рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Программирование
- /
- Очистка мусора
Реферат Курсовая Конспект
Очистка мусора
Очистка мусора - раздел Программирование, СИНТАКСИЧЕСКИЙ И СЕМАНТИЧЕСКИЙ АНАЛИЗ Мусором Будем Называть Вспомогательные Сиволы, Которые Не Являются Нос...
Мусором будем называть вспомогательные сиволы, которые не являются носителями смыслового содержания текста. Такими символами являются символы табуляции ‘t’, символы перевода на новую строку ‘n’, пробелы ‘ ’, комментарии и другие. Эти символы используются только при редактировании исходного текста, когда необходимо соблюдать определённое форматирование текста и повысить читабельность.
На Рис 5.4. Показана схема потоков при очистке мусора
|
|
 | |||
 |
ungetc(liter, stdio)
Рис 5.4.
Реализация процедуры очистки от мусора осуществляется с помощью стандартных функций getchar( ) и ungetc( ) из встроенной стандартной библиотеки <stdio.h>. Ниже приведена функция clear ( ) , которая очищает текст от символов табуляции, переводов строки и пробелов и возвращает очищенный текст во входной поток studio.
#include <stdio.h>
int clear ( )
{
int liter;
while (1) /* цикл по всему входному потоку символов
{
liter = getchar( );
if ( liter = = ' ' | | liter = = ' n ' || liter = = ' t ' )
then ungetc (liter, stdio);
}
}
Рис 5.5.
Часто в процессорах функцию сканера заменяет синтаксический анализатор, при этом нет необходимости в специальном просмотре исходного текста, который осуществляется на этапе синтаксического анализа. В отличие от синтаксического анализатора, сканер определяет лишь принадлежность символов алфавиту языка и не устанавливает принадлежность языковых конструкций к грамматике.
Проиллюстрируем разработку сканера, используя грамматику арифметических выражений языка ФОРТРАН (в усеченном варианте).
1. <AB> ® T | <AB> + T | <AB> - T
2. T ® O | T*O | T/O | T**O
3. O ® (<AB>) | <Идентификатор> | <Целое без знака>
Функции сканера на этом примере является: внутреннее представление символов арифметического выражения, причем под внутренним представлением будем понимать некий код, который ставится в соответствие идентификаторам, числовым константам и другим объекта языка.
Важно знать, какой идентификатор или его адрес в таблице символов используется в программе. Поэтому вместе с выбором класса или кода символов необходимо в качестве продукта работы сканера иметь ссылку на его адрес.

На рис. 5.6. приведена диаграмма состояний для грамматики G[AB]. На диаграмме представлена посимвольная декомпозиция арифметических выражений с генерацией соответствующего кода символов <идентификатор>, <целое без знака> и литеры “+”, ”-” и др.. Непомеченные дуги на диаграмме соответствуют состоянию ERROR (отсутствие данного символа в словаре грамматики), либо выходу из обработки очередного символа и переходу на старт обработки следующего.
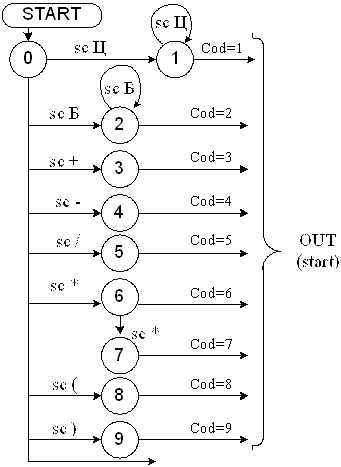
Рис. 5.6. Диаграмма состояний сканера
Пример 5.2.Пусть арифметическое выражение имеет вид :A1*A2 #.
Проиллюстрируем движение по состояниям графа для данного примера:
0 – 2 – 2 – OUT – START – 6 – OUT – START – 2 – 2 – OUT
Семантика сканера. На семантической диаграмме “навешаны” семантические атрибуты: SC — сканирование очередного символа, Ц — адресная генерация кода соответствующего символа.
Реализацию сканера по диаграмме состояний или по графу на рис. 5.6. приведем на языке С. Отметим, что данная реализация универсальна для графов, в которых переходы соответствуют терминальному символу из узла в узел, либо по петле. Поэтому программа для графа 5.3. мало, чем будет отличаться от приведенной ниже.
# include <ctype.h>
# include <stdio.h>
# define ERROR 0
int i = 0;
int num = 0;
/*---------------------------------------------------------------------*/
main()
{
while((i = scaner()) != ERROR) printf(“%d”, i);
}
/*---------------------------------------------------------------------*/
scaner( )
{
int liter;
liter=getchar( );
if (isdigit(liter))
{ while(isdigit(liter = getchar()));
ungetchar(liter);
return(1);
}
else
if (isalpha(liter))
{
while(isnum(liter = getchar()) | | (isalpha(liter));
ungetchar(liter);
return(2);
}
else
switch(liter)
{
case ‘+’: return(3);
case ‘-’: return(4);
case ‘/’: return(5);
case ‘*’: if ((liter = getchar() = = ‘*’)
return(7);
else
{
ungetchar(liter);
return(6);
}
case ‘(’: return(8);
case ‘)’: return(9);
default : ungetchar(liter);
return(ERROR);
}
}
В приведённом примере реализации сканирования символов грамматики выражений эта процедура сознательно упрощена из методических соображений и чтобы не усложнять реализующую программу , которая в приведённом простом варианте доступна и читабельна.
Опишем дополнительные атрибуты сканера, используя для символов идентификатор и целое алгебру регулярных выражений.
– Конец работы –
Эта тема принадлежит разделу:
СИНТАКСИЧЕСКИЙ И СЕМАНТИЧЕСКИЙ АНАЛИЗ
На сайте allrefs.net читайте: "СИНТАКСИЧЕСКИЙ И СЕМАНТИЧЕСКИЙ АНАЛИЗ"
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Очистка мусора
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.02 сек.
Новости и инфо для студентов