Многофакторный дисперсионный анализ - раздел Математика, Доклады по дисциплине Дополнительные главы математической статистики . Регрессионный анализ. 4 Следует Сразу Же Отметить, Что Принципиальной Разницы Между Многофакторным И ...
Следует сразу же отметить, что принципиальной разницы между многофакторным и однофакторным ДА нет. Многофакторный анализ не меняет общую логику ДА, а лишь несколько усложняет ее, поскольку, кроме учета влияния на зависимую переменную каждого из факторов по отдельности, следует оценивать и их совместное действие. Таким образом, то новое, что вносит в анализ данных многофакторный дисперсионный анализ, касается в основном возможности оценить межфакторное взаимодействие. Тем не менее, по-прежнему остается возможность оценивать влияние каждого фактора в отдельности. В этом смысле процедура многофакторного ДА (в варианте ее компьютерного использования) несомненно более экономична, поскольку всего за один запуск решает сразу две задачи: оценивается влияние каждого из факторов и их взаимодействие.
Общая схема двухфакторного эксперимента, данные которого обрабатываются ДА имеет вид:
Рисунок 1.1 – Схема двухфакторного эксперимента
Предположив, что в рассматриваемой задаче о качестве различных m партий изделия изготавливались на разных t станках и требуется выяснить, имеются ли существенные различия в качестве изделий по каждому фактору:
А - партия изделий;
B - станок.
В результате получается переход к задаче двухфакторного ДА.
Все данные представлены в таблице 1.2, в которой по строкам - уровни Ai фактора А, по столбцам — уровни Bj фактора В, а в соответствующих ячейках, таблицы находятся значения показателя качества изделий xijk (i=1,2,...,m; j=1,2,...,l; k=1,2,...,n).
Таблица 1.2 – Показатели качества изделий
B1
B2
…
Bj
…
Bl
A1
x11l,…,x11k
x12l,…,x12k
…
x1jl,…,x1jk
…
x1ll,…,x1lk
A2
x21l,…,x21k
x22l,…,x22k
…
x2jl,…,x2jk
…
x2ll,…,x2lk
…
…
…
…
…
…
…
Ai
xi1l,…,xi1k
xi2l,…,xi2k
…
xijl,…,xijk
…
xjll,…,xjlk
…
…
…
…
…
…
…
Am
xm1l,…,xm1k
xm2l,…,xm2k
…
xmjl,…,xmjk
…
xmll,…,xmlk
Двухфакторная дисперсионная модель имеет вид:
xijk=μ+Fi+Gj+Iij+εijk, (15)
где xijk - значение наблюдения в ячейке ij с номером k;
μ - общая средняя;
Fi - эффект, обусловленный влиянием i-го уровня фактора А;
Gj - эффект, обусловленный влиянием j-го уровня фактора В;
Iij - эффект, обусловленный взаимодействием двух факторов, т.е. отклонение от средней по наблюдениям в ячейке ij от суммы первых трех слагаемых в модели (15);
εijk - возмущение, обусловленное вариацией переменной внутри отдельной ячейки.
Предполагается, что εijk имеет нормальный закон распределения N(0; с2), а все математические ожидания F*, G*, Ii*, I*j равны нулю.
Групповые средние находятся по формулам:
- в ячейке:
,
- по строке:
по столбцу:
общая средняя:
В таблице 1.3 представлен общий вид вычисления значений, с помощью дисперсионного анализа.
Таблица 1.3 – Базовая таблица дисперсионного анализа
Компоненты дисперсии
Сумма квадратов
Число степеней свободы
Средние квадраты
Межгрупповая (фактор А)
m-1
Межгрупповая (фактор B)
l-1
Взаимодействие
(m-1)(l-1)
Остаточная
mln - ml
Общая
mln - 1
Проверка нулевых гипотез HA, HB, HAB об отсутствии влияния на рассматриваемую переменную факторов А, B и их взаимодействия AB осуществляется сравнением отношений , , (для модели I с фиксированными уровнями факторов) или отношений , , (для случайной модели II) с соответствующими табличными значениями F – критерия Фишера – Снедекора. Для смешанной модели III проверка гипотез относительно факторов с фиксированными уровнями производится также как и в модели II, а факторов со случайными уровнями – как в модели I.
