Алгоритмы обработки символьной информации
Символьная информация — это информация, отображаемая с помощью символов (букв, цифр, знаков операций и др.). IBM-совместимые компьютеры обрабатывают 256 различных символов, каждый из которых кодируется одним байтом. Соответствие символов и байтов задается таблицей кодировки, в которой для каждого символа указывается соответствующий байт.
Символы с кодами от 0 до 127 построены по стандарту ASCII(American Standard Code for Information Interchange — Американский стандартный код обмена информацией, читается "аски"). Вторая половина таблицы (коды 128 ... 255) в нашей стране содержит русские буквы (кириллицу) и символы псевдографики. Для того, чтобы определить по этим таблицам код того или иного символа, нужно сложить номер строки с номером столбца, в которых он расположен. Так, код цифры 5 равен 05+048 = 053.
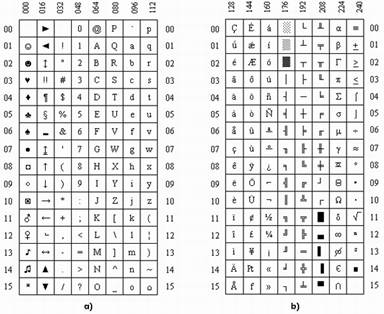
Рисунок 1 - Стандартная кодировка фирмы IBM: а) для кодов 0...127; b) для кодов 128...255
Стандартный отечественный знакогенератор строится по рекомендациям Международного консультационного комитета по телеграфии и телефонии (МККТТ). Расположение символов во второй половине таблицы этого знакогенератора (рис.2,а) резко отличается от принятого фирмой IBM, что затрудняет использование зарубежного программного обеспечения на отечественных ПК. В связи с этим, стандартный (так называемый ГОСТовский) вариант кодировки часто заменяется альтернативным (рис.2,b), главное достоинство которого - расположение символов псевдографики на тех же местах, что и в знакогенераторе IBM. Недостаток такого знакогенератора заключается в том, что символы кириллицы не образуют непрерывный массив. Вариант, показанный на рис. 2,b в настоящее время получил наибольшее распространение на отечественных ПК. Именно на него рассчитаны практически все программы отечественного производства. Он стал фактическим стандартом для зарубежных фирм, изготовляющих ПК для экспорта в нашу страну.

Рисунок 2 - Варианты кодировки для кодов 128...255: а) по рекомендациям МККТТ; b) наиболее популярный
Символьная информация в алгоритмах и программах описывается данными двух типов: символьным и литерным. Они отличаются друг от друга тем, что значением символьной переменной является один символ, а литерной — строка символов.
Строка - это последовательность символов кодовой таблицы персональной ЭВМ. При использовании в выражениях строка-константа заключается в апострофы. Длина строки равняется количеству символов в этой строке и может изменяться от 0 до 255.
Для определения данных строкового типа используется идентификатор string, за которым следует заключенное в квадратные скобки значение максимально допустимой длины строки данного типа. Если это значение не указывается, то по умолчанию длина строки равна 255 байт. Переменную строкового типа можно задать через описание типа в разделе определения типов или непосредственно в разделе описания переменных.
Форма описания строковых данных:
Type имя типа=String [максимальная длина строки];
Var имя строковой переменной : имя типа;
или
Var имя строковой переменной : String [максимальная длина строки];
Пример: Type str=String[30];
Var C1,C2:str;
или
Var C3,C4:String[25];
Объем памяти в байтах, требуемый для размещения строки, равен ее максимальной длине плюс 1 байт, в котором запоминается длина данной строки. Допустимо использование типизированных констант строкового типа, например:
Const S1 : String[4]=’ТБП’;
S2 : String[4]=#107#116#102#44; {ktf.}
S3 : String[10]=’Да‘;
Знак #означает, что символ представляется его ASCII кодом.
Как и в массивах, к отдельным символам строки можно обратиться с помощью индексов в квадратных скобках: S1[2], S2[3]. При этом символ с нулевым индексом S1[0] содержит код, равный числу символов в строке S1.
Выражения, в которых операндами служат строковые данные, называются строковыми. Они состоят из строковых констант, переменных, строковых функций и знаков операций. Над строковыми данными допустимы операции присваивания, сцепления и отношения.