Отношения процесса управления инцидентами с другими процессами
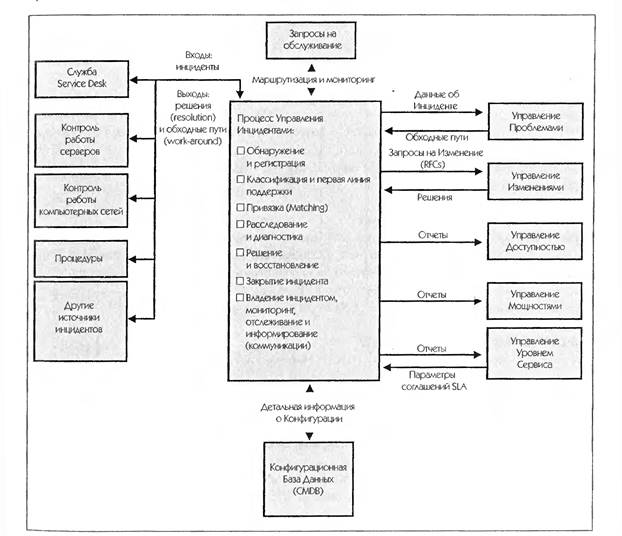
2.1. Управление Конфигурациями
Конфигурационная База Данных (Configuration Management Database — CMDB) играет важную роль в Управлении Инцидентами, так как она определяет связь между ресурсами, услугами, пользователями и Уровнями Услуг (сервисов). Например,
Ø более эффективное распределение инцидентов по группам специалистов. На основе данных CMDB о том, кто является ответственным за компонент инфраструктуры (КЭ),
Ø решение оперативных вопросов, например, перенаправление очереди печати или переключение пользователя на другой сервер.
Ø информация об источнике ошибки за счет того, что при регистрации инцидента в регистрационные данные добавляется связь (link) с соответствующей Конфигурационной Единицей (Configuration Item — CI).
2.2. Управление Проблемами
Ø Эффективное Управление Проблемами требует качественной регистрации инцидентов, что значительно облегчит поиск корневых причин.
Ø С другой стороны, Управление Проблемами помогает Процессу Управления Инцидентами, предоставляя информацию о проблемах, известных ошибках, обходных решениях и быстрых исправлениях'.
2.3. Управление Изменениями
Ø Инциденты могут быть решены путем внесения изменений, например, заменой монитора.
Ø Управление Изменениями предоставляет Процессу Управления Инцидентами информацию о запланированных изменениях и их статусах.
Ø Кроме того, изменения могут вызвать инциденты, если изменения произведены неправильно или содержат ошибки. Процесс Управления Изменениями получает информацию о них из Процесса Управления Инцидентами.
2.4. Управление Уровнем Услуг
Ø Сотрудники, участвующие в Управлении Инцидентами должны хорошо знать SLA, чтобы использовать необходимую информацию при контактах с пользователями.
Ø Регистрационные данные об инцидентах требуются при составлении отчетов для проверки выполнения согласованного Уровня Услуг.
2.5. Управление Доступностью
Ø Для определения показателей доступности услуг Процесс Управления Доступностью использует регистрационные данные об инцидентах.
2.6. Управление Мощностями
Ø Процесс Управления Мощностями получает информацию об инцидентах, связанных с функционированием самих ИТ-систем, например, инцидентах, произошедших в связи с недостатком дискового пространства или медленной скоростью реакции и т. д.
Ø В свою очередь, информация об этих инцидентах может поступать в Процесс Управления Инцидентами от системною администратора или от самой системы на основе мониторинга своего состояния.
3. 3. Схема процесса (основные стадии и задачи)
3.1. Входы процесса
Инциденты могут возникнуть в любой части инфраструктуры:
Ø Пользователи
Ø Сотрудники других отделов
Ø Автоматические системы управления, настроенные на регистрацию событии в приложениях и технической инфраструктуре.
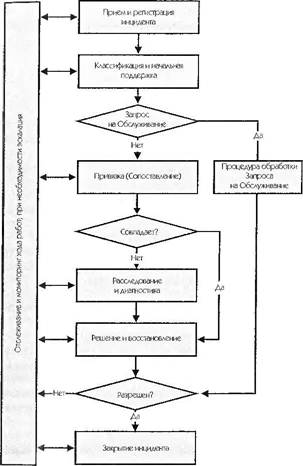
3.2. Прием и регистрация инцидента (Acceptance and Recording)
— принимается сообщение и создается запись об инциденте.
