План лекции
6.1. Основные понятия математической статистики
6.2. Точечные оценки параметров
6.3. Примеры некоторых распределений
6.1. Основные понятия математической статистики
Математическая статистика – это раздел математики, посвящённый анализу статистических данных самой разнообразной природы. Есть определённая связь математической статистики с теорией вероятностей, которая не случайно изучается раньше. В теории вероятностей имеют дело с вероятностями случайных событий, а также со случайными величинами и их характеристиками. При этом предполагается, что интересующие нас вероятности либо известны, либо их можно рассчитать. Но в практических задачах положение иное. Во время проведения опытов фиксируются конкретные значения случайной величины, по которым затем нужно определить её числовые характеристики и закон распределения вероятностей. Особенностью задачи в подавляющем числе случаев является невозможность обследовать все объекты наблюдения, а значит, имея в наличие только ограниченное количество измерений, нам необходимо сделать вывод о поведении всей совокупности объектов.
Всё множество исследуемых объектов называется генеральной совокупностью. Число объектов называется объёмом генеральной совокупности. Объём генеральной совокупности является конечным в отличие от теоретических рассмотрений, где он предполагается бесконечным.
Множество случайным образом отобранных объектов исследования называется выборочной совокупностью или выборкой, а число объектов в выборке – её объёмом. Произведённая выборка должна достаточно полно отражать свойства всех объектов генеральной совокупности. Особенно это важно, когда генеральная совокупность имеет некоторую неоднородность объектов. Такое требование к выборке формулируется так: выборка должна быть репрезентативной (представительной). Репрезентативность выборки обеспечивается случайностью отбора при одинаковой вероятности любого объекта попасть в выборку.
Проиллюстрируем это понятие на примере. Допустим, что население города составляет 100 000 человек, среди которых 60% - бедняки, 30% - средний класс, а остальные - богачи. Требуется оценить среднегодовой доход на душу населения. Поскольку нет ни финансовых, ни физических возможностей опросить всех жителей города, то решили сделать выборку из 1000 человек, и по результатам опроса оценить среднегодовой доход. Чтобы выборка была репрезентативной, следует случайным образом выбрать для опроса приблизительно 600 бедняков, 300 человек со средним достатком и 100 богачей. Только в этом случае среднее арифметическое их годовых доходов будет хорошей оценкой среднегодового дохода жителей этого города.
Теперь перейдем к формальной стороне математической статистики, которая, как уже говорилось, определяется как раздел математики, посвящённый математическим методам систематизации, обработки и использования статистических данных для научных и практических выводов вне зависимости от природы изучаемых объектов.
Пусть имеется генеральная совокупность случайной величины Х (в приведённом выше примере - индивидуальные доходы 100 000 горожан), функция распределения F(x) которой нам неизвестна, либо известна с точностью до нескольких параметров. Тогда выборкой объёма n будет являться случайный n - мерный вектор, имеющий “координаты” {х1, х2, ... , хn} (в примере – доходы случайным образом отобранных n горожан). Ставится задача: по имеющейся выборке оценить основные числовые характеристики случайной величины Х (математическое ожидание, дисперсию) или сделать вывод о виде функции распределения.
Поскольку выборка случайна, то координаты n - мерного вектора хi неупорядочены, т.е., во-первых, среди них могут встретиться одинаковые величины (равные доходы), а во-вторых, может выполняться любое из неравенств: хi+1 > > xi или хi+1 < xi. Для удобства работы с выборкой значения xi переставляют так, чтобы выполнялись нестрогие неравенства: х1 £ х2 £ х3 £ ... £ хn. Такая перестановка не приведет ни к потере информации, ни к её приобретению (просто опрос тех же горожан проводился бы в ином порядке).
Некоторые значения в выборке могут совпадать. Допустим, всего имеется k (1 £ k £ n) разных и расположенных в порядке возрастания значений 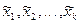 ; их называют вариантами, а такую последовательность чисел – вариационным рядом. Разность
; их называют вариантами, а такую последовательность чисел – вариационным рядом. Разность  -
- между наибольшим и наименьшим значениями выборки называют размахом выборки. Допустим, значение
между наибольшим и наименьшим значениями выборки называют размахом выборки. Допустим, значение  повторяется ni раз (1 £ i £ k) при соблюдении равенства
повторяется ni раз (1 £ i £ k) при соблюдении равенства  . Величину ni называют частотой варианты , а отношение ni / n относительной частотой Wi. Легко убедиться, что сумма относительных частот равна единице:
. Величину ni называют частотой варианты , а отношение ni / n относительной частотой Wi. Легко убедиться, что сумма относительных частот равна единице:  .
.
Данные вариационного ряда заносим в таблицу, верхнюю строку которой заполним вариантами , 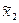 ,..., , а нижнюю - соответствующими относительными частотами
,..., , а нижнюю - соответствующими относительными частотами  . Такая таблица называется таблицей статистического распределения выборки или просто статистической таблицей. Статистическая таблица в случае отсутствия повторяющихся значений в вариационном ряду имеет вид табл. 6.1, а для выборки с повторяющимися значениями - табл. 6.2.
. Такая таблица называется таблицей статистического распределения выборки или просто статистической таблицей. Статистическая таблица в случае отсутствия повторяющихся значений в вариационном ряду имеет вид табл. 6.1, а для выборки с повторяющимися значениями - табл. 6.2.
|
| 
| 
| 
| … | 
| 
|
| Wi | 1/n | 1/n | 1/n | … | 1/n | 1/n |
Табл. 6.1
|
|
|
| … |
|
| Wi | 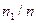
| 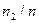
| … | 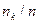
|
Табл.6.2
Заметим, что таблицу статистического распределения выборки можно считать таблицей распределения некоторой гипотетической случайной дискретной величины, принимающей значения ,,...,с вероятностями . В силу этой аналогии можно по тем же формулам, которые использовались для дискретного распределения в теории вероятностей, по известному эмпирическому распределению найти выборочные аналоги математического ожидания, дисперсии и эмпирической функции распределения.
Если объём выборки из генеральной совокупности некоторой случайной непрерывной величины велик, то прибегают к предварительной группировке данных: интервал значений этой величины разбивают на k интервалов (при этом их длины не обязательно должны быть одинаковы). При выборе количества интервалов руководствуются формулой k = log2 n + 1 . Подсчитывают, сколько значений n1 , n2 , ... , nk попало в каждый из k интервалов (n1 + n2 + ... + nk = = n). Вариантами для группированной выборки считают середины этих интервалов ,,...,. Эти данные заносят в статистическую таблицу распределения выборки (табл. 6.2).
Для наглядного представления статистического распределения пользуются графическими изображениями вариационных рядов: полигоном (для случайной дискретной величины) и гистограммой (для непрерывной). Полигон получают, соединяя отрезками прямых точки с координатами (,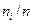 ), i = 1,..., k. Он является аналогом многоугольника распределения случайной дискретной величины в теории вероятностей. Гистограмма - это ряд прямоугольников, основаниями которых являются отрезки длиной -
), i = 1,..., k. Он является аналогом многоугольника распределения случайной дискретной величины в теории вероятностей. Гистограмма - это ряд прямоугольников, основаниями которых являются отрезки длиной -  , а их высоты равны
, а их высоты равны 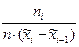 . При таком выборе сторон прямоугольников достигается равенство единице площади всей этой ступенчатой фигуры. Гистограмма является аналогом плотности вероятностей случайной непрерывной величины. Примеры полигона и гистограммы приведены соответственно на рис. 5.1 и 5.2 .
. При таком выборе сторон прямоугольников достигается равенство единице площади всей этой ступенчатой фигуры. Гистограмма является аналогом плотности вероятностей случайной непрерывной величины. Примеры полигона и гистограммы приведены соответственно на рис. 5.1 и 5.2 .
 Wi
Wi
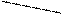




