Лекция 7.
1. Простые типы данных Ассемблера
Любая программа предназначена для обработки некоторой информации, поэтому вопрос о том, какие типы данных языка программирования доступны для использования и какие средства языка привлекаются для их описания, обычно встает одним из первых. Трансляторы TASM и MASM предоставляют широкий набор средств описания и обработки данных, который вполне сравним с аналогичными средствами большинства языков высокого уровня.
Понятие типа данных носит двойственный характер. С точки зрения размерности процессор аппаратно поддерживает следующие основные типы данных (рис. 5.17).
Байт – восемь последовательно расположенных битов, пронумерованных от 0 до 7, при этом бит 0 является самым младшим значащим битом.

Рис. 5.17. Основные типы данных процессора
Слово – последовательность из двух байтов, имеющих последовательные адреса. Размер слова – 16 битов; биты в слове нумеруются от 0 до 15. Байт, содержащий нулевой бит, называется младшим байтом, а байт, содержащий 15-й бит, – старшим. Процессоры Intel имеют важную особенность — младший байт всегда хранится по меньшему адресу. Адресом слова считается адрес его младшего байта. Адрес старшего байта может быть использован для доступа к старшей половине слова.
Двойное слово – последовательность из четырех байтов (32 бита), расположенных по последовательным адресам. Нумерация этих битов производится от 0 до 31. Слово, содержащее нулевой бит, называется младшим словом, а слово,содержащее 31-й бит, – старшим словом. Младшее слово хранится по меньшему адресу. Адресом двойного слова считается адрес его младшего слова. Адрес старшего слова может быть использован для доступа к старшей половине двойного слова.
Учетверенное слово – последовательность из восьми байтов (64 бита), расположенных по последовательным адресам. Нумерация битов производится от 0 до 63. Двойное слово, содержащее нулевой бит, называется младшим двойным словом, а двойное слово, содержащее 63-й бит, – старшим двойным словом. Младшее двойное слово хранится по меньшему адресу. Адресом учетверенного слова считается адрес его младшего двойного слова. Адрес старшего двойного слова может быть использован для доступа к старшей половине учетверенного слова.
128-битный упакованный тип данных. Этот тип данных появился в процессоре Pentium III. Для работы с ним в процессор введены специальные команды.
Кроме трактовки типов данных с точки зрения их разрядности, процессор на уровне команд поддерживает логическую интерпретацию этих типов, как показано на рис. 5.18 (Зн означает знаковый бит).

Рис. 5.18. Основные логические типы данных процессора
Целый тип со знаком – двоичное значение со знаком размером 8,16 или 32 бита. Знак в этом двоичном числе содержится в 7, 15 или 31 бите соответственно. Ноль в этих битах в операндах соответствует положительному числу, а единица – отрицательному. Отрицательные числа представляются в дополнительном коде.
Числовые диапазоны для этого типа данных следующие:
8-разрядное целое— от-128 до+127;
16-разрядное целое — от -32 768 до +32 767;
32-разрядное целое — от -231 до +231-1.
Целый тип без знака — двоичное значение без знака размером 8,16 или 32 бита.
Числовой диапазон для этого типа следующий:
байт — от 0 до 255;
слово — от 0 до 65 535;
двойное слово— от 0 до 232-1.
Указатель на память бывает двух типов:
ближний тип – 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента; указатели подобного типа могут также использоваться в сплошной (плоской) модели памяти, где сегментные составляющие одинаковы;
дальний тип – 48-разрядный логический адрес, состоящий из двух частей: 16-разрядной сегментной части (селектора) и 32-разрядного смещения.
Цепочка представляет собой некоторый непрерывный набор байтов, слов или двойных слов максимальной длиной до 4 Гбайт.
Битовое поле представляет собой непрерывную последовательность битов, в которой каждый бит является независимым и может рассматриваться как отдельная переменная. Битовое поле может начинаться с любого бита любого байта и содержать до 32 битов.