Если n=1, т.е. при одном наблюдении в ячейке, то не все нулевые гипотезы могут быть проверены так как выпадает компонента Q3 из общей суммы квадратов отклонений, а с ней и средний квадрат , так как в этом случае не может быть речи о взаимодействии факторов.
С точки зрения техники вычислений для нахождения сумм квадратов Q1, Q2, Q3, Q4, Q целесообразнее использовать формулы:
Q3 = Q – Q1 – Q2 – Q4.
Отклонение от основных предпосылок ДА— нормальности распределения исследуемой переменной и равенства дисперсий в ячейках (если оно не чрезмерное) — не сказывается существенно на результатах ДА при равном числе наблюдений в ячейках, но может быть очень чувствительно при неравном их числе. Кроме того, при неравном числе наблюдений в ячейках резко возрастает сложность аппарата ДА. Поэтому рекомендуется планировать схему с равным числом наблюдений в ячейках, а если встречаются недостающие данные, то возмещать их средними значениями других наблюдений в ячейках. При этом, однако, искусственно введенные недостающие данные не следует учитывать при подсчете числа степеней свободы.
ДА подобно t-критерию Стьюдента, позволяет оценить различия между выборочными средними; однако, в отличие от t-критерия, в нем нет ограничений на количество сравниваемых средних. Таким образом, вместо того, чтобы поставить вопрос о различии двух выборочных средних, можно оценить, различаются ли два, три, четыре, пять или k средних.
ДА позволяет иметь дело с двумя или более независимыми переменными (признаками, факторами) одновременно, оценивая не только эффект каждой из них по отдельности, но и эффекты взаимодействия между ними, поэтому позволяет проверять более сложные гипотезы.
Еще одно преимущество ДА по сравнению с обычным t-критерием для двух выборок: ДА позволяет изучать каждый фактор, управляя значениями других факторов. Это является основной причиной его большей статистической мощности (для получения значимых результатов требуется меньшие объемы выборок).
ДА определяет, есть ли эффект.
Слишком большая размерность выборок затрудняет проведение статистических анализов, поэтому имеет смысл уменьшить размер выборки.
Применив ДА можно выявить значимость влияния различных факторов на исследуемую переменную. Если влияние фактора окажется несущественным, то этот фактор можно исключить из дальнейшей обработки.
Модели ДА со случайными факторами неустойчивы к нарушениям предположений о нормальности и независимости эффектов случайных факторов. Эти нарушения могут привести к ошибкам при проверке гипотез.
Содержание... Регрессионный анализ Теоретическая часть работы...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ:
Многофакторный дисперсионный анализ
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
Виды регрессионного анализа
Многошаговая регрессия (ШРА) — последовательность шагов РА, выполняемая в направлении увеличения или уменьшения количества учитываемых коэффициентов линейной модели регрессии.