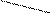

 x1 x2 x3 x4 х5 x6 x7 x
x1 x2 x3 x4 х5 x6 x7 x
Рис. 6.1


 Wi
Wi
 |

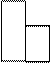 | |||
 | |||


 х
х
Рис. 6.2
Рассматривая эти графики, можно высказать предположение, что в первом случае случайная величина имеет равномерное распределение, а во втором - нормальное. Оценка правомерности этих гипотез составляет отдельную главу математической статистики.
П р и м е р № 1. На приёмных экзаменах случайная выборка среди абитуриентов дала следующие набранные ими баллы: 12. 11, 12, 10, 10, 9, 14, 12, 13, 10, 11, 11, 15, 9, 12, 12, 11, 9, 9, 10, 11, 11, 14, 13, 9, 11, 12, 9, 11, 13. Построить для данной выборки вариационный ряд, полигон и эмпирическую функцию распределения, найти моду и медиану.
Р е ш е н и е . Расположим данные выборки в порядке их возрастания, или другими словами, составим вариационный ряд: 9, 9, 9, 9, 9, 9, 10, 10, 10, 10, 11, 11, 11, 11, 11, 11, 11, 11, 12, 12, 12, 12, 12, 12, 1, 13, 13, 14, 14, 15. Числа  являются вариантами с числом повторений соответственно n1 = 6, n2 = 4, n3 = 8, n4 = 6, n5 = 3, n6 = 2, n7 = 1. Объём выборки равен n =
являются вариантами с числом повторений соответственно n1 = 6, n2 = 4, n3 = 8, n4 = 6, n5 = 3, n6 = 2, n7 = 1. Объём выборки равен n =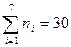 . Данные занесём в статистическую таблицу распределения выборки (табл. 6.3).
. Данные занесём в статистическую таблицу распределения выборки (табл. 6.3).
|
| |||||||
| Wi | 6/30 | 4/30 | 8/30 | 6/30 | 3/30 | 2/30 | 1/30 |