рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Основні операції над деревами
Реферат Курсовая Конспект
Основні операції над деревами
Основні операції над деревами - раздел Образование, Графи P Над Деревами Визначені Наступні Основні Операції: - Обхід Дерева У В...
Над деревами визначені наступні основні операції:
- обхід дерева у визначеному порядку,
- пошук вузла з заданим ключем,
- додавання нового вузла,
- видалення вузла ( поддерева ).
ОБХІД ДЕРЕВА. У багатьох задачах, зв'язаних з деревами, потрібно здійснити систематичний перегляд усіх його вузлів у визначеному порядку. Такий перегляд називається обходом дерева.
Бінарне дерево можна обходити трьома основними способами: спадним (від кореневої вершини вниз), змішаним (від самого лівого листа дерева через корінь до самого правого листа) і висхідним (від листів нагору до кореня). Можливі також зворотні спадні, зворотні змішані і зворотний висхідні обходи.
Схематично алгоритм обходу двоічного дерева відповідно до спадного способу може виглядати в такий спосіб:
1). Узяти корінь дерева.
2). Виконати обробку чергової вершини відповідно до вимог задачі.
3. а). Якщо чергова вершина має дві вітки, то як нову вершину вибрати ту вершину, на яку посилається ліва вітка, а вершину, на яку посилається права вітка, занести в стек; перейти до пункту 2.
3. б). Якщо чергова вершина є кінцевою, то вибрати в якості нової чергової вершини вершину зі стека, якщо він не порожній, і перейти до пункту 2; якщо ж стік порожній, те це означає, що обхід усього дерева закінчено.
3. в). Якщо чергова вершина має тільки одну вітку, то як чергову вершину вибрати ту вершину, на яку ця вітка указує, перейти до пункту 2.

При обході дерева представленого на рис.7.31 цими трьома методами одержимо наступні послідовності:
ABCDEFG ( спадний );
CBAFEDG ( змішаний );
CBFEGDA ( висхідний ).
Рис.7.31. Схема дерева
СПАДНИЙ ОБХІД (Preorder, r_Preorder). Текст процедури відповідно до алгоритму, приведеному вище, подано в програмному прикладі 7.5.
{===== Програмний приклад 7.5 =======}
Procedure Preorder (t: TreePtr); {=== Спадний обхід ===}
Type Stack=^Zveno;
Zveno = record
next: Stack;
el: pointer; end;
Var st:stack; p:TreePtr;
Procedure Push_st (var st:stack; p:pointer); (* Процедура занесення в стек покажчика -*)
Var q: stack;
begin new(q); q^.el:=p; q^.next:=st; st:=g; end;
Function Pop_st(var st:stack):pointer; {Bитяг зі стека покажчика}
Var e,p: stack;
begin Pop_st:=st^.el; e:=st; st:=st^.next; dispose(e); end;
Begin
if t = NIL then
begin writeln('Дерево порожнє'); exit; end
else begin st:=nil; Push_st(St,t); end;
while st <> nil do { контроль заповнення стека }
begin p:=Pop_st(st);
while p <> nil do
begin { Обробка даних ланки }
if p^.right <> nil
then Push_st(st,p^.right);
p:=p^.left;
end; end;
End; { Preorder }
Трасування спадного обходу приведено у табл.7.1.
Таблиця 7.1

@ вузла @ вузол обробка вихідна
у стеці покажчика вузла рядок
p:=pt A A A
D RPA D
 LPA B B AB
LPA B B AB
RPB=nil
LPB C C ABC
RPC=nil
LPC=nil
D D D ABCD
G RPD G
LPD E E ABCDE
RPE=nil
LPE F F ABCDEF
RPF=nil
LPF=nil
G G G ABCDEFG
RPG=nil
LPG=nil Стек порожній. Кінець алгоритму.
РЕКУРСИВНИЙ СПАДНИЙ ОБХІД. Алгоритм істотно спрощується при використанні рекурсії. Спадний обхід можна описати в такий спосіб:
1). Обробка кореневої вершини;
2). Спадний обхід лівого поддерева;
3). Спадний обхід правого поддерева.
Рекурсивна процедура спадного обходу дана в програмному прикладі 7.6.
