рефераты конспекты курсовые дипломные лекции шпоры

- Раздел Образование
- /
- Процессоры z10
Реферат Курсовая Конспект
Процессоры z10
Процессоры z10 - раздел Образование, Февраля в Москве с визитом находился генеральный директор System z аппаратного подразделения IBM Systems & Целью Разработки Процессоров Z10 (Микросхемы Central Processor, Cp) Было Суще...
Целью разработки процессоров z10 (микросхемы Central Processor, CP) было существенное увеличение производительности по сравнению с z9. Это связано с расширением класса рабочих нагрузок, характерных для сегодняшних мэйнфреймов. К традиционной рабочей нагрузке мэйнфреймов, требующей кэша большой емкости, добавились приложения новых типов, дающие большую вычислительную нагрузку и меньшие требования к емкости кэша. Еще одна цель создателей z10 – повышение энергоэффективности.
CP в z10 являются четырехъядерными, построенными по КМОП-технологии IBM c применением технологии «кремний на изоляторе» и с типоразмером 65 нм. CP содержит 993 млн транзисторов и имеет соответственно большую площадь – 454 кв. мм. Его 64-разрядные процессорные ядра (Processor Unit, PU) уникальны уже потому, что достигли наивысшей в своем классе тактовой частоты (более высокие характеристики только у RISC-процессоров Power6).
Но и само строение СР имеет много оригинальных особенностей (рис. 1). Помимо четырех ядер PU, в CP предусмотрены контроллер оперативной памяти MC, контроллер высокоскоростной шины ввода-вывода GX, а также два сопроцессора COP, каждый из которых используется совместно парой PU [1].
Высокая плотность упаковки и надежность работы обеспечиваются благодаря знаменитому конструктиву IBM MCM (Multi-Chip Module), который агрегирует в себе пять микросхем СР, кэш второго уровня и другую электронику. Повышение производительности процессоров z10 достигнуто в первую очередь благодаря значительному росту тактовой частоты (в поколении z9 оно равнялось 1,7 ГГц) и переработке структуры кэш-памяти. Иерархия кэш-памяти в z10 включает кэш команд первого уровня (I-кэш L1) емкостью 64 Кбайт, кэш данных первого уровня (D-кэш L1) емкостью 128 Кбайт, а также новый уровень кэша для команд и данных (L1.5) для команд и данных емкостью 3 Мбайт; все они являются «собственными» для каждого PU. Кроме того, вне микросхемы СР имеется еще общий кэш второго уровня (L2) емкостью 48 Мбайт.
В z10, как и в Power6, не применяется внеочередное спекулятивное выполнение, характерное для большинства других современных микропроцессоров. Минусом последнего подхода является повышение задержек и возможность останова конвейера из-за взаимозависимостей между командами. В Power6 (и в меньшей степени в z10) старались взаимозависимости минимизировать. В результате достигнутая тактовая частота в z10 при данной технологии изготовления лишь немногим уступает Power6 (4,7 ГГц).
Общая длина «основного» конвейера (по аналогии с процессорами архитектур 86 и RISC будем считать таковым целочисленный конвейер) в z10 составляет 19 тактов, что всего на несколько стадий больше, чем в самых высокочастотных процессорах Intel Xeon c микроархитектурой Core, но в полтора раза ниже, чем в суперконвейерной архитектуре Intel NetBurst. В случае сбоя в PU к этим стадиям добавляется еще пять стадий контрольной точки/восстановления для автоматического аппаратного восстановления при сбое.
Всего можно выделить пять групп стадий конвейера z10: выборка команд; декодирование и выдача на выполнение; доступ в память (в D-кэш); выполнение (команды с фиксированной и плавающей запятой имеют разные участки конвейера); обработка сбоев.
Стадии выборки команд (их пять) реализуются устройством выборки команд IFU (рис. 1). Оно отвечает также за предсказание переходов. Кроме I-кэша L1 c двухтактным доступом здесь представлен также буфер быстрой переадресации TLB (128 строк, 4-канальный). В I-кэше команды хранятся в исходном недекодированном виде. Емкость I-кэша по сравнению с z9 уменьшена в четыре раза, поскольку появился собственный для PU высокопроизводительный кэш L1.5, где также хранятся команды.
