Исследование методов эффективного кодирования дискретных источников информации
Лабораторная работа № 5
«Исследование методов эффективного кодирования дискретных источников информации»
ОСНОВНЫЕ ТЕОРЕТИЧЕСКИЕ ПОЛОЖЕНИЯ
Для передачи и хранения информации, как правило, используется двоичное кодирование. Любое сообщение передается в виде различных комбинаций двух… Если алфавит Aсостоит изNсимволов, то для их двоичного кодирования необходимо… n = élog2 Nù .N2 = élog2 Nù== élog2 50ù=6.
Очевидно, передача сообщения с помощью такого кода будет более эффективной, т.к. будет требовать меньшего количества бинарных сигналов при кодировании. Можно говорить о том, что при таком кодировании мы не передаем избыточную информацию, которая была бы в восьмибитовом кодировании;
· Использовать специальный код со словом переменной длины, в котором символы, появляющиеся в сообщении с наибольшей вероятностью, будут закодированы короткими словами, а наименее вероятным символам сопоставлять длинные кодовые комбинации. Такое кодирование называется эффективным.
Эффективное кодирование базируется на основной теореме Шеннона для каналов без шума, в которой доказано, что сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных символов на букву будет сколь угодно близко к энтропии источника этих сообщений, но не меньше этой величины.
Теорема не указывает конкретного способа кодирования, но из нее следует, что при выборе каждого символа кодовой комбинации необходимо стараться, чтобы он нес максимальную информацию. Следовательно, каждый элементарный сигнал должен принимать значения 0 и 1 по возможности с равными вероятностями и каждый выбор должен быть независим от значений предыдущих символов.
При отсутствии статистической взаимосвязи между кодируемыми символами конструктивные методы построения эффективных кодов были даны впервые К. Шенноном и Н. Фано. Их методики существенно не различаются, поэтому соответствующий код получил название кода Шеннона-Фано.
Код строится следующим образом:
буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей. Затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы. Всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним — 0. Каждая из полученных групп, в свою очередь, разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве.
Рассмотрим алфавит из восьми букв (табл. 1). Ясно, что при обычном (не учитывающем статистических характеристик) кодировании для представления каждой буквы требуется n2 =3символа. В табл.1 приведен один из возможных вариантов кодирования по сформулированному выше правилу.
| Таблица 1 | |||||||
| Символы | Вероятности p(ai) | Кодовые комбинации | 1 ступень | 2 ступень | 3 ступень | 4 ступень | ступень |
| a1 | 0.22 | ||||||
| a2 | 0.20 | ||||||
| a3 | 0.16 | ||||||
| a4 | 0.16 | ||||||
| a5 | 0.10 | ||||||
| a6 | 0.10 | ||||||
| a7 | 0.04 | ||||||
| a8 | 0.02 |
Очевидно, для указанных вероятностей можно выбрать другое разбиение на подмножества не нарушая алгоритма Шеннона-Фано. Такой пример приведен в табл.2.
Сравнивая приведенные таблицы, обратим внимание на то, что по эффективности полученные коды различны. Действительно, в табл.2 менее вероятный символ a4 будет закодирован двухразрядным двоичным числом, в то время как a2 , вероятность появления которого в сообщении выше, кодируется трехразрядным числом.
Таким образом, рассмотренный алгоритм Шеннона-Фано не всегда приводит к однозначному построению кода. Ведь при разбиении на подгруппы можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппу.
| Таблица 2 | |||||||
| Символы | Вероятности p(ai) | Кодовые комбинации | 1 ступень | 2 ступень | 3 ступень | 4 ступень | ступень |
| a1 | 0.22 | ||||||
| a2 | 0.20 | ||||||
| a3 | 0.16 | ||||||
| a4 | 0.16 | ||||||
| a5 | 0.10 | ||||||
| a6 | 0.10 | ||||||
| a7 | 0.04 | ||||||
| a8 | 0.02 |
Энтропия набора символов в рассматриваемом случае определяется как
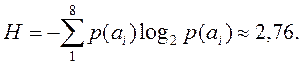
Напомним, что смысл энтропии в данном случае, как следует из теоремы Шеннона, – наименьшее возможное среднее количество двоичных разрядов, необходимых для кодирования символов алфавита размера восемь с известными вероятностями появления символов в сообщении.
Мы можем вычислить среднее количество двоичных разрядов, используемых при кодировании символов по алгоритму Шеннона-Фано
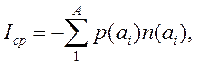 (1)
(1)
где:
A –размер (или объем) алфавита, используемого для передачи сообщения;
N(ai) –число двоичных разрядов в кодовой комбинации, соответствующей символуai.
От недостатка рассмотренного алгоритма свободна методика Д. Хаффмена. Она гарантирует однозначное построение кода с наименьшим для данного… Для двоичного кода алгоритм Хаффмана сводится к следующему: Шаг 1. Символы алфавита, составляющего сообщение, выписываются в основной столбец в порядке убывания вероятностей. Два…ПОРЯДОК ВЫПОЛНЕНИЯ РАБОТЫ
1. Оценка вероятностей появления символов в тексте; 2. Энтропия источника. 1. Построить код Шеннона-Фано для посимвольного кодирования заданного текста.СОДЕРЖАНИЕ ОТЧЕТА
3.1. Таблицы кодирование по алгоритмам Шеннона-Фано и Хаффмана.
3.2. Расчеты энтропии и среднего количества двоичных разрядов, необходимых для передачи текста при использовании эффективных кодов.
3.3. Результаты проверки возможности однозначного декодирования полученных кодов.
3.4. Выводы по работе.
Литература:
1. Савельев А.Я. Основы информатики: Учеб. Для вузов.- М.: Изд-во МГТУ им. Н.Э.Баумана, 2001.- 328 с.
2. Темников Ф.Е. и др. Теоретические основы информационной техники.- М.: Энергия, 1979.- 512 с.

|