{===== Програмний приклад 7.6 =======}
Procedure r_Preorder (t: TreePtr);
begin
if t = nil then begin writeln('Дерево порожнє'); exit; end;
if t^.left <> nil then r_Preorder(t^.left); (* Обробка даних ланки --*)
if t^.right <> nil then r_Preorder(t^.right);
End; { r_Preorder }
ЗМІШАНИЙ ОБХІД (Inorder, r_Inorder). Змішаний обхід можна описати в такий спосіб:
1). Спуститися по лівій вітки з запам'ятовуванням вершин у стеці;
2). Якщо стік порожній - кінець;
3). Вибрати вершину зі стека й обробити дані вершини;
4). Якщо вершина має правого сина, то перейти до нього; перей ти до п.1.
Процедура змішаного обходу подана в програмному прикладі 7.7.
{===== Програмний приклад 7.7 =======}
Procedure Inorder (t: TreePtr);
label 1;
type Stack=^Zveno; { тип стека }
Zveno = record
next: Stack;
El: pointer; end;
Var
st: stack; p: TreePtr;
Procedure Push_st (var st:stack; p:pointer);
Var q: stack;
begin new(q); q^.el:=p; q^.next:=st; st:=g; end;
Function Pop_st (var st: stack):pointer;
Var e,p: stack;
begin Pop_st:=st^.el; e:=st; st:=st^.next; dispose(e); end;
Begin
if t = NIL then begin writeln('Дерево порожнє'); exit; end
else begin p:=t; st:=nil; end;
1: while p^.left <> nil do
begin {Спуск по лівій галузі і заповнення черги}
Push_st(st,p); p:=p^.left; end;
if st = NIL { контроль заповнення стека }
then exit;
p:=Pop_st(st); {вибірка чергового елемента на обробку}
if p^.right <> nil {---- Обробка даних ланки -----}
then begin p:=p^.right; { перехід до правої вітки }
goto 1; end;
End; { Inorder }
Трасування змішаного обходу наведено в таблиці 7.2.
Таблиця 7.2
 |
@ вузла @ вузол обробка вихідна
у стеці покажчика вузла рядок
 |
 B LPA B
B LPA B
C LPB C
LPC=nil
C C C C
RPC=nil
B B B CB
RPB=nil
A A A CBA
D RPA D
E LPD E
F LPE F
LPF=nil
F F F CBAF
RPF=nil
E E E CBAFE
RPE=nil
D D D CBAFED
G
RPG LPG=nil
G G G CBAFEDG
RPG=nil Стік порожній. Кінець алгоритму.
Рекурсивний змішаний обхід описується в такий спосіб:
1). Змішаний обхід лівого поддерева.
2). Обробка кореневої вершини.
3). Змішаний обхід правого поддерева.
Рекурсивне виконання змішаного обходу:
{===== Програмний приклад 7.8 =======}
Procedure r_Inorder(t: TreePtr);
begin
if t = nil then
begin writeln('Дерево порожнє'); exit; end;
if t^.left <> nil then R_inorder (t^.left);
{ Обробка даних ланки }
if t^.right<>nil then R_inorder(t^.right);
End;
ВИСХІДНИЙ ОБХІД (Postorder, r_Postorder). Труднощі полягають у тім, що на відміну від Preorder у цьому алгоритмі кожна вершина запам'ятовується в стеці двічі: перший раз - коли обходиться ліве поддерево, і другий раз - коли обходиться праве поддерево.
Таким чином, в алгоритмі необхідно розрізняти два види стековых записів: 1-й означає, що в даний момент обходиться ліве поддерево; 2-й - що обходиться праве, тому в стеці запам'ятовується ще покажчик на вузол і ознаку (код-1 і код-2 відповідно).
Алгоритм висхідного обходу можна представити в такий спосіб:
1). Спуститися по лівій вітки з запам'ятовуванням вершини в стеці як 1-й вид стековых записів.
2). Якщо стік порожній, те – кінець.
3). Вибрати вершину зі стека, якщо це перший вид стековых записів, то повернути його в стек як 2-й вид стековых записів; перейти до правого сина; перейти до п.1, інакше перейти до п.4.
4). Обробити дані вершини і перейти до п.2.
Процедура висхідного обходу подана в програмному прикладі 7.9.