В связи с большой длиной конвейера в z10 используется агрессивное предсказание переходов, в первую очередь с применением 5-канального наборно-ассоциативного буфера BTB (Branch Target Buffer) емкостью 10К строк с полем истории на восемь состояний. Кроме того, для переходов, у которых точность предсказания оказывается низкой, применяется специальная таблица PHT емкостью 512 строк. Еще одна структура, используемая в PU параллельно c BTB, – MTBTB (Multiple Target Branch Target Buffer) емкостью 2К строк, использующая хеш-функцию от истории произошедших переходов (детальнее логика предсказания переходов описана в [1]).
За стадии декодирования и выдачи команд на выполнение отвечает блок IDU (Instruction Decoding Unit), которому отвечает суперскалярный конвейер шириной в две инструкции и глубиной в шесть стадий.
В процессоре z9 конвейер короче, но за такт декодируется максимум одна команда.
Стадии доступа в память используют D-кэш L1, имеющий двухтактный конвейеризованный доступ, и двухканальный наборно-ассоциативный блок TLB емкостью 512 строк, обеспечивающий два параллельных доступа по чтению. Стадии доступа в память также обрабатываются суперскалярно с «шириной» в две команды.
В поколении z9 эти стадии могли выполняться во внеочередном порядке. В z10 этого нет, зато реализована аппаратная и программная предварительная выборка в кэш L1. Соответственно в z-Architecture появились новые команды prefetch. А «движок» аппаратной предварительной выборки использует так называемый «буфер истории шагов» емкостью 32 строки с 11-разрядным полем шага (stride). Предварительная выборка работает не так агрессивно, как это делают другие ориентированные на вычисления суперскалярные процессоры, поскольку z10 ориентирован на коммерческую нагрузку. Зато милликоды (так называют встроенные декодированные последовательности, реализующие команды) для длинных пересылок MVCL могут запускать предварительную выборку страниц емкостью 4 Кбайт.
На стадиях выполнения задействовано несколько функциональных устройств: два целочисленных конвейерных устройства FXU и два устройства с плавающей запятой – двоичное конвейерное устройство BFU и десятичное устройство DFU. Большинство целочисленных команд может выполняться в обоих FXU, но некоторые более редкие – только в первом FXU.
B процессорах z9 параллельное выполнение целочисленных команд и команд с плавающей запятой не допускалось; в z10 допускается частичный параллелизм выполнения. BFU выполняет арифметику с плавающей запятой в старом шестнадцатеричном формате мэйнфреймов, а также совместимые со стандартом IEEE P754 операции. Кроме того, в BFU выполняется целочисленное умножение и деление. Ряд компонентов BFU совместим с аналогичными компонентами Power6.
Устройство DFU обеспечивает арифметику, совместимую с IEEE P754. В z9 это было реализовано в милликодах, в z10 – аппаратно. Для выполнения записи данных в оперативную память имеется очередь записи в устройстве LSU (Load/Store Unit), что позволяет перенаправлять оттуда данные, например, в последующую команду загрузки регистров вместо длительного обращения в память [1].
Как это делалось в мэйнфреймах IBM еще несколько десятков лет назад, в случае сбоя процессоров происходит автоматическое восстановление и попытка повторения невыполненной команды. В z10 имеется устройство восстановления RU, которое создает защищенную кодами ЕСС контрольную точку для последующего восстановления. В z9 восстановление было организовано по-иному: в двухъядерной микросхеме центрального процессора там имелось общее «резервное устройство» (sparing unit).
Рассмотрим теперь другие устройства процессорного ядра (рис. 1), в том числе устройство преобразования адресов XU и иерархию кэш-памяти [1,2]. XU используется, в частности, для динамического преобразования виртуальных адресов в физические и содержит буфер TLB L2. Буфер TLB в z10 поддерживает не только стандартные 4-килобайтные страницы, но и большие страницы емкостью 1 Мбайт.
I-кэш L1 является 4-канальным наборно-ассоциативным, D-кэш L1 – 8-канальным, объединенный кэш L1.5 для команд и данных – 12-канальным. Вся эта кэш-память у каждого процессорного ядра – своя, в отличие от кэша L2, который вообще находится вне микросхемы СР. Кэши всех уровней имеют длину строки 256 байт, как и в z9. При этом в L1 и L1.5 применяется сквозная запись, а в L2 – так называемые операции store-in, когда сохраняемые в памяти данные записываются туда не сразу, а буферизуются. Поэтому они могут быть доступны другим процессорным ядром и подсистеме ввода-вывода без обращения в оперативную память.
