Мовні технології
Виділяють такі напрямки мовних технологій.
1. Стиск (кодування) мови.
Високого степеня стиску досягаємо використанням дискретних косинусних перетворень.
2. Синтез мови
Завдання полягає в тому , що треба озвучити наявний текст. На сьогодні є два принципово різних підходи до вирішення цієї задачі.
а) компілятивний синтез
Виділяються певні одиниці мови, наприклад звуки мови, після цього з них утворюють слова, речення.
б) формантний синтез
Будують математичну модель голосового тракту людини, щоб мати змогу утворювати різні одиниці мови.
3. Розпізнавання диктора за голосом.
Є два варіанти цієї задачі. Перший варіант, так звана верифікація, полягає в з’ясуванні факту: належить записаний мовний зразок заданій особі чи ні. Інший ускладнений варіант ідентифікації полягає у визначенні якій із наперед заданих осіб належить записаний мовний зразок.
4. Визначення емоційного стану людини за голосом.
5. Визначення стану хворого за голосом (наприклад, при лікуванні мовних розладів).
6. Зміна темпу мовлення.
7. Розпізнавання мови.
Розпізнавання мови є одним з найскладніших напрямків мовних технологій, який можна застосувати в багатьох областях.Задача полягає в тому, що маючи мовний сигнал, треба утворити відповідний текст (так звану транскрипцію).
Підхід до розпізнавання мовних команд вкладається у загальну схему розпізнавання образів (крім мови це можуть бути двовимірні або тривимірні зображення, багатовимірні сигнали різної природи тощо). Згідно з цією схемою слід виконувати такі кроки:
- на фазі навчання попередньо записати певну множину мовних образів-еталонів;
- під час розпізнавання порівнювати невідомий образ (мовний сигнал), який хочемо розпізнати, з кожним із із записаних мовних образів-еталонів;
- найближчий (у сенсі вибраної відстані між образами) до невідомого образу, для якого хочемо здійснити розпізнавання, образ-еталон і буде відповіддю системи розпізнавання.
Ідея лежить на поверхні – проблема в тому, як підійти до її реалізації. Коли ми хочемо реалізувати описану схему для випадку розпізнавання мовних команд виникає багато конкретних труднощів.
У якому вигляді готувати і тримати мовні сигнали-еталони ?
Використовувати часове, спектральне чи якесь комбіноване зображення сигналів ?
Якою міркою порівнювати відстань між двома мовними сигналами ?
Розглянемо найпростіший алгоритм розпізнавання окремих слів із обмеженого словника з навчанням на одного диктора.
Найпростіший розпізнавач мови
Спочатку опишемо як виконують спрощене попереднє опрацювання мовного сигналу х(n). Пропускаємо його через набір смугопропускних цифрових фільтрів (кількість фільтрів для прикладу взята рівною 16). Тобто частотний діапазон сигналу від 0 до 8 кГц (для мовних сигналів) розбиваємо на 16 рівних смуг. Частотні характеристики фільтрів наведені на рис.9.1.
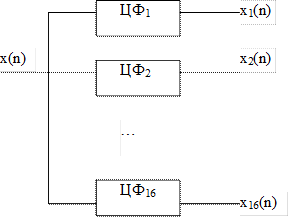
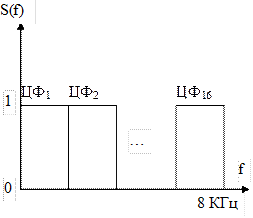
Рис.9.1.
В результаті на виходах цифрових фільтрів ЦФ1, ЦФ2,...,ЦФ16 отримуємо 16 цифрових сигналів х1(n), х2(n),.... х16(n).
Ділимо число N відліків кожного з цих сигналів на 16 рівних відрізків, доповнюючи сигнал при потребі нульовими відліками, щоб N було кратне 16. Для відліків кожного із шістнадцяти відрізків знаходимо середнє значення. Тобто, перше значення – це середнє відліків сигналу від першого до N/16-го; друге значення – це середнє відліків сигналу від (N/16+1)-го до 2N/16-го;...; шістнадцяте значення – це середнє відліків сигналу від (15N/16+1)-го до N-го. Отже, для кожного з шістнадцяти сигналів х1(n), х2(n),.... х16(n) отримуємо 16 середніх значень.
