Алгоритм построения иерархического разбиения (дендограмм) задач управления СОТС
Для построения иерархического разбиения множества задач А могут быть использованы методы [2, 4, 8]соединительного иерархического кластерного анализа, общий алгоритм которых может быть представлен в следующем виде:
Шаг 0. За исходное разбиение R0принять тривиальное разбиение множества задач A на n одноэлементных кластеров R0 ={Ai, i=1, 2, …,n}, где Ai={ai}. Положить начальный уровень разбиения l=0.
Шаг 1. Для заданного уровня разбиений lнайти наибольшее значение (в частности, целевого или функционального) сходства между кластерами
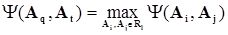 . Значение сходства определяется с использованием отображений соответственного целевого и функционального сходства g и f.
. Значение сходства определяется с использованием отображений соответственного целевого и функционального сходства g и f.
Шаг 2. Объединить соответствующие кластеры с наибольшим сходством в один кластер и образовать новое разбиение As=Aq È At. Положить l равное l+1.
Шаг 3. Проверить выполнение условия: card Rl=1 – мощность множества Rl(все задачи объединены в один кластер). Если оно выполняется, то завершить выполнение алгоритма. Если не выполняется, то перейти на шаг 4.
Шаг 4.Пересчитать значения сходства для кластеров нового разбиения по одной из приведенных ниже формул и перейти на шаг 1.
Пересчет значений сходства для кластеров нового разбиения можно осуществлять по следующим формулам, каждая из которых ассоциируется с названием соответствующего метода иерархического кластерного анализа:
1) метод ближайшего соседа (сильной связи):
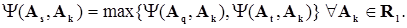
2) метод дальнего соседа (слабой связи):
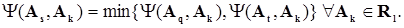
3) метод простого среднего (средней связи):
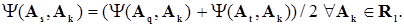
Для построения иерархического разбиения по целевому сходству Tgв качестве y используется отображение g, а по функциональному сходству Tf – отображение f.