Алгоритм динамічного часового вирівнювання для розпізнавання слів з невеликого словника
На фазі навчання як мовні еталони записуємо якнайкоротше вимовлені диктором слова із заданого невеликого словника.
Сигнал, який розпізнаємо, та сигнали-еталони параметризуємо – перетворюємо в послідовність спектральних векторів. Для цього розбиваємо сигнал на послідовні інтервали по 25,6 мс з перекриттям на 10 мс.У результаті попереднього опрацювання кожного з інтервалів отримуємо вектор з 24 спектральних значень. Кроки, які слід виконати для попереднього опрацювання кожного інтервалу мовного сигналу, детально описані раніше.
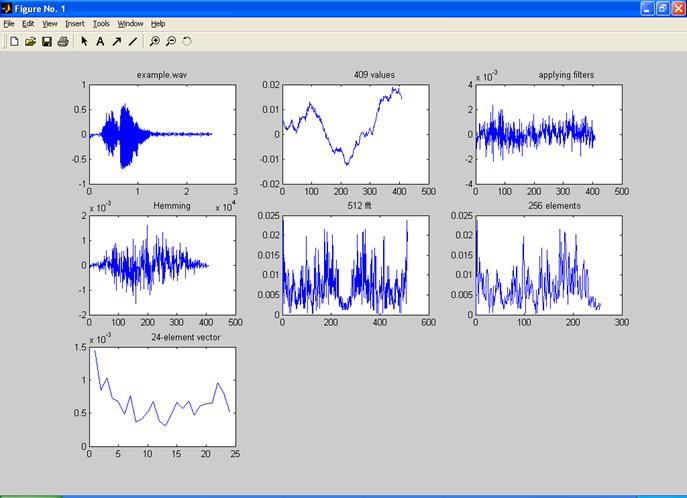
Рис. 9.3. Етапи попереднього опрацювання мовного сигналу
Кількість отриманих у результаті попереднього опрацювання спектральних векторів може бути різною. Вона залежить від тривалості в часі мовного сигналу, який опрацьовуємо.
До послідовності векторів для кожного з еталонів додаємо один вектор зі всіма нульовими компоненти на початку послідовності і такий же ж один вектор укінці послідовності. Потреба в додаванні таких векторів полягає в необхідності моделювати паузи довільної тривалості на початку і вкінці еталону. Адже записаний сигнал, який розпізнаємо, завжди має такі паузи, і спроба автоматично усунути ці паузи не дає задовільного результату.
На фазі розпізнавання будуємо матриці відстаней між векторами того сигналу, який хочемо розпізнати, і векторами кожного з сигналів-еталонів. Побудова матриці відстаней для сигналу, який розпізнаємо, і одного сигналу-еталону ілюструється рис.9.4.
| aI | dI1 | dI2 | … | dIJ |
| … | … | … | … | … |
| a2 | d21 | d22 | … | d2J |
| a1 | d11 | d12 | … | d1J |
| b1 | b2 | … | bJ |
Рис. 9.4. Матриця відстаней для сигналу і одного еталону
Наведені в матриці відстані dij між векторами сигналу і векторами еталону – це евклідові відстані між відповідними векторами. Їх значення задаються таким виразом:
 , i=1,2,….,I; j=1,2,…,J
, i=1,2,….,I; j=1,2,…,J
Базуючись на отриманій матриці відстаней, будуємо матрицю (граф) шляхів. Побудова матриці шляхів для сигналу і одного еталону наведена на рис.9.5.

Рис. 9.5.Матриця шляхів для сигналу і одного еталону
Мета побудови матриці шляхів – встановити найкращу відповідність між векторами сигналу і векторами еталону. Кожен вектор еталону можемо повторити, а можемо перейти до наступного вектора. Але повторювати вектор еталону два рази підряд забороняється. Винятками є початковий та кінцевий вектори еталону, повторення яких імітують паузи довільної тривалості на початку і укінці сигналу. Їх дозволяється повторяти будь-яке число разів. По суті, з основних еталонів будуємо похідні еталони за рахунок повторення векторів в основних еталонах.