У результаті для сигналу х(n) маємо загалом вектор із 16·16=256 значень.
На фазі навчання диктор проводить навчання системи розпізнавання, повторюючи по три рази (для надійності) слова із вибраного невеликого словника.
Наприклад, це можуть бути назви десяткових цифр, тобто словник складається з таких 10 слів: нуль, один, два, три, чотири, п’ять, шість, сім, вісім, дев’ять.
Виконуючи описане попереднє опрацювання цих мовних сигналів, отримуємо тридцять векторів довжиною 256 значень кожен. Це мовні еталони системи розпізнавання.
На фазі розпізнавання диктор вимовляє будь-яке невідоме слово з обумовленого словника і записуємо відповідний мовний сигнал. Після його попереднього опрацювання отримуємо вектор довжиною 256 значень. Підраховуємо по черзі відстань між цим вектором і кожним із 30 еталонних векторів.
Відстань між двома векторами 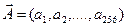 та
та  задають як евклідову відстань:
задають як евклідову відстань: 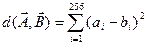 .
.
Мінімальна із отриманих відстаней визначає відповідь системи розпізнавання.
Точність (якість) розпізнавання оцінюємо процентом правильно розпізнаних слів.
Експерименти показують, що описаний найпростіший розпізнавач мови має точність розпізнавання приблизно 85%. Це не можна вважати задовільним показником.
Що потрібно вдосконалити в розглянутому алгоритмі розпізнавання, щоб покращити точність розпізнавання ?
Зауважимо, що два рази абсолютно однаково вимовити якесь слово неможливо. Неодмінно є відмінності в темпі мови (хоча би незначні) та певні спектральні відмінності.
Тому вдосконалений алгоритм розпізнавання слів із невеликого словника повинен задовільняти таким вимогам:
- порівнювати мовні сигнали з урахуванням часових (темпоральних) відмінностей, при потребі вирівнюючи тривалості мовних сигналів;
- враховувати спектральні зміни в мовному сигналі при зміні цього сигналу в часі. Для цього слід, зокрема, виконувати точне попереднє опрацювання мовних сигналів.
Таким вимогам задовольняє алгоритм розпізнавання мовних команд (ізольованих слів), який називають алгоритмом DTW (dynamic time warping - динамічного часового вирівнювання).
Попереднє опрацювання мовних сигналів
Результатом попереднього опрацювання мовних сигналів є отримання множини спектральних векторів, які характеризують цей сигнал і використовуються для подальшого розпізнавання.
Принципове припущення, яке робиться в сучасних розпізнавачах є те, що мовний сигнал розглядається як стаціонарний (тобто його спектральні характеристики відносно постійні) на інтервалі в кілька десятків мілісекунд. Тому основною функцією попереднього опрацювання є розбити вхідну мовний сигнал на інтервали і для кожного інтервалу отримати згладжені спектральні оцінки.
Типова величина одного інтервалу - 25,6 мс. Сусідні інтервали беруться зі зсувом відносно попереднього інтервалу. Вживана величина перекриття інтервалів рівна 10 мс.У результаті попереднього опрацювання кожного з вказаних інтервалів отримуємо вектор з кількох десятків спектральних значень. Блок-схема алгоритму попереднього опрацювання мовного сигналу наведена на рис.. Кроки, які слід виконати для попереднього опрацювання кожного інтервалу мовного сигналу, детально описані далі.
Як приклад розглядаємо мовні зразки, дискретизовані з частотою 16 КГц та з розрядністю 16 біт. Дискретизований мовний сигнал розбиваємо на інтервали тривалістю 25,6 мс, тобто 409 відліків. Інтервали перекриваються зі зсувом на 10 мс (160 відліків).
