рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Социология
- /
- NVIDIA CUDA
Реферат Курсовая Конспект
NVIDIA CUDA
NVIDIA CUDA - раздел Социология, Стоит одна большая проблема — обработка информации и данных в установленные сроки · Cuda – Compute Unified Device Architecture · Программно-Аппаратная...
· CUDA – Compute Unified Device Architecture
· Программно-аппаратная платформа для параллельных вычислений от NVIDIA
· Раскрывает потенциал GPU для вычислений общего назначения
· Не поддерживается другими производителями
В представленном вашему вниманию обзоре-интервью мы продолжим знакомство с технологиями корпорации NVIDIA и поговорим о NVIDIA CUDA.
Стоит начать с вопроса — Что такое CUDA? CUDA — платформа, а не какой-то язык программирования, не какая-то среда программирования, а платформа, которая позволяет использовать мощности графических процессоров (GPU) для вычислений общего назначения. Почему это стало интересно? Примерно в 2003 году сформировалось сообщество энтузиастов, которые стали использовать GPU для запуска произвольного кода. Тогда еще не было CUDA, были стандартные графические API. Но примерно в то время GPU стали достаточно программируемыми. То есть появилось понятие графического шейдера, Open GL и Direct X фактически позволял вам сконфигурировать графический pipeline визуализации. К примеру, расчет цвета пикселя, указать какие текстуры используются и по каким правилам смешиваются, каким образом получается пиксель. Примерно в 2003 году появилась программируемость, разработчики получили возможность написать произвольную программу, которая выполнялась на каждом пикселе и вычисляла, какой ни будь алгоритм. Вместо того, чтобы фиксированным образом конфигурировать графический pipeline, появилась возможность описывать действия, которые производятся над каждой вершиной или пикселем в виде программы. При этом интерфейс GPU оставался сугубо графическим. Т.е. все равно нужно было использовать Direct X или Open GL. Можно так сказать, что графический конвейер остался тем же самым, но мы добавили программируемость в определенные места этого конвейера. Т.е. в конфигурируемом конвейере появилась возможность заменять участки на программы. При этом энтузиасты поняли, что эту возможность можно использовать не только для графики, но и для любых вычислений. Если представить, что мы вычисляем не цвета пикселей, а какие то значения, решаем уравнения. При этом соответственно ваш экран или массив пикселей, который вы считаете, становится выходным массивом данных, а ваша «текстура», которую вы подаете — входным массивом данных. Это то, что называется GPGPU.
Естественно, программирование, таким образом, было сопряжено с большими трудностями, потому что разработчикам нужно было изучать API, понимать, как работает графический ускоритель, и для многих это оставалось недоступным. Если человек исследователь, в какой-то предметной области несвязанной никак с графикой, ему соответственно требовалось время и ресурсы чтобы изучить саму программную модель того же Direct X. Но, тем не менее, люди этим занимались. Почему это было интересно? Потому что для большого класса задач оказалось, что производительность, которую они получают, используя GPU, значительно превосходила CPU.
Примерно в то время мы за этим очень внимательно наблюдали и попытались проанализировать все проблемы, с которыми разработчики сталкивались, и мы решили создать свою программную модель, которая все эти проблемы решала. То есть модель-платформа, которая позволяла запускать произвольный код на GPU. Собственно это идея, которая лежит в основе CUDA. Сама CUDA на рынке появилась в конце 2006 года. С приходом архитектуры G80. Когда появились карты GeForce 8800 — первые наши продукты, которые поддерживали CUDA.
Dimson3d | Архитектура у G80 была существенно переработана?
Совершенно верно, такие нововведения кардинальны и они требовали значительных изменений в самой базовой архитектуре. Все наши чипы до G80 кардинально отличались оттого, что было после G80. Именно в силу того, что мы предоставили возможность запускать произвольный код на GPU связанный не только с графикой.
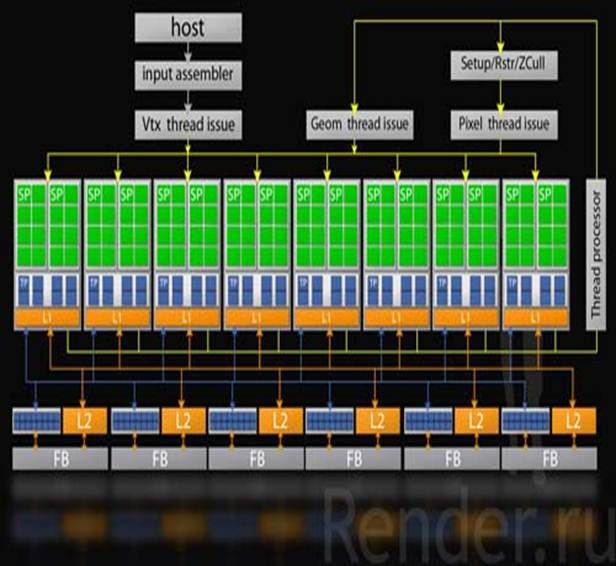
Архитектура чипа G80.
