рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Информатика
- /
- Статические модели надежности
Реферат Курсовая Конспект
Статические модели надежности
Статические модели надежности - раздел Информатика, Т е м а 1: Основные понятия и определения Статические Модели Принципиально Отличаются От Динамических Прежде Всего Тем,...
Статические модели принципиально отличаются от динамических прежде всего тем, что в них не учитывается время появления ошибок в процессе тестирования и не используется никаких предположений о поведении функции риска  . Эти модели строятся на твердом статистическом фундаменте.
. Эти модели строятся на твердом статистическом фундаменте.
1) Модель Миллса. Использование этой модели предполагает необходимость перед началом тестирования искусственно вносить в программу (“засорять”) некоторое количество известных ошибок. Ошибки вносятся случайным образом и фиксируются в протоколе искусственных ошибок. Специалист, проводящий тестирование, не знает ни количества, ни характера внесенных ошибок до момента оценки показателей надежности по модели Миллса. Предполагается, что все ошибки (как естественные, так и искусственно внесенные) имеют равную вероятность быть найденными в процессе тестирования.
Тестируя программу в течение некоторого времени, собирается статистика об ошибках. В момент оценки надежности по протоколу искусственных ошибок все ошибки делятся на собственные и искусственные. Соотношение
N = 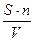 (21)
(21)
дает возможность оценить N – первоначальное число ошибок в программе. В данном соотношении, которое называется формулой Миллса,
S – количество искусственно внесенных ошибок;
n – число найденных собственных ошибок;
V – число обнаруженных к моменту оценки искусственных ошибок.
Например, в программу внесено 50 ошибок и к некоторому моменту тестирования обнаружено 25 собственных и 5 внесенных ошибок. В результате по формуле Миллса делается предположение, что первоначально в программе было 250 ошибок.
Вторая часть модели связана с проверкой гипотезы от N. Предположим, что в программе имеется К собственных ошибок, и внесем в нее еще S ошибок. В процессе тестирования были обнаружены все S внесенных ошибок. Тогда по формуле Миллса мы предполагаем, что первоначально в программе было N = n ошибок. Вероятность, с которой можно высказать такое предположение, возможно рассчитать последующему соотношению:

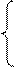 1, если n > K;
1, если n > K;
С =  , если n
, если n 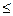 K. (22)
K. (22)
Например, если утверждается, что в программе нет ошибок (К = 0), и при внесении в программу 10 ошибок все они в процессе тестирования обнаружены, но при этом не выявлено ни одной собственной, С = 0,9. Т.е., с вероятностью 0,9 можно утверждать, что в программе нет ошибок. Но если в процессе тестирования была обнаружена одна собственная ошибка, то С = 1, т.к. n > K. А наше предположение о том, что в программе нет ошибок, на 100% не подтвердилось.
Т.о., величина С является мерой доверия к модели. Она показывает вероятность того, насколько правильно найдено значение N. Эти два связанных между собой по смыслу соотношения образуют полезную модель ошибок. Первое показывает возможное число первоначально имевшихся в программе ошибок, а второе используется для установления доверительного уровня прогноза. Однако формула (22) для расчета С не может быть использована в случае, когда не обнаружены все искусственно рассеянные ошибки. Для этого случая, когда оценка надежности производится до момента обнаружения всех S рассеянных ошибок, величина С рассчитывается по следующей модифицированной формуле:
 1, если n > К;
1, если n > К;
С =  /
/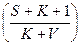 , если n К. (23)
, если n К. (23)
Здесь числитель и знаменатель формулы при n К являются биноминальными коэффициентами вида
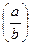 =
= 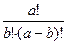 .
.
Например, если утверждается, что в программе нет ошибок, а к моменту оценки надежности обнаружено 5 из 10 рассеянных ошибок и не обнаружено ни одной собственной ошибки, то вероятность того, что в программе действительно нет ошибок, будет равна:
С =  /
/ =
= 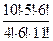 =
=  ≈ 0,45. (24)
≈ 0,45. (24)
Если же при тех же исходных условиях оценка надежности производится в момент, когда обнаружены 8 из 10 искусственных ошибок, то вероятность того, что в программе не было ошибок, увеличивается до 0,73. В действительности модель Миллса можно использовать для оценки N после каждой найденной ошибки. Предлагается во время всего периода тестирования отмечать на графике число найденных ошибок и текущие значения для N. Достоинством модели являются простота применяемого математического аппарата, наглядность и возможность использования в процессе тестирования.
Однако она не лишена и ряда недостатков. Самые существенные из них: 1) Необходимость внесения искусственных ошибок. Этот процесс плохо формализуем. 2) Достаточно вольное допущение величины К, которое основывается исключительно на интуиции и опыте человека, производящего оценку, т.е. допускается большое влияние субъективного фактора.
2) Модель Липова.Липов модифицировал модель Миллса, рассмотрев вероятность обнаружения ошибки при использовании различного числа тестов. Если сделать то же предположение, что и в модели Миллса, т.е. что собственные и искусственные ошибки имеют равную вероятность быть найденными, то вероятность обнаружения n собственных и V внесенных ошибок равна:
Q(n,V) = 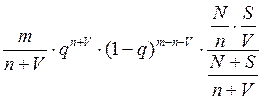 ,
,
где m – количество тестов, используемых при тестировании;
q – вероятность обнаружения ошибки в каждом из m тестов, рассчитанная по формуле
q = 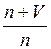 ;
;
S – общее количество искусственно внесенных ошибок;
N – количество собственных ошибок, имеющихся в ПС до начала тестирования.
