Декомпозиция программы при лексическом анализе
Основным функциональным назначением сканера является декомпозиция программы на её терминальные составляющие: идентификаторы, ключевые слова, числовые константы, знаки операций и так далее. Эти языковые конструкции являются сентенциальными формами своих деревьев или терминальными символами. Причём эти терминальные символы могут состоять из одной (знаки операций '+', '-', '/', '*', …) или нескольких литер (идентификаторы, числовые константы, …). Для иллюстрации выполним декомпозицию над арифметическими выражениями языка FORTRAN.
Грамматика арифметических выражений FORTRAN, G[<АВ>] была рассмотрена раньше. Приведём её с заменой нетерминала <АВ> на E.
G[E]:
E ® T | E + T | E – T
T ® O | O * T | O / T | O ** T
O ® ( E ) | num | id
В качестве операнда рассматриваются целые числовые константы (num) и идентификаторы (id). Это ограничение в операнде O не нарушает общности и выполнено с чисто методическими целями, чтобы был понятен основной механизм декомпозиции. Увеличение размерности (наличие альтернатив) в операнде никак не влияет на алгоритмическую идеологию.
Основная декомпозиция сентенциальной формы будет проходить на уровне операнда (O). Выделение знаковых конструкций производится на уровне выражения (E) и терма (T).
Приведённая грамматика G[E] не может быть LL(1) и даже LL(k)-грамматикой [3], поскольку для любого k = 1, 2, 3, … нетерминальному символу E может соответствовать выражение вида (((…(a)…))) + a или (((…(a)…))) – a, содержащие (k+1) пар скобок, и следовательно, просмотр этого выражения на k символов вперёд не позволит определить альтернатив E ® E + T или E ® E – T. Это неудобный вид КС-грамматики. Построим эквивалентную G'[E]:
E ® TA
A ® e | + TA | – TA
T ® OB
B ® e | * OB | / OB | ** OB
O ® num | id | ( E )
Построенная грамматика является LL(1)-грамматикой и для неё легко построить синтаксическую диаграмму (см. рис. ). Легко убедится в эквивалентности G и G', так как обе грамматики порождают один и тот же язык. L(G) = L(G'). Забегая вперёд, отметим, что синтаксический анализ LL(1)-грамматик производится методом рекурсивного спуска, который с одной стороны является однозначным и безвозвратным, с другой – весьма прост и эффективен при реализации.
Теперь по известным правилам (см. р. 3.2.) от синтаксической диаграммы (рис.5.8. ) легко перейти к диаграмме состояний, представленной на рис.5.6. В этой диаграмме целые и идентификаторы перенесены первыми. В остальном, структура графа осталась без изменения.
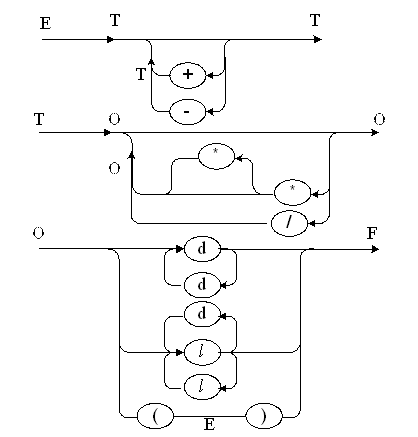
Рис. 5.7. Синтаксическая диаграмма G[E]
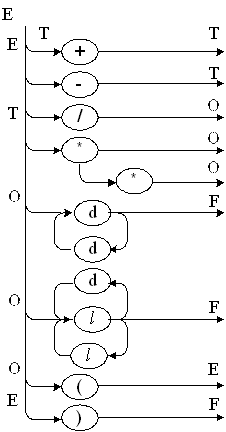
Рис.5.8. Обобщённая синтаксическая диаграмма
Семантика простого кодирования может быть без нарушения алгоритма выполнена с использованием аппарата регулярных выражений. Покажем как это выглядит для приведённых конструкций <ЦБЗ> = num, <ид> = id и операций.