Еще раз подчеркну, что CUDA — не какой то конкретный язык программирования. Люди зачастую ассоциируют с языком C и в принципе изначально мы такие заявления делали — что CUDA - язык программирования. Теперь мы пытаемся от этого уйти, то есть CUDA – именно платформа. Набор средств, которые позволяют вам использовать возможности GPU для вычислений. На данный момент у нас есть компилятор с языка С, но это не значит, что в будущем будет только он. У нас есть планы по поддержке других языков, будет Open CL, DX Compute, все это языки программирования, программные среды поддерживают одну и туже базовую модель вычислений, и туже базовую архитектуру. Вот эта архитектура называется CUDA.
Dimson3d | Скажите, а какие различия существуют, между разработкой для CPU и GPU?
Наверное, в первую очередь, стоит отметить, какие архитектурные отличия существуют между CPU и GPU. Потому что из этого будут следовать отличия программирования. То есть GPU по сути своей — массивно параллельный процессор. Традиционная модель вычислений на CPU подразумевает последовательную модель исполнения. То есть у вас есть программа набор инструкций и эти инструкции вы выполняете одну за другой последовательно. А GPU подходит к проблеме совсем с другой стороны. Мы изначально предполагаем что, в наборе данных задач, которые мы обрабатываем, присутствует очень высокая степень параллелизма. То есть если мы говорим о графике, то совершенно естественно у вас большое количество пикселей на экране, большое количество вершин, треугольников и с этим большим массивом данных вам необходимо провести действия, но которые сходны. Одна последовательность действий, одна программа, которая исполняется сразу в массивно-параллельном режиме. В соответствии со свойством таких систем, мы изначально имели дело с очень массивно-параллельными задачами — коими являются графические задачи. Исходя из этого, архитектура GPU сильно отличается от архитектуры CPU. Мы имеем дело с большим массивом вычислительных модулей. Каждый, из которых работает в какой-то степени независимо, но все они выполняют одну последовательность действий одну программу над большим массивом данных. CPU в отличии от этой модели, использует другой подход. Вместо того, что бы использовать очень много маленьких процессоров, которые все делают, они строят достаточно увесистые ядра. Большие размеры кэша, обеспечивая достаточно высокую производительность при исполнении последовательного кода, но при этом очень трудно вместить большое количество ядер на кристалл. Допустим, сейчас Intel говорит о 4 — 8 ядрах на кристалле, в то время как у нас это море процессоров, массив процессоров исчисляется сотнями. Наш последний GPU например Tesla 10-ой серии — 240 процессоров, которые работают параллельно. Кардинальные отличия между архитектурами – то, что мы тратим площадь кристалла на сами вычислительные модули и делаем их очень много. В то время как центральный процессор, тратит площади кристалла, допустим, на кэш и достаточно небольшое количество относительно мощных вычислительных ядер. В соответствии с этим, программные модели тоже кардинально отличаются. Собственно поэтому мы и вынуждены были создать CUDA потому что традиционные языки программирования такие — как традиционный С не совсем подходят для выражения этого параллелизма. Нам пришлось взять стандартный С, расширить его мета-конструкциями для того, что бы программист мог выражать параллельные задачи и создать свой компилятор. В этом, наверное, и состоит главное отличие — масштаб параллелизма, к которому мы идем.

Пример кода на стандартном языке C, и пример кода с дополнениями для параллелизма.
Изначально CUDA как модель поддерживала гетерогенные вычисления — вы строите свою программу в виде секций. Есть секции, которые массивно параллельны — секции, которые будут исполняться на GPU. Есть секции, которые исполняются последовательно на CPU. С самой первой версии CUDA это было реализовано и поддерживалось. В одной программе вы могли смешивать параллельные и последовательные участки кода.
– Конец работы –
Эта тема принадлежит разделу:
Стоит одна большая проблема — обработка информации и данных в установленные сроки
Стоит одна большая проблема обработка информации и данных в установленные сроки Бывает что даже самых современных серверных залов с самыми... Здесь вступает в игру не так давно получившее массовое признание... Введение в GPGPU...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: NVIDIA CUDA
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.025 сек.
Новости и инфо для студентов