рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Математика
- /
- Существенно нелинейные регрессионные модели
Реферат Курсовая Конспект
Существенно нелинейные регрессионные модели
Существенно нелинейные регрессионные модели - раздел Математика, Доклады по дисциплине Дополнительные главы математической статистики . Регрессионный анализ. 4 Для Некоторых Регрессионных Моделей, Которые Не Могут Быть Сведены К Линейным...
Для некоторых регрессионных моделей, которые не могут быть сведены к линейным, единственным способом для исследования остается Нелинейное оценивание. В приведенном выше примере для скорости роста, мы специально “забыли ” о случайной ошибке в зависимой переменной. Конечно, на скорость роста влияют множество других факторов (кроме возраста), и нам следует ожидать значительных случайных отклонений (остатков) от предложенной нами кривой. Если добавить эту ошибку или остаточную изменчивость, нашу модель можно переписать следующим образом:
Рост = exp(-b1*Возраст) + ошибка
Аддитивная ошибка. В этой модели предполагается, что случайная ошибка не зависит от возраста, т.е., остаточная изменчивость одинакова для всех возрастов. Поскольку ошибка в этой модели аддитивна, т.е. просто прибавляется к точному значению скорости роста, мы больше не можем линеаризовать эту модель простым логарифмированием обеих частей. Если бы мы снова прологарифмировали входные данные о скорости роста и подобрали простую линейную модель, мы заметили бы, что остатки больше не являются равномерно распределенными вокруг значений переменной возраст; и поэтому, стандартный линейный регрессионный анализ больше не применим. Единственным способом оценивания параметров модели остается использование Нелинейного оценивания.
Мультипликативная ошибка. В “оправдание” предыдущего примера заметим, что в данном случае постоянство вариации случайной ошибки в любом возрасте мало вероятно, т.е., предположение об аддитивности ошибки не слишком реалистично. Правдоподобнее, что изменения скорости роста более случайны и непредсказуемы в раннем возрасте, чем в позднем, когда рост практически останавливается. Поэтому, более реалистичной моделью, включающей ошибку, будет:
Рост = exp(-b1*Возраст) * ошибка
На словах это означает, что чем больше возраст, тем меньше множитель exp(-b1*Возраст), и, следовательно, тем меньше будет разброс результирующей ошибки. Если же вы теперь прологарифмируете обе части нашего уравнения, то остаточная ошибка перейдет в свободный член линейного уравнения, т.е., аддитивный фактор, и вы сможете продолжить и оценить b1 пользуясь стандартную множественную регрессию.
Log (Рост) = -b1*Возраст + ошибка
Теперь мы рассмотрим некоторые регрессионные модели (нелинейные по параметрам), которые не могут быть сведены к линейным простым преобразованием начальных данных.
Общая модель роста. Общая модель роста похожа на рассмотренный ранее пример:
y = b0 + b1*exp(b2*x) + ошибка
Эта модель обычно используется при изучении различных видов роста (y), когда скорость роста в любой момент времени (x) пропорциональна оставшемуся приросту. Параметр b0 в этой модели представляет максимальное значение скорости роста. Типичным примером ее адекватного использования служит описание концентрации вещества (например, в воде) в виде функции времени.
Модели бинарных откликов: пробит и логит. Нередко зависимая переменная - переменная отклика бинарна по своей природе, т.е. может принимать только два значения. Например, пациент может выздороветь, а может и нет, кандидат на должность может пройти, а может провалить тест при приеме на работу, подписчики журнала могут продлить, а могут не продлевать подписку, купоны скидок могут быть использованы, а могут быть и не использованы и т.п. Во всех этих случаях нас может заинтересовать поиск зависимости между одной или несколькими “непрерывными” переменными и одной, зависящей от них бинарной переменной.
Использование линейной регрессии. Конечно, можно использовать стандартную множественную регрессию и вычислить стандартные коэффициенты регрессии. Например, если рассматривается продление журнальной подписки, можно задать переменную y со значениями 1’ и 0’, где 1 означает, что соответствующий подписчик продлил подписку, а 0, что он отказался от продления. Однако здесь возникает проблема: Множественная регрессия не “знает”, что переменная отклика бинарна по своей природе. Поэтому, это неизбежно приведет к модели с предсказываемыми значениями большими 1 и меньшими 0. Но такие значения вообще не допустимы для первоначальной задачи, таким образом, множественная регрессия просто игнорирует ограничения на диапазон значений для y.
Непрерывные функции отклика. Задача регрессии может быть сформулирована иначе: вместо предсказания бинарной переменной, мы предсказываем непрерывную переменную со значениями на отрезке [0,1]. Наибольшее распространение в этой области получили регрессионные модели логит и пробит.