Неупакованный двоично-десятичный тип – байтовое представление десятичной цифры от 0 до 9. Неупакованные десятичные числа хранятся как байтовые значения без знака по одной цифре в каждом байте. Значение цифры определяется младшим полубайтом.
Упакованный двоично-десятичный тип представляет собой упакованное представление двух десятичных цифр от 0 до 9 в одном байте. Каждая цифра хранится в своем полубайте. Цифра в старшем полубайте (биты 4-7) является старшей.
Типы данных с плавающей точкой. Сопроцессор имеет несколько собственных типов данных, несовместимых с типами данных целочисленного устройства.
Типы данных MMX-расширения Pentium MMX/II/III/IV. Данный тип данных появился в процессоре Pentium MMX. Он представляет собой совокупность упакованных целочисленных элементов определенного размера.
Типы данных MMX-расширения Pentium III/IV. Этот тип данных появился в процессоре Pentium III. Он представляет собой совокупность упакованных элементов с плавающей точкой фиксированного размера.
2. Директивы описания данных простых типов
Описанные ранее данные можно определить как данные простого типа. Описать их можно с помощью специального вида директив — директив резервирования и инициализации данных. Эти директивы, по сути, являются указаниями транслятору на выделение определенного объема памяти. Если проводить аналогию с языками высокого уровня, то директивы резервирования и инициализации данных являются определениями переменных. Машинного эквивалента этим (впрочем, как и другим) директивам нет; просто транслятор, обрабатывая каждую такую директиву, выделяет необходимое количество байтов памяти и при необходимости инициализирует эту область некоторым значением. Формат директив резервирования и инициализации данных простых типов показан на рис. 5.19.
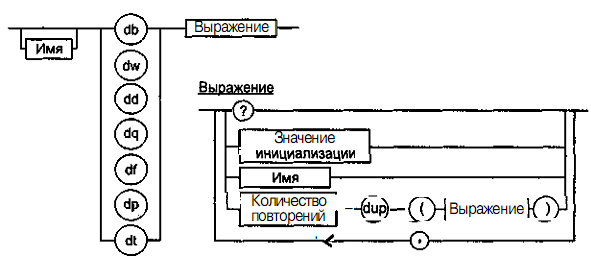
Рис. 5.19. Директивы описания данных простых типов
На рисунке использованы следующие обозначения.
Знак вопроса (?) показывает, что содержимое поля не определено, то есть при задании директивы с таким значением выражения содержимое выделенного участка физической памяти изменяться не будет. Фактически, создается неинициализированная переменная.
Значение инициализации — значение элемента данных, которое будет занесено в память после загрузки программы. Фактически, создается инициализированная переменная, в качестве которой могут выступать константы, строки символов, константные и адресные выражения в зависимости от типа данных.
Выражение — итеративная конструкция, о синтаксисе которой можно судить по рисунку. В частности, она позволяет повторить занесение в физическую память выражения в скобках столько раз, сколько повторений указано.
Имя — некоторое символическое имя метки или ячейки памяти в сегменте данных, используемое в программе.
Далее представлены поддерживаемые TASM и MASM директивы резервирования и инициализации данных, а также информация о возможных типах и диапазонах значений, которые можно описывать или задавать с их помощью.
DB — резервирование памяти для данных размером 1 байт. Директивой DB можно задавать следующие значения:
– выражение или константу, принимающую значение из диапазона -128...+127 (для чисел со знаком) или 0...255 (для чисел без знака);
– 8-разрядное относительное выражение, использующее операции HIGH и LOW;
– символьную строку из одного или более символов, которая заключается в кавычки (в этом случае определяется столько байтов, сколько символов в строке).
DW — резервирование памяти для данных размером два байта. Директивой DW можно задавать следующие значения:
– выражение или константу, принимающую значение из диапазона -32 768...32 767 (для чисел со знаком) или 0...65 535 (для чисел без знака);
– выражение, занимающее 16 или менее битов, в качестве которого может выступать смещение в 16-битовом сегменте или адрес сегмента;
– 1-или 2-байтовая строка, заключенная в кавычки.
