Табличный метод определения истинностных значений логических форм сложных суждений
Мы научились выявлять логическую форму и простых, и сложных суждений. Она записывается в логическом языке в виде формул этого языка. К примеру, формула «┐ (Все S есть P)» является символической записью логической формы суждения «Неверно, что все водоплавающие дышат жабрами», а формула (х ┐у) – сложного суждения «Иванов – соучастник данного преступления, но не является его инициатором».
┐у) – сложного суждения «Иванов – соучастник данного преступления, но не является его инициатором».
Для целей установления логических отношений между формулами сложных суждений (а, значит, и между самими суждениями) нам необходимо овладеть табличным методом определения их истинностных значений. Возьмем для примера формулу х┐у. Строим «вход» и «шапку» таблицы.
1 этап:
| х | у | х┐у
|
| и | и | |
| и | л | |
| л | и | |
| л | л |
Левая часть таблицы («вход») содержит все возможные варианты распределения истинностных значений переменных х и у, входящих в данную формулу. Этих вариантов всего четыре: они могут быть обе истинны; х - истинно, а у – ложно; х –ложно, а у –истинно; они могут быть обе ложными. Сама формула является сложной, состоит из двух подформул. Общая структура этой формулы XY, где X – это х, а Y - ┐у. Подформула Y, в свою очередь, является сложной формулой ┐y. На втором этапе нашей вычислительной процедуры выпишем (в правой части таблицы) «столбцы» распределения истинностных значений переменных (как они заданы во входе таблицы) строго под этими переменными. Получаем:
2 этап:
| x | y | х |
| ┐у |
| и | и | и | и | |
| и | л | и | л | |
| л | и | л | и | |
| л | л | л | л | |
| (1) | (2) |
Поскольку левая подформула X всей формулы XY – это переменная x, то столбец под ней и будет распределением истинностных значений переменной x. Вычисление подформулы Y выписыванием столбца под переменной у еще не завершено. Как мы помним, эта подформула - тоже сложная формула вида ┐y. По таблице истинности для отрицания (раздел 3.4) выстраиваем столбец истинностных значений для этой подформулы (строго под знаком «┐»):
3 этап:
| x | y | х |
| ┐ | у |
| и | и | и | л | и | |
| и | л | и | и | л | |
| л | и | л | л | и | |
| л | л | л | и | л | |
| (3) |
Теперь, построив столбцы истинностных значений для подформул X и Y, выстраиваем столбец для всей конъюнктивной формулы XY (см. раздел 3.4):
4 этап:
| x | y | х | 
| ┐ | у |
| и | и | и | л | л | и |
| и | л | и | и | и | л |
| л | и | л | л | л | и |
| л | л | л | л | и | л |
| (4) |
Определение истинностного значения формулы х┐у завершено. В результирующем столбце нашей таблицы (4), как можно убедиться, присутствует как значение «истина», так и значение «ложь».
В дальнейшем нам не потребуется выстраивать каждый этап таблицы отдельно: просто мы будем указывать последовательность этих этапов в единой таблице.
Теперь определим истинностные значения формулы (ху)→z. Выделим две основные части этой формулы: ху и z.
Схема всей формулы такова: X→Y. Поэтому последний (результирующий) столбец таблицы будет выстраиваться под импликацией. Предпоследний столбец построим под конъюнкцией , определив тем самым истинностные значения подформулы X. Наконец, первые три столбца разместим под переменными x, y и z. Получаем:
| x | y | z | (x |
| y) | → | z |
| и | и | и | и | и | и | и | и |
| и | и | л | и | и | и | л | л |
| и | л | и | и | л | л | и | и |
| и | л | л | и | л | л | и | л |
| л | и | и | л | л | и | и | и |
| л | и | л | л | л | и | и | л |
| л | л | и | л | л | л | и | и |
| л | л | л | л | л | л | и | л |
| (1) | (4) | (2) | (5) | (3) |
Как видно из этого примера, чтобы точнее представить структуру формулы логического языка, удобно использовать скобки. Они (как в обычной алгебре) играют роль своеобразных знаков препинания, применяемых для указания последовательности построения столбцов истинностных значений. Следует также помнить, что знак «┐» связывает теснее, чем знаки «», «v», «→» и « ≡ »; знак «» - теснее, чем «v», «→» и « ≡ »; знак «v» теснее, чем «→» и « ≡ »; знак «→» - теснее, чем « ≡ » (сначала «вычисляется» формула, в которой главный логический знак «связывает теснее»). При чтении формула должна быть названа именем той логической константы, которая определяет общую структуру всей формулы.
