Проверка гипотезы о правильности выбора вида тренда
При правильном выборе вида тренда отклонения от него будут носить случайный характер. Это означает, что изменение остатков (случайной составляющей) et=yt-yt (t=1,2,…n) не связаны с изменением времени.
Переведенные ниже критерии являются непараметрическими и не зависят от вида распределения исследуемой величины.
 Критерий серий, основанный на медиане выборки.
Критерий серий, основанный на медиане выборки.
Пусть найдены отклонения от тренда e1, e2, … en. Они располагаются в порядке возрастания их значений (ранжируются) и находится emed – медиана вариационного ряда (величина варьирующего признака, делящая совокупность на две равные части – со значениями признака меньше и больше медианы). Образовывается последовательность из «+» и «-» по следующему правилу. На i-м месте (i=1,2…n) ставится знак «+», если i-е наблюдение в исходном ряду превосходит медиану, и знак «-», если оно меньше медианы. Когда i-е наблюдение равно emed , оно опускается. Таким образом получается последовательность, состоящая из «+» и «-» общее число которых не превышает n. Последовательность подряд идущих плюсов и минусов называется серией.
Подсчитаем протяженность самой длинной серии Kmax и общее число серий v. Для того чтобы исходный ряд подставлял случайную выборку, протяженность самой длинной серии не должна быть слишком большой, а общее число серий – слишком маленьким. Выборка признается случайной, если выполняются следующие неравенства для 5%-ного уровня значимости:

где квадратные скобки означают целую часть числа.
Если хотя бы одно из неравенств нарушается, то гипотеза о случайном характере отклонений уровней временного ряда от тренда отвергается и, следовательно, трендовая модель признается неадекватной.
Критерий пиков (поворотных точек) [Федосеев] (в литературе также встречаются следующие названия теста – критерий «восходящих» и «нисходящих» серий [Френкель], критерий «пиков» и «ям» [Шмойлова].
Вначале образуют последовательность из «+» и «-» по правилу: на i-м месте в ряду e1, e2, … en ставится знак
«+» если ei+1 - ei >0
«-» если ei+1 - ei < 0
В случае, когда последующее наблюдение окажется равным предыдущему, учитывается только одно наблюдение.
Далее подсчитывается протяженность самой длинной серии Kmax и общее число серий v.
Для того чтобы отклонения от тренда были случайными, протяженность самой длинной серии не должно быть слишком большой, а общее число серий – слишком маленькой. Гипотеза о случайности выборки подтверждается в том случае, если выполняется следующее условие для 5%-ного уровня значимости:
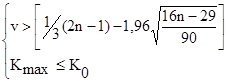
К0 – число подряд идущих плюсов и минусов в самой длинной серии.
Величина К0 определяется следующим образом:
| При n£26 | K0=5 |
| При 26<n£153 | K0=6 |
| При 153<n£170 | K0=7 |
Если хотя бы одно из неравенств нарушается, то гипотеза о случайном характере отклонений уровней временного ряда от тренда отвергается и трендовая модель считается неадекватной.
Во всех методах вместо фактических уровней при обработке ряда рассчитываются иные (расчетные) уровни, в которых тем или иным способом взаимопогашается действие случайных факторов и тем самым уменьшается колеблемость уровней.

Укрупнение интервалов является простейшим метод выявления долговременной тенденции, суть его заключается в определении суммы или средней величины внутри выбранного интервала времени.
| y1 | y2 | y3 | y4 | y5 | y6 | y7 | y8 | … | yn-2 | yn-1 | yn |
| Sy`1 | Sy`2 | … | Sy`n |
Этот метод особенно эффективен, если первоначальные уровни ряда относятся к коротким промежуткам времени.
Метод скользящих среднихзаключается втом, что первой начальные уровни временного ряда заменяются средней арифметической величиной внутри выбранного интервала времени. Полученное значение относится к середине выбранного периода. Затем период сдвигается на одно наблюдение и расчет средней повторяется, причем периоды определения средней берутся все время одинаковыми.
| y1 | y2 | y3 | y4 | y5 | y6 | y7 | y8 | … | yn-2 | yn-1 | yn |
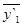
| … | ||||||||||