Такий підхід до встановлення відповідності між векторами сигналу і векторами еталону визначається відповідною моделлю утворення слів, наведеною на рис. Кружечки на рисунку зображають вектори еталону. У цій моделі дозволяється повторити вектор еталону (петля біля кружечка) або перейти до наступного вектора еталону (стрілка до чергового кружечка).
Виходячи з цієї моделі, будуємо шляхи, які складаються з діагональних або вертикальних відрізків. Діагональний відрізок означає повторення вектора еталону, а вертикальний – повторення вектора еталону. Вибір певного шляху полягає у встановленні якоїсь відповідності між векторами сигналу, який хочемо розпізнати, і векторами чергового сигналу-еталону, до якого приміряємо наш сигнал. Стосовно наведеного в матриці шляхів конкретного шляху ця відповідність виглядає так:


Рис.9.6. Модель утворення слова
- вектору сигналу а1 ставимо у відповідність вектор b1 еталону (відстань між цими векторами дорівнює d11, її беремо з раніше підготовленої матриці відстаней);
- вектору сигналу а2 ставимо у відповідність вектор b1 еталону;
- вектору сигналу а3 ставимо у відповідність вектор b2 еталону;
- вектору сигналу а4 ставимо у відповідність вектор b3 еталону;
- вектору сигналу а5 ставимо у відповідність вектор b3 еталону;
- вектору сигналу а6 ставимо у відповідність вектор b4 еталону;
- вектору сигналу а7 ставимо у відповідність вектор b5 еталону;
- вектору сигналу а8 ставимо у відповідність вектор b5 еталону;
- вектору сигналу а9 ставимо у відповідність вектор b6 еталону;
- вектору сигналу а10 ставимо у відповідність вектор b6 еталону;
- вектору сигналу а11 ставимо у відповідність вектор b6 еталону.
За такими правилами будуємо всі можливі шляхи. Для кожного шляху підраховуємо сумарну відстань як суму евклідових відстаней між парами векторів, пов’язаних з відрізками шляху.
Знаходимо в матриці шлях із найменшою сумарною відстанню. Сумарна відстань вздовж цього шляху є відстанню між сигналом і даним еталоном. Для якого з усіх можливих еталонів відстань буде мінімальною, тому еталону, ми вважаємо, відповідає невідомий сигнал.
Формально рух по матриці шляхів описуємо наступним чином (далі наведено первинний фрагмент матриці):
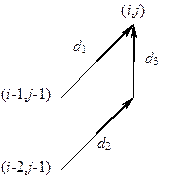
Найменша сумарна відстань S(i,j) від точки (0,0) до точки (i,j) дорівнює
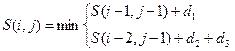 ,
,
де S(i-1,j-1) – найменша сумарна відстань від точки (0,0) до точки (i-1,j-1);
S(i-2,j-1) – найменша сумарна відстань від точки (0,0) до точки (i-2,j-1);
d1 - відстань між векторами, які відповідають відрізку, що з’єднує точки (i-1,j-1) та (i,j);
d2 - відстань між векторами, які відповідають відрізку, що з’єднує точки (i-2,j-1) та (i-1,j);
d3 - відстань між векторами, які відповідають відрізку, що з’єднує точки (i-1,j) та (i,j);
Для отримання наведеного виразу застосовуємо так званий принцип оптимальності Белмана. Згідно із цим принципом (основним принципом динамічного програмування) будь-який підшлях оптимального шляху має бути оптимальним.
Виходячи з наведеного виразу всі шляхи будуються рекурсивно (зліва вправо) та одночасно. У цьому разі кращі (в сенсі меншої сумарної відстані) шляхи залишаються, а гірші відкидаються.