Сравним следующие две формулы:
1. ((x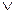 y)┐y)→(x→y)
y)┐y)→(x→y)
2. ((x(y┐y)) →x)→y
Они содержат одни и те же переменные и одни и те же логические константы, которые входят в них в той же последовательности. Но логический смысл этих формул различен, поскольку скобки расставлены разными способами. Хотя обе они – импликативные, то есть имеют общий вид X→Y, однако, основание (X) первой формулы составляет конъюнктивная подформула ((xy)┐y), а основание второй - импликативная подформула ((x(y┐y))→x); следствие (Y) первой составляет импликативная подформула x→y, а следствие второй – переменная y.
Обратим внимание, что в таблице истинностных значений формулы (ху)→z, построенной ранее, содержатся не четыре строки, как в предшествующей ей (для формулы x┐y), а восемь. Вообще число строк в таблице зависит от количества переменных, входящих в формулу: если их две, то строк будет четыре, если три, то восемь, если четыре – то 16 и т.п. Словом, оно равно числу 2ⁿ, где n – число попарно различных переменных. Далее, выписывая столбцом все возможные значения для каждой переменной, удобно воспользоваться следующим алгоритмом: начинаем с последней (крайней справа) чередованием «истина» и «ложь» через строку. Для следующей (слева от предыдущей) – чередование идет уже через две строки, а для идущей за ней переменной – через четыре строки и т.п. Такой алгоритм позволяет гарантированно «перебрать» все возможные варианты сочетаний истинностных значений переменных: не пропустить ни одного и не допустить повторов.
Построим таблицы истинности еще для двух формул: ((х→у)х)→у и (х≡у)(х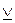 у):
у):
| х | у | ((х | → | у) |
| х) | → | у | (х | ≡ | у) |
| (х |
| у) |
| и | и | * | * | * | и | * | и | и | * | и | * | л | * | л | * |
| и | л | * | * | * | л | * | и | л | * | л | * | л | * | и | * |
| л | и | * | * | * | л | * | и | и | * | л | * | л | * | и | * |
| л | л | * | * | * | л | * | и | л | * | и | * | л | * | л | * |
| (1) | (5) | (2) | (6) | (3) | (7) | (4) | (1) | (5) | (2) | (7) | (3) | (6) | (4) |
Столбцы 1, 2, 3, 5 в первой таблице и столбцы 1- 4 во второй мы оставляем незаполненными (предоставим возможность эту процедуру выполнить самому читателю). Заполнены только столбцы для основных подформул (столбцы 4 и 6 в первой таблице и столбцы 5 и 6 – во второй) и для формул в целом (столбцы под номером 7, выделенные рамкой), то есть результирующие столбцы. Особенность формулы ((х→у)х)→у состоит в том, что в ее результирующем столбце в каждой строке стоит значение «и». В то же время, в результирующем столбце формулы (х≡у)(ху) во всех строках стоит значение «л». Отметим в этой связи следующее. Формула, в каждой строке результирующего столбца которой стоит «и», является тождественно-истинной формулой, то есть законом логики. Формула, в каждой строке результирующего столбца которой стоит «л», является тождественно-ложной, то есть логическим противоречием. Формула, в результирующем столбце которой есть и значение «и», и значение «л», называют выполнимой (см. формулу (х→у)х)).