| … | ||||||||||
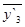
| … | ||||||||||
| … | … | … | … | … | … | … | … | … | … | … | … |
| … | 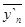
|
Таким образом, в каждом случае средняя центрирована, т.е. отнесена к серединной точке интервала сглаживания и представляет собой уровень для этой точкой.
Более совершенный метод обработки рядов динамики в целях устранения случайных колебаний и выявления тренда — выравнивание уровней ряда по аналитическим формулам (или аналитическое выравнивание). Суть аналитического выравнивания заключается в замене эмпирических (фактических) уровней yt теоретическими 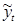 которые рассчитаны по определенному уравнению, принятому за математическую модель тренда, где теоретические уровни рассматриваются как функция времени.
которые рассчитаны по определенному уравнению, принятому за математическую модель тренда, где теоретические уровни рассматриваются как функция времени.
Задача аналитического выравнивания сводится к следующему:
1. определение на основе фактических данных вида (формы) гипотетической функции, способной наиболее адекватно отразить тенденцию развития исследуемого показателя;
2. нахождение по эмпирическим данным параметров указанной функции (уравнения);
3. расчет по найденному уравнению теоретических (выровненных) уровней и оценка их качества (на основании t и F критерия и значения R2).
4. Прогнозирование неизвестных значений исследуемого показателя на основе разработанной модели и построение доверительных границ.
В аналитическом выравнивании наиболее часто используются следующие простейшие функции:
| Функция | Формула | Рекомендации |
| Линейная | 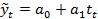
| используется в том случае, если первые разности уровней (абсолютные приросты) более или менее постоянны |
| Парабола второго порядка | 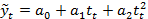
| используется в том случае, если вторые разности уровней (ускорения) более или менее постоянны |
| Показательная | 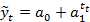
| используется в том случае, если цепные коэффициенты роста примерно постоянны |
| Гипербола | 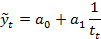
| используется в том случае, если обнаружено замедленное снижение (рост) уровней ряда, которые по логике не могут снизиться до нуля (превысить какое-либо значение) |
Рассмотрим алгоритм нахождения параметров тренда на примере линейной функции.
Для нахождения параметров линейного тренда (также как и в случае пространственных данных) используется МНК и решить систему нормальных уравнений:
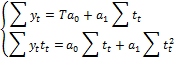
Для нахождения a0, a1 и а2 парабола второго порядка, соответственно необходимо решить систему:

В практике экономических исследований моменты времени t можно расставлять двояко:
1. от начала ряда (метод используется при машинном счете) - t1
2. от центра (середины) ряда (метод используется при ручном счете) - t2
Для иллюстрации рассмотрим виртуальный пример: допустим, имеются 5 значений показателя (2002-2006гг.):
| Годы | yt | t1 | t2 |
| y1 | -2 | ||
| y2 | -1 | ||
| y3 | |||
| y4 | |||
| y5 |
Во втором случае Stt = 0 и из предложенных систем уравнений можно выразить следующие отношения:
| Моменты (периоды) времени расстановлены от середины ряда | Моменты (периоды) времени расстановлены от начала ряда |
| Для линейного тренда: | Для линейного тренда: |
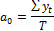
| 
|

| 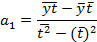
|
| Для параболы второго порядка: | Для параболы второго порядка: |
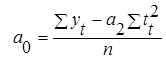
| а0 = Dа0 / D |
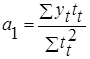
| а1 = Dа1 / D |

| а2 = Dа2 / D |
На заключительном этапе построения тренда (в случае его адекватности) проводят прогнозирование неизвестных значений, для этого подставляют в оцененное уравнение регрессии номера прогнозных периодов (моментов времени).
Относительно нашего абстрактного примера для нахождения значения показателя в 2007г. необходимо подставить в уравнение значение 6:
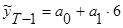
Полученное значение 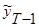 называется точечным прогнозом.
называется точечным прогнозом.
В силу того, что любая модель является всего лишь приближением действительности, а также в силу того, что при расчете точечного прогноза не учитывается колеблемость признака. Такой прогноз необходимо дополнять доверительными границами.
Неопределенность прогноза уровня отдельного периода складывается из двух элементов. Ошибки линии тренда для прогнозируемого периода и колебаний уровня около тренда.
Колеблемость отдельных уровней относительно линии тренда измеряется среднеквадратическим отклонением S(t).
В расчет ошибки прогноза следует взять ожидаемое значение показателя колеблемости S(t) на прогнозируемый период.
Рекомендуется использовать точечный прогноз силы колебаний если его тренд надежно установлен. Средняя ошибка прогноза конкретного уровня по правилу сложения независимых дисперсии имеет вид [1]:
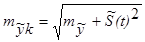
|
Для линейного тренда формула имеет вид:
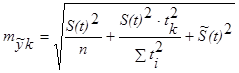
|
В первых двух слагаемых величина S(t) рассчитывается по анализируемому ряду, а третья величина S(t) это прогнозируемое ее значение. Если же на период прогноза принята та же величина показателя колеблемости как и за период – базу расчета тренда то величину S(t) вынести из под корня.
На основе средней ошибки тренда вычислим доверительную ошибку по формуле:
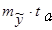
где ta – определяется по таблицам t - распределения Стьюдента с вероятностью 0,05 или 0,01 и степенями свободы n-p.
Затем вычисляются доверительные границы прогноза:
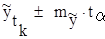
|