{===== Програмний приклад 7.9 =======}
Procedure Postorder (t: TreePtr)
label 2;
Var
p: TreePtr; top: point; { стековый тип }
Sign: byte; {sign=1(2)-перший (другий) вид стековых записів}
Begin
if t = nil then
begin writeln('Дерево порожнє'); exit; end
else begin p:=t; top:=nil; end; {ініціалізація стека}
{Запам'ятовування адрес уздовж лівої вітки}
2: while p <> nil do
begin s_Push(top,1,p); { заноситься покажчик 1-го виду}
p:=p^.left; end;
{Підйом нагору по дереву з обробкою правих віток}
while top <> nil do
begin p:=s_Pop(top,sign); if sign = 1 then
begin s_Push(top,0,p);{заноситься покажчик 2-го виду }
p:=p^.right; goto 2; end
else {Обробка даних ланки }
end; End; { Postorder }
РЕКУРСИВНИЙ ЗМІШАНИЙ ОБХІД описується в такий спосіб:
1). Висхідний обхід лівого поддерева.
2). Висхідний обхід правого поддерева.
3). Обробка кореневої вершини.
Текст процедури подано в програмному прикладі 7.10.
{===== Програмний приклад 7.10 =======}
Procedure r_Postorder (t: TreePtr);
Begin
if t=nil then begin writeln('Дерево порожнє'); exit; end;
if t^.left <> nil then r_Postorder (t^.left);
if t^.right <> nil then r_Postorder (t^.right);
{Обробка даних ланки }
End; { r_Postorder }
Якщо в розглянутих вище процедурах поміняти місцями поля left і right, то одержимо процедури зворотних спадних, зворотних змішаних і зворотного висхідних обходів.
ПРОШИВАННЯ БІНАРНИХ ДЕРЕВ. Під прошиванням дерева розуміється заміна за визначеним правилом порожніх покажчиків на синів покажчиками на наступні вузли, що відповідають обходові. Розглядаючи бінарне дерево, легко знайти, що в ньому є багато покажчиків типу NIL. Дійсно, дерево з N вершинами має (N+1) покажчиків типу NIL. Цей незайнятий простір можна використовувати для зміни представлення дерев. Порожні покажчики заміняються покажчиками - "нитками", які адресують вершини дерева, що розташовані вище. При цьому дерево прошивається з урахуванням визначеного способу обходу. Наприклад, якщо поле left деякої вершини P має значення NIL, то його можна замінити на адресу, що вказує на попередника P, відповідно до того порядку обходу, для якого прошивається дерево. Аналогічно, якщо поле right порожньє, то вказується спадкоємець P відповідно до порядку обходу. Оскільки після прошивання дерева поля left і right можуть характеризувати або структурні зв'язки, або "нитки", виникає необхідність розрізняти них, для цього вводяться в опис структури дерева характеристики лівого і правого покажчиків (FALSE і TRUE).
Таким чином, для прошитих дерев операція обходу виконується швидше і при цьому не вимагається додаткова пам'ять для стеку, однак вимагається додаткова пам'ять для збереження прапорів ниток, а також ускладнені операції включення і видалення елементів дерева. Прошите бінарне дерево на Паскалі можна описати в такий спосіб:
type TreePtr:=^S_Tree;
S_Tree = record
key: KeyType; { ключ }
left,right: TreePtr; { лівий і правий сини }
lf,rf: boolean; { характеристики зв'язків }
end;
де lf і rf - указують, зв'язок є покажчиком на елемент або ниткою.
Машинне представлення дерева, що подано на рис. 7.31, при спадному обході з прошиванням приведене на рис. 7. 32.
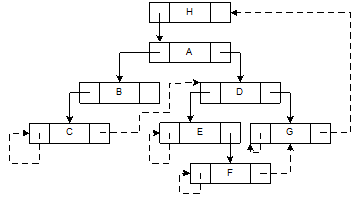
Рис. 7.32. Машинне зв'язне представлення дерева
при спадному обході з прошиванням
Таким чином, як що дерево не підлягає редагуванню, має сенс для прискорення операцій таке дерево прошивати.
ПОШУК ВУЗЛА З ЗАДАНИМ КЛЮЧЕМ.Операцію розглянуто на прикладі дерева пошуку. У такому дереві, щоб знайти потрібний ключ, досить, почавши з кореня, рухатися по лівому або правому піддереві на підставі лише одного порівняння з ключем поточної вершини. Оскільки пошук йде по одному-єдиному шляху від кореня до бажаної вершини, то його можна просто програмувати за допомогою ітерації.