Линейная регрессия
Регрессионный анализ - раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным. Проблема
Описание объекта
В нашем случае объектом исследования является совокупность наблюдений за посещаемостью WEB сайта Комитета по делам семъи и молодежи Правительства г. Москвы www.telekurs.ru/ismm. Тематика сайта – эт
Факторы формирующие моделируемое явление
Отбор факторов для модели осуществляется в два этапа. На первом идет анализ, по результатам которого исследователь делает вывод о необходимости рассмотрения тех или иных явлений в качестве переменн
Построение уравнения регрессии
Используя программное обеспечение «ОЛИМП» (которое в свою очередь использует для расчетов указанные выше принципы и формулы чем значительно облегчает нам жизнь), найдем искомое урав
Смысл модели
При увеличении количества вакансий в день, количество посетивших сайт людей будет увеличиваться . Это означает что в настоящий момент сайт не полностью удовлетворяет запросы пользователей, что необ
Общее назначение
Любой закон природы или общественного развития может быть выражен в конечном счете в виде описания характера или структуры взаимосвязей (зависимостей), существующих между изучаемыми явлениями или
Оценивание линейных и нелинейных моделей
Формально говоря, Нелинейное оценивание является универсальной аппроксимирующей процедурой, оценивающей любой вид зависимости между переменной отклика и набором независимых переменных. В общ
Регрессионные модели с линейной структурой
Полиномиальная регрессия. Распространенной “нелинейной” моделью является модель полиномиальной регрессии. Термин нелинейная заключен в кавычки, поскольку эта модель линейна
Существенно нелинейные регрессионные модели
Для некоторых регрессионных моделей, которые не могут быть сведены к линейным, единственным способом для исследования остается Нелинейное оценивание. В приведенном выше примере для скорости
Регрессионные модели с точками разрыва
Кусочно - линейная регрессия. Нередко вид зависимости между предикторами и переменной отклика различается в разных областях значений независимых переменных. Например,
Методы нелинейного оценивания
Метод наименьших квадратов Функция потерь Метод взвешенных наименьших квадратов Метод максимума правдоподобия Максимум правдоподобия и логит/пробит мод
Начальные значения, размеры шагов и критерии сходимости.
Общим моментом всех методов оценивания является необходимость задания пользователем некоторых начальных значений, размера шагов и критерия сходимости алгоритма. Все методы начинают свою работу с ос
Оценивание пригодности модели
После оценивания регрессионных параметров, существенной стороной анализа является проверка пригодности модели в целом. Например, если вы определили линейную регрессионную модель, а реальная зависим
Распределения Вейбулла - Гнеденко
Экспоненциальные распределения - частный случай так называемых распределений Вейбулла - Гнеденко. Они названы по фамилиям инженера В. Вейбулла, введшего эти распределения в практику анализа результ
Распределение Рэлея
Распределение Рэлея введено Дж. У. Рэлеем (1880) в связи с задачей сложения гармонических колебаний со спиральными фазами. Закон Рэлея применяется для описания неотрицательных величин, в частности,
Факторный анализ как метод редукции данных
Под редукцией понимается переход от многих исходных количественных признаков к пространству факторов, число которых значительно меньше числа исходных количественных признаков. Например, от исходных
Общий обзор методов факторного анализа
В основе каждого метода факторного анализа лежит математическая модель, описывающая соотношения между исходными признаками и обобщенными факторами. Перейдем к краткой характеристике этих моделей дл
Метод главных компонент
В основе модели для выражения исходных признаков через факторы здесь лежит предположение о том, что число факторов равно числу исходных признаков (k=m), а характерные факторы вообще отсутств
Центроидный метод
Этот метод основан на предположении о том, что каждый из исходных признаков aj(j = 1...m) может быть представлен как функция небольшого числа
общих факторов F1
Метод экстремальной группировки параметров
Данный метод также основан на обработке матрицы коэффициентов корреляции между исходными признаками. В основе этого метода лежит гипотеза о том, что совокупность исходных признаков может быть разби
Критерии рационального выбора числа факторов
Сколько факторов следует выделять?Напомним, что анализ главных компонент является методом сокращения или редукции данных, т.е. методом сокращения числа переменных. Возникает естест
Проверка качественных характеристик выборки
Будем рассматривать критерии однородности.
Любой статистически критерий проверки гипотез представляет собой средство измерения. Поэтому пользоваться им следует также квалифицированно, как
Метод минимального расстояния
Равномернаяметрика,или метрика Колмогорова, - одна из наиболее старых и наиболее часто используемых вероятностных метрик. Термин «метрика Колмогорова» в отечественной литературе ис
Проверка количественных характеристик выборки
В §1 были определены характеристики генеральной совокупности, т.е. принадлежность к одной генеральной выборке, а также среднее и первый момент.