Модель утворення слова можна ускладнити: деякі вектори еталону дозволяється перестрибувати (пропускати), як показано на рис.

Рис.9.7. Ускладнена модель утворення слова
Тоді шляхи складатимуться з діагональних, вертикальних або горизонтальних відрізків. Горизонтальний відрізок означає пропускання вектора еталону. Перевага такого варіанту: при записування мовних сигналів-еталонів немає необхідності вимовляти їх якнайкоротше.
Блок-схема алгоритму розпізнавання слів з використанням динамічного часового вирівнювання наведена на рис.9.8.
Отримавши матриці відстаней, будуємо матрицю (граф) шляхів користуючись викладеними далі практичними прийомами.
Спочатку значення всіх елементів матриці шляхів покладаємо рівними
S(u,v)=10000, u =1,.., time; v =1,…, time(k),
де time – кількість спектральних векторів у мовному сигналі, що розпізнаємо,
time(k) - кількість спектральних векторів у k –му мовному сигналі-еталоні (k =1, 2, …, chyslo);
chyslo – число еталонів.
Значення 10000 є практичним замінником теоретичного нескінченно великого додатнього значення. З точки зору побудови шляху з мінімальним значенням сумарної відстані вздовж цього шляху, такі значення є нейтральними.
Далі обраховуємо tdelta=time-time(k). Обчислене значення є більшим від нуля, бо всі еталони вимовляються коротко, і тому їх довжина завжди менша за довжину сигналу: time>time(k) для k =1, 2, …, chyslo.
Значення відстані S(1,1) в точці (1,1) матриці шляхів береться рівним відстані між першим вектором сигналу і першим вектором зразка:
S(1,1)=d(1,1).
Оскільки попереднього вектора в еталоні немає, то немає що повторювати, і це єдиний можливий варіант.
Для j=2,…,time(k) беремо значення діагональних елементів матриці шляхів рівними
S(j,j)= S(j-1,j-1)+d(j,j).
Дійсно, оскільки рух по горизонталі заборонений, то дістатися до діагонального елемента (j,j) можна лише від діагонального елемента на місці (j-1,j-1).
Для j=2,…,tdelta+1 беремо значення елементів першого стовпця матриці шляхів рівними
S(i,1)= S(i-1,1)+d(i,1).
Справді, оскільки перед першим стовпцем немає стовпців (бо він перший), дійти до елемента (i,1) першого стовпці можна лише з елемента (i-1,1) першого стовпця. Як бачимо, у першому стовпці не забороняється повторення першого вектора еталону більше, ніж один раз. Зрозуміло чому так. Адже перший вектор еталону – це вектор паузи.
Від другого до передостаннього стовпця (j=2,…,time(k)-1) матриці шляхів виконуємо такі дії.
Починаючи з елемента відповідного стовпця вище від діагоналі і до елемента в рядку tdelta+j виконуємо обчислення сумарної мінімальної відстані. У цьому разі до елемента (i,j) можна дістатися двома можливими шляхами.
Перший можливий шлях – від елемента (i-1,j-1) по діагоналі до елемента (i,j).У цьому разі до сумарної відстані S(i-1,j-1) в точці (i-1,j-1) додаємо відстань d(i,j) і отримуємо число c1.
Другий можливий шлях розбивається на два кроки. Спочатку від елемента (i-2,j-1) рухаємось по діагоналі до елемента (i-1,j). Потім від елемента (i-1,j) рухаємось по вертикалі до елемента (i,j).
Під час першого кроку до сумарної відстані S(i-2,j-1) в точці (i-2,j-1) додаємо відстань d(i-1,j). Під час другого кроку до отриманої на попередньому кроці відстані додаємо d(i,j). У результаті отримуємо:
c2= S(i-2,j-1)+ d(i-1,j)+ d(i,j).
Значення матриці шляхів у точці (i,j) беремо рівним меншому з чисел c1, c2:
s(i,j)=min(c1, c2).