Нехай є дерево і потрібно знайти вузол з ключем key. В програмному прикладі 7.11 спочатку порівнюється з key ключ, що знаходиться в корені дерева. У випадку рівності пошук закінчено. У противному випадку - перехід до розгляду вершини, що знаходиться ліворуч унизу, якщо ключ key менше тільки що розглянутого, або праворуч унизу, якщо ключ key більше тільки що розглянутого. Процес завершується в одному з двох випадків:
- знайдена вершина, що містить ключ, який дорівнює ключеві key;
- у дереві відсутня вершина, до якої потрібно перейти для виконання чергового кроку пошуку.
У першому випадку повертається покажчик на знайдену вершину. В другому – значення nil.
{===== Програмний приклад 7.11 =======}
Function Find(key:integer;d:TreePtr): TreePtr;
Var {key - ключ, d - корінь дерева}
p:TreePtr;
Begin p:=d;
while (p<>nil)and(key<>p^.data) do
if key<p^.data then p:=p^.lptr {пошук вліво}
else p:=p^.rptr{пошук вправо}
Find:=p;
End; { Find }
Як і у випадку пошуку в списку, складність умови закінчення циклу наводить на думку, що може існувати і краще рішення. Таким рішенням є використання бар'єра. Адже такий прийом можна застосовувати і при пошуку по дереву. Використання посилань дозволяє закінчити всі вітки дерева бар'єром. Тепер виходить уже не дерево, а щось, що нагадує дерево, усі листи якого "причеплені" знизу до одного якоря. Бар'єр можна розглядати як загальне представлення всіх зовнішніх вершин, що додаються до первісного дерева (див. рис. 7.33).
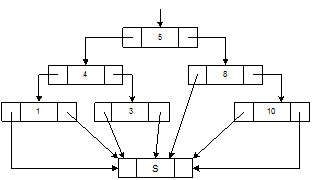
Рис. 7.33. Дерево пошуку з бар’єром
У результаті це дозволяє одержати більш просту процедуру пошуку як у програмному прикладі 7.12.
{===== Програмний приклад 7.12 =======}
Function Find(key:integer;d:TreePtr): TreePtr;
Var p:TreePtr; {key - ключ, d - корінь дерева}
Begin
p:=d; s^.data:=key;
while key<>p^.data do
if key<p^.data then p:=p^.lptr {пошук вліво}
else p:=p^.rptr{пошук вправо}
Find:=p;
End; { Find }
Очевидно, якщо в дереві з коренем d ключ зі значенням кеу не буде виявлений, то функція Find одержить значення не nil(як у попередньому випадку), а s, тобто буде вказувати на бар'єр.
ДОДАВАННЯ НОВОГО ВУЗЛА. Алгоритм операції додавання вузла в дерево залежить від типу дерева.
ДОДАВАННЯ ВУЗЛА В ДЕРЕВО ПОШУКУ. Для включення вузла в дерево пошуку насамперед потрібно знайти в дереві ту вершину, до якої можна "підвести" (приєднати) нову вершину, що відповідає запису, що включається. При цьому упорядкованість ключів повина зберігатися. Алгоритм пошуку потрібної вершини, узагалі говорячи, той же самий, що і при пошуку вершини з заданим ключем. Ця вершина буде знайдена в той момент, коли поточний покажчик, що визначає вітку дерева, дорівнюватиме NIL. Тоді процедура вставки записується так, як у програмному прикладі 7.13.
{===== Програмний приклад 7.13 =======}
Procedure insert(k:integer; var d:TreePtr);
{ k – ключ, що додається, d - корінь дерева}
Var s: TreePtr;
Begin
if Find(k,d)<>nil then
begin new(t); t^.key:=k;
t^.left:=NIL; t^.right:=NIL;
if d = NIL then d:=t (* Вставка нової ланки *)
else if k < r^.key
then r^.left:=t
else r^.right:=t;
end; End; { insert }
У програмному прикладі 7.14 наведено приклад процедури додавання вузла до дерева в рекурсивному варіанті.