Для использования модели Липова должны выполняться следующие условия:
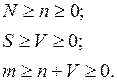
Оценки максимального правдоподобия (наиболее вероятное значение) для N задаются соотношениями:
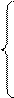
 при n ≥ 1, V ≥ 1;
при n ≥ 1, V ≥ 1;
N = n∙S при V = 0;
0 при n = 0.
Модель Липова дополняет модель Миллса, давая возможность оценить вероятность обнаружения определенного количества ошибок к моменту оценки.
3) Простая интуитивная модель. Использование этой модели предполагает проведение тестирования двумя группами программистов или двумя программистами в зависимости от величины программы независимо друг от друга. Они должны использовать независимые тесовые наборы. В процессе тестирования каждая из групп фиксирует все найденные ею ошибки. При оценке числа оставшихся в программе ошибок результаты тестирования обеих групп собираются и сравниваются.
Получается, что 1-я группа обнаружила N ошибок, 2-я – N
ошибок, 2-я – N , а N
, а N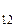 – это ошибки, обнаруженные обеими группами.
– это ошибки, обнаруженные обеими группами.
Если обозначить через N неизвестное количество ошибок, присутствовавших в программе до начала тестирования, то можно эффективность тестирования каждой из групп определить как
Е=  ; Е=
; Е= 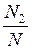 . (25)
. (25)
Предположим, что возможность всех ошибок одинаковая для обеих групп. Теперь можно допустить, что, если первая группа обнаружила определенное количество всех ошибок, она могла бы определить то же количество любого случайным образом выбранного подмножества. В частности, можно допустить, что
Е= =  . (26)
. (26)
Из формулы (25) N= Е∙N, подставив в (26), получим:
Е= 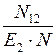
или
N = 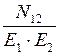 =
=  .
.
Значение Nизвестно, а Еи Еможно определить как N/ Nи N/ N. Развивая эту модель и опираясь на предположение, что обе группы, проводящие тестирование, имеют равную вероятность обнаружения “общих” ошибок, ее можно рассчитать по следующей формуле:
Р(N) =  , (27)
, (27)
где Р(N) – вероятность обнаружения N“общих” ошибок тестирования программы двумя независимыми группами.
4) Модель Коркорэна. Модель Коркорэна относится к статистическим моделям надежности ПС, т.к. в ней не используются параметры времени тестирования и учитывается только результат N испытаний, в которых выявлено Nошибок i-го типа. Модель использует изменяющиеся вероятности отказов для различных типов ошибок.
В двух рассмотренных выше статистических моделях оценивалось количество первоначальных ошибок в программе, а также их количество, оставшееся после некоторого периода тестирования. В отличие от них по модели Коркорэна оценивается вероятность безотказного выполнения программы на момент оценки:
R = 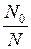 +
+ 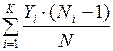 ,
,
где N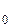 – число безотказных выполнений программы;
– число безотказных выполнений программы;
N – общее число прогонов;
К – априори известное число типов;
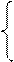 a
a , если N> 0;
, если N> 0;
Y= 0, если N= 0;
а– вероятность выявления при тестировании ошибки i-го типа.
В этой модели вероятность адолжна оцениваться на основании априорной информации или данных предшествующего периода функционирования однотипных ПС. Наиболее часто встречающиеся ошибки и вероятности их выявлений при тестировании ПС прикладного назначения приводятся в табл. 4.3.
Таблица 4.3
ОШИБКИ ПРОГРАММЫ ПО КАТЕГОРИЯМ И ВЕРОЯТНОСТИ ИХ ПОЯВЛЕНИЯ (ПРИМЕР)
| № п/п | Тип ошибки | Вероятность появления ошибки |
| Ошибки вычислений Логические ошибки Ошибки ввода-вывода Ошибки манипулирования данными Ошибки сопряжения Ошибки определения данных Ошибки в БД | 0,09 0,26 0,16 0,18 0,17 0,08 0,06 |
4) Модель Нельсона. Данная модель создана в фирме TRW (аэрокосмическая компания США). При расчете надежности ПС учитывается вероятность выбора определенного тестового набора для очередного выполнения программы.
Предполагается, что область данных, необходимых для выполнения тестирования ПС, разделяется на К взаимоисключающих подобластей Z , i = 1,2,…,k. Пусть Р– вероятность того, что набор данных Zбудет выбран для очередного выполнения программы. Предполагаем, что к моменту оценки надежности было выполнено Nпрогонов программы на Zнаборе данных. Из них nколичество прогонов закончилось отказом. Надежность ПС в этом случае равна:
, i = 1,2,…,k. Пусть Р– вероятность того, что набор данных Zбудет выбран для очередного выполнения программы. Предполагаем, что к моменту оценки надежности было выполнено Nпрогонов программы на Zнаборе данных. Из них nколичество прогонов закончилось отказом. Надежность ПС в этом случае равна:
R = 1 – 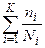 ∙Р. (28)
∙Р. (28)
На практике вероятность выбора очередного набора данных для прогона (Р) определяется путем разбиения всего множества значений входных данных на подмножества и нахождения вероятностей того, что выбранный для очередного прогона набор данных будет принадлежать конкретному подмножеству. Определение этих вероятностей основано на эмпирической оценке вероятности появления тех или иных входов в реальных условиях функционирования.
– Конец работы –
Эта тема принадлежит разделу:
Т е м а 1: Основные понятия и определения
Организация и планирование производства... программного обеспечения... Т е м а Основные понятия и определения Системное и...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Статические модели надежности
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.022 сек.
Новости и инфо для студентов