Вектор еталону від третього до передостаннього стовпця не можна повторювати більше одного разу підряд.
Рух по останньому стовпцю матриці шляхів є специфічним. Дозволяється прийти до елемента в цьому стовпці по діагоналі або по вертикалі. Тобто, в кінці матриці шляхів дозволяється багатократно повторювати останній вектор еталону, який є вектором паузи.
Алгоритм розпізнавання включає в себе такі блоки:
Введення диктором мовних зразків із вибраного словника. У цьому блоці диктор вводить мовні зразки тих слів української мови, які потім система розпізнавання зможе розпізнати. Тобто тут задаються можливі варіанти слів, з яких система буде вибирати при розпізнаванні.
Попереднє опрацювання к-го сигналу-еталону. Виконується згідно з описом, наведеним раніше.

Рис. 9.8. Блок-схема алгоритму DTW розпізнавання слів
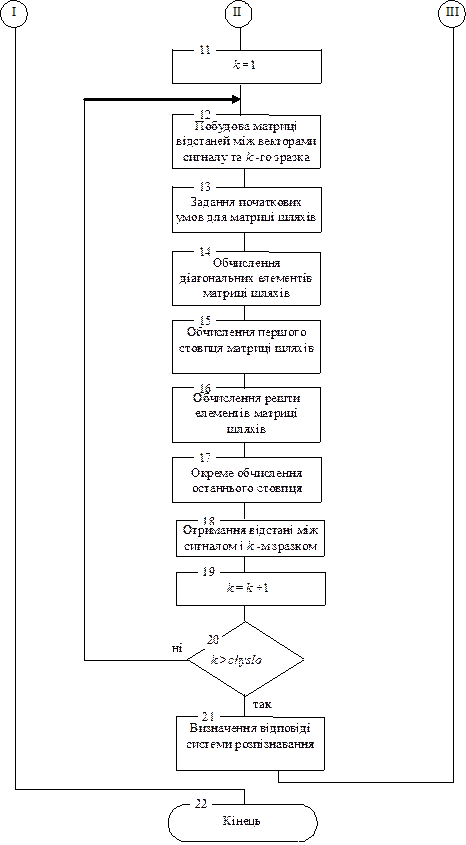
Рис. 9.8. Блок-схема алгоритму DTW розпізнавання слів (закінчення)
Додавання звукових векторів паузи до і після звукових векторів сигналу-еталона. Мовний сигнал, що буде розпізнаватися, фізично неможливо записати без пауз перед і після команди. Разом з тим відомі прийоми автоматичного викидання цих пауз не дають задовільних результатів. Тому для реалізації розпізнавання мовних сигналів з паузами до отриманих сигналів-еталонів спочатку і в кінці додаємо по одному вектору, які моделюють нам паузи. Усі значення цих векторів дорівнюють нулю.
Запис мовного сигналу в звуковому редакторі. Використовуємо вікно звукового редактора Cool Edit для запису мовного сигналу, що потім повинен розпізнаватися. Для цього використовується мікрофон, підключений до звукової плати. Після запису мовного сигналу з відповідною частотою дискретизації та розрядністю без усякого редактування він дається на розпізнавання.
Попереднє опрацювання мовного сигналу, що буде розпізнаватися: формування звукових векторів. Виконується згідно з описом, наведеним раніше.
Побудова матриці відстаней між векторами сигналу та k-го зразка. Обчислюються евклідові відстані між усеможливими парами векторів, де перший елемент пари – це довільний вектор сигналу, що розпізнається, а другий елемент пари – це довільний вектор к-го сигналу-еталона. Розмір матриці відстаней дорівнює time x time(k), де time – кількість векторів мовної команди, що розпізнається, а time(k) – кількість векторів k -го мовного сигналу-еталона.
