5650 и графических ускорителей NVIDIA Tesla C2050. Создатели заявляют, что возможностей масштабирования архитектуры хватит для достижения показателя в 3 петафлопс, в то время, как нынешний лидер может улучшить результат «всего» до 2,3 петафлопс.
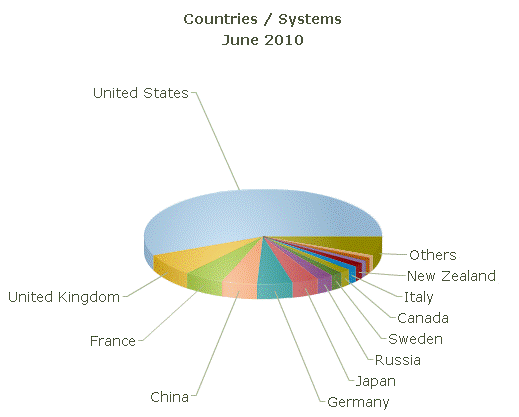
Что касается российских систем, то их количество возросло до 11 машин (в предыдущем списке их было 8), или около 2% всех систем рейтинга. Среди 31 страны Россия занимает 6 место, отставая от США (282 системы), Великобритании (38), Франции (27), Германии и Китая (по 24 на каждую), и Японии (18). Самой мощной системой в России остается суперкомпьютер «Ломоносов», установленный в МГУ. В новой редакции списка он переместился на одну позицию вниз и теперь занимает 13 место. Пиковая производительность машины составляет 414 терафлопс, реальная – 350 терафлопс. Напомним, что в 2011 г. мощность этой системы планируется увеличить до 1 петафлопс.
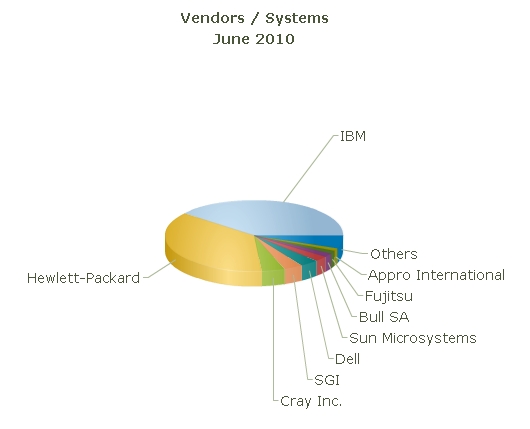
Статистика рейтинга TOP500 говорит о том, что суммарная мощность всех 500 систем превышает 10 петафлопс. Большинство суперкомпьютеров (81,6%) работают на базе процессоров Intel, доля AMD составила 9,4%. Лидерами среди компаний-производителей являются IBM и Hewlett-Packard, на долю которых приходится 39,8% и 37% суперкомпьютеров соответственно.
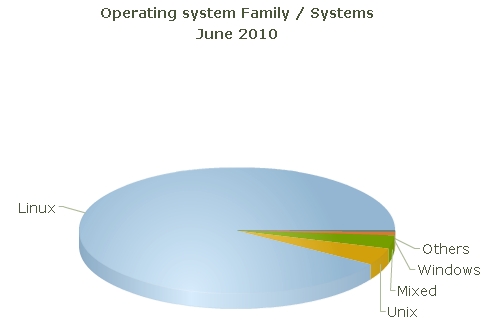
В разрезе операционных систем подавляющее большинство принадлежит Linux – 91% (455 машин), на втором месте – Unix 4,4% (22), доля Windows, BSD и прочих ОС в сумме – менее 5 %.
Лекция. Архитектура векторно-конвейерных супер-ЭВМ CRAY C90
Разделяемые ресурсы процессора
Структура оперативной памяти.
