Лабораторная работа № 5
ПРИМЕНЕНИЕ ЭВМ ДЛЯ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ ДАННЫХ
1. Цель работы
Получение практических навыков составления программ для статистической обработки данных.
2. Исходные данные
Закон распределения случайной величины Y и параметры распределения принимаются по табл. 1 из лаб. работы № 4 в соответствии с номером варианта. Для получения псевдослучайных чисел X, равномерно распределенных в интервале [0, 1], использовать алгоритмы, схемы которых приведены на рис. 1 - 3 в лаб. работе № 4; варианты 1, 2, 3, 4, 14 - рис. 2; варианты 5, 6, 7, 8, 13 - рис. 3: варианты 9, 10, 11, 12 - рис. 1.
3. Содержание работы
3.1. Разработать алгоритм и программу, которые обеспечивают
- генерацию значений случайной величины Y;
- расчет оценок математического ожидания и среднего квадратического отклонения случайной величины на основании полученной выборки;
- получение интервального статистического ряда частот.
3.2. В соответствии с исходными данными получить и вывести на печать массивы из 50 и 200 псевдослучайных чисел, оценки математического ожидания и среднего квадратического отклонения, границы интервалов и интервальный статистический ряд частот.
4. Теоретические основы работы

Оценка математического ожидания случайной величины, представляющая собой среднее арифметическое, рассчитывается по формуле
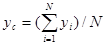 |
где
 - случайные значения ; N - объем выборки.
- случайные значения ; N - объем выборки.
Суммирование случайных значений целесообразно выполнять в процессе их генерации.
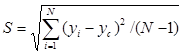 |
Расчет оценки среднего квадратического отклонения проводится по формуле
Случайные значения выбираются из массива, куда они предварительно записываются в процессе генерации.
Для получения интервального статистического ряда необходимо определить число интервалов К из выражения
К = trunc(1 + 3,2*lg(N)) + 1 ,
где trunc - означает операцию выделения целой части результата. Затем следует найти длину интервала
h = (ymax - ymin)/K ,
где - ymax и ymin - максимальное и минимальное значения выборки, которые целесообразно определить на этапе генерации случайных
чисел yi.
Далее вычисляются номера интервалов j, в которые попадают значения yi.
j = trunc((yi - ymin )/h) + 1 , i = 1,2,...N
Поскольку при использовании указанной формулы значению уmах соответствует интервал с номером К+1, необходимо проверять условие j<=K и при его невыполнении сделать присвоение j=K.
После нахождения номера интервала, в который попадает очередное значение yi, соответствующий счетчик числа попаданий в этот интервал увеличивается на единицу:
mj = mj + 1
В результате, после просмотра всех значений yi, получаем массив частот mj, j = 1, 2,...,К, который показывает распределение значений случайной величины по интервалам.
5. Содержание отчета
5.1. Цель работы
5.2. Исходные данные
5.3. Алгоритм расчета
5.4. Распечатка программы и результатов расчета
5.5. Выводы