Задання початкових умов для матриці шляхів. Усі елементи матриці шляхів на початку покладаються рівними достатньо великому числу 10000. Оскільки подальші кроки пов’язані із знаходженням мінімумів, то такі присвоєння не вплинуть на отримання правильного результату.
Обчислення діагональних елементів матриці шляхів. Діагональні елементи матриці шляхів обчислюються за правилом, що відрізняється від правила обчислення решта елементів матриці, як описано раніше.
Обчислення першого стовпця матриці шляхів. Елементи першого стовпця матриці шляхів обчислюються за правилом, що відрізняється від правила обчислення решта елементів матриці шляхів і від правила обчислення діагональних елементів. У цьому разі дозволяється багатократно повторювати перший вектор сигналу-еталона (він відповідає паузі). Це також описано раніше.
Обчислення решти стовпців матриці шляхів. Елементи від третього до передостаннього включно стовпців матриці шляхів обчислюються з урахуванням двох можливих підшляхів на матриці і вибору коротшого (в сенсі евклідової відстані) з них. Такі варіанти описані на початку цього підрозділу.
Окреме обчислення останнього стовпця. Елементи останнього стовпця матриці шляхів обчислюються за правилом, що відрізняється від правила обчислення решта елементів матриці шляхів і від правила обчислення діагональних елементів. У цьому разі дозволяється багатократно повторювати останній вектор сигналу-еталона (він відповідає паузі). Це також описано раніше.
Отримання відстані між сигналом і k-м зразком. Користуючись збудованою матрицею шляхів, знаходимо відстань між сигналом, що розпізнається і k-м сигналом-еталоном.
Визначення відповіді системи розпізнавання. Порівнюються знайдені відстані між мовним сигналом, що розпізнається, і всіми сигналами-еталонами. Найменша з цих відстаней визначає відповідь системи розпізнавання. На екрані друкується відповідне слово із визначеного на фазі навчання словника.
Для моделювання цього алгоритму (його реалізації та виконання експериментів для з’ясування точності розпізнавання) вибрано середовище MATLAB.
Для роботи із звуками (у даному випадку для запису та редактування мовних сигналів-еталонів та довільних мовних сигналів) використовувалися професійний звуковий редактор COOL EDIT фірми Sintrillium Software Corporation, навушники і мікрофон.
Cool Edit є цифровим аудіо редактором для операційної системи Windows. Його, зокрема, можна використати щоб записати та програти файли з широкого набору аудіо форматів, відредактувати файли і змішати їх докупи, а також конвертувати файли з одного формату в інший.
Таким чином, робоче середовище, яке використовувалось при виконанні експериментів складалось із головного вікна програми MATLAB 6.5 та вікна професійного звукового редактора Cool Edit. Вигляд цього робочого середовища наведений на рис.9.9.
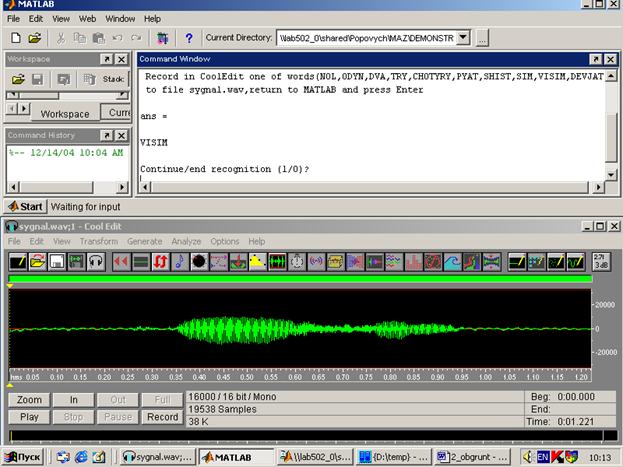
Рис. 9.9. Робоче середовище для розпізнавання слів із невеликого словника
Виконувалися експерименти з розпізнавання з використанням алгоритму динамічного часового вирівнювання 10 ізольованих слів (назви цифр від 0 до 9: ноль, один, два, три, чотири, п’ять, шість, сім, вісім, дев’ять). Коротко (як тільки можливо) вимовлені ці слова слугували еталонами для розпізнавання. Приклади отриманих після навчання на конкретного диктора сигналів-еталонів наведені на рис. Для цих еталонів виконано попереднє опрацювання. Кількість акустичних векторів у цих еталонах наведена в табл.9.2.
