Выбор факторов
При выборе факторов нужно выполнять следующие требования:
1) фактор должен быть регулируемым, т. е. с помощью определенного регулирующего устройства фактор можно изменять от значения x1 до значения x2.
2) точность измерения и управления факторов должна быть известна и достаточно высока (хотя бы на порядок выше точности измерения выходной переменной); очевидно, что низкая точность измерения факторов уменьшает возможности воспроизведения эксперимента.
К факторам и переменным состояния одновременно также предъявляется ряд требований:
1) факторы и переменные состояния должны иметь области определения, заданные технологическими или принципиальными ограничениями (пример технологического ограничения — максимальная производительность компрессора, подающего газ в реактор;
пример принципиального ограничения — температура кристаллизации жидкого продукта, образующегося в результате реакции);
области определения факторов должны быть таковы, чтобы при различных их комбинациях переменные состояния не выходили свои ограничения;
2) между факторами и переменными состояниями должно существовать однозначное соответствие; оно позволит в основном эксперименте построить математическую модель объекта исследования и решить поставленную задачу эксперимента.
Выделение значимых факторов осуществляется в ходе так называемой отсеивающего эксперимента. Число опытов в нем может быть больше, равно или меньше числа проверяемых факторов. Планы, отвечающие таким экспериментам, называют соответственно ненасыщенными, насыщенными или сверхнасыщенными.
Ненасыщенные планы используют, если предварительному исследованию подлежат сравнительно небольшое число факторов (т < 6 - 7) и их возможные взаимодействия. Эффект взаимодействие двух или несколько факторов проявляется при одновременном их варьировании, когда влияние каждого фактора на отклик зависит от уровней, на которых находятся др. факторы. Ненасыщенные планы обычно включают значительной число опытов и поэтому достаточно трудоемки. В качестве таких планов часто применяют планы так называемой полного факторного эксперимента (ПФЭ), в котором каждый фактор изменяется одинаковое число раз q (где q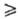 2-число выбранных уровней); при этом реализуются все возможные опыты, различающиеся значением хотя бы одного фактора. Число опытов в ПФЭ n = qm: например, для m = 2 и q = 2 число n = 22 = 4 опыта.
2-число выбранных уровней); при этом реализуются все возможные опыты, различающиеся значением хотя бы одного фактора. Число опытов в ПФЭ n = qm: например, для m = 2 и q = 2 число n = 22 = 4 опыта.
Условия проведения опытов может быть представлены в графич. (рис. 1) или табличной (см. табл.) форме. В последнем случае первый столбец (i-номер опыта) и совокупность значений факторов (второй и третий столбцы) образуют так называемой матрицу плана ПФЭ, к которой предъявляют следующей требования: 1) сумма элементов столбца каждого фактора равна нулю:
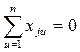
(u-текущий номер опыта);
2) сумма квадратов элементов столбца каждого фактора равна числу опытов:
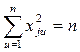
3)сумма почленных произведений любых столбцов двух любых факторов равна нулю:
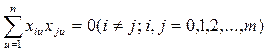
| i | Кодированные переменные | Отклик y | |
| x1 | x2 | ||
| -1 | + 1 | y1 | |
| - 1 | - 1 | y2 | |
| + 1 | + 1 | y3 | |
| + 1 | -1 | y4 |
Значения физических переменных, соответствующие матрице, выбранной для реализации опытов, рассчитывают по формуле:
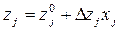
При числе опытов в ПФЭ, значительно превышающем число определяемых параметров модели, применяют так называемой дробные реплики (или дробный факторный эксперимент -ДФЭ), которые представляют собой часть плана ПФЭ. ДФЭ может содержать половину, четверть и т.д. опытов от ПФЭ. Соотв. различают полуреплики (qm-1), четвертьреплики (qm-2) и т. п. В общем случае ДФЭ может быть обозначен как qm-l, где l-дробность реплики. К матрице ДФЭ предъяв ляют те же требования, что и к матрице ПФЭ. Планы, полученные с использованием ПФЭ или его дробных реплик, в которых переменные варьируются на двух уровнях, называют линейными либо планами 1-го порядка, так как при их применении можно построить уравнение модели, включающее исследуемые факторы лишь в 1-й степени.
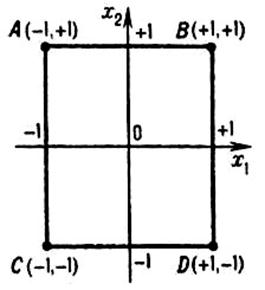
Рис. 30. Расположение точек в факторном пространстве в случае ПФЭ 22. Цифры около точек A, B, C, D характеризуют в кодированных переменных условиях проведения опытов.
Насыщенные планы используют, если математическая модель предполагается в виде полинома (уравнения регрессии) 1-го порядка, общий вид которого может быть представлен выражением:
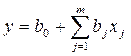 ,
,
где y-отклик, b0 и bj-параметры модели. В качестве насыщенных планов наиболее часто применяют планы ДФЭ.
Алгоритм выделения значимых факторов в этом случае включает следующие этапы:
1) по формуле определяют параметры мат. модели.
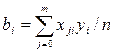
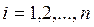
2) По результатам параллельных опытов вычисляют дисперсию воспроизводимости, характеризующую разброс значений отклика. Например, при проведении r параллельных опытов в одной точке факторного пространства:
 ,
,
 где
где
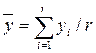
3)По формуле определяют дисперсию каждого параметра.