{===== Програмний приклад 7.14 =======}
Procedure insert(k:integer; var t:TreePtr);
Var s: TreePtr;
Begin
if t = nil then
begin new(d); t^.key:=k;
t^.left:=NIL; t^.right:=NIL;
end else (* Вставка нової ланки *)
if k < t^.key then insert(k, t^.left)
else insert(k,t^.reft:=t);
End; { insert }
ДОДАВАННЯ ВУЗЛА В ЗБАЛАНСОВАНЕ ДЕРЕВО. Розглянемо тепер, що може відбутися при включенні в ідеально збалансоване дерево нової вершини. Якщо в дереві є корінь t і ліве (L) і праве (R) піддерева, то необхідно розрізняти три можливих випадки. Припустимо, включення в L нової вершини приведе до збільшення на 1 його висоти; тоді можливі три випадки:
1). L- і R- вітки стануть різної висоти, але критерій збалансованості не буде порушено.
2). L- і R- вітки стануть рівної висоти, тобто збалансованість навіть покращиться.
3). Критерій збалансованості порушиться, і дерево необхідно перебудовувати.
Візьмемо дерево, представлене на рис. 7.34. Вершини з ключами 9 і 11 можна включити, не порушуючи збалансованості дерева. Так дерево з коренем 10 стає однобічним (випадок 1) а з коренем 8 — лише краще збалансованим (випадок 2). Однак включення ключів 1,3,5 або 7 порушить збалансованість дерева і вимагатиме наступного балансування.

Рис. 7.34. Збалансоване дерево
Алгоритм балансування суттєво залежить від того, як зберігається інформація про збалансованість дерева. Можна для кожної вершини зберігати показник збалансованості. В цьому випадку вузол дерева на мові Pascal можна описати в такий спосіб:
type TreePtr:=^S_Tree;
S_Tree = record
key: KeyType; { ключ }
left,right: TreePtr; { лівий і правий сини }
bal: [-1..1]; { показник збалансованості }
end;
Таким чином, додавання вузла у збалансоване дерево складається з таких шагів:
1) проход по дереву і визначення, що вузол з вказаним ключем вітсутній,
2) включення нового вузла в дерево і визначення показника збалансованості вузла,
3) перевірка у кожному вузлі показника збалансованості і, як що треба, балансування.
Алгоритм балансування є достатньо складним і тут не приводиться. Помітимо лише, щоб не порушити збалансованості дерева, операції додавання вузла в дерево або вилучення вузла з дерева можливі лише на кінці дерева. В іншому випадку збалансованість дерева буде порушено, і для іі встановлення необхідно виконувати досить сложну процедуру повторного балансування.
ВИДАЛЕННЯ ВУЗЛА З ДЕРЕВА ДЕРЕВА ПОШУКУ. Завдання полягає в тому, щоб видалити з упорядкованого дерева вузол з заданим ключем key. Алгоритм видалення простий як що вузол, що видаляється, являється листом, або має одного нащадка. Складності виникають, коли треба видалити вузол з двома нащадками. У цьому випадку видаляємий вузол треба замінити
а) або на самий правий вузол його лівого піддерева,
б) або на самий лівий вузол його правого піддерева. Причому вони можуть мати саме більше одного нащадка.
В програмному прикладі 7.15 подано процедуру видалення вузла з дерева пошуку. В ній виконується спуск по правій вітці лівого піддерева вузла q^, який треба видалити, і змінює ключ вузла q^ на відповідні значення із самого правого вузла лівого піддерева (відносно вузла q^).
{===== Програмний приклад 7.15 =======}
Procedure delete(key:integer; var d:TreePtr);
{ k – ключ, що додається, d - корінь дерева}
Var p,r,q: TreePtr;
Begin
p:=d;
while (p<>nil)and(p^.key<>key) do
if p^.key<key then p:= p^.right else p:=p^.left;
if p^.key=key then
Begin q:=p;
while (p^.right<>nil)and(p^.left<>nil) do
Begin r:=p;
p^.right=nil then p:=p^.left else p:= p^.right;
end; {спуск до кінця вітки}
q^.key:= p^.key;
if r^.right=p then r^.right=nil
else r^.left=p then r^.left=nil;
dispose(p);
end; end;
Видалення вузла по заданому ключу із збалансованого дерева складніше ніж включення вузла оскільки вимагає балансування дерева.
– Конец работы –
Эта тема принадлежит разделу:
Графи P
ДИНАМІЧНІ СТРУКТУРИ ДАНИХ R... Особливості динамічних структурP Лінійні зв язні списки P...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Основні операції над деревами
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.027 сек.
Новости и инфо для студентов