Инциденты могут быть обнаружены следующим образом:
ü Обнаружен пользователем: он докладывает об инциденте в Службу Service Desk.
ü Обнаружен системой: при обнаружении события в приложении или технической инфраструктуре, например, при превышении критического порога, событие регистрируется как инцидент в системе регистрации инцидентов и, при необходимости, направляется в группу поддержки.
ü Обнаружен сотрудником Службы Service Desk: сотрудник производит регистрацию инцидента.
ü Обнаружен кем-либо в другом подразделении ИТ: этот специалист регистрирует инцидент в системе регистрации инцидентов или докладывает о нем в Службу Service Desk.
Необходимо избегать двойной регистрации одного инцидента. Поэтому при регистрации инцидента следует проверить, нет ли аналогичных открытых инцидентов.
При регистрации инцидента производятся следующие действия:
Назначение номера инцидента: в большинстве случаев система автоматически назначает новый (уникальный) номер инцидента. Часто этот номер сообщается пользователю, чтобы он мог ссылаться на него при дальнейших контактах.
Запись базовой диагностической информации: время, признаки (симптомы), пользователь, сотрудник, принявший вопрос в обработку, место произошедшего инцидента и информация о затронутой услуге и/или технических средствах.
Запись дополнительной информации об инциденте: добавляется информация, например, из скрипта (script) или процедуры опроса или из Конфигурационной Вазы Данных — CMDB (обычно на основе взаимоотношений Конфигурационных Единиц, определенных в CMDB).
Объявление сигнала тревоги: если происходит инцидент, имеющий высокую степень воздействия, например, сбой важного сервера, производится предупреждение других пользователей и руководства.
3.3. Классификация и начальная поддержка (Classification and Initial support)
— присваиваются тип, статус, степень воздействия, срочность, приоритет инцидента, SLA и т. п. Пользователю может быть предложено возможное решение, даже если оно только временное.
Категория
Прежде всего, инцидентам присваивается категория и подкатегория, например, исходя из предполагаемого источника инцидента или соответствующей группы поддержки:
Центральная процессинговая система — подсистема доступа, центральный сервер, приложение.
Сеть — маршрутизаторы, сегменты, концентратор (hub), IP-адреса.
Рабочая станция — монитор, сетевая карта, дисковод, клавиатура.
Использование и функциональность — услуга (сервис), возможности системы, доступность, резервное копирование (back-up), документация.
Организация и процедуры — заказ, запрос, поддержка, оповещение (коммуникации).
Запрос на Обслуживание — запрос пользователя в Службу Service Desk на поддержку, предоставление информации, документации или оказание консультации. Это может быть выделено в отдельную процедуру или обработано таким же образом, как реальный инцидент.
Приоритет
После этого назначается приоритет, чтобы быть уверенными, что группа поддержки уделит инциденту необходимое внимание. Приоритет — это номер, определяющийся срочностью (насколько быстро это должно быть исправлено) и степенью воздействия (какой ущерб будет нанесен, если не исправить быстро).
Приоритет = Срочность х Степень воздействия. Услуги (сервисы)
Для определения услуг, подвергшихся воздействию инцидента, может быть использован перечень существующих договоренностей (соглашений) об Уровне Услуг — SLA. Этот перечень позволит также установить время эскалации для каждой из услуг, определенных в SLA.
Группа поддержки.
Ø Если Служба Service Desk не может разрешить инцидент незамедлительно, то определяется группа поддержки, которая будет заниматься разрешением инцидента.
Ø Основой для распределения (маршрутизации) инцидентов часто является информация о категориях..
Ø Правильное распределение инцидентов имеет существенное значение для эффективности Процесса Управления Инцидентами. Поэтому одним из ключевых показателей эффективности' (KPI) Процесса Управления Инцидентами может быть число неправильно распределенных обращений.
Сроки решения
С учетом приоритета и соглашения SLA пользователь информируется о максимальном расчетном времени разрешения инцидента. Эти сроки также фиксируются в системе.
Идентификационный номер инцидента
Абонент информируется о номере инцидента для его точной идентификации при последующих обращениях.
Статус
Статус инцидента указывает на его положение в процессе обработки инцидента. Примерами статусов могут быть:
• новый;
• принят;
• запланирован;
• назначен;
• активный;
• отложен;
• разрешен;
• закрыт.
Ø Если вызов касается Запроса на Обслуживание (Service Request), то инициируется соответствующая процедура.