Постановка задачи регрессии - раздел Экономика, Курс лекций по дисциплине Эконометрика. В последнее время специалисты Поставим Задачу Регрессии Y На X.
Пусть Мы Располагаем...
Поставим задачу регрессии Y на X.
Пусть мы располагаем n парами выборочных наблюдений над двумя переменными X и Y:
X1,
X2,
. . .
Xn;
Y1,
Y2,
. . .
Yn.
Функция f(X) называется функцией регрессииY по X, если она описывает изменение условного среднего значения результирующей переменной Y в зависимости от изменения значений объясняющей переменной X: f(X)=E(Y |X).
Таким образом, имеет место уравнение регрессионной связи между Y и X:
Yi =f(Xi)+ui, i=1,…,n. (2.2)
Присутствие в модели (2.2) случайной "остаточной" компонентыu, также называемой случайным членом, обусловлено следующими причинами:
1. Ошибки спецификации. Среди них выделяют невключение важных объясняющих переменных, агрегирование (объединение) переменных, неправильную функциональную спецификацию модели.
2. Ошибки измерения. Связаны со сложностью сбора исходных данных и использованием в модели аппроксимирующих переменных для учета факторов, непосредственное измерение которых невозможно.
3. Ошибки, связанные со случайностью человеческих реакций. Обусловлены тем, что поведение и непосредственное участие человека в ходе сбора и подготовки данных может быть достаточно непредсказуемым и вносит, таким образом, свой вклад в случайный член.
Мы хотим на основе выборочных наблюдений с учетом дополнительных требований, налагаемых на u,статистически оценить функцию f(X), проверить оптимальность полученной оценки и использовать уравнение для построения прогноза.
Допущения модели. Относительно u необходимо принять ряд гипотез, известных как условия Гаусса-Маркова:
1. Eui=0, i=1,…,n.
Это требование состоит в том, что математическое ожидание случайного члена в любом наблюдении должно быть равно нулю. Иногда случайный член будет положительным, иногда отрицательным, но он не должен иметь систематического смещения ни в одном из двух возможных направлений. Свойство непосредственно вытекает из смысла функции регрессии. Возьмем в (2.2) матожидание от обеих частей при фиксированном значении X, получим: E(Y|X) =E(f(X))+E(u), по свойству матожидания Þ E(Y|X) =f(X)+E(u), а поскольку с учетом определения функции регрессии должно быть f(X)=E(Y |X), то необходимо E(u)=0.
2.
Первая строчка означает требование постоянства дисперсии регрессионных остатков (независимость от того, при каких значениях объясняющей переменной производятся наблюдения i), которое называют гомоскедастичностью остатков. Вторая строчка предполагает отсутствие систематической связи между значениями случайного члена в любых двух наблюдениях, которые должны быть абсолютно независимы друг от друга.
3. X1, …, Xn – неслучайные величины.
Таким образом, задача регрессии имеет вид:
Yi =f(Xi)+ui, i=1,…,n.
а. Eui=0, i=1,…,n. (2.3)
б. (2.4)
в. X1, …, Xn – неслучайные величины. (2.5)
При выборе вида функцииf в (2.2) обычно руководствуются следующими рекомендациями:
§ используется априорная информация о содержательной экономической сущности анализируемой зависимости – аналитический способ,
§ предварительный анализ зависимости с помощью визуализации – графический способ,
§ использование различных статистических приемов обработки исходных данных и экспериментальных расчетов.
Введение... В последнее время специалисты обладающие знаниями и навыками проведения прикладного экономического анализа с...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ:
Постановка задачи регрессии
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
Области применения эконометрических моделей
Области применения эконометрических моделей напрямую связаны с целями эконометрического моделирования, основными из которых являются:
1) прогноз экономических и социально-экономичес
Парная регрессия и метод наименьших квадратов
Будем предполагать в рамках модели (2.2) линейную зависимость между двумя переменными Y и X. Т.е. имеем модель парной регрессии в виде:
Yi =a+
Оценка статистической значимости регрессии
Перейдем к вопросу о том, как отличить "хорошие" оценки МНК от "плохих". Конечно, предполагается, что существуют критерии качества рассчитанной линии регрессии.
Перечис
Интерпретация уравнения регрессии
Проанализируем, какую информацию дает нам оцененное уравнение регрессии (2.6), т.е. поставим вопрос об интерпретации (содержательном объяснении) коэффициентов уравнения.
Во-первых,
Предположения модели
Пусть мы располагаем выборочными наблюдениями над k переменными Yi и , j=1,..., k,
Методом наименьших квадратов
Применяя к (3.1) с учетом (3.2)-(3.5) МНК, получаем из необходимых условий минимизации функционала:
,
т.
Парная и частная корреляция в КЛММР
В случаях, когда имеется одна независимая и одна зависимая переменные, естественной мерой зависимости (в рамках линейного подхода) является выборочный (парный) коэффициент корреляции между ними.
И множественный коэффициент детерминации
Множественный коэффициент корреляции используется в качестве меры степени тесноты статистической связи между результирующим показателем (зависимой переменной) y и набором объясняющих
Оценка качества модели множественной регрессии
Проверка качества модели множественной регрессии может быть осуществлена с помощью дисперсионного анализа.
Как уже было отмечено (см. 2.5), сумма квадратов отклонений от среднего в выборке
Спецификация уравнения регрессии и ошибки спецификации
При построении эконометрической модели исследователь специфицирует составляющие ее соотношения, выбирает переменные, входящие в эти соотношения, а также определяет вид математическо
С гетероскедастичными остатками
Довольно часто при построении регрессии анализируемые объекты неоднородны, например, при исследовании структуры потребления домохозяйств естественно ожидать, что колебания в структуре будут выше дл
С автокорреляцией остатков
Вернемся еще раз к предположению (3.3). Из него, в частности, следует, что ковариации случайной ошибки для разных наблюдений равны нулю. Если к тому же случайные ошибки распределены нормально, то э
Фиктивные переменные. Тест Чоу
Факторы (объясняющие переменные), применяемые в задаче регрессии до сих пор, принимали значения из некоторого непрерывного интервала. Иногда может понадобиться ввести в модель переменные, значения
Специфика временных рядов
Часто исследователь имеет дело с данными в виде временных рядов.
Совокупность наблюдений анализируемой величины
Проверка гипотезы о существовании тренда
Для выявления факта наличия или отсутствия неслучайной составляющей f(t), то есть для проверки гипотезы о существовании тренда - Н0: Еy(t
Метод последовательных разностей
Часто при аналитическом выравнивании ряда используется модель тренда в виде полинома.
Для определения порядка аппроксимирующего полинома в этом случае выделения тренда широко используется
Аддитивная и мультипликативная модели временного ряда
Простейшим подходом к моделированию временных рядов, содержащих сезонные колебания, является построение аддитивной или мультипликативной моделей временного ряда.
Выбор одной из этих моделе
Тестирование стационарности временного ряда
Как было отмечено выше, стационарные временные ряды имеют следующие отличительные черты: значения ряда колеблются вокруг постоянного среднего значения с постоянной дисперсией, которая не зависит от
Библиографический список
1. Айвазян С.А., Мхитарян В.С. Прикладная статистика и основы эконометрики. Учебник для вузов. М.: ЮНИТИ, 1998. 1022 с.
2. Джонстон Дж. Эконометрические методы.- М.: Статис
Хотите получать на электронную почту самые свежие новости?
Подпишитесь на Нашу рассылку
Наша политика приватности обеспечивает 100% безопасность и анонимность Ваших E-Mail

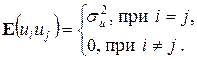






Новости и инфо для студентов