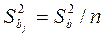
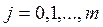
4) Для оценки точности найденных значений параметров, а также полученной мат. модели используют статистические критерии соответственно Стьюдента (t-критерий) и Фишера (F-критерий). При этом количественное мерами служат так называемой доверительная вероятность α или уровень значимости p= 1 — α и число степеней свободы f, т. е. число экспериментов за вычетом числа констант, рассчитываемых по результатам этих опытов. Число констант определяется видом выбранной дисперсии; например, в случае дисперсии воспроизводимости по результатам параллельных опытов находят величину 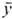 , поэтому fb = r — 1. При заданных требованиях на точность результатов измерений доверительная вероятность (уровень значимости) определяет надежность полученной оценки. Значения указанных критериев табулированы и приводятся в спец. литературе.
, поэтому fb = r — 1. При заданных требованиях на точность результатов измерений доверительная вероятность (уровень значимости) определяет надежность полученной оценки. Значения указанных критериев табулированы и приводятся в спец. литературе.
5) Значимость каждого фактора проверяют оценкой значимости соответствующего параметра, так как вклады факторов в значение отклика пропорциональны значениям параметров. Для оценки их значимости рассчитывают соответствующее значение t-критерия по формуле:
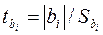
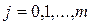
Полученное значение сравнивают с табличным tT, найденным на предыдущем этапе. При выбранной доверительной вероятности параметр считается значимым, если tbi. > tT. В противном случае параметр незначим и соответствующий фактор можно исключить из построенной мат. модели.
Сверхнасыщенные планы используют, если на процесс может влиять большое число факторов и их взаимодействий. Наиболее часто с целью уменьшения их числа применяют метод случайного баланса, позволяющий вместо ПФЭ и ДФЭ применять эксперименты, в которых значения факторов распределены по уровням случайным образом (рандомизированы). Метод имеет высокую разрешающую способность (возможность выделять сильно влияющие факторы), но малую чувствительность (т. е. способность выделять значимые параметры модели, характеризующие факторы, которые имеют относительно слабое влияние). Используют также метод последовательного отсеивания: все изучаемые факторы на основе априорной информации подразделяют на группы, каждую из которых в дальнейшем рассматривают как отдельный комплексный фактор. В зависимости от полученной при этом информации остальные факторы снова разбивают на группы и выполняют новый цикл расчетов.
Планы отсеивающего эксперимента
Эти планы используются на стадии предварительных исследований для выделения существенных эффектов факторов. В этом классе различают следующие планы.
Насыщенные планы Плакетта и Бермана, представляющие собой двухуровневые планы, образованные методом циклических сдвигов. Число опытов в планах равно числу исследуемых эффектов.
Сверхнасыщенные планы случайного баланса в зависимости от числа уровней варьирования могут быть двух- и многоуровневыми. По методу построения эти планы могут быть образованы случайным образом (например, из строк факторного эксперимента типа 2* с помощью таблиц случайных чисел). Систематически отобранные планы обеспечивают минимальные корреляции между столбцами плана (планы Бут и Кокса и др. ). При случайном балансе результаты эксперимента представляются в виде модели
 ,
,
где p – число значимых эффектов, l – p число отсеиваемых незначимых эффектов, ε – случайная ошибка, N<l (при p<N) - число опытов плана.
Планы последовательного отсеивания. При последовательном отсеивании, используемом в отличие от двух вышеописанных типов планов, для задач большой размерности (число факторов до 100 и выше) все факторы на основе априорной информации делятся на группы, каждая из которых рассматривается далее как отдельный комплексный фактор. Эти группы — комплексные факторы, которые содержат только незначимые переменные, исключаются из рассмотрения после первого цикла опытов (первой проверки). Оставшиеся факторы вновь делятся на группы для проверки, и цикл опытов повторяется. Такая процедура проводится до выявления всех значимых эффектов. В процессе отсеивания комбинирование и разделение переменных по группам проводится с помощью комбинаторных планов типа BIB-PBIB-схем, латинских квадратов и др.
После каждого цикла опытов получается новая информация, позволяющая выбрать оптимальные планы для реализации очередного цикла. В простейшем случае при последовательном отсеивании используется линейная модель аддитивного типа
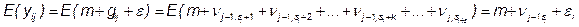
где 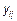 - результат эксперимента в j-й подгруппе и i-м цикле с-циклового эксперимента, m- общее среднее,
- результат эксперимента в j-й подгруппе и i-м цикле с-циклового эксперимента, m- общее среднее, 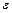 - ошибка эксперимента,
- ошибка эксперимента, 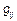 - комбинированный эффект от
- комбинированный эффект от  - переменных, включенных в модель. Предполагается, что только k-й из этих переменных в подгруппе значит, т.е. имеется эффект
- переменных, включенных в модель. Предполагается, что только k-й из этих переменных в подгруппе значит, т.е. имеется эффект 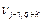 , который больше ошибки или комбинации всех остальных
, который больше ошибки или комбинации всех остальных 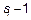 незначительных переменных. Если это так, то вся группа должна быть полностью пересмотрена в следующем
незначительных переменных. Если это так, то вся группа должна быть полностью пересмотрена в следующем 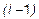 -м цикле. Если
-м цикле. Если  , то подгруппа , содержащая незначимые переменные, исключается из рассмотрения и далее следует -й цикл.
, то подгруппа , содержащая незначимые переменные, исключается из рассмотрения и далее следует -й цикл.
В более сложных случаях в модель включают эффекты взаимодействий факторов [5,6].