Логит регрессия. В этой модели предсказываемые значения для зависимой переменной больше или равны 0 и меньше или равны 1 при любых значениях независимых переменных. Это достигается применением следующего регрессионного уравнения, которое в действительности имеет также некоторый глубокий смысл, как вы вскоре увидите (термин логит впервые был использован в работе Berkson, 1944):
y = exp(b0 + b1*x1 + ... + bn*xn)/{1 + exp(b0 + b1*x1 + ... + bn*xn)}
Легко заметить, что вне зависимости от коэффициентов регрессии и значений x, значения y, предсказанные этой моделью всегда будут принадлежать отрезку [0,1].
Название логит этой модели происходит от названия простого способа сведения этой модели к линейной с помощью логит преобразования. Предположим, что мы рассуждаем о нашей зависимой переменной в терминах нашей основной вероятности p, лежащей между 0 и 1. Тогда мы можем преобразовать эту вероятность p:
p' = loge{p/(1-p)}
Это преобразование обычно называют логистическим или логит - преобразованием. Отметим, что теоретически p’ может принимать любое значение от минус до плюс бесконечности. Поскольку логистическое преобразование решает проблему об ограничении на 0-1 границы для первоначальной зависимой переменной (вероятности), вы можете использовать эти (преобразованные) значения в обычном линейном регрессионном уравнении. А именно, если произвести логистическое преобразование обеих частей описанного выше уравнения, мы получим стандартную модель линейной регрессии:
p' = b0 + b1*x1 + b2*x2 + ... + bn*xn
Пробит регрессия. Можно рассматривать бинарную зависимую переменную как отклик на изменения некоторой “основной”, нормально распределенной переменной, в действительности имеющую диапазон изменений от минус до плюс бесконечности. Например, подписчик журнала может быть решительно против продления подписки, находится в нерешительности или испытывать расположение к журналу и стремиться продлить подписку. В любом случае, все, что мы (как издатели журнала) увидим, будет бинарный отклик, означающий продление или отказ от продления подписки. Однако если мы запишем стандартное уравнение линейной регрессии, основанное на “отношении людей к журналу”, мы получим:
отношение... = b0 + b1*x1 + ...
что, конечно, соответствует стандартной регрессионной модели. Логично предположить, что это “отношение людей к журналу” нормально распределено, и что вероятность продления подписки p равна соответствующей “отношению к журналу ” площади под графиком плотности нормального распределения. Поэтому, если мы преобразуем обе части уравнения в соответствующие нормальные вероятности, мы получим:
NP(отношение...) = NP(b0 + b1*x1 + ...)
Здесь NP означает нормальную вероятность (площадь под графиком плотности нормального распределения), таблицы которой имеются практически в любом статистическом справочнике. Выписанное выше уравнение называется также регрессионной моделью пробит. (Термит пробит был впервые использован в работе Bliss, 1934.)
Обобщенная логит регрессия. Обобщенная логит регрессия может быть выражена уравнением:
y = b0/{1 + b1*exp(b2*x)}
Вы можете представлять себе эту модель как обобщение обычной логит модели для бинарных зависимых переменных. Однако если логит модель ограничивает значения зависимой переменной только двумя возможными значениями, то общая модель позволяет отклику произвольно меняться внутри фиксированного интервала. Например, предположим, что вас интересует прирост популяции вида, перенесенного на новое место обитания, рассмотренный в виде функции времени. Тогда зависимая переменная будет равна числу особей данного вида в соответствующей среде обитания. Очевидно, что ее значение ограничено снизу, так как число особей не может быть меньше нуля; вероятно, что также существует какой-то верхний предел для численности популяции, который будет достигнут в некоторый момент времени.
Восприимчивость к лекарству и полумаксимальный отклик.В фармакологии, для описания эффективности различных доз лекарственных средств, часто используется следующая модель:
y = b0 - b0/{1 + (x/b2)b1}
В этой модели, x означает размер дозы (обычно в некоторой закодированной форме, так что x 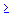 1), а y соответствует восприимчивости, измеренной в процентах по отношению к максимально возможной. Параметр b0 тогда означает ожидаемый отклик при насыщающем уровне дозы, а b2 равен концентрации, вызывающей полумаксимальный отклик; параметр b1 определяет наклон графика предсказываемой функции.
1), а y соответствует восприимчивости, измеренной в процентах по отношению к максимально возможной. Параметр b0 тогда означает ожидаемый отклик при насыщающем уровне дозы, а b2 равен концентрации, вызывающей полумаксимальный отклик; параметр b1 определяет наклон графика предсказываемой функции.
– Конец работы –
Эта тема принадлежит разделу:
Доклады по дисциплине Дополнительные главы математической статистики . Регрессионный анализ. 4
Содержание... Регрессионный анализ Теоретическая часть работы...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Существенно нелинейные регрессионные модели
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.046 сек.
Новости и инфо для студентов