рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Математика
- /
- Краткая теория УИРС
Реферат Курсовая Конспект
Краткая теория УИРС
Краткая теория УИРС - раздел Математика, Изучение вероятностных алгоритмов диагностики Информационный Или Диагностический Вес J Симптома...
Информационный или диагностический вес J симптома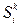 при диагнозе равен двоичному логарифму отношения следующих вероятностей:
при диагнозе равен двоичному логарифму отношения следующих вероятностей:
J(/dj)=log2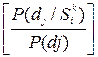 (9)
(9)
J( /dj) показывает, насколько значим (специфичен), симптом
/dj) показывает, насколько значим (специфичен), симптом 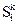 при заболевании dj ,т.е. насколько наличие у пациента этого симптома увеличивает вероятность диагноза dj по сравнению с другими, возможными в этом kj-ом заболевании.
при заболевании dj ,т.е. насколько наличие у пациента этого симптома увеличивает вероятность диагноза dj по сравнению с другими, возможными в этом kj-ом заболевании.
Сравнение информационных весов различных симптомов при одном и том заболевании позволяет отобрать наиболее характерные, значимые симптомы для этого заболевания, чтобы потом использовать их для диагностики.
Можно подсчитать J(/dj) и по другой формуле. Из формулы (5) следует, что:
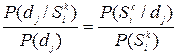 откуда
откуда
J(/dj)=log2 (10)
(10)
Из (10) следует, что информационный вес симптома при заболевании dj также показывает, насколько чаще встречается этот симптом при заболевании dj по сравнению с частотой его появления в среднем по всей группе заболеваний.
Измеряется J(/dj) в битах (I бит =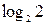 ). Обычно малой степенью информативности симптома считают величины до 0,3 бит, средней - от 0,3 до 0,6 бит, большой - свыше 0,6 бит.
). Обычно малой степенью информативности симптома считают величины до 0,3 бит, средней - от 0,3 до 0,6 бит, большой - свыше 0,6 бит.
Имеются диагностические алгоритмы, в которых складываются информационные веса (или величины, им пропорциональные) симптомов, обнаруженных у больного, по отдельности для каждого из заболеваний dj. Если сумма информативности для какого-то заболевания превысит некоторое пороговое значение  (свое для каждого диагноза), то этот диагноз считается более вероятным. Если суммы информативности превысит пороговые не по одному, а по двум и более диагнозам, то следует думать или о сочетании этих заболеваний, или, если сочетание невозможно, о проведении дополнительных исследований для уточнения диагноза. Если же ни для одного диагноза сумма информативности не превзойдет пороговое значение, то диагноз остается неопределенным и необходимо провести еще добавочные исследования.
(свое для каждого диагноза), то этот диагноз считается более вероятным. Если суммы информативности превысит пороговые не по одному, а по двум и более диагнозам, то следует думать или о сочетании этих заболеваний, или, если сочетание невозможно, о проведении дополнительных исследований для уточнения диагноза. Если же ни для одного диагноза сумма информативности не превзойдет пороговое значение, то диагноз остается неопределенным и необходимо провести еще добавочные исследования.
Пороговые суммы определяются эмпирически подсчетом суммы информативности для каждого заболевания (по уже имеющимся в клиническом архиве историям болезни) и выбора оптимальных пороговых, максимально исключающих возможные диагностические ошибки. Заметим, что на основе этого диагностического алгоритма возможно создание самообучающейся диагностической системы, т.к. по мере накопления практического опыта работы с таким алгоритмом, как значения информативности симптомов и значения пороговых сумм уточняются. Эта способность к самообучению, к самосовершенствованию присуща вообще вероятностным диагностическим алгоритмам (действительно, ведь приближение равенства P(A)= nA/N становится тем точнее, чем больше N - число используемых при составлении алгоритма правильно поставленных диагнозов).
Вычисления при применении этого алгоритма несложны, могут проводиться даже вручную - упрощается постановка и повышается достоверность диагноза.
– Конец работы –
Эта тема принадлежит разделу:
Изучение вероятностных алгоритмов диагностики
На сайте allrefs.net читайте: "Изучение вероятностных алгоритмов диагностики"
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Краткая теория УИРС
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.025 сек.
Новости и инфо для студентов