Таблиця 9.2. Кількість звукових векторів для еталонів слів
| Слово | Довжина |
| ноль | |
| один | |
| два | |
| три | |
| чотири | |
| п’ять | |
| шість | |
| сім | |
| вісім | |
| дев’ять |
Далі вимовлялися вказані слова в довільному порядку. Кількість акустичних векторів у мовних сигналах, які фігурували в експериментах, наведена в табл.9.3.
Таблиця 9.4. Кількість звукових векторів для мовних сигналів слів
| Слово | Довжина |
| ноль | 30-40 |
| один | 48-58 |
| два | 29-39 |
| три | 28-38 |
| чотири | 55-65 |
| п’ять | 38-48 |
| шість | 55-65 |
| сім | 52-62 |
| вісім | 53-63 |
| дев’ять | 55-65 |
Зауважимо, що слова вимовлялися в різному темпі та з різною гучністю.
Отримано практично 100% точність розпізнавання.
Потім був змінений диктор: також отримано практично 100% точність розпізнавання.
Отже, система розпізнавання з невеликим словником та для одного диктора працює добре.
Якщо брати зразки від одного диктора, а потім намагатися розпізнавати слова іншого диктора, то система починає робити помилки. Точність розпізнавання падає до 75-85%. Така точність уже є неприйнятною для більшості практичних застосувань. Щоб покращити точність розпізнавання у цьому разі треба було записувати зразки від кількох дикторів і потім всі отримані зразки використовувати при розпізнаванні.
Інша проблема, яка виникає при розпізнаванні, це забезпечення великого словника при розпізнаванні, поступаючись при цьому точністю розпізнавання. Зрозуміло, що буквально записати велику кількість еталонів практично нереально. У цьому разі слід використовувати інші підходи, які розглянемо далі.
Сигнал записаний в звуковому професійному редакторі Cool Edit. У цьому разі слово “чотири” вимовлялося диктором якомога коротше (у швидкому темпі). Частота дискретизації сигналу-еталона – 16 КГц. Розрядність сигналу-еталона – 16 розрядів. Після того, як сигнал був записаний, у ньому вручну на початку і вкінці викинуто паузи. Ці паузи обов’язково присутні в мові людини. З точки зору проведення подальшого розпізнавання їх слід викинути.
Кількість відліків для наведеного на рис.4.5 сигналу-еталона дорівнює 7139 відліків.

Рис.9.5. Сигнал-еталон слова “ноль”
Сигнал записаний в звуковому професійному редакторі Cool Edit. У цьому разі слово “ноль” вимовлялося диктором якомога коротше (у швидкому темпі). Частота дискретизації сигналу-еталона – 16 КГц. Розрядність сигналу-еталона – 16 розрядів. Після того, як сигнал був записаний, у ньому вручну на початку і вкінці викинуто паузи. Ці паузи обов’язково присутні в мові людини. З точки зору проведення подальшого розпізнавання їх слід викинути.
Кількість відліків для наведеного на рис. сигналу-еталона дорівнює 3725 відліків.
Сигнал записаний в звуковому професійному редакторі Cool Edit. У цьому разі слово “вісім” вимовлялося диктором якомога коротше (у швидкому темпі). Частота дискретизації сигналу-еталона – 16 КГц. Розрядність сигналу-еталона – 16 розрядів. Після того, як сигнал був записаний, у ньому вручну на початку і вкінці викинуто паузи. Ці паузи обов’язково присутні в мові людини. З точки зору проведення подальшого розпізнавання їх слід викинути.
