ПРОЦЕССОР ЧИСЛОВЫХ КОНСТАНТ
Приведем грамматику числовых констант в следующем виде G[<Число>]:
1. <Число> ® [+ | -] <Число Без Знака>
2. <Число Без Знака> ® <Десятичное Число> [Е<целое>] | Е<целое>
3. <Десятичное Число> ® [Ц{Ц}]. Ц{Ц} | Ц{Ц}
4. <Целое> ® [+ | -] <Целое Без Знаков>
5. <Целое Без Знака> ® Ц{Ц}
Легко видеть, что грамматика G[<Число>] является автоматной, поэтому построим граф состояний (схема алгоритмизации, рис. 5.1., 5.2.).
Правило 1) отражено на диаграмме рис. 5.1.
1) <Число> ® <Число Без Знака> | + <Число Без Знака> | - <Число Без Знака>
На Рис.5.1. <Ч> - <Число> , <ЧБЗ> - <Число Без Знака>.

Рис. 5.1. Граф для правила 1) грамматики G[<Число>].
Правило 2) -5) для G[<Число>] реализованы на графе рис. 5.2.
Сплошные стрелки на графе характеризуют синтаксически верный разбор; пунктирные символизируют состояние ошибки (ERROR); непомеченные дуги предполагают любой терминальный символ, отличный от указанного из соответствующего узла. Состояние OUT символизирует успешное завершение разбора.
После синтаксической стадии обработки, как это указывалось выше (см. рис 1.1.), выполняется семантический анализ. Причем семантика в этих методах дополняет синтаксически верные конструкции и инициируется после OUT.
Семантическая обработка текста предполагает смысловое наполнение вычислительного процесса в соответствии с содержанием грамматики. Как правило, семантическая обработка основывается на синтаксических конструкциях. Для грамматик автоматного типа, диаграммы состояний представляют собой “как бы дерево”, на которое, словно “ёлочные украшения” навешиваются семантические атрибуты. Такой “украшенный” граф называется семантическим.
Семантические атрибуты, или смысловые правила, проектируются в зависимости от смыслового содержания данной грамматики, как правило эвристически.

Рис. 5.2. Граф G[<Число>]
Семантические атрибуты числовой константы имеют вид [78]:
n1: m = 10m + d
n2: n = n + 1; m = 10m + d
n3: p = 10p + d
n4: m = 1
n5: s = -1
n6: R = m*10
Начальные условия:
m = p = n = 0; s = 1,
где m — текущее значение мантиссы; p — текущее значение порядка;
n — счётчик числа десятичных цифр в мантиссе; s — знак порядка;
d — значение сканируемого символа (лексемы).
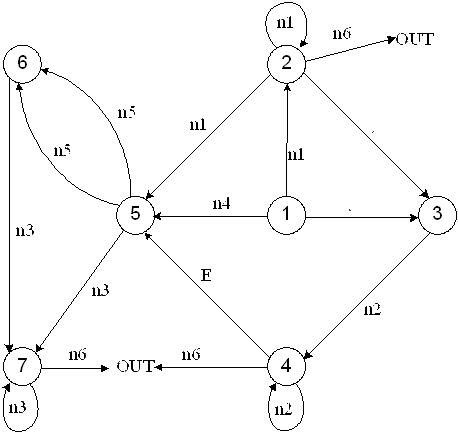
Рис. 5.3. Семантический граф для G[<Число>]
Семантический граф отличается от синтаксического тем, что на нем нет состояния ERROR, и это не противоречит логике связей компилятора, то есть семантическая обработка может начаться только в случае успешной синтаксической обработки. Поэтому компилятор в рассмотренной технологии является многопроходным, то есть исходный текст на языке, порождаемым данной грамматикой, просматривается слева направо не менее двух раз. Первый проход - фаза синтаксического анализа, второй проход - семантический анализ.
Рассмотрим пример разбора числовой константы в соответствии рис. 5.2. , 5.3.:
Пусть числовая константа имеет вид: 1.02Е-2
Тогда «путешествие» по графу рис. 5.3. вызовет следующие семантические атрибуты:
n1: m = 1
n2: n = 1; m = 10
n2: n = 2; m = 102
n5: s = -1
n3: p = 2
n6: R = 102 * 10(-2-2) = 102*10-4 = 0,0102
Представленный процессор числовых констант, выполняющий синтаксический и семантический анализ является универсальным. Изменяя грамматику, можно преобразовать любые числовые константы, спроектированные для предметного пользования.
В современных языках программирования, процедуру преобразования символа в числовой эквивалент встроили в компилятор как библиотеки стандартных функций. Однако эти процедуры жестко регламентированы форматом входных данных, иначе говоря, пользователю нельзя изменить грамматику допустимых числовых констант. Например, в языке Си существует функция atoi(S), которая преобразует символьную цепочку S в её числовой эквивалент. Ограничением является то, что S должна быть целым числом. Функция atof(S) также преобразует символьную цепочку в её числовой эквивалент, но здесь числовые константы должны быть с плавающей точкой типа float.