На данном этапе имеется функция распределени
Иерархические методы кластерного анализа
Суть иерархической кластеризации состоит в последовательном объединении меньших кластеров в большие или разделении больших кластеров на меньшие.
Иерархические аглом
Меры сходства
Для вычисления расстояния между объектами используются различные меры сходства (меры подобия), называемые также метриками или функциями расстояний.
Для придания больших весов более отдале
Методы объединения или связи
Когда каждый объект представляет собой отдельный кластер, расстояния между этими объектами определяются выбранной мерой. Возникает следующий вопрос — как определить расстояния между кластерами? С
Иерархический кластерный анализ в SPSS
Рассмотрим процедуру иерархического кластерного анализа в пакете SPSS (SPSS). Процедура иерархического кластерного анализа в SPSS предусматривает группировку как объектов (строк матрицы данных), т
Определение количества кластеров
Существует проблема определения числа кластеров. Иногда можно априорно определить это число. Однако в большинстве случаев число кластеров определяется в процессе агломерации/разделения множества об
Итеративный процесс.
Вычисляются центры кластеров, которыми затем и далее считаются покоординатные средние кластеров. Объекты опять перераспределяются.
Процесс вычисления центров и перераспределения объектов п
Проверка качества кластеризации
После получений результатов кластерного анализа методом k-средних, следует проверить правильность кластеризации (т.е. оценить, насколько кластеры отличаются друг от друга). Для этого рассчитывают
Алгоритм BIRCH
(Balanced Iterative Reducing and Clustering using Hierarchies)
Алгоритм предложен Тьян Зангом и его коллегами.
Благодаря обобщенным представлениям кластеров, скорость кластеризаци
Алгоритм WaveCluster
WaveCluster представляет собой алгоритм кластеризации на основе волновых преобразований . В начале работы алгоритма данные обобщаются путем наложения на пространство данных многомерной решетки. Н
Алгоритмы Clarans, CURE, DBScan
Алгоритм Clarans (Clustering Large Applications based upon RANdomized Search) формулирует задачу кластеризации как случайный поиск в графе. В результате работы этого алгоритма совокупность узлов гр
Биотестирование почвы
Многообразные загрязняющие вещества, попадая в агроценоз, могутпретерпевать в нем различные превращения, усиливая при этом свое токсическое действие. По этой причине оказались необх
Дисперсионный анализ в химии
ДА – совокупность методов определения дисперсности, т. е. характеристики размеров частиц в дисперсных системах. ДА включает различные способы определения размеров свободных частиц в жидких и газовы
Хотите получать на электронную почту самые свежие новости?
Подпишитесь на Нашу рассылку
Наша политика приватности обеспечивает 100% безопасность и анонимность Ваших E-Mail


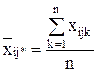 ,
,
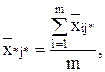

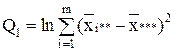

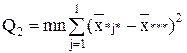
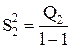
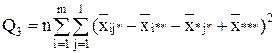




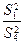 ,
, 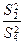 ,
,  (для модели I с фиксированными уровнями факторов) или отношений
(для модели I с фиксированными уровнями факторов) или отношений 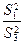 ,
, 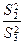 ,
, 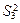 , так как в этом случае не может быть речи о взаимодействии факторов.
, так как в этом случае не может быть речи о взаимодействии факторов.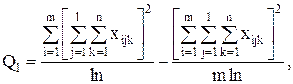
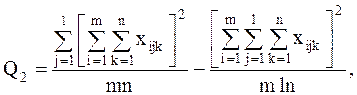

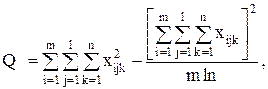






Новости и инфо для студентов