Появление L1.5 в z10 позволило по сравнению с z9 уменьшить емкости кэшей L1 и увеличить их быстродействие. При попадании в кэш L1.5 строка (16 квадрослов) передается в L1 по одному квадрослову за такт при средней задержке 14,5 такт.
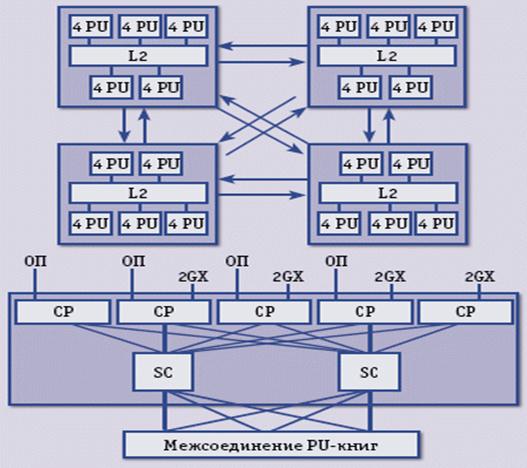
Кэш L2 использует инклюзивный подход и является общим для пяти микросхем СР, упакованных в МСМ (рис. 2). Он имеет емкость 48 Мбайт, является 24-канальным наборно-ассоциативным и, как и L1.5, защищен кодами ECC (в кэше L1 применяется контроль четности). Около 90% промахов в кэше L1 удовлетворяется за счет кэшей L1.5 и L2. О когерентности кэша мы скажем ниже.
В структуре СР представлен еще сопроцессор СОР; другие компоненты СР мы обсудим ниже при анализе структуры SMP-серверов z10. Сопроцессор СОР управляется в основном из милликодов и используется для сжатия данных и задач криптографии. Он включает в себя два устройства сжатия данных и два криптографиеских «движка» – цифровой и для хеширования.
В СОР поддерживается стандарт 3DES, а в z10 появилась и поддержка AES, а также Secure Hash Algorithm (SHA-2) для ключей с длиной до 512 бит. СОР обеспечивает декомпрессию со скоростью до 8,3 Гбайт/с, сжатие – до 240 Мбайт/с и шифрование на скоростях 290-960 Мбайт/с.
Таким образом, резюмируя усовершенствования процессора z10 по сравнению с z9, следует указать на новый высокопроизводительный конвейер; улучшенное предсказание переходов; аппаратную и программную предварительную выборку данных; появление нового кэша L1.5; аппаратную поддержку десятичной арифметики с плавающей запятой; развитие функциональности СОР и др. В CISC-архитектуре z10 появилось 50 новых команд. А всего в ней имеется теперь 894 команды, из которых 668 реализовано аппаратно.
В результате для обработки транзакций в больших базах данных, в том числе на стандартной для мэйнфреймов рабочей нагрузки LSPR, производительность по сравнению с z9 возросла в полтора раза, а на новых приложениях с большей процессорной нагрузкой – вдвое [1].
– Конец работы –
Эта тема принадлежит разделу:
Февраля в Москве с визитом находился генеральный директор System z аппаратного подразделения IBM Systems &
System z EC System z EC IBM... Архитектура IBM System z является первым семейством с новой архитектурой z Architecture ARCHLVL Новые операционные системы IBM первой из которых...
Если Вам нужно дополнительный материал на эту тему, или Вы не нашли то, что искали, рекомендуем воспользоваться поиском по нашей базе работ: Процессоры z10
Что будем делать с полученным материалом:
Если этот материал оказался полезным ля Вас, Вы можете сохранить его на свою страничку в социальных сетях:
| Твитнуть |
Хотите получать на электронную почту самые свежие новости?

Подпишитесь на Нашу рассылку
Реклама





Информация в виде рефератов, конспектов, лекций, курсовых и дипломных работ имеют своего автора, которому принадлежат права. Поэтому, прежде чем использовать какую либо информацию с этого сайта, убедитесь, что этим Вы не нарушаете чье либо право.
© copyright 1999 - 2024 allRefs.net. Все права защищены. Страница сгенерирована за: 0.019 сек.
Новости и инфо для студентов