Оцінка продуктивності вузла реалізації алгоритму ШПФ на ПЛІС
Швидкодія виконання алгоритму ШПФ на ПЛІС визначається в NMAC (кількість операцій типу множення-нагромадження) за такою формулою:
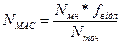 ,
,
де NMAC - число операцій типу множення-нагромадження, c-1;
- Nмн - число множень, необхідних для обчислення перетворення;
- fвідл - частота надходження вхідних даних, Гц;
- Nточ - розмір перетворення.
Тоді, наприклад, для обчислення ШПФ 256 точок за основою 2 з комплексними вхідними даними потрібно приблизно 3 тис. множень дійсних операндів і 5,5 тис. додавань дійсних операндів, для 1024 - точкового ШПФ за основою 2 - приблизно 16 тис. множень і 28,5 тис. додавань. Тоді, при частоті надходження вхідних даних 40 МГЦ продуктивність вузла обчислення ШПФ 256 точок повинна складати не менш 460 млн МАС у секунду, вузла обчислення ШПФ 1024 точки - не менш 620 млн МАС у секунду.
Основна ідея реалізації ковзного ШПФ полягає в тому, що для обчислень на кожній ступені використовується окремий закінчений блок, забезпечується конвеєризація в межах не тільки однієї ступені, але і всього модуля. При цьому час перетворення буде рівним часу обчислень на одній ступені.
Приклад розробки процесора ШПФ на ПЛІС
Завдання:
Спроектувати процесор для обчислення 16-ти точкового ШПФ за основою 2 та прорідженням за частотою на ПЛІС ф. Xilinx. Розрядність вхідних даних – 32 (16 розрядів дійсна і уявна частини).