DD — резервирование памяти для данных размером четыре байта. Директивой DD можно задавать следующие значения:
– выражение или константу, принимающую значение из диапазона -32 768...+32 767 (для чисел со знаком и процессора i8086), 0...65 535 (для чисел без знака и процессора 18086), -2 147 483 64S...+2 147 483 647 (для
– чисел со знаком и процессора 1386 и выше) или 0...4 294 967 295 (для чисел без знака и процессора 1386 и выше);
– относительное или адресное выражение, состоящее из 16-разрядного адреса сегмента и 16-разрядного смещения;
– строку длиной до 4 символов, заключенную в кавычки.
DF и DP — резервирование памяти для данных размером 6 байтов. Директивами DF и DP можно задавать следующие значения:
– выражение или константу, принимающую значение из диапазона -32 768...+32 767 (для чисел со знаком и процессора 18086), 0...65 535 (для чисел без знака и процессора 18086), -2 147 483 648...+2 147 483 647 (для чисел со знаком и процессора 1386 и выше) или 0...4 294 967 295 (для чисел без знака и процессора 1386 и выше);
– относительное или адресное выражение, состоящее из 32 или менее битов (для i80386) или 16 или менее битов (для первых моделей процессоров Intel);
– адресное выражение, состоящее из 16-разрядного сегмента и 32-разрядного смещения;
– константу со знаком из диапазона -247...247 - 1;
– константу без знака из диапазона 0...248 - 1;
– строку длиной до 6 байтов, заключенную в кавычки.
DQ — резервирование памяти для данных размером 8 байтов. Директивой DQ можно задавать следующие значения:
– выражение или константу, принимающую значение из диапазона
– -32 768...+32 767 (для чисел со знаком и процессора 18086), 0...65 535 (для чисел без знака и процессора 18086), -2 147 483 648...+2 147 483 647 (для чисел со знаком и процессора 1386 и выше) или 0...4 294 967 295 (для чисел без знака и процессора 1386 и выше);
– относительное или адресное выражение, состоящее из 32 или менее битов (для i80386) или 16 или менее битов (для первых моделей процессоров Intel);
– константу со знаком из диапазона -263...263- 1;
– константу без знака из диапазона 0...264 - 1;
– строку длиной до 8 байтов, заключенную в кавычки.
DT — резервирование памяти для данных размером 10 байтов. Директивой DТ можно задавать следующие значения:
– выражение или константу, принимающую значение из диапазона -32 768...+32 767 (для чисел со знаком и процессора i8086), 0...65 535 (для чисел без знака и процессора 18086), -2 147 483 648...+2 147 483 647 (для чисел со знаком и процессора 1386 и выше) или 0...4 294 967 295 (для чисел без знака и процессора 1386 и выше);
– относительное или адресное выражение, состоящее из 32 или менее битов (для i80386) или 16 или менее битов (для первых моделей);
– адресное выражение, состоящее из 16-разрядного сегмента и 32-разрядного смещения;
– константу со знаком из диапазона -279...279 - 1;
– константу без знака из диапазона 0...280 - 1;
– строку длиной до 10 байтов, заключенную в кавычки;
– упакованную десятичную константу в диапазоне 0...99 999 999 999 999 999 999.
Заметим, что все директивы позволяют задавать строковые значения, но нужно помнить, что в памяти эти значения могут выглядеть совсем не так, как они были описаны в директиве. Причиной этому является упоминавшийся ранее принцип «младший байт по младшему адресу». Для определения строк лучше использовать директиву DB. Задаваемые таким образом строки должны заключаться в кавычки. Эти кавычки могут быть одинарными (') или двойными (""). Если задать в строке подряд два таких ограничителя, то вторая кавычка (одинарная или двойная) будет частью строки.
Для иллюстрации принципа «младший байт по младшему адресу» рассмотрим листинг 5.3, в котором определим сегмент данных. В этом сегменте данных приведено несколько директив описания простых типов данных.