Кількість відліків для наведеного на рис. сигналу-еталона дорівнює 6292 відліків.
Як бачимо з рисунку, на початку і вкінці реального сигналу, який розпізнається, є паузи. Пауза на початку сигналу рівна приблизно 0,3 с, а пауза вкінці сигналу рівна наближено 0,25 с. Система розпізнавання дала відповідь, що сигнал, який розпізнавався, це слово “вісім”. Можна порівняти рис. з рис. (сигнал-еталон слова “вісім”). Кількість відліків у сигналі суттєво більша порівняно з сигналами-еталонами і дорівнює 19538 відліків.
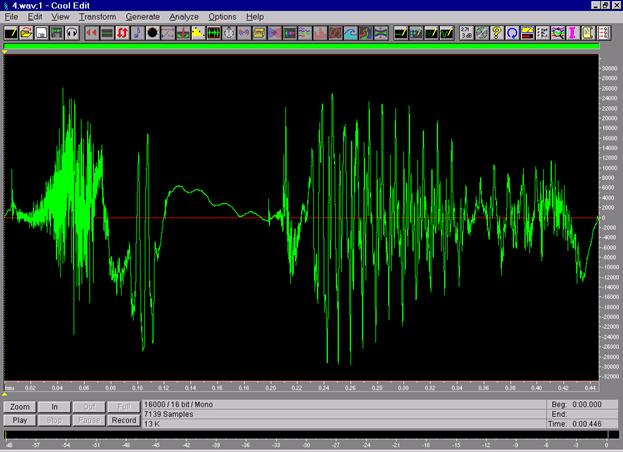
Рис.9.6. Сигнал-еталон слова “чотири”
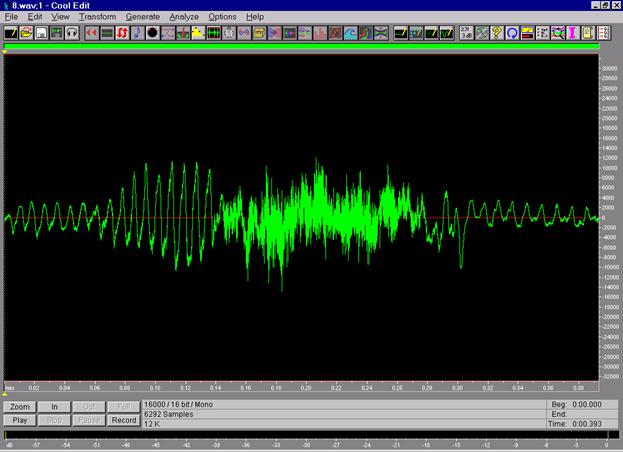
Рис.9.7. Сигнал-еталон слова “вісім”
Приклад, сигналу для якого виконувалося розпізнавання, наведений на рис.9.8.
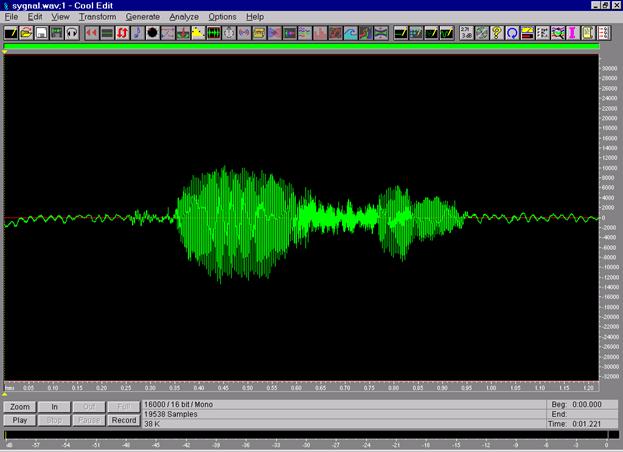
Рис.9.8. Сигнал, що розпізнавався