Каждый процессор имеет доступ к ОП через четыре порта с пропускной способностью два слова за один такт каждый, причем один из портов всегда связан с… В максимальной конфигурации вся память разделена на 8 секций, каждая секция на… При одновременном обращении к одной и той же секции из разных портов возникает задержка в 1 такт, а при обращении к…Секция ввода/вывода
Компьютер поддерживает три типа каналов, которые различаются скоростью передачи:
- Low-speed (LOSP) channels - 6 Mbytes/s
- High-speed (HISP) channels - 200 Mbytes/s
- Very high-speed (VHISP) channels - 1800 Mbytes/s
Секция межпроцессорного взаимодействия
Секция межпроцессорного взаимодействия содержит разделяемые регистры и семафоры, предназначенные для передачи данных и управляющей информации между процессорами. Регистры и семафоры разделены на одинаковые группы (кластеры), каждый кластер содержит 8 (32-разрядных) разделяемых адресных (SB) регистра, 8 (64-разрядных) разделяемых скалярных (ST) регистра и 32 однобитовых семафора.
Вычислительная секция процессора
Все процессоры имеют одинаковую вычислительную секцию, состоящую из регистров, функциональных устройств (ФУ) и сети коммуникаций. Регистры и ФУ могут хранить и обрабатывать три типа данных: адреса (A-регистры, B-регистры), скаляры (S-регистры, T-регистры) и вектора (V-регистры).
Регистры
Адресные регистры: A-регистры, 8 штук по 32 разряда, для хранения и вычисления адресов, индексации, указания величины сдвигов, числа итераций циклов… Скалярные регистры: S-регистры, 8 штук по 64 разряда, для хранения аргументов… Векторные регистры: V-регистры, 8 штук на 128 64-разрядных слова каждый. Векторные регистры используются только для…Функциональные устройства
Адресные ФУ (2): целочисленное сложение/вычитание, целочисленное умножение. Скалярные ФУ (4): целочисленное сложение/вычитание, логические поразрядные… Векторные ФУ (5-7): целочисленное сложение/вычитание, сдвиг, логические поразрядные операции (1-2), число единиц/число…Секция управления процессора
Команды выбираются из ОП блоками и заносятся в буфера команд, откуда они затем выбираются для исполнения. Если необходимой для исполнения команды нет в буферах команд, то происходит выборка очередного блока.
Команды имеют различный формат и могут занимать 1 пакет (16 разрядов), 2 пакета или 3 пакета (в одном слове 64 разряда, следовательно, в слове содержится 4 пакета). Максимальная длина программы на CRAY C90 равна 1 Гигаслову.
Параллельное выполнение программ
Конвейеризация выполнения команд
Все основные операции, выполняемые процессором: обращения в память, обработка команд и выполнение инструкций являются конвейерными.
Независимость функциональных устройств
Большинство ФУ в CRAY C90 являются независимыми, поэтому несколько операций могут выполняться одновременно. Для операции A=(B+C)*D*E порядок выполнения может быть следующим (все аргументы загружены в S регистры). Генерируются три инструкции: умножение D и E, сложение B и C и умножение результатов двух предыдущих операций. Первые две операции выполняются одновременно, затем третья.
Векторная обработка
в скалярном режиме потребуется сгенерировать целую последовательность команд: прочитать элемент B(I), прочитать элемент C(I), выполнить сложение,… Перед тем, как векторная операция начнет выдавать результаты, проходит… Векторные операции, использующие различные ФУ и регистры, могут выполняться параллельно.Зацепление функциональных устройств
Архитектура CRAY Y-MP C90 позволяет использовать регистр результатов векторной операции в качестве входного регистра для последующей векторной операции, т.е. выход сразу подается на вход. Это называется зацеплением векторных операций. Вообще говоря, глубина зацепления может быть любой, например, чтение векторов, выполнение операции сложения, выполнение операции умножения, запись векторов.
Многопроцессорная обработка: multiprogramming, multitasking
Multiprogramming - выполнение нескольких независимых программ на различных процессорах.
Multitasking - выполнение одной программы на нескольких процессорах.
Пиковая производительность CRAY Y-MP C90
Пиковая производительность компьютера CRAY Y-MP C90 вычисляется так: функциональные устройства выдают два результата каждый такт (сдвоенные конвейеры), зацепление сложения и умножения дает четыре операции за такт, что составляет почти 1 Гфлопс (109 опер/с). Если работают все 16 процессоров, то 16 Гфлопс.